大模型评测体系介绍及中文大模型表现

大模型评测体系介绍及中文大模型表现

霞姐聊IT
发布于 2025-05-30 08:11:27
发布于 2025-05-30 08:11:27
近几年,ChatGPT、GPT4、LLaMA、Claude3、DeepSeek、字节豆包、百度文心一言、阿里通义千问、腾讯混元、智谱清言、华为盘古等国内外大模型产品不断推出,这么多模型表现如何?它们的擅长领域是什么?在生产中如何选型呢?

现在的主流方式是使用基准测试(Benchmark)来对大模型的能力进行全面量化的评估。
基准测试能验证大模型效果,促进大模型能力的持续提升,指导厂家的选型、推广大模型的行业应用,提升大模型的安全合规性。
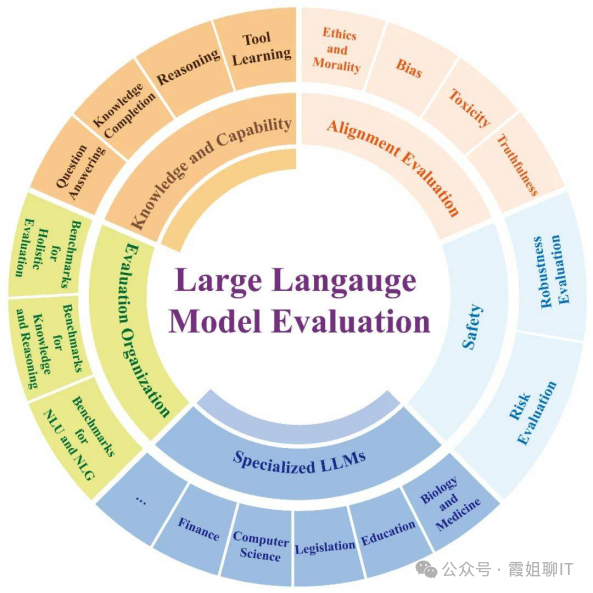
《Evaluating Large Language Models: A Comprehensive Survey》
大模型基准测试包括四个要素:测试指标体系、测试数据集、测试方法、测试工具。
1.测试指标体系(测什么)
大模型评测的指标体系按照“场景-能力-任务-指标”四个维度构建。
(1)场景:通用场景、专业场景、安全场景等
(2)能力:理解能力、生成能力、推理能力、长文本处理能力等
(3)任务:文本分类、情感分析、阅读理解、自然语言推理、视频异常检测等
(4)指标:准确率、召回率、F1值、精确率、BLEU、Rouge-L等。
能力可以通过多种测试任务完成测试,不同的测试任务需要关联不同的指标。
2.测试方法(如何测)
大模型基准测试流程包括:需求分析、环境准备、数据构建、测试执行、结果评估、结果展示这几个步骤。
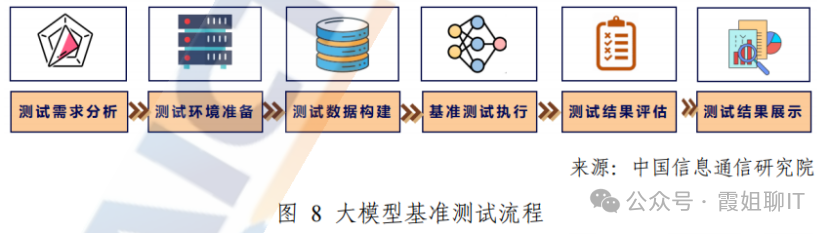
(1)需求分析:全面准确覆盖测试需求,如评测的目的、待测试模型的预评估、测试体系以及方案设计、测试用例设计、测试可行性分析等
(2)环境准备:搭建配套的软硬件环境,如测试脚本开发、测试框架部署、以及测试环境验证
(3)数据构建:人工构建、题目自动化填充、智能算法生成三种方式定期补充或更新评测数据
(4)测试执行:将测试数据输入被测模型并观测模型输出结果
(5)结果评估:采用自动化或者人工的方式进行结果评估。自动化评估会计算特定指标完成模型输出和标准答案的对比。人工评估的方式对评测人员的资质或者评测方法有一定的要求。较为前沿的,有通过大模型作为裁判,对其它模型进行评估的研究。
(6)结果展示:测试报告、榜单、雷达图、柱状图等方式展示被测模型表现。
3.测试数据集(用什么测)
测试数据集即评测数据集。
近年大模型基准测试发展迅猛,各大机构纷纷新增数据集,尤其是2023年,一年就新增了209个评测数据集。现有评测数据集的比例大致是这样的:通用语言类(53%)、行业(21%)、模型安全(7%)、多模态(13%)、可靠性/鲁棒性等(6%)。
评测数据集的发布机构有大学,也有学术机构。从数量上来看,前三名分别是清华大学、阿里巴巴、斯坦福大学。从评测数据集的发布国家来看,中国和美国最多,各占47%,但从国际影响力来看,美国较中国领先。
各领域具有代表性的评测数据集列举如下(加粗标绿的是常用评测数据集):
(1)通用语言类代表性评测数据集
理解知识:MMLU(美)、C-Eval(中)、CMMLU(中)
生成(对话):MT-Bench(美)、MT-Bench-101(中)、AlpacaEval(美)、Lmsys-chat-lm(美)
生成(摘要):DialogSum(中)、LCSTS(中)
推理:BBH(美)、GSM8K(美)、CMATH(中)
学科:GAOKAO(中)、M3Exam(中)
(2)多模态
综合能力:MME(中)、MMBench(中)、MM-Vet(新)、LLaVA-Bench(美)
视觉问答:VQA(美)、OK-VQA(美)
视觉推理:CORE-MM(中)、CONTEXTUAL(美)
视觉处理:OCRBench(中)、Q-Bench(新)
图像生成:T2I-CompBench(中国香港)、HRA-Bench(沙特)
(3)行业&应用
金融:FinVal(中)、FINANCEBENCH(美)
医疗:PubMedQA(美)、CMExam(中)
法律:JEC-QA(中)、CUAD(美)
软件:LogBench(中)、OpsEval(中)
通信:NetEval(中)
互联网:MSQA(美)
代码助手:MBPP(美)、HumanEval(美)
AI智能体:AgentBench(中)
具身智能:SQA3D(中)、ALFRED(美)
(4)安全
综合安全:DECODINGTRUST(美)、Safety-Prompts(中)
内容安全:TOXIGEN(美)、CPAD(中)
伦理安全:CVALUES(中)、ETHICS(美)
隐私安全:CONFAIDE(美)
模型安全:R-Judge(中)
4.测试工具(如何执行)
使用LLMeBench、HELM、HEIM、OpenCompass、SuperCLUE、SuperBench等套件或者框架进行实际评测。测试工具一般包含数据集管理、模型库管理、API管理、测试任务分发、测试指标计算、结果分析、结果展示等多种功能。
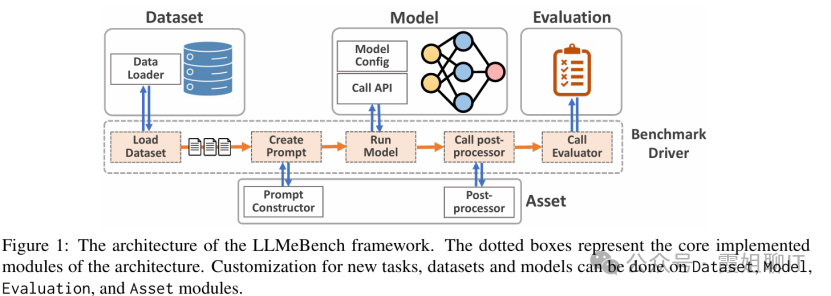
关于大模型评测,国家也发布了标准GB/T45288.2—2025 人工智能 大模型第2部分:评测指标与方法,读者可以参考。
另外,中文大模型谁家最强呢?根据SuperCLUE发布的报告,最值得关注的中文大模型有:

SuperCLUE将其和国外大模型的评测结果一起,进行了四象限分类,大家可以参考下:

SuperCLUE测试报告很详尽,读者可发送“SuperCLUE”后台获取报告,进行更详细的了解。
参考文档:
1.Evaluating Large Language Models: A Comprehensive Survey(发送“大模型测试”可得)
2.中国信通院《大模型基准测试体系研究报告2024》(发送“大模型测试”可得)
3.SuperCLUE《中文大模型基准测评2025年3月报告》(发送“SuperCLUE”可得)
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-04-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号