谷歌重磅开源 A2UI,这将会是2026年Agentic UI的王炸级标准!

谷歌重磅开源 A2UI,这将会是2026年Agentic UI的王炸级标准!

开源星探
发布于 2026-03-16 20:12:07
发布于 2026-03-16 20:12:07
过去两年,我们几乎默认了一件事:
人和 AI 的交互就只能靠文本框和语音。
不管是 GPT、DeepSeek、Claude,还是各种音视频 Agent,核心入口几乎清一色是一个聊天框。
但只要你真正做过 AI 应用,就会很快发现一个现实问题:
- • 真实任务往往不是一句话能完成的;
- • 用户输入经常不完整、不规范、缺关键信息;
- • 单靠「再问一句」对话,体验很容易崩。
比如这些场景:
- • 订机票要选日期、舱位、乘客
- • 填订单要地址、手机号、发票信息
- • 企业客服要订单号、时间范围、商品规格
你让用户靠「多轮对话」一点点补齐这些结构化信息,显然即使能顺利执行下来,步骤及体验也是相当差的。
Google 开发团队显然也意识到了这一点。就在这两天,他们开源了 A2UI。
它并不是一个“UI 框架”,而是一种基于代理的接口协议,负责 AI Agent 和用户界面之间的中间层协议与实现。
而核心目标就是让 Agent 能够使用 GUI(图形用户界面)与人类交流,就像它使用自然语言一样自然。
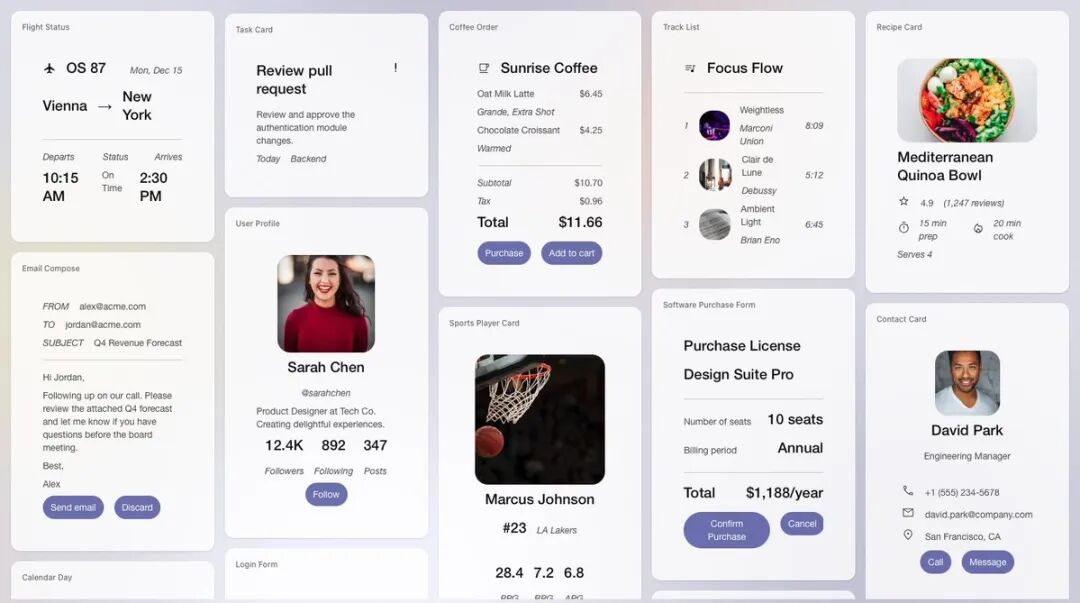
主要原理
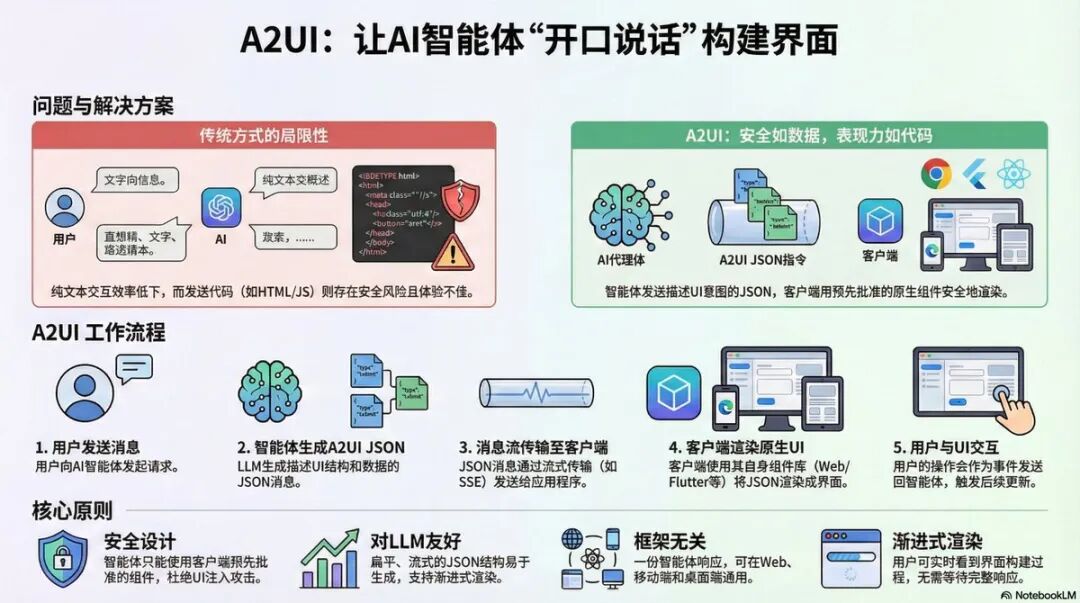
A2UI,让 AI 用 JSON 描述 UI,由客户端原生渲染交互界面。
是的,它的核心主张就是这个,声明式 JSON。
AI 不用写什么前端代码,只输出「我需要什么 UI」即可。
以下是一个简化的 JSON 消息示例(定义用户界面):
{
"surfaceUpdate": {
"surfaceId": "main",
"components": [
{
"id": "header",
"component": {
"Text": {
"text": {"literalString": "Book Your Table"},
"usageHint": "h1"
}
}
},
{
"id": "date-picker",
"component": {
"DateTimeInput": {
"label": {"literalString": "Select Date"},
"value": {"path": "/reservation/date"},
"enableDate": true
}
}
},
{
"id": "submit-btn",
"component": {
"Button": {
"child": "submit-text",
"action": {"name": "confirm_booking"}
}
}
},
{
"id": "submit-text",
"component": {
"Text": {"text": {"literalString": "Confirm Reservation"}}
}
}
]
}
}它定义了界面的 UI 组件:文本标题、日期选择器和按钮。
AI 只关心意图和结构,而不是 UI 细节。
还有一个关键核心:客户端原生渲染(安全关键)
UI 不是 AI 直接生成 HTML/JS,而是:客户端 + 用受控组件库 + 再根据 JSON 渲染。
这样做的好处是:
- • 安全(避免注入)
- • 风格统一
- • 移动端/Web/桌面端一致
- • 可控权限和交互逻辑
这也是 A2UI 能适应企业级场景的关键。
A2UI 能力一览
1、Widget Gallery:现成可用的交互组件库
A2UI 自带一个 Widget Gallery,包含大量常用 UI 小部件:
- • 表单输入
- • 日期选择
- • 下拉选项
- • 状态展示
所有组件:
- • 都有现成示例
- • 支持直接使用或二次定制
- • 界面与源码可实时切换查看
这点对开发者非常友好。
2、Material Icons:开箱即用的设计语言
内置 100 个常用 Material Icons,保证:
- • 风格统一
- • 不用额外处理设计资源
3、基于 CopilotKit,天然适合 AI 系统
A2UI 构建在 CopilotKit 之上,因此天然支持:
- • 聊天式交互
- • AI 生成内容
- • Agent 驱动 UI 更新
这让它非常适合用在:
“对话 + 操作 + 界面”混合型 AI 系统
快速入手
环境要求:Node.js(版本>=18)、Gemini API
克隆代码
git clone https://github.com/google/a2ui.git
cd a2ui设置API密钥
export GEMINI_API_KEY="your_gemini_api_key_here"切换目录至 Lit Client
cd samples/client/lit安装运行
npm install
npm run demo:all最后打开 http://localhost:5173 就能在浏览器中看到网页应用。
在网页应用中,尝试以下提示:
- • “预订一张两人桌” ——观看客服人员生成预订表格
- • “查找附近的意大利餐厅” - 查看动态搜索结果
- • “你们的工作时间是什么时候?” - 体验针对不同意图的不同用户界面布局。
其幕后执行流程:
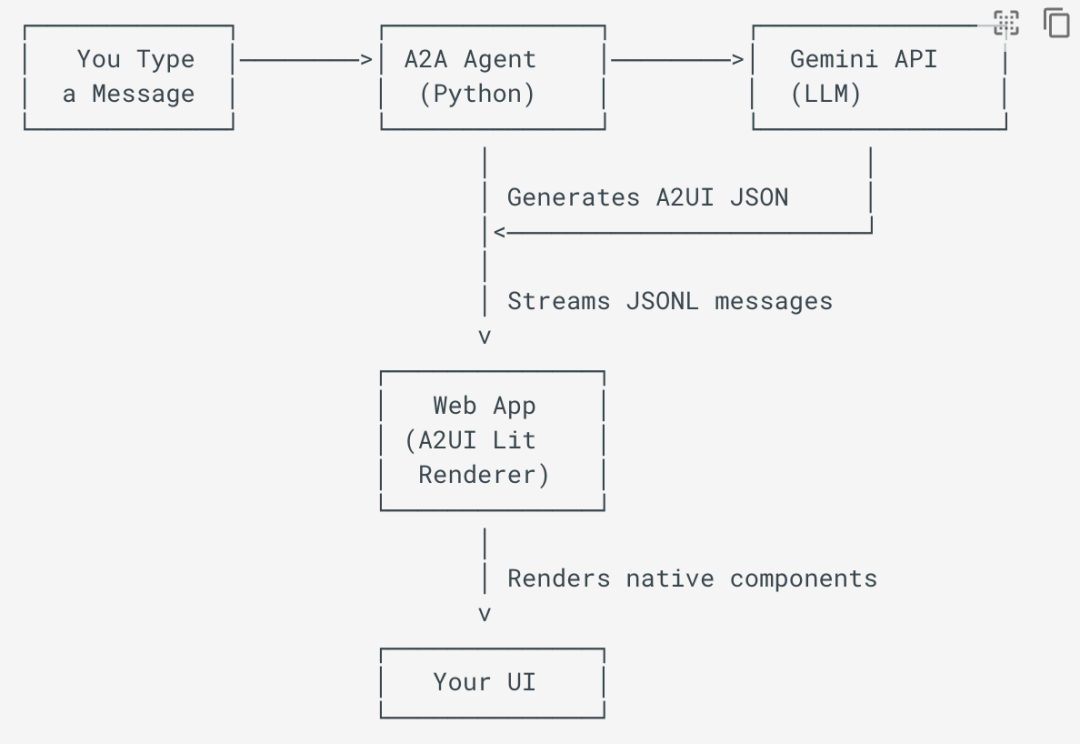
- • 首先通过网页用户界面发送消息。
- • A2A代理收到对话后,会将对话内容发送给Gemini。
- • Gemini 生成描述用户界面的 A2UI JSON 消息。
- • A2A代理会将这些消息流式传输回Web应用程序。
- • A2UI渲染器将它们转换为原生Web组件
- • 最后在浏览器中看到渲染后的用户界面。
写在最后
A2UI 传递出的一个强烈信号:未来的 AI 系统,交互不再只有「说话」,而是「会生成界面」。
这意味着:
- • AI 不只是回答问题
- • 而是能主动设计“如何与人协作”
从这个角度看,A2UI 解决的,并不是 UI 好不好看,而是一个更底层的问题:
复杂任务,应该如何让 AI 和人高效协作?
当 Agent 能根据任务需要,动态生成最合适的交互界面,很多原本“只能 Demo”的 AI 应用,才真正有机会进入生产环境。
如果你正在做 AI Agent、智能客服或企业 AI 系统,这个项目,非常值得你花时间研究一下。
GitHub:https://github.com/google/a2ui

如果本文对您有帮助,也请帮忙点个 赞👍 + 在看 哈!❤️
在看你就赞赞我!

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号