K8S 静态 PV/PVC 绑定慢原因分析

K8S 静态 PV/PVC 绑定慢原因分析

abin
发布于 2026-03-17 12:00:46
发布于 2026-03-17 12:00:46
在 K8S 生态,有存储卷声明和存储卷的概念,分别对应 K8S 集群中的 PersistentVolumeClaim 和 PersistentVolume 资源,业务 Pod 通过存储卷声明来使用存储资源:
- 存储卷声明:在该资源中声明需要的存储类型和大小等信息。
- 存储卷:实际的存储资源,可以是磁盘 ID,也可以是文件系统服务端地址。
存储卷又可以分为动态卷和静态卷:
- 动态卷:由 K8S 管理后端存储的生命周期,例如,块设备的创建和删除,文件存储目录的创建和删除。K8S 组件根据存储卷声明创建好实际存储资源后,会在集群中创建 PersistentVolume,并将该 PersistentVolume 和对应的 PersistentVolumeClaim 绑定起来。
- 静态卷:由用户自行管理后端存储的生命周期,K8S 仅将用户创建的 PersistentVolume 和 PersistentVolumeClaim 绑定起来,并且挂载给业务 Pod 使用。
静态卷不涉及和后端存储的交互,因此,PersistentVolume 和 PersistentVolumeClaim 绑定慢说明 K8S 组件存在瓶颈,而非后端存储资源。
kube controller manager 就是负责 PersistentVolume 和 PersistentVolumeClaim 绑定的 K8S 核心组件。kube controller manager(KCM)组件由很多 controller 组成,分别处理不同的 K8S 资源,例如:Daemonset controller 负责在每个节点上拉起 Pod,Replication controller 负责拉起指定数量处于期望状态的 Pod,PV controller 主要完成 PV/PVC 资源的绑定。
PV Controller 主要逻辑
func (ctrl *PersistentVolumeController) Run(ctx context.Context) {
defer utilruntime.HandleCrash()
defer ctrl.claimQueue.ShutDown()
defer ctrl.volumeQueue.ShutDown()
// Start events processing pipeline.
ctrl.eventBroadcaster.StartStructuredLogging(3)
ctrl.eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: ctrl.kubeClient.CoreV1().Events("")})
defer ctrl.eventBroadcaster.Shutdown()
logger := klog.FromContext(ctx)
logger.Info("Starting persistent volume controller")
defer logger.Info("Shutting down persistent volume controller")
if !cache.WaitForNamedCacheSync("persistent volume", ctx.Done(), ctrl.volumeListerSynced, ctrl.claimListerSynced, ctrl.classListerSynced, ctrl.podListerSynced, ctrl.NodeListerSynced) {
return
}
ctrl.initializeCaches(logger, ctrl.volumeLister, ctrl.claimLister)
go wait.Until(func() { ctrl.resync(ctx) }, ctrl.resyncPeriod, ctx.Done())
go wait.UntilWithContext(ctx, ctrl.volumeWorker, time.Second)
go wait.UntilWithContext(ctx, ctrl.claimWorker, time.Second)
metrics.Register(ctrl.volumes.store, ctrl.claims, &ctrl.volumePluginMgr)
<-ctx.Done()
}
Informer 在 PV/PVC 资源更新的时候,加入 PV 和 PVC 队列。事件包括:
- Add
- Update
- Delete
p.VolumeInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) { controller.enqueueWork(ctx, controller.volumeQueue, obj) },
UpdateFunc: func(oldObj, newObj interface{}) { controller.enqueueWork(ctx, controller.volumeQueue, newObj) },
DeleteFunc: func(obj interface{}) { controller.enqueueWork(ctx, controller.volumeQueue, obj) },
},
)
controller.volumeLister = p.VolumeInformer.Lister()
controller.volumeListerSynced = p.VolumeInformer.Informer().HasSynced
p.ClaimInformer.Informer().AddEventHandler(
cache.ResourceEventHandlerFuncs{
AddFunc: func(obj interface{}) { controller.enqueueWork(ctx, controller.claimQueue, obj) },
UpdateFunc: func(oldObj, newObj interface{}) { controller.enqueueWork(ctx, controller.claimQueue, newObj) },
DeleteFunc: func(obj interface{}) { controller.enqueueWork(ctx, controller.claimQueue, obj) },
},
)
controller.claimLister = p.ClaimInformer.Lister()
controller.claimListerSynced = p.ClaimInformer.Informer().HasSynced
resync 的目的是什么?
既然list-watch机制可以实时更新 PV/PVC 的 event 到队列中,为什么还需要 resync 呢?
Informer 的 resync 机制
Informer 的 Reflector 通过 List/Watch 机制将资源的 Event 放入 DeltaFIFO,同时更新 Indexer 本地缓存。resync 会定期将 Indexer 缓存中的 Event 同步到 DeltaFIFO。informer 的 Event Handler 在处理的时候,可能存在处理失败的情况,定期 resync 能够让这个 Event 重新走 OnUpdate 被处理。
func CreateControllerContext(ctx context.Context, s *config.CompletedConfig, rootClientBuilder, clientBuilder clientbuilder.ControllerClientBuilder) (ControllerContext, error) {
// Informer transform to trim ManagedFields for memory efficiency.
trim := func(obj interface{}) (interface{}, error) {
if accessor, err := meta.Accessor(obj); err == nil {
if accessor.GetManagedFields() != nil {
accessor.SetManagedFields(nil)
}
}
return obj, nil
}
versionedClient := rootClientBuilder.ClientOrDie("shared-informers")
sharedInformers := informers.NewSharedInformerFactoryWithOptions(versionedClient, ResyncPeriod(s)(), informers.WithTransform(trim))
// 省略部分内容
controllersmetrics.Register()
return controllerContext, nil
}
resync 逻辑:
// Resync adds, with a Sync type of Delta, every object listed by
// `f.knownObjects` whose key is not already queued for processing.
// If `f.knownObjects` is `nil` then Resync does nothing.
func (f *DeltaFIFO) Resync() error {
f.lock.Lock()
defer f.lock.Unlock()
if f.knownObjects == nil {
returnnil
}
keys := f.knownObjects.ListKeys()
for _, k := range keys {
if err := f.syncKeyLocked(k); err != nil {
return err
}
}
returnnil
}
syncKeyLocked过程:
func (f *DeltaFIFO) syncKeyLocked(key string) error {
obj, exists, err := f.knownObjects.GetByKey(key)
if err != nil {
klog.Errorf("Unexpected error %v during lookup of key %v, unable to queue object for sync", err, key)
returnnil
} elseif !exists {
klog.Infof("Key %v does not exist in known objects store, unable to queue object for sync", key)
returnnil
}
// If we are doing Resync() and there is already an event queued for that object,
// we ignore the Resync for it. This is to avoid the race, in which the resync
// comes with the previous value of object (since queueing an event for the object
// doesn't trigger changing the underlying store <knownObjects>.
id, err := f.KeyOf(obj)
if err != nil {
return KeyError{obj, err}
}
// 如果发现 FIFO 队列中已经有相同 key 的 event 进来了,说明该资源对象有了新的 event,
// 在 Indexer 中旧的缓存应该失效,因此不做 Resync 处理直接返回 nil
iflen(f.items[id]) > 0 {
returnnil
}
// 否则,重新放入 FIFO 队列中
if err := f.queueActionLocked(Sync, obj); err != nil {
return fmt.Errorf("couldn't queue object: %v", err)
}
returnnil
}
如果 FIFO 有新的 Event,不做 resync,直接返回。
Infrmer 对于 sync Event 的处理:
func (s *sharedIndexInformer) HandleDeltas(obj interface{}, isInInitialList bool) error {
s.blockDeltas.Lock()
defer s.blockDeltas.Unlock()
if deltas, ok := obj.(Deltas); ok {
return processDeltas(s, s.indexer, deltas, isInInitialList)
}
return errors.New("object given as Process argument is not Deltas")
}
processDeltas:
// Multiplexes updates in the form of a list of Deltas into a Store, and informs
// a given handler of events OnUpdate, OnAdd, OnDelete
func processDeltas(
// Object which receives event notifications from the given deltas
handler ResourceEventHandler,
clientState Store,
deltas Deltas,
isInInitialList bool,
) error {
// from oldest to newest
for _, d := range deltas {
obj := d.Object
switch d.Type {
// 判断事件类型,看事件是通过新增、更新、替换、删除还是 Resync 重新同步产生的
case Sync, Replaced, Added, Updated:
if old, exists, err := clientState.Get(obj); err == nil && exists {
if err := clientState.Update(obj); err != nil {
return err
}
// 如果 Event 已经存在,触发 OnUpdate
handler.OnUpdate(old, obj)
} else {
if err := clientState.Add(obj); err != nil {
return err
}
handler.OnAdd(obj, isInInitialList)
}
case Deleted:
if err := clientState.Delete(obj); err != nil {
return err
}
handler.OnDelete(obj)
}
}
returnnil
}
总结:resync 机制的引入,定时将 Indexer 缓存事件重新同步到 Delta FIFO 队列中,在处理 SharedInformer 事件回调时,让处理失败的事件得到重新处理。并且通过入队前判断 FIFO 队列中是否已经有了更新版本的 event,来决定是否丢弃 Indexer 缓存不进行 resync 入队。在处理 Delta FIFO 队列中 resync 的事件数据时,触发 onUpdate 回调来让事件重新被处理。
PV controller 的 resync 机制
K8S 社区不希望 PV/PVC 使用 shared informer 自带的比较短的 resync 周期,因此单独实现了 resync 逻辑,流程非常简单,仅重新将 PV/PVC 加入队列。
// resync supplements short resync period of shared informers - we don't want
// all consumers of PV/PVC shared informer to have a short resync period,
// therefore we do our own.
func (ctrl *PersistentVolumeController) resync(ctx context.Context) {
logger := klog.FromContext(ctx)
logger.V(4).Info("Resyncing PV controller")
pvcs, err := ctrl.claimLister.List(labels.NewSelector())
if err != nil {
logger.Info("Cannot list claims", "err", err)
return
}
for _, pvc := range pvcs {
ctrl.enqueueWork(ctx, ctrl.claimQueue, pvc)
}
pvs, err := ctrl.volumeLister.List(labels.NewSelector())
if err != nil {
logger.Info("Cannot list persistent volumes", "err", err)
return
}
for _, pv := range pvs {
ctrl.enqueueWork(ctx, ctrl.volumeQueue, pv)
}
}
对于队列中已经存在的元素,如何处理?
func (ctrl *PersistentVolumeController) enqueueWork(ctx context.Context, queue workqueue.Interface, obj interface{}) {
// Beware of "xxx deleted" events
logger := klog.FromContext(ctx)
if unknown, ok := obj.(cache.DeletedFinalStateUnknown); ok && unknown.Obj != nil {
obj = unknown.Obj
}
objName, err := controller.KeyFunc(obj)
if err != nil {
logger.Error(err, "Failed to get key from object")
return
}
logger.V(5).Info("Enqueued for sync", "objName", objName)
queue.Add(objName)
}
加入队列的逻辑,按顺序是:
- 如果
shuttingDown,跳过。新的元素都不处理,worker goroutine 准备退出了。 - 如果
dirty已经存在,跳过。 - 否则,插入
dirty,这是一个 map,key 为 item。 - 如果
processing已经存在,跳过。 - 否则,追加到
queue队列的最后
// Add marks item as needing processing.
func (q *Type) Add(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
if q.shuttingDown {
return
}
if q.dirty.has(item) {
return
}
q.metrics.add(item)
q.dirty.insert(item)
if q.processing.has(item) {
return
}
q.queue = append(q.queue, item)
q.cond.Signal()
}
队列中dirty、processing和queue的含义:
queue:处理的顺序(也在dirty,但是不在processing里面)dirty:需要处理的元素。processing:正在处理的元素,这些可能也同时在dirty中。当处理完某个元素并且从processing移除后,检查在dirty是否存在,如果存在,重新加入queue。
// Type is a work queue (see the package comment).
type Type struct {
// queue defines the order in which we will work on items. Every
// element of queue should be in the dirty set and not in the
// processing set.
queue []t
// dirty defines all of the items that need to be processed.
dirty set
// Things that are currently being processed are in the processing set.
// These things may be simultaneously in the dirty set. When we finish
// processing something and remove it from this set, we'll check if
// it's in the dirty set, and if so, add it to the queue.
processing set
cond *sync.Cond
shuttingDown bool
drain bool
metrics queueMetrics
unfinishedWorkUpdatePeriod time.Duration
clock clock.WithTicker
}
重新加入queue的逻辑:
// Done marks item as done processing, and if it has been marked as dirty again
// while it was being processed, it will be re-added to the queue for
// re-processing.
func (q *Type) Done(item interface{}) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
q.metrics.done(item)
q.processing.delete(item)
if q.dirty.has(item) {
q.queue =append(q.queue, item)
q.cond.Signal()
} elseif q.processing.len() == 0 {
q.cond.Signal()
}
}
为什么需要定期 resync?
由于网络或其它原因丢事件,例如,没有放入 queue,导致 Event 丢失。通过 resync 能够定期将没处理的 Event 重新加入队列,使得 controller 能够处理,保证最终一致性。
resync 的周期默认值为 15s,这是一个随意指定的值,可以通过配置参数--pvclaimbinder-sync-period修改。参数默认值参考:kubernetes/kubernetes/pull/26414[1]
worker 的执行周期?
PV 和 PVC 的 worker 每隔 1s 执行一次。
func (ctrl *PersistentVolumeController) Run(ctx context.Context) {
defer utilruntime.HandleCrash()
defer ctrl.claimQueue.ShutDown()
defer ctrl.volumeQueue.ShutDown()
// Start events processing pipeline.
ctrl.eventBroadcaster.StartStructuredLogging(3)
ctrl.eventBroadcaster.StartRecordingToSink(&v1core.EventSinkImpl{Interface: ctrl.kubeClient.CoreV1().Events("")})
defer ctrl.eventBroadcaster.Shutdown()
logger := klog.FromContext(ctx)
logger.Info("Starting persistent volume controller")
defer logger.Info("Shutting down persistent volume controller")
if !cache.WaitForNamedCacheSync("persistent volume", ctx.Done(), ctrl.volumeListerSynced, ctrl.claimListerSynced, ctrl.classListerSynced, ctrl.podListerSynced, ctrl.NodeListerSynced) {
return
}
ctrl.initializeCaches(logger, ctrl.volumeLister, ctrl.claimLister)
go wait.Until(func() { ctrl.resync(ctx) }, ctrl.resyncPeriod, ctx.Done())
go wait.UntilWithContext(ctx, ctrl.volumeWorker, time.Second)
go wait.UntilWithContext(ctx, ctrl.claimWorker, time.Second)
metrics.Register(ctrl.volumes.store, ctrl.claims, &ctrl.volumePluginMgr)
<-ctx.Done()
}
worker 每次处理的 PV/PVC 数量?
workFunc返回 true 的时候,结束处理队列中的内容- 只有
ctrl.volumeQueue.Get返回的第二个值quit为 true 的时候,workFunc返回 true
// volumeWorker processes items from volumeQueue. It must run only once,
// syncVolume is not assured to be reentrant.
func (ctrl *PersistentVolumeController) volumeWorker(ctx context.Context) {
logger := klog.FromContext(ctx)
workFunc := func(ctx context.Context) bool {
keyObj, quit := ctrl.volumeQueue.Get()
if quit {
returntrue
}
defer ctrl.volumeQueue.Done(keyObj)
key := keyObj.(string)
logger.V(5).Info("volumeWorker", "volumeKey", key)
_, name, err := cache.SplitMetaNamespaceKey(key)
if err != nil {
logger.V(4).Info("Error getting name of volume to get volume from informer", "volumeKey", key, "err", err)
returnfalse
}
volume, err := ctrl.volumeLister.Get(name)
if err == nil {
// The volume still exists in informer cache, the event must have
// been add/update/sync
ctrl.updateVolume(ctx, volume)
returnfalse
}
if !errors.IsNotFound(err) {
logger.V(2).Info("Error getting volume from informer", "volumeKey", key, "err", err)
returnfalse
}
// The volume is not in informer cache, the event must have been
// "delete"
volumeObj, found, err := ctrl.volumes.store.GetByKey(key)
if err != nil {
logger.V(2).Info("Error getting volume from cache", "volumeKey", key, "err", err)
returnfalse
}
if !found {
// The controller has already processed the delete event and
// deleted the volume from its cache
logger.V(2).Info("Deletion of volume was already processed", "volumeKey", key)
returnfalse
}
volume, ok := volumeObj.(*v1.PersistentVolume)
if !ok {
logger.Error(nil, "Expected volume, got", "obj", volumeObj)
returnfalse
}
ctrl.deleteVolume(ctx, volume)
returnfalse
}
for {
if quit := workFunc(ctx); quit {
logger.Info("Volume worker queue shutting down")
return
}
}
}
什么时候quit为 true?
- 队列长度为 0 的时候,
quit为 true,也就是说,队列中已经没有待处理的 PV/PVC 资源。
// Get blocks until it can return an item to be processed. If shutdown = true,
// the caller should end their goroutine. You must call Done with item when you
// have finished processing it.
func (q *Type) Get() (item interface{}, shutdown bool) {
q.cond.L.Lock()
defer q.cond.L.Unlock()
forlen(q.queue) == 0 && !q.shuttingDown {
q.cond.Wait()
}
iflen(q.queue) ==0 {
// We must be shutting down.
returnnil, true
}
item = q.queue[0]
// The underlying array still exists and reference this object, so the object will not be garbage collected.
q.queue[0] = nil
q.queue = q.queue[1:]
q.metrics.get(item)
q.processing.insert(item)
q.dirty.delete(item)
return item, false
}
worker 为什么是单线程?
按 Kubernetes 代码注释中的描述,多个syncClaim(处理 PVC 的队列)会导致多个 PVC 绑定到同一个 PV,或者多个 PV 绑定到同一个 PVC,所以 PV 和 PVC 的绑定需要串行进行。
// Work queues of claims and volumes to process. Every queue should have
// exactly one worker thread, especially syncClaim() is not reentrant.
// Two syncClaims could bind two different claims to the same volume or one
// claim to two volumes.The controller would recover from this (due to
// version errors in API server and other checks in this controller),
// however overall speed of multi-worker controller would be lower than if
// it runs single thread only.
claimQueue *workqueue.Type
volumeQueue *workqueue.Type
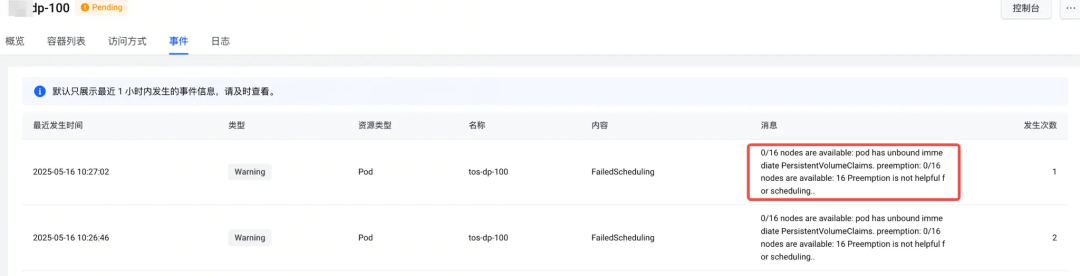
静态卷 PV/PVC 绑定慢的原因?
从业务 Pod Event 展示的信息看,静态 PV 和 PVC 没绑定会导致 Pod 无法调度。用户的 PV/PVC 绑定时间最长达到 30s:
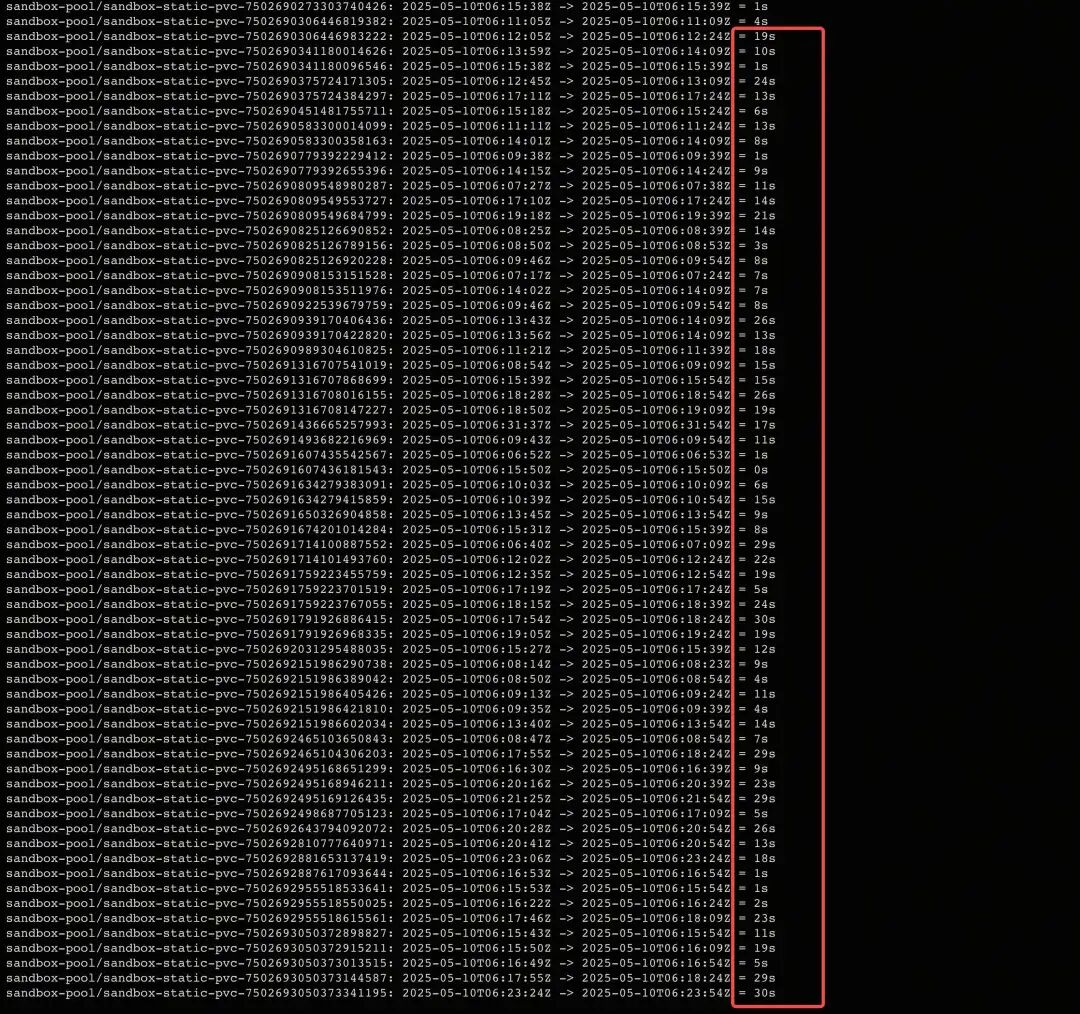
问题复现(1000 PV/PVC)
- PV
apiVersion: v1
kind:PersistentVolume
metadata:
name:oss-pv
spec:
accessModes:
-ReadWriteMany
capacity:
storage:20Gi
csi:
driver:oss.csi.xxx.com
volumeAttributes:
bucket:model
path:/
secret_name:oss-secret
secret_namespace:kube-system
url:http://oss-s3-xxx.com
volumeHandle:oss-pv
persistentVolumeReclaimPolicy:Retain
volumeMode:Filesystem
- PVC
apiVersion: v1
kind:PersistentVolumeClaim
metadata:
name:oss-pvc
namespace:default
spec:
accessModes:
-ReadWriteMany
resources:
requests:
storage:20Gi
volumeMode:Filesystem
volumeName:oss-pv
- Pod
apiVersion: v1
kind:Pod
metadata:
name:oss-dp
namespace:default
spec:
containers:
-image:nginx:latest
name:nginx
volumeMounts:
-mountPath:/var/lib/www
name:oss
volumes:
-name:oss
persistentVolumeClaim:
claimName:oss-pvc
- 脚本
#!/bin/bash
total=1000
mkdir -p pvs
mkdir -p pvcs
mkdir -p pods
mkdir -p outputs
functioninit() {
for i in $(seq $total); do
sed "s/ name: oss-pv.*/ name: oss-pv-$i/g" pv.yaml >pvs/$i.yaml
sed -i "s/ volumeHandle: oss-pv.*/ volumeHandle: oss-pv-$i/g" pvs/$i.yaml
sed "s/ name: oss-pvc.*/ name: oss-pvc-$i/g" pvc.yaml >pvcs/$i.yaml
sed -i "s/ volumeName: oss-pv.*/ volumeName: oss-pv-$i/g" pvcs/$i.yaml
sed "s/ name: oss-dp.*/ name: oss-dp-$i/g" pod.yaml >pods/$i.yaml
sed -i "s/ claimName: oss-pvc.*/ claimName: oss-pvc-$i/g" pods/$i.yaml
done
}
functionhandle_start() {
i=$1
kubectl create -f pvs/$i.yaml
kubectl create -f pvcs/$i.yaml
kubectl create -f pods/$i.yaml
}
functionstart() {
for i in $(seq $total); do
handle_start $i > outputs/$i.log 2>&1 &
done
}
functionhandle_stop() {
i=$1
kubectl delete -f pods/$i.yaml
kubectl delete -f pvcs/$i.yaml
kubectl delete -f pvs/$i.yaml
}
functionstop() {
for i in $(seq $total); do
handle_stop $i > outputs/$i.log 2>&1 &
done
}
# Check if a subcommand is provided
if [ $# -eq 0 ]; then
echo"Usage: $0 <init|start|stop>"
exit 1
fi
case"$1"in
init)
init
;;
start)
start
;;
stop)
stop
;;
*)
echo"Invalid subcommand. Usage: $0 <init|start|stop>"
exit 1
;;
esac
- 复现问题
- PV/PVC 绑定时间
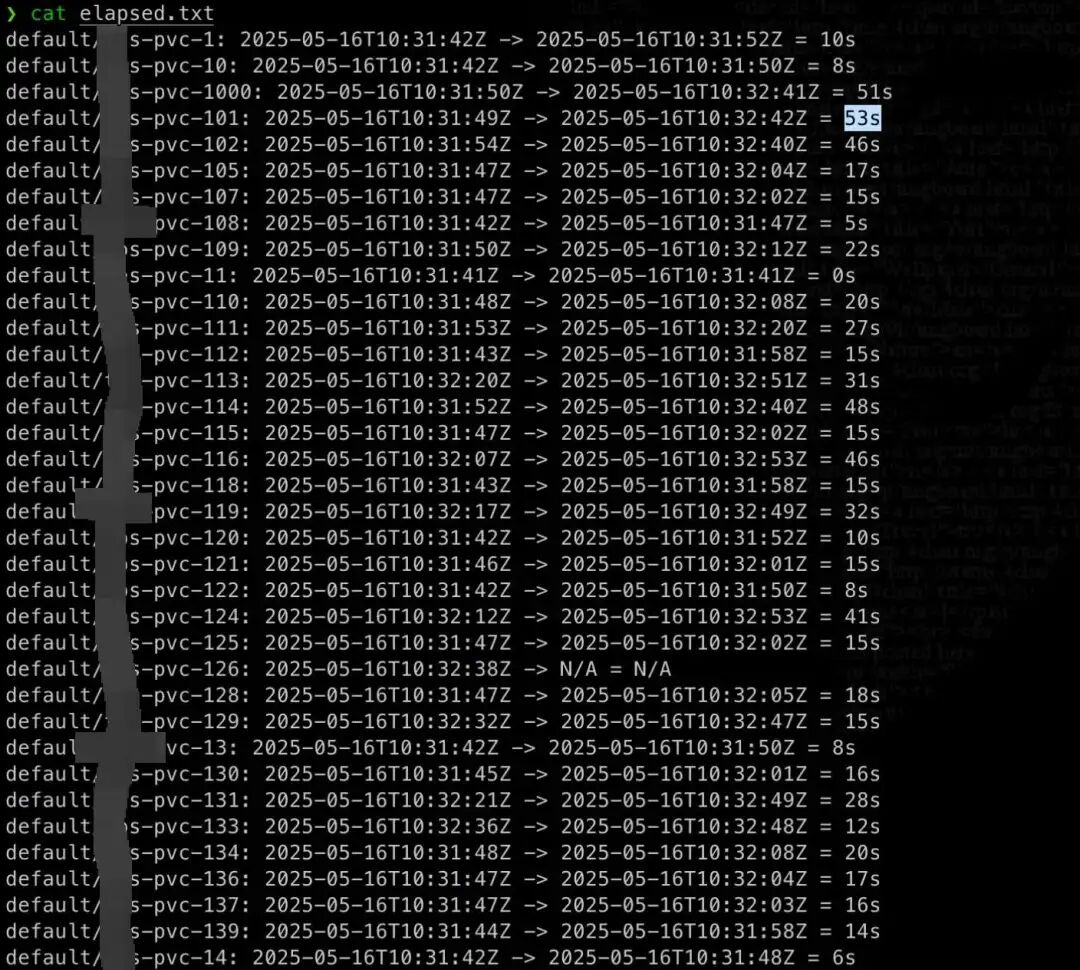
测试结果比实际情况的更差,PV/PVC 最长绑定时间达到 53 秒。
调试 KCM
增加 debug 信息,打印出 KCM 绑定成功到更新 PVC/PV 资源的时间,分析绑定阶段的耗时:
- 创建时间:2025-05-17T07:43:25Z
- 收到 add 事件:2025-05-17 15:43:25.853
- resync:2025-05-17 15:43:36.338
- KCM 开始绑定:2025-05-17 15:43:41.247
收到 add 事件到开始绑定的时间:16s
原因:处理 queue 只有一个 GoRoutine,队列中的 PVC 按顺序被处理。
- 更新 status:2025-05-17 15:43:41.247
- 更新 status 完成:2025-05-17 15:43:41.267
- 更新 phase:2025-05-17 15:43:41.267
- 没有更新 phase 成功的打印
从日志可以看出,更新 phase 失败是因为 PV 资源在 volumeWorker 被修改了,所以只能下次重试。
“I0517 17:18:52.713016 1 pv_controller.go:1100] [test][2025-05-17 17:18:52.713] update phase of pvc default/pvc-324 error: Operation cannot be fulfilled on persistentvolumes "pv-324": the object has been modified; please apply your changes to the latest version and try again
- resync:2025-05-17 15:43:51.349
- KCM 开始绑定:2025-05-17 15:44:02.542
这里可以看到,从收到 add 事件,到 KCM 绑定成功,中间等待的时间为:37s
- Kcm 更新 status:2025-05-17 15:44:02.542
- Kcm 更新 status 完成:2025-05-17 15:44:02.542
- Kcm 更新 phase:2025-05-17 15:44:02.542
- Kcm 更新 phase 完成:2025-05-17 15:44:02.542
- Kcm 绑定完成:2025-05-17 15:44:02.542
更新 status 和 phase 本身花的时间不多。
总结
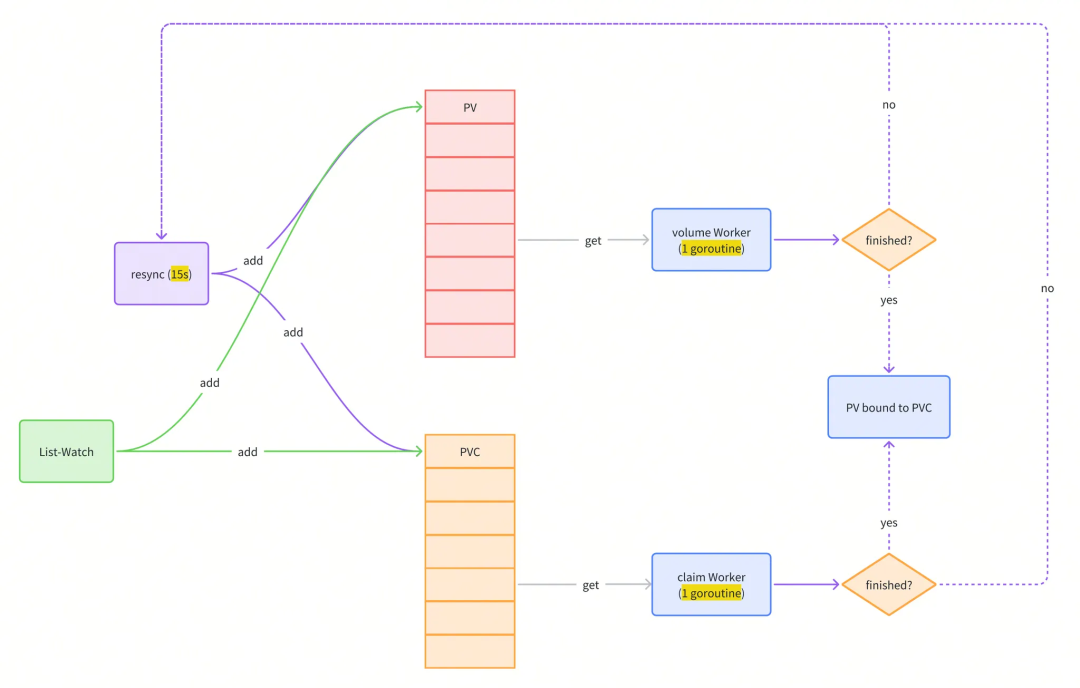
PVC/PV 资源从创建到绑定的时间包括以下部分:
- KCM 收到 Add 事件并且加入队列:集群没瓶颈时,很快。
- KCM 开始处理:和队列中的 PV/PVC 数量有关。PV 和 PVC 分别有个 worker,并且都只有单个 Goroutine,每秒执行一次,依次取出队列中的元素进行处理。队列中等待被处理的 PV/PVC 很多时,处理某个 PV/PVC 的等待时间比较长。社区没有用多个 GoRoutine 是因为多个 worker 同时处理可能导致单个 PV 绑定到多个 PVC 或单个 PVC 绑定到多个 PV 的情况。
- KCM 更新 PV phase 失败:需要等下次 resync,默认最长时间 15s。由于 PV 和 PVC 是并行处理的,KCM 在绑定 PVC 的时候会修改 PV 的 ClaimRef 信息,如果 PV 对象的内容和更新前的内容相比发生了变化,会报错。
- KCM 再次处理:和队列中的 PV/PVC 数量有关。
优化方案
- 调整 --pvclaimbinder-sync-period,减少重新入队的等待时间;能够优化部分体感明显创建慢的 Pod;
- 优点:改动较小,能够有收益;
- 缺点:对于 PVC 特别多的场景,效果比较有限;
- 调整业务使用 PV 的方式,提前申请一部分 PV,绑定到 PVC,然后通过 webhook 给 Pod 添加可用的空闲 PVC,跳过 bind 过程;
- 优点:效果比较明显,相当于做了 PV 的池化;
- 缺点:需要业务层面适配;
- 调整业务使用 PV 的方式,PV 指定文件系统根目录,业务 Pod 挂载时通过 volumeMounts 指定 subpath,避免每个 Pod 都走一遍 PV/PVC 绑定过程;
- 优点:效果明显,相当于对于同一个后端存储,只需进行 1 次 PV/PVC 绑定;
- 缺点:需要业务层面适配,多个业务 Pod 共用同一个客户端,可能引入性能问题。
参考资料
[1]
kubernetes/kubernetes/pull/26414: https://github.com/kubernetes/kubernetes/pull/26414
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号