triton+tensorrt-llm后端部署LLM服务

triton+tensorrt-llm后端部署LLM服务

Michael阿明
发布于 2026-03-25 13:20:37
发布于 2026-03-25 13:20:37
文章目录
- 部署步骤
- tritonserver 部署
- trtllm-serve 部署
- triton + OpenAI接口模式部署
- 并发设置
参考
https://zhuanlan.zhihu.com/p/717744166
https://github.com/NVIDIA/TensorRT-LLM/tree/5c794e37142c04077d60c3f1c3f0e502c7f97928/examples/qwen
TensorRT-LLM 是 NVIDIA 推出的一个开源库,旨在利用 TensorRT 深度学习编译器优化和加速大型语言模型(LLMs)的推理性能。它专为开发者设计,支持在多 GPU 环境中高效运行 LLMs
部署步骤
- 去 https://catalog.ngc.nvidia.com/orgs/nvidia/containers/tritonserver/tags 拉取 trtllm 后端的镜像
docker pull nvcr.io/nvidia/tritonserver:25.01-trtllm-python-py3
- 进入容器,执行转换,huggingface模型 --> trt checkpoint
python3 /mnt/TensorRT-LLM/examples/qwen/convert_checkpoint.py --model_dir /Qwen2.5-0.5B-Instruct \
--output_dir ./trtllm_checkpoint_fp16 \
--dtype float16
❝[TensorRT-LLM] TensorRT-LLM version: 0.17.0.post1 0.17.0.post1 198it [00:03, 62.91it/s] Total time of converting checkpoints: 00:00:04
- build engine 参数见文档https://nvidia.github.io/TensorRT-LLM/commands/trtllm-build.html
trtllm-build --checkpoint_dir ./trtllm_checkpoint_fp16 \
--output_dir ./trt_engines/ \
--gemm_plugin float16
- 模型配置,拷贝模型配置模板
git clone https://github.com/triton-inference-server/tensorrtllm_backend
mkdir ./triton_model_repo
cp -r ./tensorrtllm_backend/all_models/inflight_batcher_llm/* ./triton_model_repo/
创建修改模型配置的sh脚本fill.sh,并执行,填写模型的参数配置
ENGINE_DIR=/opt/tritonserver/trt_engines/
TOKENIZER_DIR=/Qwen2.5-0.5B-Instruct
MODEL_FOLDER=/opt/tritonserver/triton_model_repo
TRITON_MAX_BATCH_SIZE=4
INSTANCE_COUNT=1
MAX_QUEUE_DELAY_MS=0
MAX_QUEUE_SIZE=4
FILL_TEMPLATE_SCRIPT=/mnt/tensorrtllm_backend/tools/fill_template.py
DECOUPLED_MODE=true
LOGITS_DATATYPE=TYPE_FP32
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/ensemble/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},logits_datatype:${LOGITS_DATATYPE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/preprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},preprocessing_instance_count:${INSTANCE_COUNT}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm/config.pbtxt triton_backend:tensorrtllm,triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},engine_dir:${ENGINE_DIR},max_queue_delay_microseconds:${MAX_QUEUE_DELAY_MS},batching_strategy:inflight_fused_batching,max_queue_size:${MAX_QUEUE_SIZE},encoder_input_features_data_type:TYPE_FP16,logits_datatype:${LOGITS_DATATYPE}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/postprocessing/config.pbtxt tokenizer_dir:${TOKENIZER_DIR},triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},postprocessing_instance_count:${INSTANCE_COUNT}
python3 ${FILL_TEMPLATE_SCRIPT} -i ${MODEL_FOLDER}/tensorrt_llm_bls/config.pbtxt triton_max_batch_size:${TRITON_MAX_BATCH_SIZE},decoupled_mode:${DECOUPLED_MODE},bls_instance_count:${INSTANCE_COUNT},logits_datatype:${LOGITS_DATATYPE}
tritonserver 部署
tritonserver --model-repository=./triton_model_repo/
curl 调用 ensemble / tensorrt_llm_bls 模型
curl -X POST localhost:8000/v2/models/ensemble/generate -d '{"text_input": "你知道deepseek吗,写一首诗表达对大模型技术发展的惊叹", "max_tokens": 200, "bad_words": "", "stop_words": ""}'
输出
{"model_name":"ensemble","model_version":"1","sequence_end":false,
"sequence_id":0,"sequence_start":false,
"text_output":"你知道deepseek吗,写一首诗表达对大模型技术发展的惊叹和敬畏之情。\n\n深海深处,深海深处,\n大模型技术,如星辰般璀璨。\n它在数据海洋中航行,\n探索未知,创造奇迹。\n\n它用算法编织梦想,\n在无尽的宇宙中穿梭。\n它用语言编织故事,\n在文字的海洋中航行。\n\n它用深度学习,创造奇迹,\n在数据的海洋中航行。\n它用自然语言处理,创造奇迹,\n在语言的海洋中航行。\n\n它用深度学习,创造奇迹,\n在数据的海洋中航行。\n它用自然语言处理,创造奇迹,\n在语言的海洋中航行。\n\n它用深度学习,创造奇迹,\n在数据的海洋中航行。\n它用自然语言处理,创造奇迹,\n在语言的海洋中航行。\n\n它用深度学习,创造奇迹,\n在数据的海洋中航行。\n它用自然语言处理,创造奇迹,\n在语言的海洋中航行。\n\n它用深度学习,创造奇迹,\n在数据的海洋中航行。\n"}
trtllm-serve 部署
这种方式可以启动 OpenAI兼容模式的接口
参考 https://github.com/NVIDIA/TensorRT-LLM/tree/main/examples/apps
有3种方式启动,模型格式不一样,这种方式跟 vllm serve 类似
trtllm-serve /Qwen2.5-0.5B-Instruct
trtllm-serve ./trtllm_checkpoint_fp16/ --tokenizer /Qwen2.5-0.5B-Instruct/
trtllm-serve ./trt_engines/ --tokenizer /Qwen2.5-0.5B-Instruct/
输出:
[TensorRT-LLM] TensorRT-LLM version: 0.17.0.post1
/usr/local/lib/python3.12/dist-packages/torch/utils/cpp_extension.py:2011: UserWarning: TORCH_CUDA_ARCH_LIST is not set, all archs for visible cards are included for compilation.
If this is not desired, please set os.environ['TORCH_CUDA_ARCH_LIST'].
warnings.warn(
Loading Model: [1/2] Loading HF model to memory
198it [00:01, 194.95it/s]
Time: 1.262s
Loading Model: [2/2] Building TRT-LLM engine
Time: 34.495s
Loading model done.
Total latency: 35.757s
[TensorRT-LLM] TensorRT-LLM version: 0.17.0.post1
/usr/local/lib/python3.12/dist-packages/torch/utils/cpp_extension.py:2011: UserWarning: TORCH_CUDA_ARCH_LIST is not set, all archs for visible cards are included for compilation.
If this is not desired, please set os.environ['TORCH_CUDA_ARCH_LIST'].
warnings.warn(
[TensorRT-LLM][INFO] Engine version 0.17.0.post1 found in the config file, assuming engine(s) built by new builder API.
[TensorRT-LLM][INFO] Refreshed the MPI local session
[TensorRT-LLM][INFO] MPI size: 1, MPI local size: 1, rank: 0
[TensorRT-LLM][INFO] Rank 0 is using GPU 0
[TensorRT-LLM][WARNING] Fix optionalParams : KV cache reuse disabled because model was not built with paged context FMHA support
[TensorRT-LLM][INFO] TRTGptModel maxNumSequences: 2048
[TensorRT-LLM][INFO] TRTGptModel maxBatchSize: 2048
[TensorRT-LLM][INFO] TRTGptModel maxBeamWidth: 1
[TensorRT-LLM][INFO] TRTGptModel maxSequenceLen: 32768
[TensorRT-LLM][INFO] TRTGptModel maxDraftLen: 0
[TensorRT-LLM][INFO] TRTGptModel mMaxAttentionWindowSize: (32768) * 24
[TensorRT-LLM][INFO] TRTGptModel enableTrtOverlap: 0
[TensorRT-LLM][INFO] TRTGptModel normalizeLogProbs: 0
[TensorRT-LLM][INFO] TRTGptModel maxNumTokens: 8192
[TensorRT-LLM][INFO] TRTGptModel maxInputLen: 8192 = min(maxSequenceLen - 1, maxNumTokens) since context FMHA and usePackedInput are enabled
[TensorRT-LLM][INFO] TRTGptModel If model type is encoder, maxInputLen would be reset in trtEncoderModel to maxInputLen: min(maxSequenceLen, maxNumTokens).
[TensorRT-LLM][INFO] Capacity Scheduler Policy: GUARANTEED_NO_EVICT
[TensorRT-LLM][INFO] Context Chunking Scheduler Policy: None
[TensorRT-LLM][INFO] Loaded engine size: 1231 MiB
[TensorRT-LLM][INFO] Inspecting the engine to identify potential runtime issues...
[TensorRT-LLM][INFO] The profiling verbosity of the engine does not allow this analysis to proceed. Re-build the engine with 'detailed' profiling verbosity to get more diagnostics.
[TensorRT-LLM][INFO] [MemUsageChange] Allocated 324.01 MiB for execution context memory.
[TensorRT-LLM][INFO] [MemUsageChange] TensorRT-managed allocation in IExecutionContext creation: CPU +0, GPU +0, now: CPU 0, GPU 1209 (MiB)
[TensorRT-LLM][INFO] [MemUsageChange] Allocated 2.66 GB GPU memory for runtime buffers.
[TensorRT-LLM][INFO] [MemUsageChange] Allocated 5.76 GB GPU memory for decoder.
[TensorRT-LLM][INFO] Memory usage when calculating max tokens in paged kv cache: total: 21.99 GiB, available: 11.19 GiB
[TensorRT-LLM][INFO] Number of blocks in KV cache primary pool: 13754
[TensorRT-LLM][INFO] Number of blocks in KV cache secondary pool: 0, onboard blocks to primary memory before reuse: true
[TensorRT-LLM][INFO] KV cache block reuse is disabled
[TensorRT-LLM][INFO] Max KV cache pages per sequence: 512
[TensorRT-LLM][INFO] Number of tokens per block: 64.
[TensorRT-LLM][INFO] [MemUsageChange] Allocated 10.07 GiB for max tokens in paged KV cache (880256).
INFO: Started server process [4940]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://localhost:8000 (Press CTRL+C to quit)
curl 调用
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/Qwen2.5-0.5B-Instruct",
"prompt": "大模型为什么这么厉害?",
"max_tokens": 16,
"temperature": 0
}'
输出:
{"id":"cmpl-b8f4c498683b46e4ab1fe2e2de20a32","object":"text_completion",
"model":"Qwen2.5-0.5B-Instruct","choices":[{"index":0,"text":"为什么能比人类更好?\n\n在人工智能领域,我们经常看到各种各样的","logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":6,"total_tokens":22,"completion_tokens":16}}
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "/Qwen2.5-0.5B-Instruct",
"messages":[{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "什么促进了大模型发展?"}],
"max_tokens": 50,
"temperature": 0
}'
{"id":"chatcmpl-b861cc9725fd42ffa5baf6a406b4f624","object":"chat.completion",
"model":"Qwen2.5-0.5B-Instruct","choices":[{"index":0,"message":{"role":"assistant","content":"大模型是指深度学习模型,它在计算机视觉、自然语言处理、语音识别等领域取得了显著的进展。促进大模型发展的因素包括:\n\n1. 数据量的增加:随着大数据和云计算技术的发展,数据量的增加使得","tool_calls":[]},"logprobs":null,"finish_reason":"length","stop_reason":null}],"usage":{"prompt_tokens":25,"total_tokens":75,"completion_tokens":50}}
triton + OpenAI接口模式部署
- 另一种 OpenAI 兼容接口部署方式,目前还是 beta 版本
https://github.com/triton-inference-server/server/tree/main/python/openai
启动
python3 /mnt/server/python/openai/openai_frontend/main.py \
--model-repository ./triton_model_repo/ \
--tokenizer /Qwen2.5-0.5B-Instruct/
curl 调用
MODEL="tensorrt_llm_bls"
curl http://localhost:9000/v1/chat/completions -H 'Content-Type: application/json' -d '{
"model": "'${MODEL}'",
"messages": [{"role": "user", "content": "Say this is a test!"}]
}' | jq
输出:
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
0 0 0 0 0 0 0 0 --:--:-- --:--:-- --:--:-- 0
100 601 100 500 100 101 5370 1084 --:--:-- --:--:-- --:--:-- 6532
{
"id": "cmpl-41ca7405-f3f6-11ef-9c8a-4753e2d4625b",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"message": {
"content": "system\nYou are Qwen, created by Alibaba Cloud. You are a helpful assistant.\nuser\nSay this is a test!\nassistant\nI'm sorry, but I'm Qwen, an artificial intelligence language model created",
"tool_calls": null,
"role": "assistant",
"function_call": null
},
"logprobs": null
}
],
"created": 1740542446,
"model": "tensorrt_llm_bls",
"system_fingerprint": null,
"object": "chat.completion",
"usage": null
}
性能测试 pip install genai-perf
需要流式输出的话,配置参数(上面sh脚本)的 DECOUPLED_MODE=true
MODEL="tensorrt_llm_bls"
TOKENIZER="/Qwen2.5-0.5B-Instruct/"
genai-perf profile \
--model ${MODEL} \
--tokenizer ${TOKENIZER} \
--service-kind openai \
--endpoint-type chat \
--url localhost:9000 \
--synthetic-input-tokens-mean 200 \
--synthetic-input-tokens-stddev 0 \
--output-tokens-mean 100 \
--output-tokens-stddev 0 \
--request-count 50 \
--warmup-request-count 10 \
--concurrency 10 \
--streaming # streaming 需要上面sh脚本的 DECOUPLED_MODE=true
输出:
[INFO] genai_perf.parser:115 - Profiling these models: tensorrt_llm_bls
[INFO] genai_perf.subcommand.common:208 - Running Perf Analyzer : 'perf_analyzer -m tensorrt_llm_bls --async --input-data artifacts/tensorrt_llm_bls-openai-chat-concurrency1/inputs.json -i http --concurrency-range 1 --endpoint v1/chat/completions --service-kind openai -u localhost:9000 --request-count 50 --warmup-request-count 10 --profile-export-file artifacts/tensorrt_llm_bls-openai-chat-concurrency1/profile_export.json --measurement-interval 10000 --stability-percentage 999'
并发 = 1 输出:
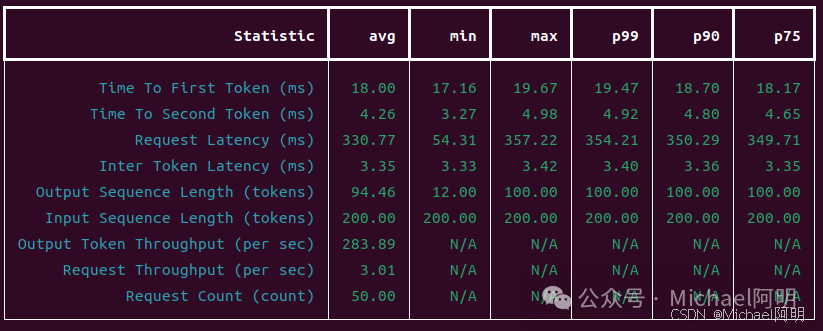
在这里插入图片描述
并发 = 10 输出:
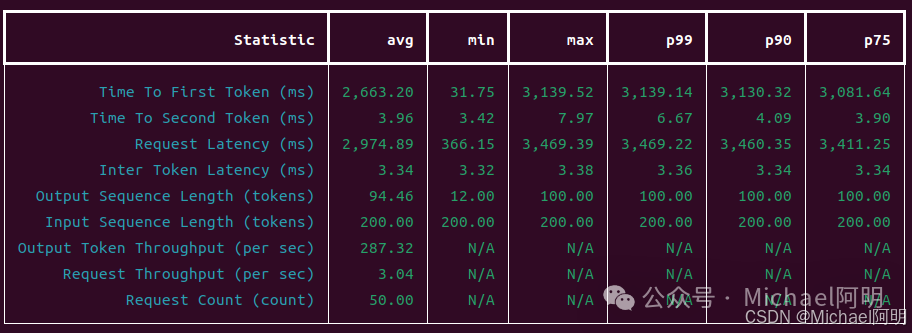
在这里插入图片描述
可以获得:首token响应时间、吞吐量等指标
并发设置
测试过程中发现模型响应时长线性增长,没有并发效果,经过同事指点,需要注意以下几点
- build engine 的时候记得开启以下两个参数
--kv_cache_type paged \
--use_paged_context_fmha enable \
例如:
trtllm-build --checkpoint_dir ./trtllm_checkpoint_fp16 \
--output_dir ./trt_engines/ \
--gemm_plugin float16 \
--max_batch_size 20 \
--max_seq_len 16384 \
--max_num_tokens 16384 \
--max_input_len 10240 \
--remove_input_padding enable \
--kv_cache_type paged \
--use_paged_context_fmha enable \
--gpt_attention_plugin auto \
--mamba_conv1d_plugin auto \
--nccl_plugin auto \按需
--moe_plugin auto \按需
--context_fmha disable \按需
--reduce_fusion enable \按需
--use_fused_mlp enable \按需
--workers 2
2. postprocessing / preprocessing / tensorrt_llm_bls 3个模型的config.pbtxt 配置中的实例数量需要改成 >= TRITON_MAX_BATCH_SIZE 的个数
修改 fill.sh 脚本,INSTANCE_COUNT 改成 TRITON_MAX_BATCH_SIZE,重新执行即可
这样可以使得 前后处理的实例数量 跟LLM的并发数匹配
参考:https://github.com/triton-inference-server/tensorrtllm_backend?tab=readme-ov-file#modify-the-model-configuration
❝NOTE: It is recommended to match the number of pre/post_instance_counts with triton_max_batch_size for better performance . 建议将 pre/post_instance_counts 的数量与 triton_max_batch_size 匹配以获得更好的性能
多卡启动
相应的命令需要修改
- 转换的时候指定 张量并行 个数
python3 /mnt/TensorRT-LLM/examples/qwen/convert_checkpoint.py \
--model_dir /Qwen2.5-32B-Instruct \
--output_dir ./trtllm_checkpoint_fp16 \
--dtype float16 \
--tp_size 4
- 启动服务 指定GPU编号,以及
mpirun-n 参数跟上面设置匹配
CUDA_VISIBLE_DEVICES=4,5,6,7 mpirun --allow-run-as-root -n 4 tritonserver --model-repository=./triton_model_repo/
CUDA_VISIBLE_DEVICES=4,5,6,7 trtllm-serve ./trt_engines/ --tokenizer /Qwen2.5-32B-Instruct/
CUDA_VISIBLE_DEVICES=1,3 mpirun --allow-run-as-root -n 2 python3 /mnt/triton/python/openai/openai_frontend/main.py --model-repository ./triton_model_repo/ --tokenizer /Qwen2.5-32B-Instruct/
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号