Langchain4j简单玩法


今天和小伙伴们分享一下使用 langchain4j 快速搭建一个 RAG 应用。
前面松哥和大家聊了什么是 RAG,以及 RAG 开发所涉及到的技术栈。
前面几篇文章涉及到技术的,松哥都是使用 Python 来演示的,今天我们回归到自己的大本营,拿出我们的看家本领 Java,一起来简单的玩一下 langchain4j。
一 RAG
1.1 为什么需要RAG
大语言模型(如 ChatGPT)的知识储备截止于训练数据,无法主动获取新信息。当遇到以下场景时,我们需要 RAG 技术:
- 专业领域知识(如医疗诊断、法律条款)
- 实时动态数据(如最新股票行情)
- 企业私密数据(如内部产品文档)
1.2 RAG是什么
开卷考试式的知识增强。
RAG(检索增强生成) 就像给模型一本“参考书”,在回答问题前自动查找相关知识,再结合这些信息生成答案。这种方法能显著减少模型“瞎编乱造”的问题。
核心流程:
- 索引阶段(考前划重点)
- 预处理文档:清理、分段、转化为向量存入数据库
- 就像把课本知识点做成小卡片,方便快速查找
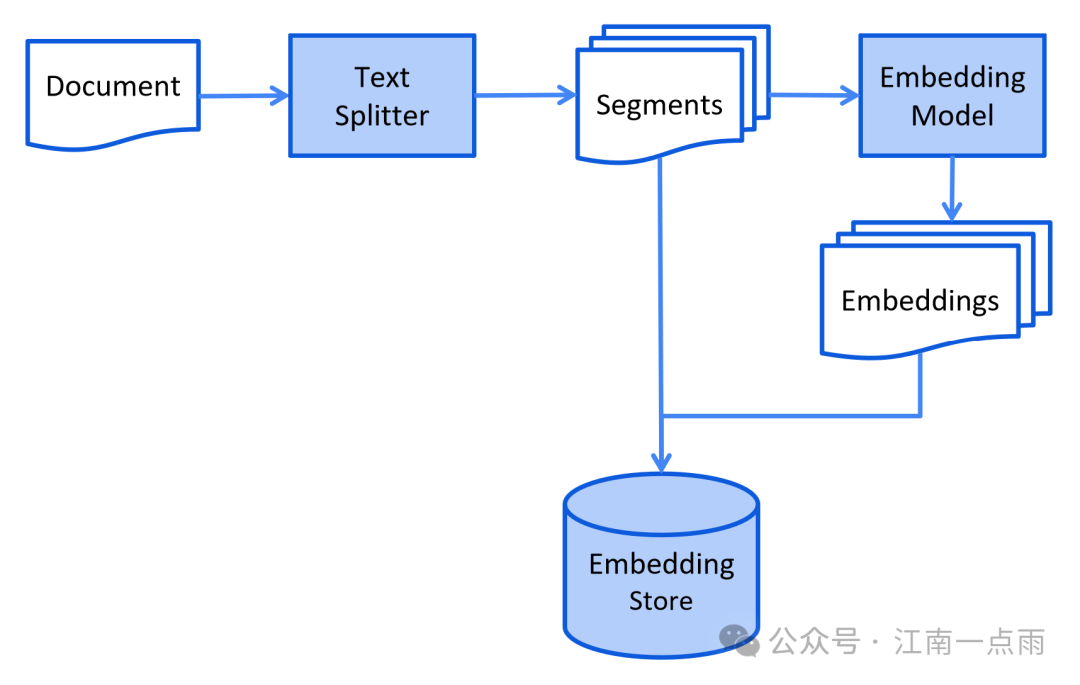
- 检索阶段(考试时查资料)
- 用户提问时,将问题转为向量,从数据库找到最相关的内容
- 把这些内容拼接到问题中,让模型参考作答
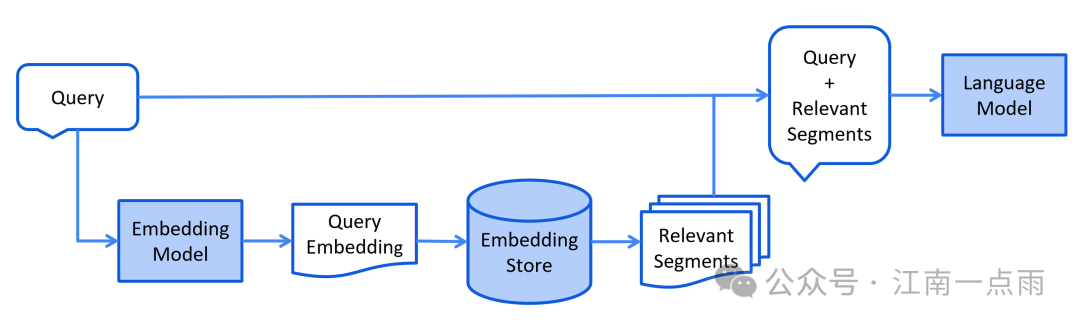
1.3 三种检索方式对比
方式 | 原理 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|---|
关键词检索 | 匹配关键词(如百度搜索) | 速度快 | 无法理解语义 | 简单问题 |
向量检索 | 通过语义相似度查找(如找近义词) | 理解深层含义 | 需要算力支持 | 复杂语义问题 |
混合检索 | 结合前两种方式 | 查全率高 | 实现复杂 | 专业领域问答 |
例如问“苹果新品”,关键词检索会找含“苹果”的文档,而向量检索能识别“iPhone发布”相关内容。
1.4 技术实现关键点
- 文档预处理 • 文件类型处理:支持 PDF/Word/网页等格式解析 • 智能分段:避免把完整句子切碎(如按段落拆分)
- 向量数据库选择 • 常用工具:Pinecone(云端)、FAISS(本地) • 维度选择:OpenAI 的 text-embedding-ada-002 模型使用 1536 维向量
- 结果优化 • 相关性过滤:设置相似度阈值(如 0.7 以上才采用) • 重排序机制:对初步结果二次筛选
1.5 RAG vs 微调模型
维度 | RAG | 微调 |
|---|---|---|
数据时效性 | 实时更新 | 依赖训练数据 |
实施难度 | 较低 | 需要标注数据 |
数据安全 | 知识不外泄 | 需上传数据 |
成本 | 较低 | 训练费用高 |
在企业应用中,我们可以将两者结合:用RAG处理动态知识,微调优化回答风格
RAG 相当于给 AI 装了个“实时知识库”,让它既能保持通用智能,又具备专业领域的精准回答能力。这种技术已应用于智能客服(如银行业务咨询)、医疗问答系统等多个场景。
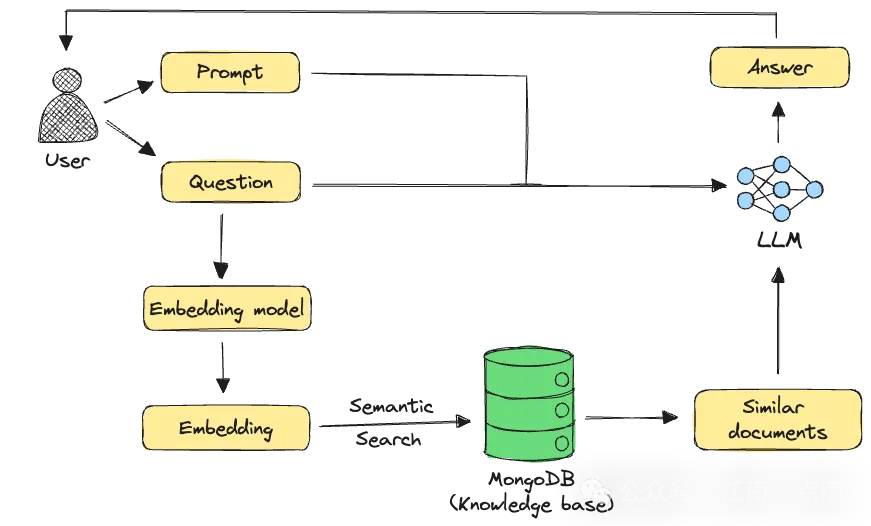
二 langchain4j RAG
langchain4j 提供了三种构建 RAG 应用的方案,分别是:
- Easy RAG
- Native RAG
- Advanced RAG
我们分别来介绍下。
2.1 Easy RAG
- 核心特点:全自动化流程,无需配置即可实现文档解析、分块和嵌入
- 适用场景:快速验证概念、小型项目原型、新手学习
- 技术实现:
• 自动文档解析(支持 PDF/TXT/Word 等格式)
• 默认分块策略(300 字符固定长度,30 字符重叠)
• 内置轻量级嵌入模型(如
bge-small-en-v1.5) • 内存型向量存储(InMemoryEmbeddingStore)
代码示例:
// 加载文档并自动处理
List<Document> docs = FileSystemDocumentLoader.loadDocuments("/Users/youyou/javaboy/doc",new PDFDocumentParser());
EmbeddingStore<TextSegment> store = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(docs, store); // 自动分块+嵌入
InMemoryEmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>();
EmbeddingStoreIngestor.ingest(docs, embeddingStore);
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
.apiKey(API_KEY)
.model("glm-4")
.temperature(0.6)
.maxToken(1024)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.chatMemory(MessageWindowChatMemory.withMaxMessages(10))
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
String answer = assistant.answer("江南一点雨为什么选择做开发?");
System.out.println("answer = " + answer);
优势:10 分钟内完成部署,适合验证性需求 局限:无法调整分块策略或更换嵌入模型
2.2 Native RAG
核心特点:灵活配置各组件,适配中等复杂度需求 适用场景:企业知识库、需定制分块规则的项目 可调参数: • 分块策略(按段落/句子/固定长度) • 嵌入模型(支持本地 ONNX 或云端 API) • 向量存储类型(Redis/Pinecone/Elasticsearch/Milvus 等)
代码示例:
//1.读取文件
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler bodyContentHandler = new BodyContentHandler();
parser.parse(new FileInputStream("/Users/youyou/Desktop/jianying/松哥/思否有约访谈提纲 - 江南一点雨.docx"), bodyContentHandler, new Metadata());
Document document = Document.from(bodyContentHandler.toString());
//2.文件切分
DocumentByParagraphSplitter splitter = new DocumentByParagraphSplitter(150, 50);
List<TextSegment> textSegments = splitter.split(document);
//3.文件向量化
ZhipuAiEmbeddingModel embeddingModel = ZhipuAiEmbeddingModel.builder()
.apiKey(API_KEY)
.logRequests(true)
.logResponses(true)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Response<List<Embedding>> embedded = embeddingModel.embedAll(textSegments);
//4.向量存储
MilvusEmbeddingStore store = MilvusEmbeddingStore.builder()
.host("localhost")
.port(19530)
.collectionName("javaboy_collection_data_3")
.dimension(1024)
.indexType(IndexType.FLAT)
.metricType(MetricType.COSINE)
.username("username")
.password("password")
.consistencyLevel(ConsistencyLevelEnum.EVENTUALLY)
.autoFlushOnInsert(true)
.idFieldName("id")
.textFieldName("text")
.metadataFieldName("metadata")
.vectorFieldName("vector")
.build();
store.addAll(embedded.content(), textSegments);
//5. 搜索
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(store)
.embeddingModel(embeddingModel)
.maxResults(2)
.minScore(0.5)
.build();
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
ChatLanguageModel chatModel = ZhipuAiChatModel.builder()
.apiKey(API_KEY)
.model("glm-4")
.temperature(0.6)
.maxToken(1024)
.maxRetries(1)
.callTimeout(Duration.ofSeconds(60))
.connectTimeout(Duration.ofSeconds(60))
.writeTimeout(Duration.ofSeconds(60))
.readTimeout(Duration.ofSeconds(60))
.build();
Assistant assistant = AiServices.builder(Assistant.class)
.chatLanguageModel(chatModel)
.contentRetriever(contentRetriever)
.chatMemory(chatMemory)
.build();
String answer = assistant.answer("江南一点雨为什么选择做开发?");
System.out.println("answer = " + answer);
优势:支持优化分块策略(如医疗报告按章节拆分) 局限:需自行管理组件兼容性
从上面的代码大家可以看出,Easy RAG 主要是简化了 Native RAG 中的 2、3、4 三个步骤。
2.3 Advanced RAG
来看下面一张图:
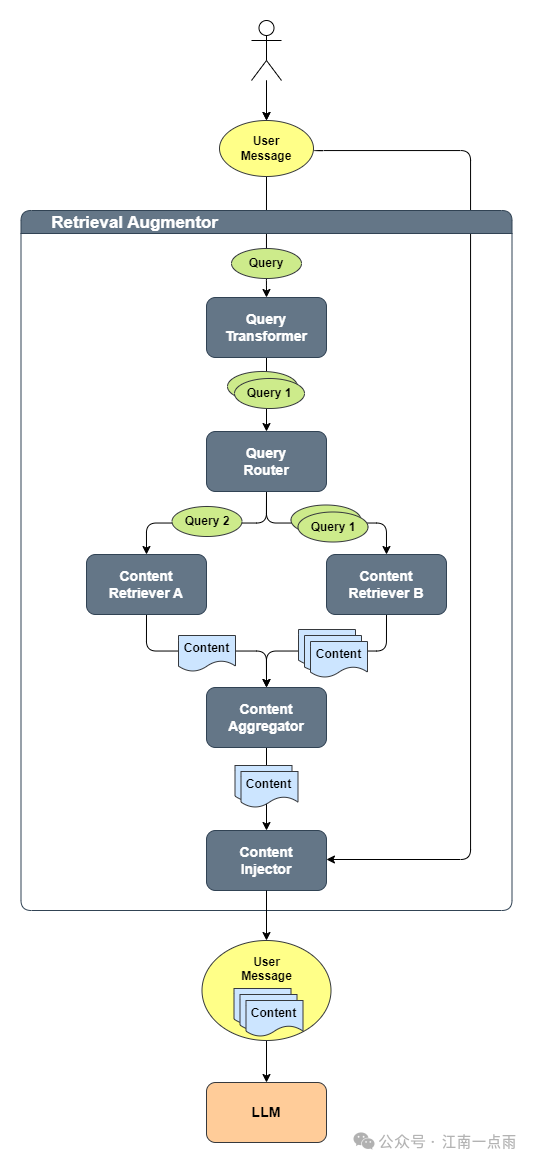
这个工作流程就像图书馆管理员帮你查资料的过程:
- 用户发起问题 你提出一个问题(比如"如何做糖醋排骨"),就像向图书馆员提出查阅需求。
- 问题加工处理 系统会将你的问题拆解成多个相关查询(如拆解为"糖醋排骨做法""火候控制技巧""酱料调配比例"),相当于图书馆员把复杂问题分解成多个检索关键词。
- 智能分配查询 每个加工后的查询会被智能分配到不同的检索渠道(类似图书馆员同时查纸质菜谱书、美食视频库、厨师论坛等不同资源库)。
- 多途径检索内容 每个渠道根据分配到的查询内容,查找相关度最高的信息片段(如图书馆员在不同资料库中找到对应的做法步骤、操作要点)。
- 整合检索结果 把从各个渠道找到的信息汇总排序,去除重复内容,按相关度高低排列(类似图书馆员把找到的菜谱步骤、视频要点、专业技巧整理成有序清单)。
- 组合信息与问题 将整理好的资料清单附加到原始问题中(相当于图书馆员把找到的资料复印件和你的原始问题装订在一起)。
- 生成最终回答 把组合好的完整资料包交给AI大模型,让它基于这些资料给出具体回答(就像图书馆员带着资料包去请教专业厨师,厨师结合资料给出详细指导)。
整个过程就像有个智能图书管理员,既会拆解复杂问题,又会多途径查资料,最后请专家基于资料写答案。这种方式比直接问专家更可靠,因为专家是看着真实资料作答的。
核心特点:支持复杂检索逻辑(混合搜索+重排序)
适用场景:金融风控、法律咨询等高精度需求场景 高级功能:
- 多路召回:同时使用向量/关键词/语义检索
- 查询路由:根据问题类型选择检索路径(如技术类用向量,通用类用关键词)
- 重排序机制:通过 RRF 算法优化结果排序
优势:召回率提升 30% 以上 局限:开发复杂度高,需理解检索算法原理
召回率表示 “系统实际检索到的相关文档数” 占 “数据库中所有相关文档总数” 的比例。 召回率的公式为:召回率 = 检索到的相关文档数(TP) / 所有相关文档总数(TP + FN) 其中:
- TP(真正例):正确检索到的相关文档
- FN(假负例):未被检索到的相关文档(漏检)
例如医疗诊断场景中,若实际有 100 个病例需检测,系统正确识别 70 个但漏掉 30 个,召回率为 70%。
Advanced RAG 这块涉及到的内容比较多,松哥后面再单独开文章和大家讲。
2.4 对比总结表

三 选型建议
• 测试 Demo 或内部工具 → Easy RAG • 企业知识库系统 → Native RAG • 金融/法律专业问答 → Advanced RAG
通过这种分层设计,LangChain4j 既能满足快速试错需求,又能支撑企业级复杂系统构建。开发者可根据项目阶段选择合适方案,后期也可从 Easy RAG 平滑升级到 Advanced RAG。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-03-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号