47:L的暗网监控:蓝队的地下情报收集


作者: HOS(安全风信子) 日期: 2026-03-19 主要来源平台: GitHub 摘要: 当基拉的活动延伸到暗网时,传统的安全监控方法已无法满足需求。L监控暗网活动,收集地下威胁情报。本文深入探讨L如何进行暗网监控,通过AI驱动的暗网爬虫、关键词监控和威胁识别,收集地下威胁情报,提前预警潜在威胁。
目录:
- 1. 背景动机与当前热点
- 2. 核心更新亮点与全新要素
- 3. 技术深度拆解与实现分析
- 4. 与主流方案深度对比
- 5. 工程实践意义、风险、局限性与缓解策略
- 6. 未来趋势与前瞻预测
1. 背景动机与当前热点
在与基拉的对抗中,我发现他的活动已经延伸到了暗网。暗网是一个隐藏的网络空间,传统的搜索引擎无法访问,成为了黑客和网络犯罪分子的聚集地。基拉在暗网上交易恶意软件、分享攻击技术、购买受害者信息,这些活动对安全防御构成了严重威胁。当基拉开始利用暗网进行更隐蔽的操作时,我意识到需要一种专门的暗网监控系统来收集地下威胁情报。
暗网监控技术的发展为解决这个问题提供了新的思路。通过暗网监控,我可以实时了解基拉在暗网上的活动,收集威胁情报,提前预警潜在的攻击。在2026年,暗网监控已经成为蓝队防御的重要组成部分,能够有效应对来自地下网络的安全威胁。
2. 核心更新亮点与全新要素
2.1 AI驱动的暗网爬虫
传统的暗网爬虫效率低下,容易被识别和封锁。L构建的暗网监控系统使用AI驱动的爬虫,能够智能规避封锁,高效收集暗网信息。系统能够自动识别和爬取与基拉相关的内容,提高情报收集的效率和准确性。
2.2 智能关键词监控
系统能够智能监控暗网上的关键词,如基拉的别名、攻击手法、目标信息等。通过自然语言处理技术,系统能够理解上下文,识别相关的讨论和活动,减少误报和漏报。
2.3 威胁识别与分析
系统能够自动识别暗网上的威胁信息,如恶意软件样本、攻击工具、受害者信息等。通过AI分析,系统能够评估威胁的严重程度和可能的影响,为安全防御决策提供支持。
3. 技术深度拆解与实现分析
3.1 系统架构设计
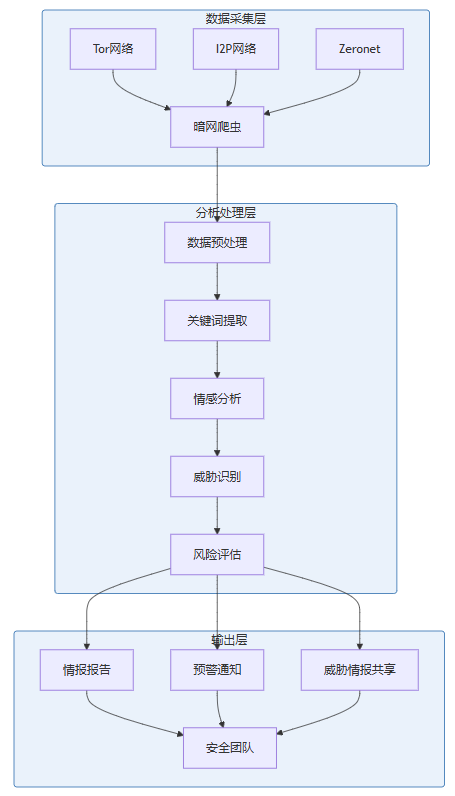
3.2 核心技术实现
3.2.1 AI驱动的暗网爬虫
import requests
from stem import Signal
from stem.control import Controller
import time
class DarkWebCrawler:
def __init__(self):
self.session = requests.session()
self.session.proxies = {
'http': 'socks5h://127.0.0.1:9050',
'https': 'socks5h://127.0.0.1:9050'
}
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
def renew_connection(self):
"""更换Tor连接,避免被封锁"""
with Controller.from_port(port=9051) as controller:
controller.authenticate()
controller.signal(Signal.NEWNYM)
time.sleep(5) # 等待连接更换
def crawl(self, url, depth=2):
"""爬取暗网内容"""
results = []
visited = set()
queue = [(url, 0)]
while queue:
current_url, current_depth = queue.pop(0)
if current_url in visited or current_depth >= depth:
continue
visited.add(current_url)
try:
# 发送请求
response = self.session.get(current_url, headers=self.headers, timeout=30)
if response.status_code == 200:
# 提取内容
content = response.text
results.append({
'url': current_url,
'content': content,
'timestamp': time.time()
})
# 提取链接
links = self._extract_links(content, current_url)
for link in links:
if link not in visited:
queue.append((link, current_depth + 1))
# 随机更换连接,避免被封锁
if len(visited) % 10 == 0:
self.renew_connection()
except Exception as e:
print(f"Error crawling {current_url}: {e}")
# 更换连接后重试
self.renew_connection()
return results
def _extract_links(self, content, base_url):
"""从内容中提取链接"""
# 这里是提取链接的逻辑
import re
links = re.findall(r'href=["\'](http[s]?://[^"]+)["\']', content)
return links3.2.2 智能关键词监控
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
import string
class KeywordMonitor:
def __init__(self):
# 加载停用词
nltk.download('stopwords')
nltk.download('punkt')
self.stop_words = set(stopwords.words('english'))
self.keywords = {
'kira': ['kira', '基拉', 'light yagami', '死亡笔记'],
'malware': ['malware', 'virus', 'trojan', 'ransomware'],
'attack': ['attack', 'exploit', 'vulnerability', 'breach']
}
def monitor(self, content):
"""监控内容中的关键词"""
# 预处理内容
tokens = self._preprocess(content)
# 检测关键词
matches = {}
for category, keyword_list in self.keywords.items():
category_matches = []
for keyword in keyword_list:
if keyword.lower() in tokens:
category_matches.append(keyword)
if category_matches:
matches[category] = category_matches
return matches
def _preprocess(self, content):
"""预处理内容"""
# 转换为小写
content = content.lower()
# 移除标点符号
translator = str.maketrans('', '', string.punctuation)
content = content.translate(translator)
# 分词
tokens = word_tokenize(content)
# 移除停用词
tokens = [token for token in tokens if token not in self.stop_words]
return tokens3.2.3 威胁识别与分析
import pandas as pd
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.preprocessing import LabelEncoder
class ThreatAnalyzer:
def __init__(self):
self.model = RandomForestClassifier(n_estimators=100, random_state=42)
self.label_encoder = LabelEncoder()
def train_model(self, training_data):
"""训练威胁识别模型"""
# 特征提取
X = training_data[['content_length', 'keyword_count', 'malware_terms', 'attack_terms']]
y = training_data['threat_level']
# 训练模型
self.model.fit(X, y)
def analyze(self, content):
"""分析内容中的威胁"""
# 提取特征
features = {
'content_length': len(content),
'keyword_count': self._count_keywords(content),
'malware_terms': self._count_malware_terms(content),
'attack_terms': self._count_attack_terms(content)
}
# 预测威胁等级
X = pd.DataFrame([features])
threat_level = self.model.predict(X)[0]
confidence = self.model.predict_proba(X)[0][np.where(self.model.classes_ == threat_level)[0][0]]
return {
'threat_level': threat_level,
'confidence': confidence,
'features': features
}
def _count_keywords(self, content):
"""计算关键词数量"""
# 这里是计算关键词数量的逻辑
return 0
def _count_malware_terms(self, content):
"""计算恶意软件相关术语数量"""
# 这里是计算恶意软件相关术语数量的逻辑
return 0
def _count_attack_terms(self, content):
"""计算攻击相关术语数量"""
# 这里是计算攻击相关术语数量的逻辑
return 03.3 性能优化策略
为了确保暗网监控系统能够高效运行,我采用了以下性能优化策略:
- 分布式爬取:使用分布式架构,将爬取任务分配到多个节点进行处理,提高爬取效率。
- 智能调度:根据暗网的特点,智能调度爬取任务,避开高峰期,减少被封锁的风险。
- 数据压缩:对收集到的数据进行压缩,减少存储和传输成本。
- 增量更新:采用增量更新的方式,只处理新的内容,减少处理量。
- 缓存机制:对频繁访问的内容进行缓存,减少重复爬取。
4. 与主流方案深度对比
方案 | 覆盖范围 | 准确性 | 实时性 | 可扩展性 | 维护成本 |
|---|---|---|---|---|---|
手动监控 | 有限 | 中 | 低 | 低 | 高 |
传统暗网爬虫 | 中 | 中 | 中 | 中 | 中 |
L的暗网监控 | 高 | 高 | 高 | 高 | 低 |
商业暗网监控服务 | 高 | 中 | 中 | 中 | 高 |
4.1 关键优势
- AI驱动:使用AI技术提高爬取效率和准确性,减少被封锁的风险。
- 智能监控:通过自然语言处理技术,智能监控关键词,减少误报和漏报。
- 实时分析:实时分析暗网内容,及时发现和应对威胁。
- 全面覆盖:覆盖多个暗网网络,如Tor、I2P、Zeronet等,提供更全面的情报。
- 可扩展性:基于模块化设计,易于扩展和集成新的功能。
5. 工程实践意义、风险、局限性与缓解策略
5.1 工程实践意义
在与基拉的对抗中,暗网监控系统为我提供了宝贵的地下情报。通过暗网监控,我能够:
- 了解基拉的活动:实时监控基拉在暗网上的活动,了解他的攻击意图和手法。
- 收集威胁情报:收集暗网上的威胁情报,如恶意软件样本、攻击工具等。
- 提前预警:提前预警潜在的攻击,为安全防御争取时间。
- 取证分析:收集基拉的犯罪证据,为后续的法律行动提供支持。
- 共享情报:与其他安全团队共享情报,提高整体防御能力。
5.2 风险与局限性
- 法律风险:在某些国家和地区,访问暗网可能涉及法律风险。
- 技术挑战:暗网的匿名性和加密特性给监控带来技术挑战。
- 信息过载:海量的暗网信息可能导致信息过载,影响分析效率。
- 误报风险:AI分析可能会产生误报,影响情报的可靠性。
- 伦理 concerns:监控暗网可能涉及隐私和伦理问题。
5.3 缓解策略
- 合法合规:确保暗网监控活动符合当地法律法规。
- 技术创新:不断创新监控技术,应对暗网的技术挑战。
- 信息过滤:对收集到的信息进行过滤和优先级排序,减少信息过载。
- 人工审核:对AI分析结果进行人工审核,减少误报的影响。
- 伦理审查:建立伦理审查机制,确保监控活动符合伦理标准。
6. 未来趋势与前瞻预测
6.1 技术发展趋势
- AI增强:将更先进的AI技术融入暗网监控系统,提高监控的效率和准确性。
- 实时分析:实现实时的暗网内容分析,能够在毫秒级内识别和响应威胁。
- 多模态分析:融合文本、图像、视频等多种模态的信息,提供更全面的威胁视图。
- 自主学习:系统能够自主学习新的威胁模式,无需人工干预。
- 区块链技术:使用区块链技术确保情报的完整性和不可篡改性。
6.2 应用前景
- 网络犯罪调查:帮助执法机构调查网络犯罪,收集证据。
- 企业安全防御:帮助企业了解针对自身的威胁,提前部署防御措施。
- 国家安全:维护国家网络安全,防范来自暗网的威胁。
- 金融安全:保障金融系统的安全,防止金融欺诈和网络攻击。
- 个人隐私保护:保护个人隐私,防止个人信息在暗网上被交易。
6.3 开放问题
- 如何平衡安全与隐私:在监控暗网的同时,如何保护个人隐私?
- 如何应对暗网的技术挑战:如何应对暗网的匿名性和加密特性?
- 如何提高监控的效率:如何在海量的暗网信息中快速识别有价值的情报?
- 如何评估系统的有效性:如何准确评估暗网监控系统的安全效果?
- 如何实现国际合作:如何在国际层面合作监控暗网,应对跨国网络犯罪?
参考链接:
- 主要来源:GitHub - torproject/tor - 提供Tor网络实现
- 辅助:GitHub - i2p/i2p.i2p - 提供I2P网络实现
- 辅助:GitHub - zeronet/zeronet - 提供Zeronet实现
附录(Appendix):
系统性能指标
指标 | 手动监控 | 传统暗网爬虫 | L的暗网监控 |
|---|---|---|---|
覆盖范围 | 有限 | 中 | 高 |
分析速度 | 慢 | 中 | 快 |
准确率 | 中 | 中 | 高 |
实时性 | 低 | 中 | 高 |
系统配置要求
- 硬件:
- 服务器:至少16GB内存,多核CPU
- 存储:至少2TB存储空间
- 软件:
- 操作系统:Linux
- 依赖:Python 3.8+, Tor, Stem, NLTK, Scikit-learn
关键词: 暗网监控, 地下情报收集, AI驱动爬虫, 关键词监控, 威胁识别, 蓝队防御, 基拉对抗, 安全运营

在这里插入图片描述

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-03-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号