Cursor AI模型实用性新标杆?Cursor 官方做了模型 PK 测评体系,AI编程能力竟然这样比出来!

Cursor AI模型实用性新标杆?Cursor 官方做了模型 PK 测评体系,AI编程能力竟然这样比出来!

程序视点
发布于 2026-03-30 15:41:26
发布于 2026-03-30 15:41:26
大家好!欢迎来到程序视点,我是你们的老朋友.安戈👋
前言
我最近盯上了一份很有分量的报告——Cursor 发布的内部评测体系 CursorBench。
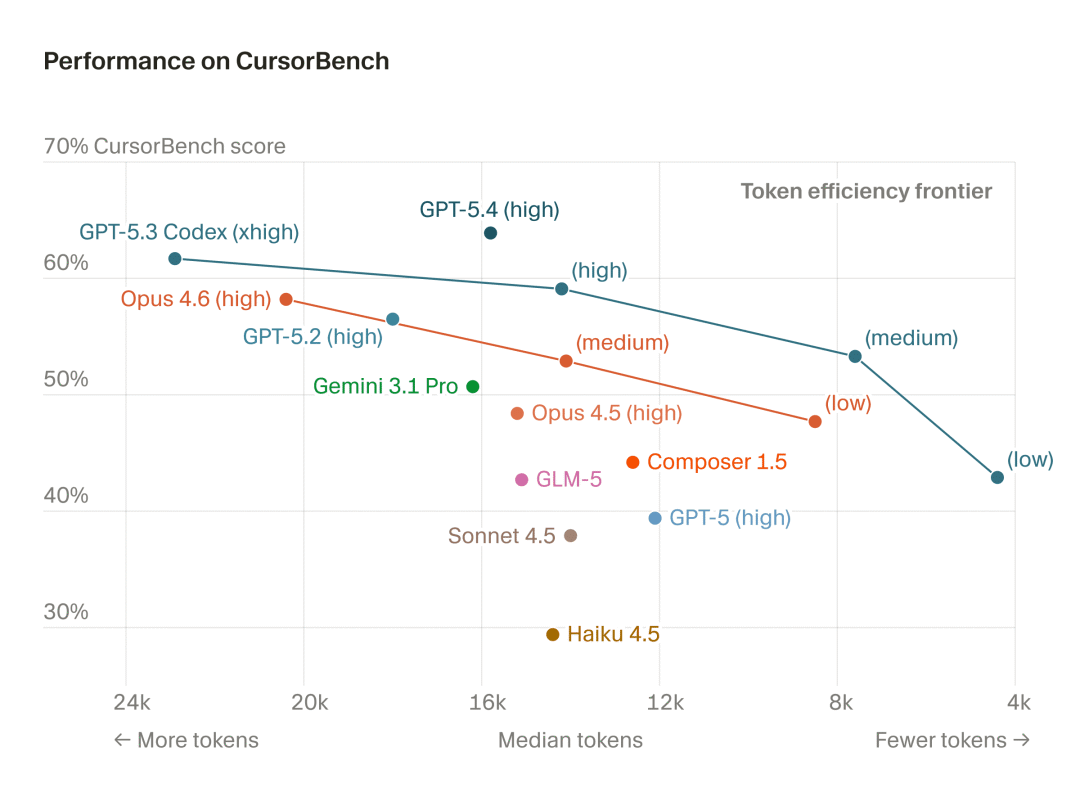
散点图展示了模型在 CursorBench 上的性能在完成 token 数和得分方面存在较大差异
CursorBench不是一串冷冰冰的分数,更像是一把“照妖镜”,直接照出各种 AI agent 真正的实力,甚至可以作为我们选Cursor AI 模型的“参考底牌”。
这种更贴近真实开发环境的测评基准,对于我们开发者来说,或许更具有参考意义!
真实开发环境下的评测,才叫“有数”
是不是已经用腻了那些一眼假大空的 benchmark 分数?我也是~
说实话,传统 benchmark 做得再漂亮,没法落地到实际开发流程,都是零。
可 CursorBench 不一样,这一套评测直接对标开发者日常:真实代码库、真实需求、真实 IDE 操作...全流程无缝还原得相当到位!
CursorBench 有点像开发者的体检报告,它结合了线上线下的评测流程——一方面用工程团队真实历史会话训练模型,另一方面也挑选了真实产品代码和需求作为测试任务。不再是公共代码仓库里的那些“老三样”,而是一线开发者真刀真枪干活时遇到的难题。
以前各种 benchmark,你测我测都图个好看。可是问题来了,模型在实际开发场景下老是掉链子,那分数再高也白搭。
CursorBench 拿开发者的真实业务场景揪模型短板,它评判不仅仅看代码写得对不对,还管效率、代码质量,甚至连交互行为也纳入考量。
官方的原话是:
We built CursorBench to measure multiple dimensions of agent performance including solution correctness, code quality, efficiency, and interaction behavior.
例如这里展示的是 CursorBench 中各个模型的性能关系结构图
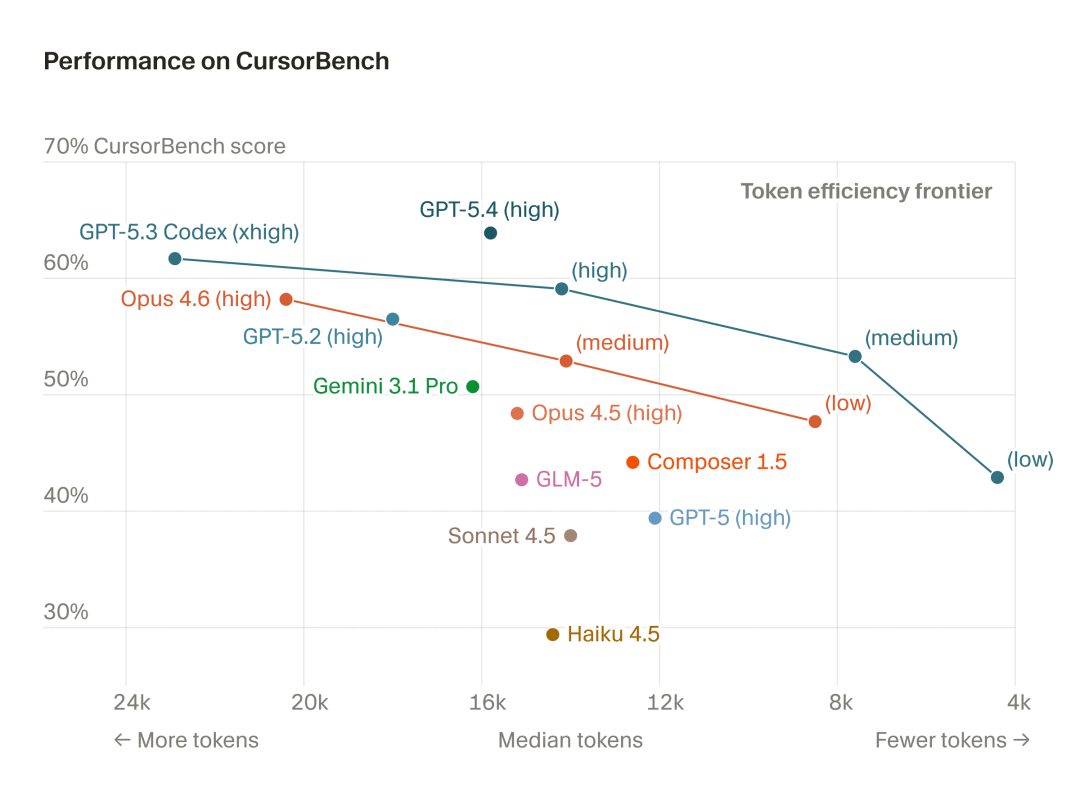
散点图展示了模型在 CursorBench 上的性能在完成 token 数和得分方面存在较大差异
此图表展示了正确性得分与完成所用 token 数中位数的关系,以捕捉影响可用性的算力/延迟权衡。右上角代表理想的智能体质量:以最低成本实现最高性能。
总归下来,就是越靠近 Token efficiency frontier 的越好。
打个比方,有的 benchmark 还在让 Agent 解谜题、下国际象棋,真遇上代码生态的复杂性就成了“纸老虎”。SWE-bench 虽然很火,但本质上还是自动验证来的 patch,和 IDE 场景完全两回事。
CursorBench 更像是 agent benchmark 里的“行业落地版”,主打的就是一种“接地气”,任务难度也升级了不少,涉及的代码行数、文件...都是高一个维度的。
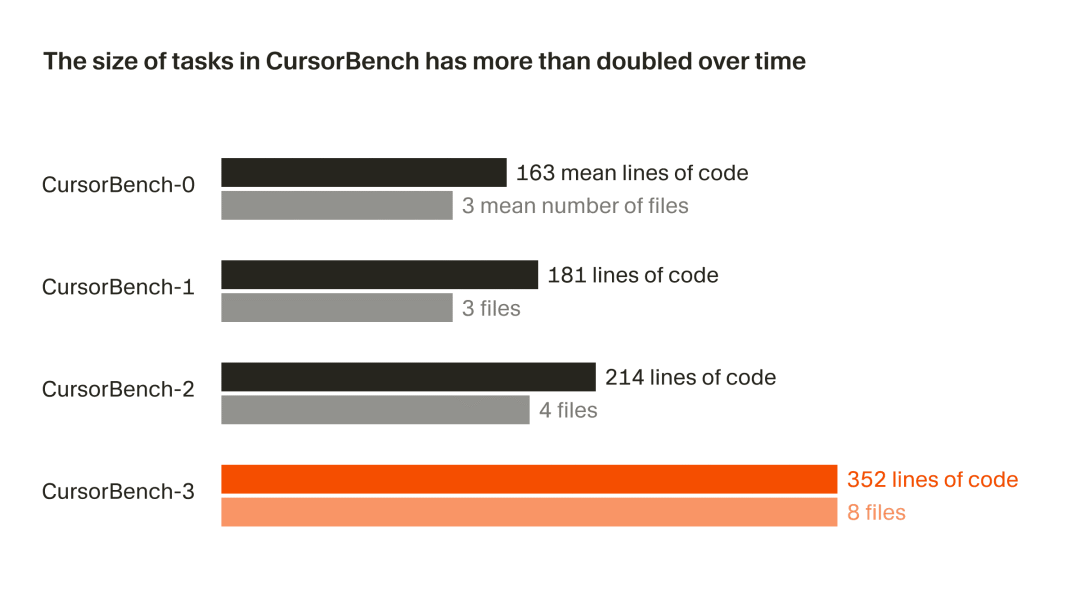
CursorBench 各版本中的编辑规模分布,显示问题规模从初始版本到 CursorBench Edit-v3 大致翻了一倍
比数据更重要的是背后的逻辑
再聊聊背后的深层逻辑。
你以为 AI 开发只拼模型吗?现在根本不是一个单纯“谁语言大模型参数多、推理快谁赢”的时代了,实际落地还得考虑 tools(工具链)、planner(任务规划)、memory(记忆管理)等协同工作。
比如同一个模型,在不同 agent 里的表现能差出 6 倍,原因就是 harness(执行环境)和模型的适配度。
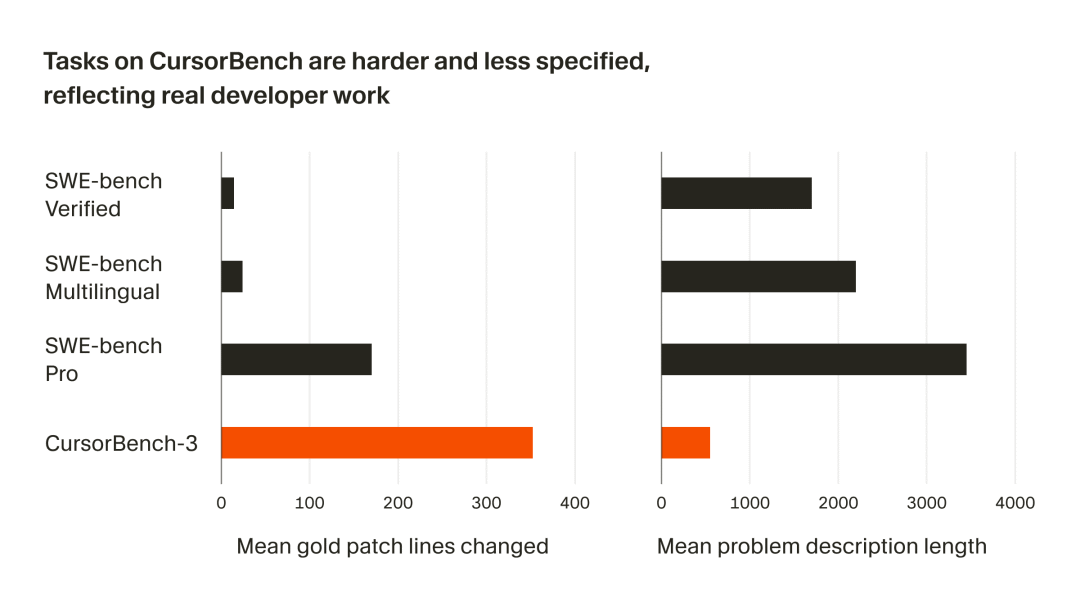
CursorBench 与公开基准任务特征对比:标准补丁代码行数和任务描述长度
你在 opencode 里用 Claude,不一定能体会到它的全部实力。但是在 Cursor 上,表现好不好,CursorBench 一测就全知道。
此外,CursorBench 还针对常见的“作弊行为”下了功夫,比如专门用 Cursor Blame 把代码生成和开发者请求一一对应,直接堵住模型“背代码”、“记答案”这些老路子。而且周期性更新任务套件,专治各种“投机取巧”。
Benchmark 越接近生产,才越有参考价值
很多开发者老在问 benchmark 到底有没有参考意义?
说白了,大部分公开的 benchmark 早就成了“猫鼠游戏”:你出题我背题,谁还拿不个高分?像 Terminal-Bench 这些甚至测解谜题,和实际开发八竿子打不着。
CursorBench 则是站在了“开发者视角”,哪怕是闭源的,但它代表了实际生产环境里的需求——比如在一个大规模多工作区的项目里,分析日志、拉通仓库、反复交互。这逻辑和我们实际工作一模一样。
对比下 SWE-bench,后者主要自动校验 issue/patch,对 context、交互等根本不关心。而 CursorBench 强调多轮交互、文件路径、涵盖 terminal、IDE 工具、上下文管理等综合维度,更全方位衡量 AI agent 的业务能力。
任务复杂度和前面说的这些差异,对基准测试的实用性产生的影响很大,比如在某些情况下,像 Haiku 这样的模型甚至可以达到或超过 GPT-5 的性能,但是对比右边 CursorBench 就结果就很明显了(看下图)。

与公开基准相比,CursorBench 在前沿水平上能更好地区分模型
排名与现实接轨,选什么看这里
最后还是要落地到大家最关心的:排名怎么用?
别迷信分数高低,CursorBench 的用法其实很现实:它证明了哪些模型在 Cursor 环境下更顺手,性价比高,而不是代表哪个模型在所有场景都无敌。
实际数据也证实,CursorBench 的排名和真实用户在线体验基本一致,线上表现高的 Agent,大概率在 CursorBench 里也数一数二。
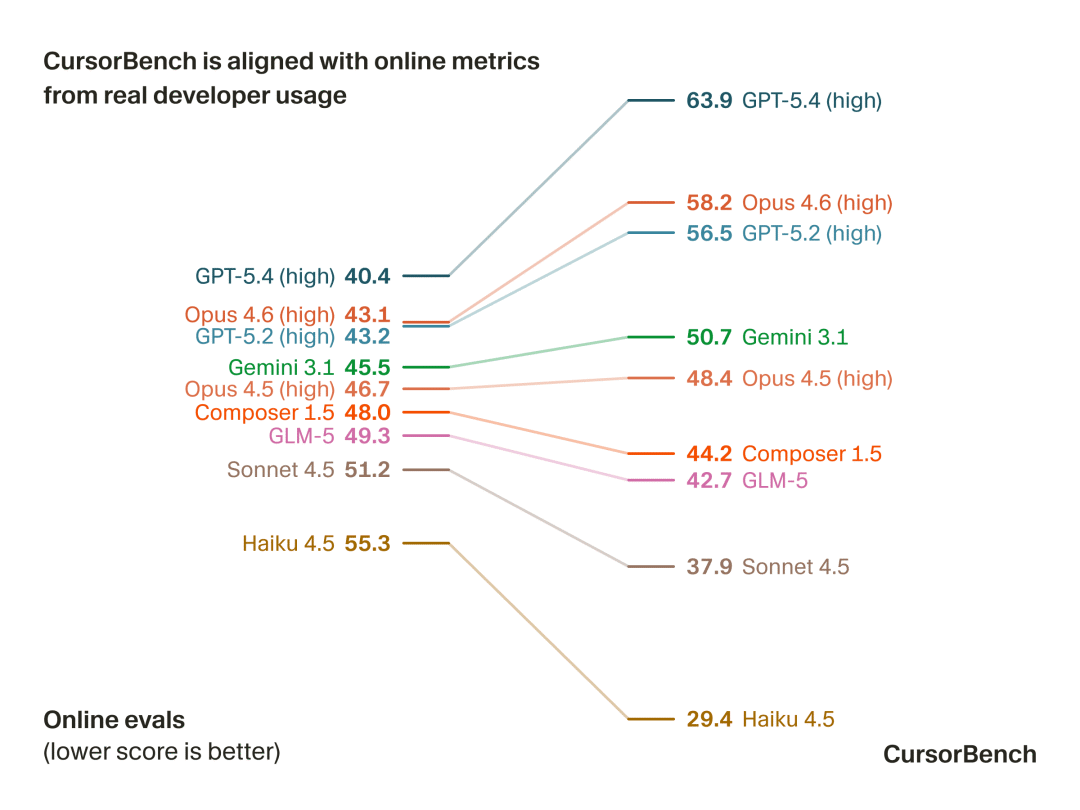
相比公开基准,CursorBench 排名更贴近开发者对模型质量的实际体验
左边:Online evals(真实用户在线指标,越低越好)
右边:CursorBench(内部benchmark,越高越好)
如果你本身就在用 Cursor,或准备上手 Cursor Agent,那么这个评测真值得细读;不然别过度解读,不同 harness 用同样的模型,感受大相径庭。
就目前来看,假如预算有限,我个人比较推荐在Cursor中优先GPT Codex5.3 medium,性价比是蛮不错的。
小结
当然,选择还要根据自己具体项目和预算来,别盲信榜,也别迷信官方口碑,最好结合实际多试试。我个人推荐的模型,也不一定适合你的开发场景。
因此,对当前 AI 模型的编码“实战能力”,大家不止是看分数,关键要看它和我们的开发场景到底有多贴近。大家平时用哪些 AI Agent,有什么踩坑或经验,留言区聊聊吧,一起成长!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号