数据库没动,Prometheus监控却"谎报"重启,真相藏在毫厘之间

数据库没动,Prometheus监控却"谎报"重启,真相藏在毫厘之间

俊才
发布于 2026-03-31 12:17:14
发布于 2026-03-31 12:17:14
最近在维护一套基于sql_exporter + Prometheus的SQL Server监控时,遇到了一个让人头大的问题:明明数据库没有重启,重启告警却频繁触发。经过一番排查,终于揪出了幕后黑手。今天就把这个踩坑经历和解决方案分享给大家。
需要采集规则及告警规则的,可以联系我获取(微信公众号:数据库干货铺)
一、问题背景
我们的监控目标很明确:当SQL Server实例在15分钟内发生重启时,立刻发出告警。
1. 监控方案
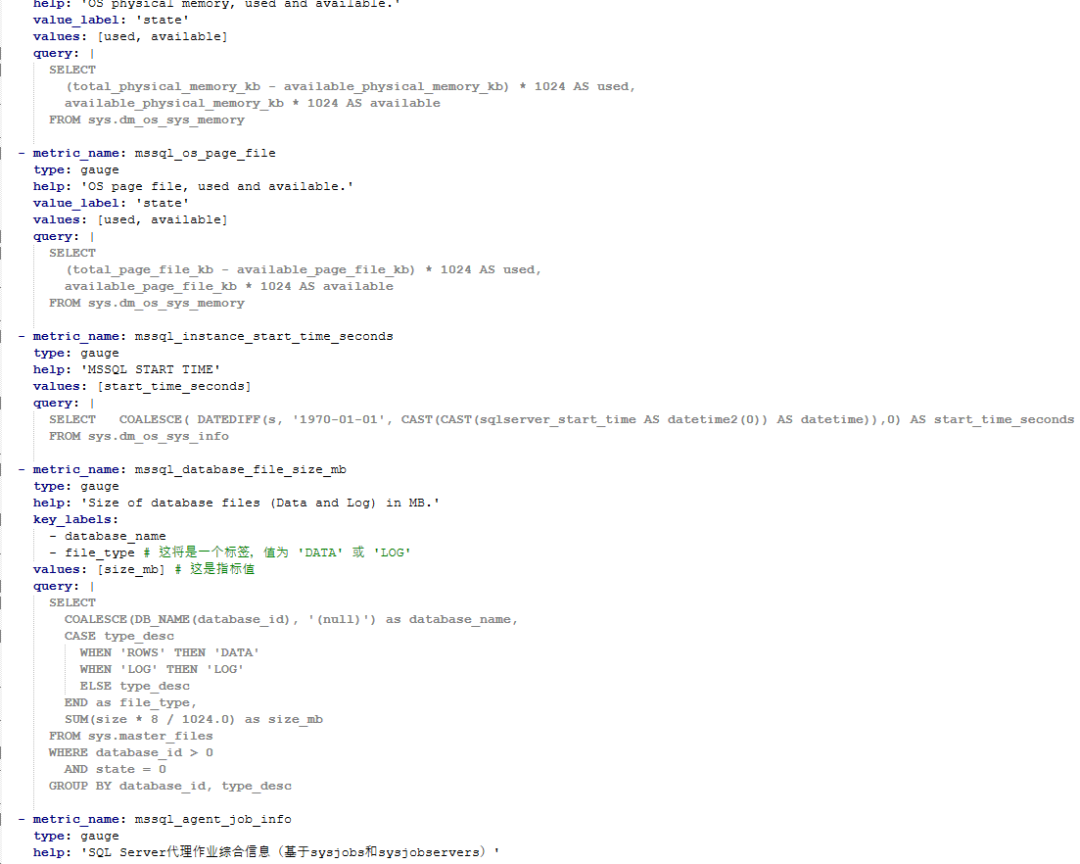
采集器: sql_exporter,通过自定义SQL从SQL Server的sys.dm_os_sys_info 视图中采集实例启动时间
PromQL 规则:
changes(mssql_instance_start_time_seconds[15m])>0这个规则的意思是,如果15分钟内启动时间的秒数发生了变化,就认为实例重启了
告警信息:Prometheus推送的告警信息如下:

2. 诡异现象
告警开始频繁出现,但我们登录服务器检查Windows事件日志和SQL Server 日志后,确认数据库当天根本没有重启。这就很奇怪了,监控系统为什么会 “谎报军情” 呢?
二、问题根源分析
1. 原始采集SQL
我们最初用来采集启动时间的SQL语句是这样的
SELECT
DATEDIFF(s, '1970-01-01', sqlserver_start_time) AS start_time_seconds
FROM sys.dm_os_sys_info;这条SQL的逻辑是:将SQL Server的启动时间sqlserver_start_time转换为从1970年1月1日开始计算的秒数,作为Prometheus的指标。
2. 关键发现:毫秒精度的 “陷阱”
在排查时,我们注意到sys.dm_os_sys_info.sqlserver_start_time这个字段的数据类型是datetimeoffset(7),它包含了毫秒甚至微秒级的精度。
当sql_exporter多次执行这条SQL时,虽然数据库没有重启,看上去sqlserver_start_time的日期和小时、分钟、秒都没有变,但毫秒部分会因为SQL Server内部的时间表示方式,在不同查询中返回不同的值。
这就导致了一个严重后果:
- 第一次采集:计算出的秒数是1772381823
- 第二次采集: 计算出的秒数是1772381823(看起来一样?)
- 第三次采集:计算出的秒数是1741150154(出现了变化)
经过分析,我们发现问题的核心在于sqlserver_start_time字段本身的毫秒部分在每次查询时都可能发生微小变化。这是因为 SQL Server 在返回这个字段时,会根据当前系统时钟的精度进行舍入或截断,导致每次查询得到的时间戳都略有不同。
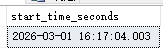

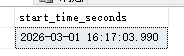
当sql_exporter把这些略有不同的时间戳转换为秒数时,即使 DATEDIFF(s, ...) 函数本身只看秒,也会因为原始时间戳的毫秒部分变化,导致最终计算出的start_time_seconds指标值出现波动。
3. PromQL的 “敏感”
我们的告警规则
changes(mssql_instance_start_time_seconds[15m])>0对这种任何数值上的变化都非常敏感。只要指标值在15分钟窗口内发生了任何改变,哪怕是小数点后一位的变化,changes()函数就会返回大于0的结果,从而触发告警。
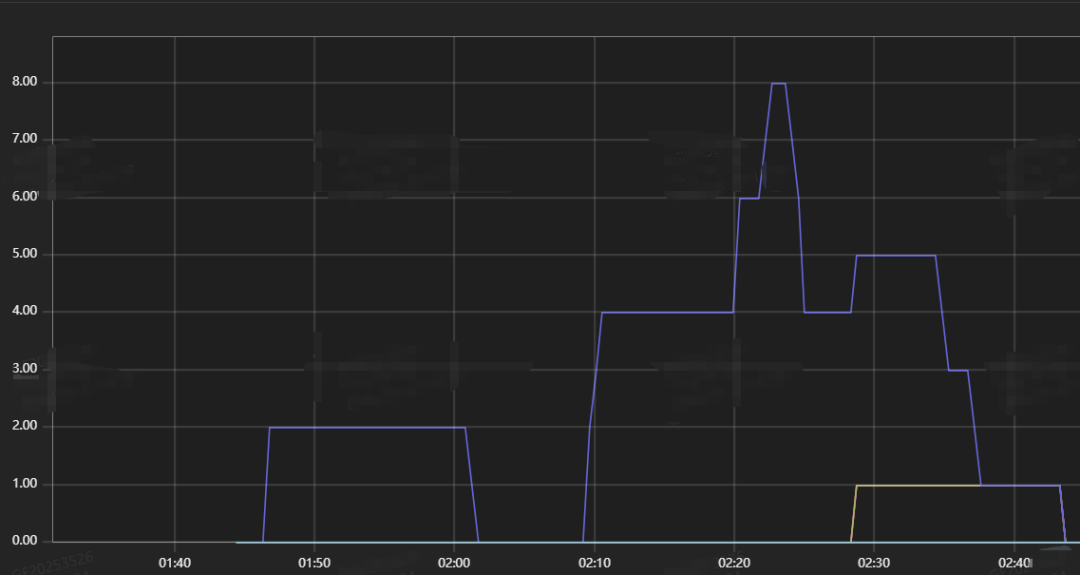
这就完美解释了为什么数据库没重启,告警却一直响:是SQL Server自身sqlserver_start_time字段的毫秒精度波动,导致采集到的指标值发生变化,被 PromQL 规则误判为了重启事件。
三、解决方案
找到了问题根源,解决起来就简单了。核心思路就是:主动截断时间精度,确保采集到的秒数是一个绝对稳定的值。
1. 优化后的采集SQL
我们修改了采集SQL,将sqlserver_start_time显式地转换为只精确到秒的datetime类型:
SELECT
COALESCE(
DATEDIFF(s, '1970-01-01', CAST(CAST(sqlserver_start_time AS datetime2(0)) AS datetime)),
0
) AS start_time_seconds
FROM sys.dm_os_sys_info;2. 脚本解析
- CAST(sqlserver_start_time AS datetime2(0)):首先将datetimeoffset(7)类型的启动时间转换为datetime2(0),这一步会将毫秒及以下的精度全部截断,只保留到秒。
- CAST(... AS datetime):为了兼容性,再将其转换为传统的datetime类型。
- DATEDIFF(s, '1970-01-01', ...):基于这个 “干净” 的、只到秒的时间,计算出从1970年开始的秒数。
- COALESCE(..., 0):添加一个容错处理,防止在极端情况下返回NULL,导致指标采集失败。
3. 效果验证
修改SQL并重新加载sql_exporter配置后,我们观察Grafana中的指标曲(如下图)
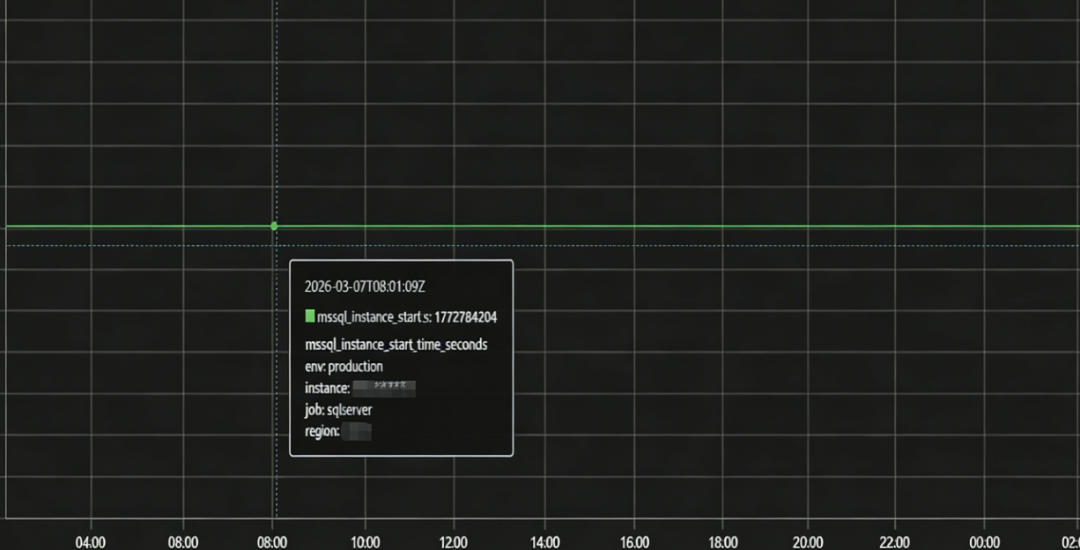
可以看到mssql_instance_start_time_seconds指标变得非常平稳,不再有不必要的波动。同时,那些烦人的误报告警也彻底消失了。
四、总结与反思
这次踩坑给了我们几个重要的启示:
- 关注数据精度:在监控系统中,尤其是处理时间戳这类指标时,一定要注意数据的精度。不必要的高精度往往是引入噪声和误报的元凶。
- 理解字段行为:要深入理解你所查询的数据库字段(如 sqlserver_start_time)的特性,避免因想当然而犯错。
- 防御性编程:在编写采集脚本和SQL时,要考虑到各种边界情况,加入 COALESCE 这类容错机制,让系统更健壮。
如果你也在使用sql_exporter监控SQL Server,不妨检查一下你的启动时间采集脚本,看看是否也存在类似的精度隐患。
如果需要采集脚本,可以联系我获取。
你在数据库监控的过程中还遇到过哪些 “坑”?欢迎在留言区分享你的故事和经验,我们一起交流进步。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号