TPU 架构与 Pallas Kernel 编程入门:从内存层次结构到 FlashAttention

TPU 架构与 Pallas Kernel 编程入门:从内存层次结构到 FlashAttention

deephub
发布于 2026-03-31 19:52:24
发布于 2026-03-31 19:52:24
做过 GPU kernel 优化的人对以下编程模型肯定不会陌生:写一个 CUDA kernel分发到流式多处理器(SM)上执行,缓存层次结构自行负责数据搬运。而TPU 则完全不同,除非明确告诉编译器要把哪些数据块搬到哪里,否则kernel 根本无法编译。实际操作确实和听起来一样繁琐,所以JAX 的Pallas 就是解决的这个问题:以 tile 为单位描述计算,无需手动指定输入张量各部分的搬运路径,编译器自动生成所需的数据移动操作。
本文从硬件约束入手,接着逐步编写复杂度递增的 kernel,最后分析 JAX 生产级 FlashAttention 实现。我们先从基础开始,把那些绕不开的"为什么"讲清楚。
为什么不能在 TPU 上直接写循环?
GPU 上的基本原理很简单:写一个对单个元素或小块数据操作的 kernel,硬件调度成千上万份到各核心执行。线程通常处理同一张量中位置相邻的元素,大量线程同时读取内存中相邻的区域。GPU 的设计就是围绕这一模式展开的:自动合并相邻读取,将近期访问的数据保留在靠近计算单元的位置。内存访问符合这个模式时性能很好;不符合时,硬件通常也能平滑掉一部分开销。
__global__ void add(float* x, float* y, float* out, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
out[i] = x[i] + y[i];
}
}
// 幕后:数千个线程在 GPU 上同时运行这同一个 kernel。
// thread 0 → out[0] = x[0] + y[0]
// thread 1 → out[1] = x[1] + y[1]
// thread 2 → out[2] = x[2] + y[2]理解 Pallas 的价值,先要看清 TPU 和 GPU 在定位上的根本差异。TPU 不是通用并行处理器,它只做一件事,矩阵运算而且做得极好。它不会给游戏带来更高帧率,但一定可以加速模型训练。TPU v5e 芯片围绕一个称为 TensorCore 的计算模块构建,内含四个 MXU(Matrix Multiply Unit),可以理解为 128×128 的 systolic array乘法器排成网格,计算结果沿网格逐级传递给相邻单元。TPU 的内存层次结构不像 GPU 那样自动管理缓存,数据必须在三个层次之间显式搬运:
- HBM(高带宽内存):v5e 上约 16 GB,张量存放的位置,片外,速度相对较慢。
- VMEM(向量内存):16+ MB 的片上 SRAM,速度快但容量小;数据到达这里后计算单元才能访问。
- 寄存器:算术运算实际发生的位置,值从 VMEM 加载到寄存器、完成计算后写回 VMEM。
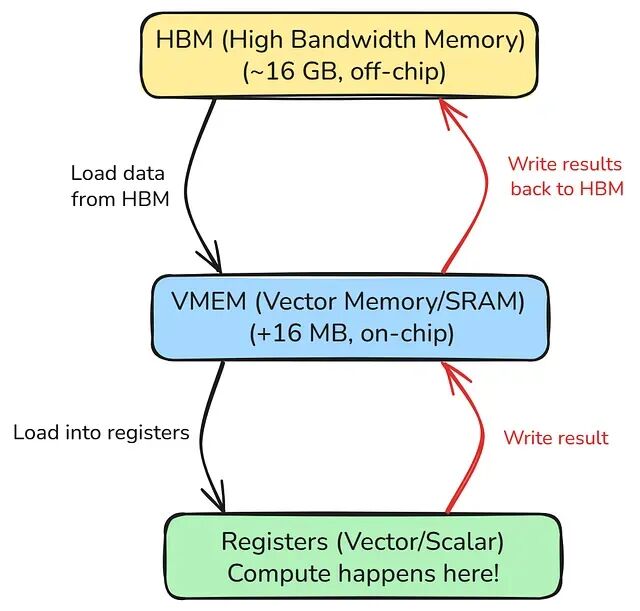
TPU 计算需要显式的数据暂存。
没法在 TPU 上像 CPU 或 GPU 那样对数据写一个简单循环,原因就在这里,数据不会自动从 HBM 流到寄存器。必须显式调度 DMA(直接内存访问)传输,将数据从 HBM 搬入 VMEM;kernel 执行完毕后 VMEM 中的结果再写回 HBM,这是 Pallas 存在的根本理由。GPU 上写 x[i] + y[i],硬件自行处理内存访问;TPU 上则需要明确声明,把这个 256 元素的块从 HBM 加载到 VMEM,在寄存器里做加法,再把结果写回。Pallas 提供了一套简洁的 Python API 来表达这些操作。
理解 Pallas 编程模型
Pallas 采用基于 grid 的执行模型,写过 CUDA 的人会觉得熟悉。程序定义一个 grid,每个 grid 实例处理输入张量的一个 tile(即一小块连续的子张量,把整体计算拆成可管理的片段)。对本文中的 kernel 而言,grid 可以视为顺序执行的,既编译器知道执行顺序,就能在计算当前 tile 时以流水线方式搬运下一个 tile 的数据,这是显式内存管理可行的前提。
三个核心抽象将执行模型串联在一起:Grid、BlockSpec 和 Ref,分别描述 kernel 实例何时运行、操作哪块数据、计算期间数据驻留在何处。
- Grid:定义迭代空间的整数元组。
grid=(4,)表示 kernel 执行 4 次,程序 ID 从 0 到 3,kernel 内部通过pl.program_id(axis=0)获取当前迭代索引。 - BlockSpec:指定每个 grid 步骤从 HBM 张量的哪个切片加载到 VMEM。每步处理一个 tile,运行时必须在计算开始前把对应切片搬入 VMEM。接受两个参数:
block_shape(tile 大小)和index_map(从 grid 索引到 tile 坐标的映射函数)。默认的 blocked 索引模式下,index_map输出乘以block_shape得到实际的 HBM 切片。以一个 1024 元素向量为例,block_shape=(256,),index_map=lambda i: (i,)时:步骤i=0加载[0:256],i=1加载[256:512],i=2加载[512:768],i=3加载[768:1024]。 - Ref:kernel 内部看到的不是原始数组,而是 Ref 对象——指向 VMEM 的句柄。读取
x_ref[...]把值从 VMEM 加载到寄存器;写入o_ref[...] = val把结果存回 VMEM。kernel 退出后 VMEM 内容自动刷写到 HBM。
单个 grid 步骤中,数据在 TPU 内存层次结构中的流动路径为:HBM ⟶(BlockSpec 控制的 DMA 加载)⟶ VMEM ⟶ 寄存器(Ref[...] 读取)⟶ 计算 ⟶ 寄存器 ⟶ VMEM(Ref[...] = 写入)⟶ DMA 写回 ⟶ HBM。下图展示了同一过程。
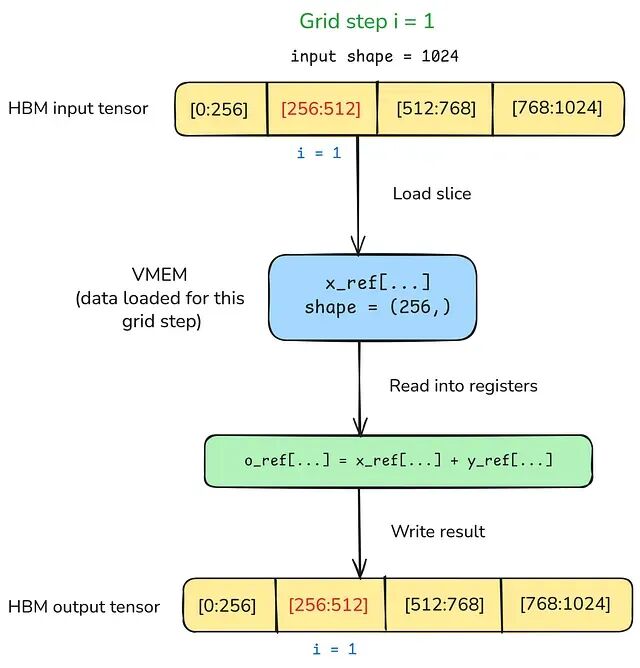
建立了这个模型之后,我们就可以按复杂度递增的顺序编写几个 Pallas kernel。
第四级:逐元素加法
kernel 函数接收每个输入和输出的 Ref 对象,从输入 ref 读取、完成计算、将结果写入输出 ref。pallas_call 包装器负责 grid 迭代和 DMA 调度。
pallas_call 建立一个 4 步 grid。 每步 i,BlockSpec 指示 DMA 引擎将 x[i*256:(i+1)*256] 和 y[i*256:(i+1)*256] 从 HBM 加载到 VMEM。 kernel 读取两个 ref 并相加,将结果写入输出 ref。四步完成后 HBM 中的输出张量包含完整的逐元素求和结果。 out_shape 告知 pallas_call 在 HBM 中为输出分配什么样的空间——这里通过 jax.ShapeDtypeStruct 传入 shape 和 dtype,而非实际张量。
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
def add_kernel(x_ref, y_ref, o_ref):
# 通过 Ref 对象从 VMEM 读取分块,计算,写入结果
o_ref[...] = x_ref[...] + y_ref[...]
def add_vectors(x: jax.Array, y: jax.Array) -> jax.Array:
block_size = 256 # 每个网格步骤处理一个 256 元素的分块
return pl.pallas_call(
add_kernel,
out_shape=jax.ShapeDtypeStruct(x.shape, x.dtype),
# 网格步骤数(每个分块一个)
grid=(x.shape[0] // block_size,),
# 描述每个网格步骤如何从 HBM 加载分块
in_specs=[
pl.BlockSpec((block_size,), lambda i: (i,)),
pl.BlockSpec((block_size,), lambda i: (i,)),
],
# 描述输出分块写入的位置
out_specs=pl.BlockSpec((block_size,), lambda i: (i,)),
)(x, y)
def main():
key = jax.random.PRNGKey(0)
x = jax.random.normal(key, (1024,), dtype=jnp.bfloat16)
y = jax.random.normal(jax.random.PRNGKey(1), (1024,), dtype=jnp.bfloat16)
result = jax.jit(add_vectors)(x, y)
expected = x + y
diff = jnp.max(jnp.abs(result - expected))
print(f"Output shape: {result.shape}, dtype: {result.dtype}")
print(f"Max abs diff: {diff}")
print(f"First 8 values: {result[:8]}")
Element-wise Add Kernel Output
第三级:分块点积
逐元素加法和 grid 的映射关系很自然,因为每一步都是独立的而点积不同:每一步都向同一个标量输出贡献一个部分和,需要跨 grid 步骤进行累加。
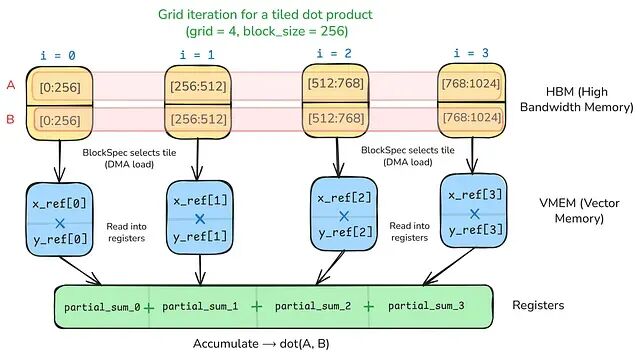
关键在于 input_output_aliases。传入 {2:0} 表示第三个输入(索引 2)与第一个输出(索引 0)共享同一个缓冲区——这里的缓冲区就是 HBM 中存储张量数据的底层内存分配。于是输出 ref 的初始值就是该输入的值,每个 grid 步骤的 += 都在此基础上累加。kernel 每步加载两个向量各一个块,计算局部点积后加入运行总和。读代码时注意一个细节:输出形状是 (1,128) 而非标量。TPU 的块形状约束要求最后两个维度分别能被 8 和 128 整除(或等于完整数组维度),标量点积结果需要 reshape 以满足该约束,读取时再 reshape 回来。
import functools
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
def dot_kernel(x_ref, y_ref, acc_in_ref, out_ref):
# 计算 dot(x_tile, y_tile) 并累加到运行总和中
out_ref[...] += jnp.sum(x_ref[...] * y_ref[...], keepdims=True)
def tiled_dot(x: jax.Array, y: jax.Array) -> jax.Array:
block_size = 256
n_blocks = x.shape[0] // block_size
# 传递给 kernel 的累加器初始值
zero = jnp.zeros((1,), dtype=jnp.float32)
return pl.pallas_call(
dot_kernel,
out_shape=jax.ShapeDtypeStruct((1,), jnp.float32),
grid=(n_blocks,),
in_specs=[
pl.BlockSpec((block_size,), lambda i: (i,)),
pl.BlockSpec((block_size,), lambda i: (i,)),
pl.BlockSpec((1,), lambda i: (0,)),
],
out_specs=pl.BlockSpec((1,), lambda i: (0,)),
# 将累加器输入与输出缓冲区设为别名,使每个
# 网格步骤都累加到同一个运行总和中
input_output_aliases={2: 0},
)(x, y, zero)
def main():
key = jax.random.PRNGKey(0)
x = jax.random.normal(key, (1024,), dtype=jnp.bfloat16)
y = jax.random.normal(jax.random.PRNGKey(1), (1024,), dtype=jnp.bfloat16)
result = jax.jit(tiled_dot)(x, y)
expected = jnp.dot(x.astype(jnp.float32), y.astype(jnp.float32))
print(f"Pallas dot result: {result.reshape(())}")
print(f"jnp.dot result: {expected}")
print(f"Max abs diff: {jnp.abs(result.reshape(()) - expected)}")
Tiled Dot Product Kernel Output
第二级:融合 RMSNorm 与 Scratch 内存
前面的 kernel 只用到了输入和输出两种 VMEM 缓冲区。有些计算需要与输入输出无关的中间存储——比如 RMSNorm,必须在整行上累加 ∑(x²) 之后才能求归一化因子。Pallas 通过 scratch_shapes 满足这一需求:请求一个指定形状和数据类型的 VMEM 缓冲区,它会作为额外的 Ref 参数出现在 kernel 签名中。这个 scratch 缓冲区(临时内存区域)仅存在于 VMEM,不会读入或写回 HBM。
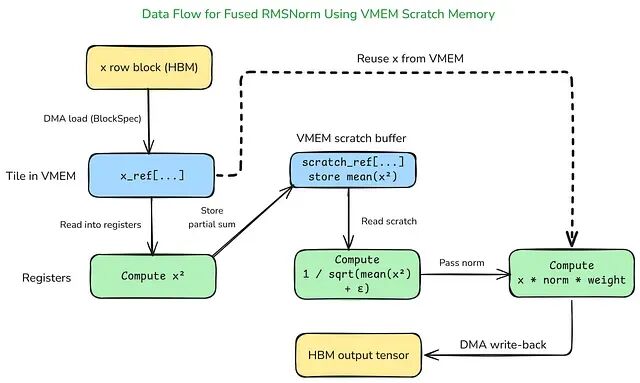
Fused RMSNorm with VMEM Scratch Buffer
寄存器容量太小、生命周期太短,无法在整行归约过程中持久保存中间结果,因此用 VMEM scratch 缓冲区来存储跨 tile 的中间统计量,如上图所示。这个 kernel 还引入了 PrefetchScalarGridSpec——一种将 grid、BlockSpec 和 scratch 形状打包到一个对象中的 grid 规范,专为需要流水线化的 TPU kernel 设计。运行时可以将下一个 tile 的 DMA 传输与当前 tile 的计算重叠执行,Pallas 文档称之为 lookahead prefetch(前瞻预取)。
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
from jax.experimental.pallas import tpu as pltpu
BATCH = 4
DIM = 1024
EPS = 1e-5
def rmsnorm_kernel(x_ref, weight_ref, o_ref, scratch_ref):
# 从 VMEM 加载分块并向上转换为 float32 以确保数值稳定性
x = x_ref[...].astype(jnp.float32)
w = weight_ref[...].astype(jnp.float32)
# 计算 mean(x^2) 并将中间结果存储在 scratch VMEM 缓冲区中
mean_sq = jnp.mean(x * x, axis=-1, keepdims=True)
scratch_ref[...] = jnp.broadcast_to(mean_sq, scratch_ref.shape)
# 从 scratch 内存中读回存储的值以计算 RMS
rms = jnp.sqrt(scratch_ref[0:BATCH, 0:1] + EPS)
# 归一化并将结果写回 VMEM(之后刷写到 HBM)
o_ref[...] = (x / rms * w).astype(jnp.bfloat16)
def fused_rmsnorm(x: jax.Array, weight: jax.Array) -> jax.Array:
grid_spec = pltpu.PrefetchScalarGridSpec(
num_scalar_prefetch=0,
# 每个 batch 行一个网格步骤
grid=(1,),
in_specs=[
# 每个网格步骤加载 x 的一行
pl.BlockSpec((BATCH, DIM), lambda i: (0, 0)),
# 权重向量在每一行中都被复用
pl.BlockSpec((DIM,), lambda i: (0,)),
],
# 每个网格步骤写入一行归一化后的结果
out_specs=pl.BlockSpec((BATCH, DIM), lambda i: (0, 0)),
# 在 VMEM 中分配用于中间统计量的 scratch 缓冲区
scratch_shapes=[pltpu.VMEM((BATCH, 128), jnp.float32)], # 遵循前面讨论的 TPU 块形状对齐要求
)
return pl.pallas_call(
rmsnorm_kernel,
grid_spec=grid_spec,
out_shape=jax.ShapeDtypeStruct((BATCH, DIM), jnp.bfloat16),
)(x, weight)
def reference_rmsnorm(x, weight):
x_f32 = x.astype(jnp.float32)
rms = jnp.sqrt(jnp.mean(x_f32 * x_f32, axis=-1, keepdims=True) + EPS)
return (x_f32 / rms * weight.astype(jnp.float32)).astype(jnp.bfloat16)
def main():
key = jax.random.PRNGKey(42)
x = jax.random.normal(key, (BATCH, DIM), dtype=jnp.bfloat16)
weight = jnp.ones((DIM,), dtype=jnp.bfloat16)
result = jax.jit(fused_rmsnorm)(x, weight)
expected = reference_rmsnorm(x, weight)
diff = jnp.max(jnp.abs(result.astype(jnp.float32) - expected.astype(jnp.float32)))
print(f"Output shape: {result.shape}, dtype: {result.dtype}")
print(f"Max abs diff: {diff}")
print(f"First row, first 8: {result[0, :8]}")
Fused RMSNorm with Scratch Memory Kernel Output
第一级:FlashAttention
我们先回顾一下 FlashAttention 解决的问题。标准 attention 的瓶颈不在算术运算,而在二次增长的中间注意力矩阵。序列长度 1024、8 个 head、batch 大小 2 的情况下,注意力分数矩阵包含 2 × 8 × 1024 × 1024 个元素,约 1600 万个浮点数;序列长度到 4096 时增长到约 2.56 亿个。在 TPU 上,这个矩阵必须在 softmax 和与 V 的矩阵乘法之前完整写入 HBM。FlashAttention 用 tile 化计算消除了这一开销——不生成完整矩阵,而是每次只处理 Q 的一个块与 K/V 的一个块,在片上快速内存中仅保留运行中的 softmax 统计量和部分输出。完整矩阵从头到尾不存在,计算加速正源于此。
需要说明的是,以下代码是从 Pallas 自身的生产级实现中提炼出的核心模式。原始实现包含更多细节,但大部分可以追溯到本文已经介绍过的模式。
前面第二级和第三级的模式已经铺好了路:每个 grid 步骤加载一个 Q 块和一个 K/V 块到 VMEM,计算部分 attention 并累加结果和点积 kernel(第三级)一致,只是多了 softmax 。PrefetchScalarGridSpec 处理与第二级相同的 DMA 流水线(kernel 计算当前 K/V 块时,运行时已经在从 HBM 预取下一个块到 VMEM)。VMEM 中的三个 scratch 缓冲区(第二级的同一模式)保存跨 K 块迭代的持久状态:
m:到目前为止注意力分数的逐行最大值。
l:指数的逐行累加和(softmax 分母)。
acc:V 的未归一化加权和(输出累加器,对应第三级的累加模式)。
新引入的模式如下:
FlashAttention 使用 online softmax。标准 softmax 需要整个 key 序列的全局最大值来保证数值稳定性,但 tile 化处理时每次只能看到一个 K 块,无法预先算出全局最大值。online softmax 维护一个运行最大值,当后续块中出现更大的值时回头修正之前的计算。 与之前的 kernel 不同,FlashAttention 使用二维 grid。第一个轴遍历 query 块,第二个轴遍历 key/value 块,每个 grid 步骤处理一个 (Q, KV) 对,将该 KV 块的贡献累加到 attention 结果中。
关于条件执行:pl.when 是 Pallas 的条件原语,仅当谓词为真时执行对应代码块。这里用它在第一个 KV 块时初始化运行统计量,在最后一个 KV 块时写入最终归一化后的输出。
前三个 kernel 的构建块都已就绪,可以动手写核心算法了。
import functools
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
from jax.experimental.pallas import tpu as pltpu
SEQ_LEN = 1024
HEAD_DIM = 128
NUM_HEADS = 8
BATCH = 2
BLOCK_Q = 128
BLOCK_K = 128
def flash_kernel(q_ref, k_ref, v_ref, o_ref, m_ref, l_ref, acc_ref, *, num_kv_blocks, sm_scale):
# 之前的级别中 kernel 仅使用 axis=0;axis=1 现在用于索引 KV 块
kv_idx = pl.program_id(axis=1)
@pl.when(kv_idx == 0)
def init():
m_ref[...] = jnp.full(m_ref.shape, -jnp.inf, jnp.float32)
l_ref[...] = jnp.zeros(l_ref.shape, jnp.float32)
acc_ref[...] = jnp.zeros(acc_ref.shape, jnp.float32)
# Q 分块保持不变,同时我们遍历所有 KV 块
q = q_ref[...].astype(jnp.float32)
k = k_ref[...].astype(jnp.float32)
v = v_ref[...]
# S = Q_block @ K_block^T,按 1/sqrt(d) 缩放
s = jax.lax.dot_general(
q, k, (((1,), (1,)), ((), ())), preferred_element_type=jnp.float32
) * sm_scale
# 运行中的 softmax 统计量存储在 VMEM scratch 缓冲区中
m_prev = m_ref[...]
m_curr = jnp.max(s, axis=1)[:, None]
m_next = jnp.maximum(m_prev, m_curr)
# 修正因子:将之前的累加值重新缩放到新的最大值
alpha = jnp.exp(m_prev - m_next)
# 对分数相对于当前稳定最大值取指数
p = jnp.exp(s - m_next)
# 更新运行总和与累加器
l_ref[...] = alpha * l_ref[...] + jnp.sum(p, axis=1)[:, None]
acc_ref[...] = alpha * acc_ref[...] + jax.lax.dot(
p.astype(v.dtype), v, preferred_element_type=jnp.float32
)
m_ref[...] = m_next
# 在最后一个 KV 块之后,我们进行归一化并写入输出分块
@pl.when(kv_idx == num_kv_blocks - 1)
def store():
o_ref[...] = (acc_ref[...] / l_ref[...]).astype(o_ref.dtype)
def single_head_flash(q, k, v):
seq_len, head_dim = q.shape
num_kv_blocks = seq_len // BLOCK_K
kernel = functools.partial(flash_kernel, num_kv_blocks=num_kv_blocks, sm_scale=head_dim ** -0.5)
grid_spec = pltpu.PrefetchScalarGridSpec(
num_scalar_prefetch=0,
grid=(seq_len // BLOCK_Q, num_kv_blocks),
in_specs=[
pl.BlockSpec((BLOCK_Q, head_dim), lambda i, j: (i, 0)),
pl.BlockSpec((BLOCK_K, head_dim), lambda i, j: (j, 0)),
pl.BlockSpec((BLOCK_K, head_dim), lambda i, j: (j, 0)),
],
out_specs=pl.BlockSpec((BLOCK_Q, head_dim), lambda i, j: (i, 0)),
scratch_shapes=[
pltpu.VMEM((BLOCK_Q, 128), jnp.float32),
pltpu.VMEM((BLOCK_Q, 128), jnp.float32),
pltpu.VMEM((BLOCK_Q, head_dim), jnp.float32),
],
)
return pl.pallas_call(
kernel,
grid_spec=grid_spec,
out_shape=jax.ShapeDtypeStruct(q.shape, q.dtype),
compiler_params=pltpu.CompilerParams(dimension_semantics=("parallel", "arbitrary")),
)(q, k, v)
def pallas_flash_attention(q, k, v):
return jax.vmap(jax.vmap(single_head_flash))(q, k, v)
def naive_attention(q, k, v):
scale = q.shape[-1] ** -0.5
s = jnp.einsum('...qd,...kd->...qk', q.astype(jnp.float32), k.astype(jnp.float32)) * scale
return jnp.einsum('...qk,...kd->...qd', jax.nn.softmax(s, axis=-1), v.astype(jnp.float32)).astype(q.dtype)
def main():
key = jax.random.PRNGKey(0)
q = jax.random.normal(key, (BATCH, NUM_HEADS, SEQ_LEN, HEAD_DIM), dtype=jnp.bfloat16)
k = jax.random.normal(jax.random.PRNGKey(1), (BATCH, NUM_HEADS, SEQ_LEN, HEAD_DIM), dtype=jnp.bfloat16)
v = jax.random.normal(jax.random.PRNGKey(2), (BATCH, NUM_HEADS, SEQ_LEN, HEAD_DIM), dtype=jnp.bfloat16)
result = jax.jit(pallas_flash_attention)(q, k, v)
expected = naive_attention(q, k, v)
diff = jnp.max(jnp.abs(result.astype(jnp.float32) - expected.astype(jnp.float32)))
print(f"Output shape: {result.shape}, dtype: {result.dtype}")
print(f"Max abs diff vs naive: {diff}")
FlashAttention Kernel Output
总结
TPU 的编程模型与 GPU 有本质区别:没有自动缓存管理,数据在 HBM、VMEM 和寄存器之间的每一次搬运都需要程序员显式控制。Pallas 将这种底层的 DMA 调度抽象为三个概念——Grid 定义迭代空间,BlockSpec 描述每步加载哪块数据,Ref 充当 VMEM 的读写句柄——从而把编程者的注意力拉回到计算逻辑本身。
本文通过四个复杂度递增的 kernel 展示了 Pallas 的核心编程模式:逐元素运算对应最基本的 tile 化映射;点积引入了跨步骤累加与 input_output_aliases;RMSNorm 展示了 scratch 内存和 PrefetchScalarGridSpec 的流水线预取;FlashAttention 则将上述模式组合在一起,加入 online softmax 和二维 grid,在 TPU 上完成了无需物化完整注意力矩阵的分块计算。
by Harshal Janjani
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号