2026-03-12:大于目标字符串的最小字典序排列。用go语言,给定两个长度相同且只含小写字母的字符串 s 和 target。 要求从 s 的所有字符重

2026-03-12:大于目标字符串的最小字典序排列。用go语言,给定两个长度相同且只含小写字母的字符串 s 和 target。 要求从 s 的所有字符重

福大大架构师每日一题
发布于 2026-03-31 20:57:18
发布于 2026-03-31 20:57:18
2026-03-12:大于目标字符串的最小字典序排列。用go语言,给定两个长度相同且只含小写字母的字符串 s 和 target。
要求从 s 的所有字符重排中找出一个新的字符串,该字符串在按字母顺序比较时比 target 严格更大,并且在所有满足这个条件的重排中位于最靠前(即最小)。如果不存在任何重排能严格大于 target,则返回空串。
这里“按字母顺序比较”的意思是:从左到右逐位比较,遇到第一个不同的字符时,字母表中靠后的那个字符串被认为更大;“重排”指把原字符串的字符以其他顺序重新排列。
1 <= s.length == target.length <= 300。
s 和 target 仅由小写英文字母组成。
输入: s = "abc", target = "bba"。
输出: "bca"。
解释:
s 的排列(按字典序)有 "abc", "acb", "bac", "bca", "cab" 和 "cba"。
字典序严格大于 target 的最小排列是 "bca"。
题目来自力扣3720。
一、算法执行全过程(分步骤详细说明)
我们以输入 s = "abc"、target = "bba" 为例,拆解整个逻辑:
步骤1:初始化字符计数数组,统计字符供需差异
核心目标:先计算 s 中每个字符的数量,减去 target 中对应位置字符的消耗,得到字符剩余量,同时统计「欠账」(负数)和「可用字符掩码」(正数)。
- • 初始化长度为26的数组
left(对应a-z),初始值全为0。 - • 遍历
s和target的每一位(长度相同):- • 对
s的第i位字符(如s[0] = 'a'),left['a'-'a'] += 1→left[0] = 1; - • 对
target的第i位字符(如target[0] = 'b'),left['b'-'a'] -= 1→left[1] = -1; - • 完整遍历后(
s=abc,target=bba):- •
left[0] (a):s有1个a,target用了0个a →1-0=1; - •
left[1] (b):s有1个b,target用了2个b →1-2=-1; - •
left[2] (c):s有1个c,target用了0个c →1-0=1; - • 其余位置均为0。
- •
- • 对
- • 统计两个关键变量:
- •
neg:left中负数的个数(此处left[1]为负,故neg=1); - •
mask:用二进制位标记left中正数的字符(a和c对应位为1,即mask = 1<<0 | 1<<2 = 5,二进制101)。
- •
步骤2:从后向前遍历target,寻找可替换的位置
核心目标:从字符串末尾往头部找第一个「可以替换成更大字符,且替换后剩余字符能凑出合法排列」的位置 i,这是整个算法的核心逻辑。
遍历范围:i 从 len(s)-1(即2)到0:
子步骤2.1:i=2(target最后一位,字符是'a')
- • 撤销当前位的字符消耗:
target[2] = 'a'(对应b=0),执行left[0]++→left[0]从1变为2; - • 更新
neg和mask:- •
left[0]原本是1(正数),加1后还是正数 →neg仍为1(无负数变化); - •
mask原本包含0位(a),现在仍包含 →mask不变(还是5);
- •
- • 检查条件:
neg > 0(1>0)→ 说明当前还存在字符欠账,即使替换当前位,也无法用剩余字符凑出合法排列 → 跳过,继续向前找。
子步骤2.2:i=1(target倒数第二位,字符是'b')
- • 撤销当前位的字符消耗:
target[1] = 'b'(对应b=1),执行left[1]++→left[1]从-1变为0; - • 更新
neg和mask:- •
left[1]从负数变为0 →neg从1减为0; - •
left[1]变为0,不加入mask→mask仍为5;
- •
- • 检查条件:
- •
neg=0(无欠账); - • 检查
mask中是否有比当前字符(b,对应1)大的字符:mask >> (1+1) = 5 >> 2 = 1(二进制101右移2位是1)→ 不为0,说明存在更大的字符(c,对应2);
- •
- • 满足条件,开始构造结果:
子步骤2.2.1:确定要替换的字符
- • 先清空
mask中比当前字符(b)小或相等的位:mask &^= 1<<(1+1) -1→1<<2 -1 = 3(二进制11),mask=5 &^ 3 = 4(二进制100); - • 找
mask中最右侧的1(即最小的更大字符):bits.TrailingZeros(4) = 2→ 对应字符c; - • 消耗该字符:
left[2]--→left[2]从1变为0。
子步骤2.2.2:拼接最终结果
- • 先截取
target的前i位(i=1,即target[:2] = "bb"),替换第i位为c→ 得到"bc"; - • 遍历
left数组,将剩余字符按a-z顺序拼接:- •
left[0] = 2→ 拼接2个a; - •
left[1] = 0→ 无; - •
left[2] = 0→ 无; - • 其余均为0;
- •
- • 最终拼接结果:
"bc" + "a" = "bca",返回该结果。
(注:若遍历完所有i都未找到满足条件的位置,则返回空串。)
步骤3:返回结果
此处找到合法位置并构造出结果"bca",算法结束。
二、时间复杂度分析
我们按「核心操作」拆解时间消耗:
- 1. 初始化left数组:遍历
s和target各一次,长度为n→ 时间复杂度O(n); - 2. 统计neg和mask:遍历26个字符 → 时间复杂度
O(1)(常数级); - 3. 从后向前遍历target:最多遍历
n次(i从n-1到0):- • 每次遍历中的「撤销消耗、更新neg/mask」:均为
O(1)(仅操作26个字符内的计数); - • 构造结果时的「遍历left数组拼接字符」:最多遍历26次 →
O(1); - • 单次遍历总耗时
O(1),n次遍历总耗时O(n);
- • 每次遍历中的「撤销消耗、更新neg/mask」:均为
- 4. 其他辅助操作(如
bits.TrailingZeros、字符串拼接):均为O(1)或O(n)(拼接结果的总长度为n)。
总时间复杂度:O(n)(n为字符串长度,26是常数,可忽略)。
三、额外空间复杂度分析
额外空间指除输入外的临时空间:
- 1. left数组:固定长度26 →
O(1); - 2. mask/neg等变量:单个整数/布尔值 →
O(1); - 3. 结果字符串的临时数组:最多存储
n个字符 →O(n); - 4. 其他辅助变量(如循环变量、临时字符):
O(1)。
总额外空间复杂度:O(n)(主要为存储结果的数组,26为常数可忽略)。
总结
- 1. 核心逻辑:先统计字符供需差异,再从后向前找第一个可替换为更大字符的位置,替换后将剩余字符按最小字典序拼接,保证结果是「大于target的最小排列」;
- 2. 时间复杂度:
O(n)(n为字符串长度,所有操作均为线性或常数级); - 3. 额外空间复杂度:
O(n)(主要消耗在结果拼接的临时数组,其余为常数空间)。
Go完整代码如下:
.
package main
import (
"fmt"
"math/bits"
"strings"
)
func lexGreaterPermutation(s, target string)string {
left := make([]int, 26)
for i, b := range s {
left[b-'a']++
left[target[i]-'a']--
}
neg, mask := 0, 0
for i, cnt := range left {
if cnt < 0 {
neg++ // 统计 left 中的负数个数
} elseif cnt > 0 {
mask |= 1 << i
}
}
for i := len(s) - 1; i >= 0; i-- {
b := target[i] - 'a'
left[b]++ // 撤销消耗
if left[b] == 0 {
neg--
} elseif left[b] == 1 {
mask |= 1 << b
}
// left 有负数 or 没有大于 target[i] 的字母
if neg > 0 || mask>>(b+1) == 0 {
continue
}
// 把 target[i] 增大到 j
mask &^= 1<<(b+1) - 1
j := bits.TrailingZeros(uint(mask)) // 也可以写循环找 j
left[j]--
ans := []byte(target[:i+1])
ans[i] = 'a' + byte(j)
for k, c := range left {
ch := string('a' + byte(k))
ans = append(ans, strings.Repeat(ch, c)...)
}
returnstring(ans)
}
return""
}
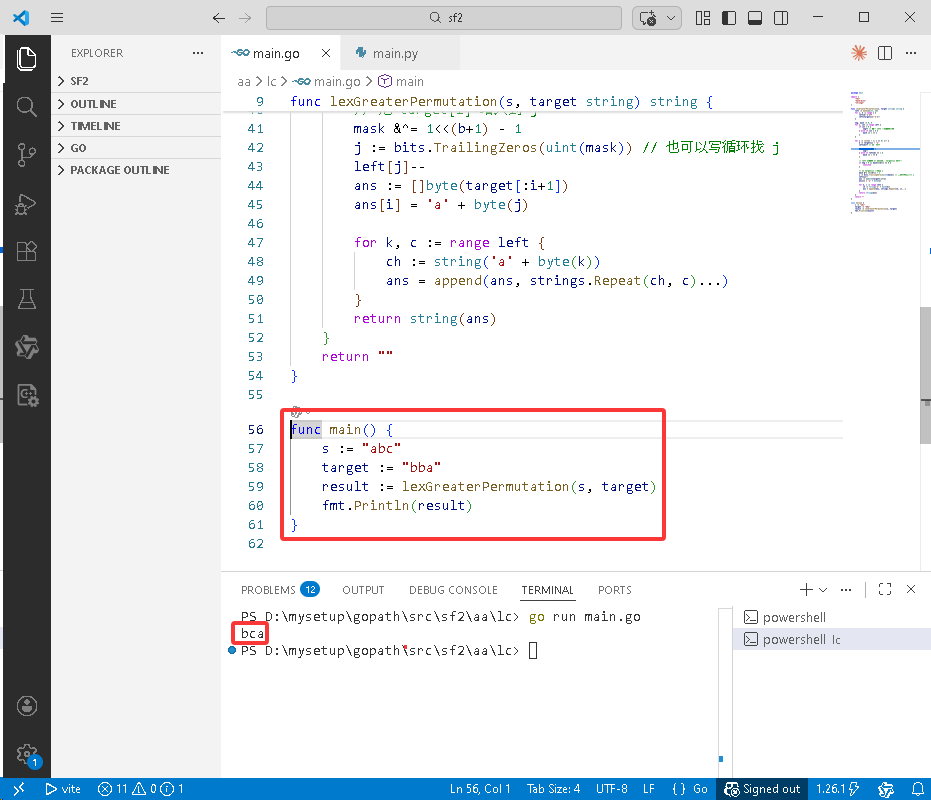
func main() {
s := "abc"
target := "bba"
result := lexGreaterPermutation(s, target)
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
def lex_greater_permutation(s: str, target: str) -> str:
left = [0] * 26
for i in range(len(s)):
left[ord(s[i]) - ord('a')] += 1
left[ord(target[i]) - ord('a')] -= 1
neg = 0
mask = 0
for i, cnt in enumerate(left):
if cnt < 0:
neg += 1 # 统计 left 中的负数个数
elif cnt > 0:
mask |= 1 << i
for i in range(len(s) - 1, -1, -1):
b = ord(target[i]) - ord('a')
left[b] += 1 # 撤销消耗
if left[b] == 0:
neg -= 1
elif left[b] == 1:
mask |= 1 << b
# left 有负数 or 没有大于 target[i] 的字母
if neg > 0 or (mask >> (b + 1)) == 0:
continue
# 把 target[i] 增大到 j
# 清除低 b+1 位
mask &= ~((1 << (b + 1)) - 1)
# 找到第一个为 1 的位置
j = (mask & -mask).bit_length() - 1 # 获取最低位的 1 的位置
left[j] -= 1
ans = list(target[:i + 1])
ans[i] = chr(ord('a') + j)
for k, c in enumerate(left):
ans.extend([chr(ord('a') + k)] * c)
return''.join(ans)
return""
def main():
s = "abc"
target = "bba"
result = lex_greater_permutation(s, target)
print(result)
if __name__ == "__main__":
main()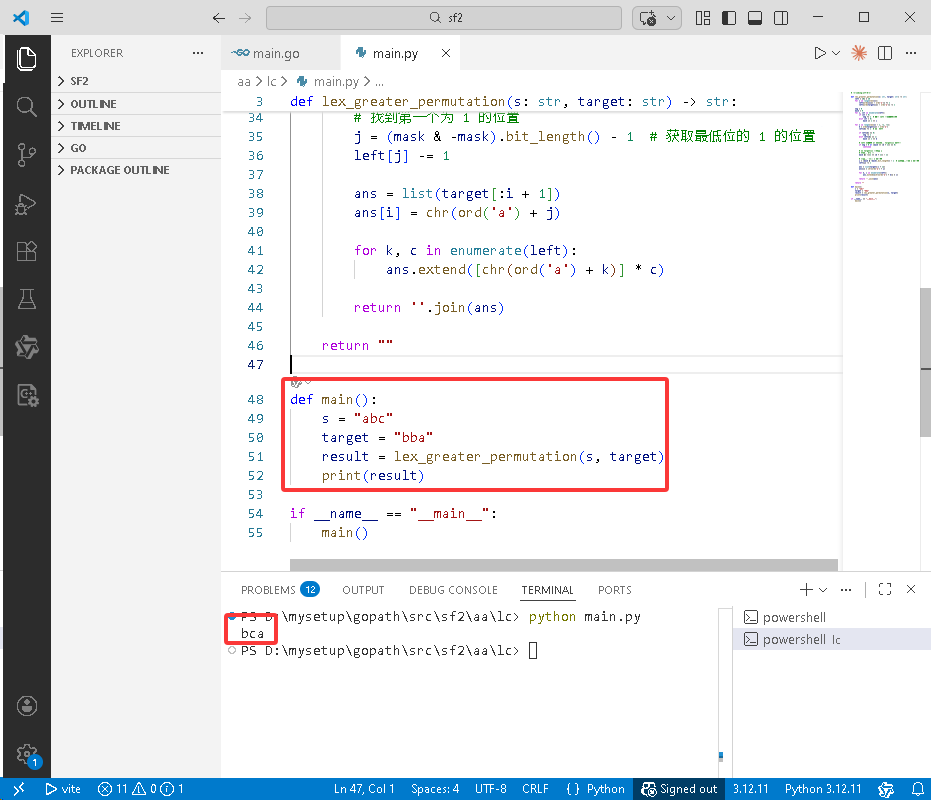
在这里插入图片描述
C++完整代码如下:
.
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
string lexGreaterPermutation(string s, string target) {
vector<int> left(26, 0);
for (int i = 0; i < s.length(); i++) {
left[s[i] - 'a']++;
left[target[i] - 'a']--;
}
int neg = 0, mask = 0;
for (int i = 0; i < 26; i++) {
if (left[i] < 0) {
neg++; // 统计 left 中的负数个数
} elseif (left[i] > 0) {
mask |= 1 << i;
}
}
for (int i = s.length() - 1; i >= 0; i--) {
int b = target[i] - 'a';
left[b]++; // 撤销消耗
if (left[b] == 0) {
neg--;
} elseif (left[b] == 1) {
mask |= 1 << b;
}
// left 有负数 or 没有大于 target[i] 的字母
if (neg > 0 || (mask >> (b + 1)) == 0) {
continue;
}
// 把 target[i] 增大到 j
mask &= ~((1 << (b + 1)) - 1);
// 找到第一个为 1 的位置
int j = __builtin_ctz(mask); // GCC/Clang 的内置函数,相当于 bits.TrailingZeros
left[j]--;
string ans = target.substr(0, i + 1);
ans[i] = 'a' + j;
for (int k = 0; k < 26; k++) {
if (left[k] > 0) {
ans.append(left[k], 'a' + k);
}
}
return ans;
}
return"";
}
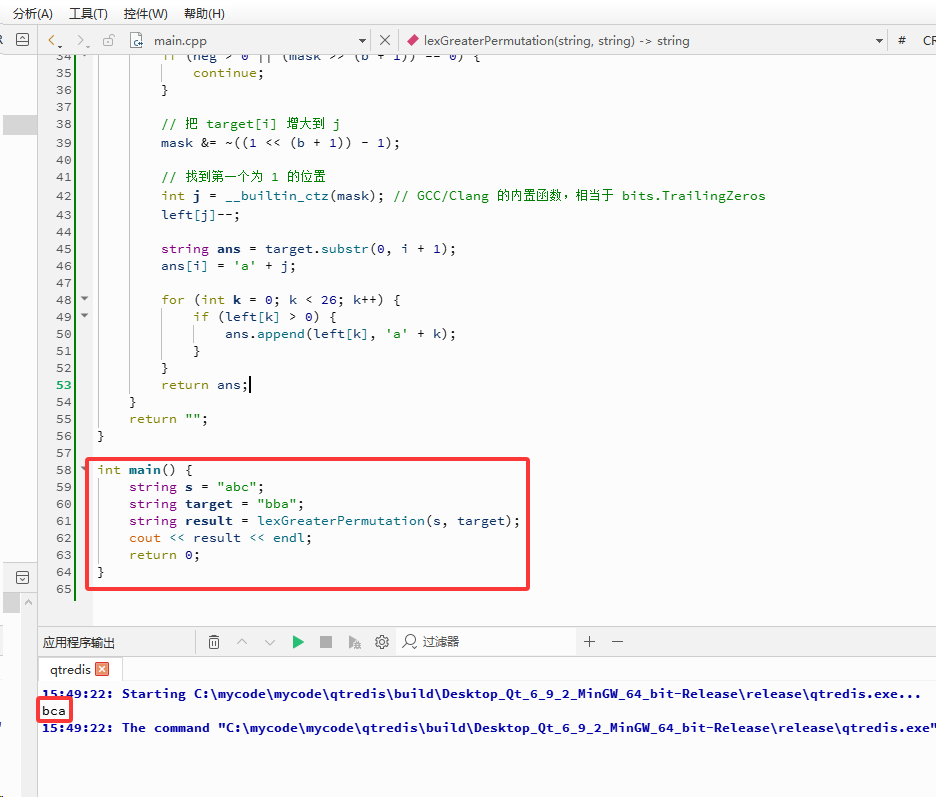
int main() {
string s = "abc";
string target = "bba";
string result = lexGreaterPermutation(s, target);
cout << result << endl;
return0;
}
在这里插入图片描述
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。 欢迎关注“福大大架构师每日一题”,发消息可获得面试资料,让AI助力您的未来发展。
·
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-11,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号