2026-03-24:大于目标字符串的最小字典序回文排列。用go语言,给定两个长度都是 n 的小写字符串 s 和 target,你要在所有“由 s 的字符重

2026-03-24:大于目标字符串的最小字典序回文排列。用go语言,给定两个长度都是 n 的小写字符串 s 和 target,你要在所有“由 s 的字符重

福大大架构师每日一题
发布于 2026-03-31 21:19:36
发布于 2026-03-31 21:19:36
2026-03-24:大于目标字符串的最小字典序回文排列。用go语言,给定两个长度都是 n 的小写字符串 s 和 target,你要在所有“由 s 的字符重排得到的字符串”里筛选出满足以下条件的字符串:
1.回文条件:重排后的字符串需要是回文(正着读和反着读完全相同)。
2.字典序条件:该回文字符串的字典序要严格大于 target(也就是比 target 在字典排序上更靠后)。
在所有满足条件的字符串中,返回字典序最小的那个;如果不存在这样的字符串,返回空字符串。
字典序的比较规则是:
对两个等长字符串从左到右逐位比较;在第一次出现不同的字符位置,若前者该位置的字母在字母表中的顺序 更靠后,则前者字典序 更大。
1 <= n == s.length == target.length <= 300。
s 和 target 仅由小写英文字母组成。
输入: s = "baba", target = "abba"。
输出: "baab"。
解释:
s 的回文排列(按字典序)是 "abba" 和 "baab"。
字典序最小的、且严格大于 target 的排列是 "baab"。
题目来自力扣3734。
大体步骤如下:
步骤1:统计字符频次,判断是否存在合法回文
回文字符串的核心规则:
- • 偶数长度:所有字符出现次数必须是偶数;
- • 奇数长度:恰好一个字符出现奇数次(作为回文中心),其余均为偶数。
具体操作:
- 1. 统计
s中26个小写字母的出现次数,存入长度为26的数组left; - 2. 遍历频次数组,检查出现奇数次的字符数量:
- • 若超过1个:直接返回空字符串(无法构成回文);
- • 若恰好1个:记录该字符为回文中心字符
midCh,并将其频次减1(变为偶数,用于两侧拼接); - • 若全为偶数:回文中心为空。
这一步是基础合法性过滤,排除所有无法构成回文的情况。
步骤2:初始化匹配,消耗目标字符串左半部分字符
回文字符串的结构 = 左半部分 + 中心字符 + 左半部分反转,因此只需要构造左半部分即可生成完整回文。
具体操作:
- 1. 计算回文左半部分的长度:
总长度n / 2(偶数长度无中心,奇数长度中心单独处理); - 2. 直接消耗
target左半部分的字符:每个字符需要成对使用,因此频次数组中对应字符减2;- • 目的:先假设我们的答案左半部分和
target左半完全一致,快速验证是否存在解。
- • 目的:先假设我们的答案左半部分和
步骤3:校验字符消耗的合法性
上一步消耗 target 左半字符后,可能出现字符透支(频次为负数),需要统计状态:
- 1. 遍历频次数组
left:- • 统计负数个数
neg:代表透支的字符种类数; - • 记录剩余可用字符的最大下标
leftMax:代表当前能使用的最大字母。
- • 统计负数个数
- 2. 合法性判断:
- • 若
neg > 0:说明target左半用了超出s拥有的字符,直接跳过特殊情况,进入回溯; - • 若
neg = 0:字符消耗合法,进入特殊情况判断。
- • 若
步骤4:特殊情况判断(左半与target一致时,能否直接生成解)
当字符消耗合法(无透支)时,验证:直接用target左半生成回文,是否严格大于target。
具体操作:
- 1. 用
target左半部分 + 中心字符 + 左半反转,生成完整回文; - 2. 只需要比较右半部分(左半完全一致,无需比较):
- • 若生成的右半 > target的右半:这个回文就是答案,直接返回;
- • 否则:说明左半和target一致时无法满足条件,需要回溯修改左半部分。
步骤5:从后往前回溯,寻找最小字典序解
这是算法的核心:从左半部分的最后一位开始,向前逐位尝试修改,找到第一个可以增大的位置,生成最小字典序解。
具体操作:
- 1. 回溯撤销:从左半最后一位向前遍历,将当前位置的字符加2归还(撤销之前的消耗);
- 2. 状态更新:归还后更新负数个数和最大可用字符;
- 3. 判断是否可修改:
- • 若仍有字符透支,或没有比当前字符更大的可用字符:继续向前回溯;
- • 若存在可用的更大字符:停止回溯,开始构造答案;
- 4. 构造最小字典序解:
- • 找到比当前字符大的最小可用字符(保证字典序最小);
- • 消耗该字符(减2),替换当前位置;
- • 剩余的可用字符,按从小到大顺序填充(保证最小字典序);
- • 拼接:左半部分 + 中心字符 + 左半反转,生成最终回文并返回。
步骤6:无满足条件的解
遍历完所有位置都无法找到可修改的位,说明不存在严格大于target的回文排列,返回空字符串。
示例演示(s="baba",target="abba")
- 1. 统计字符:
a:2,b:2,全偶数,无中心字符; - 2. 左半长度=2,target左半=
ab,消耗a、b各2个,频次全为0; - 3. 无透支,生成回文:
ab + 空 + ba = abba,和target相等,不满足严格大于; - 4. 回溯:从左半最后一位(b)开始,归还字符后,可用字符为a、b;
- 5. 修改:将
b替换为更大的a?不,替换为b不行,最终找到将第一位a改为b,第二位填a; - 6. 生成左半
ba,拼接后:ba + 空 + ab = baab,即为答案。
时间复杂度与额外空间复杂度分析
1. 时间复杂度
- • 核心操作:字符统计(O(n))、回溯遍历左半部分(O(n))、构造结果字符串(O(n));
- • 所有循环均为线性遍历,无嵌套循环,字母表固定26个(常数级);
- • 总时间复杂度:O(n)(n为字符串长度)。
2. 额外空间复杂度
- • 仅使用了固定长度的频次数组(26)、若干变量、存储结果的字节数组;
- • 所有额外空间与输入长度n无关,为常数级;
- • 总额外空间复杂度:O(1)。
总结
- 1. 算法核心:利用回文结构特性,仅构造左半部分,大幅简化问题;
- 2. 逻辑:先校验合法性→尝试直接匹配→回溯修改→生成最小解;
- 3. 效率:线性时间+常数空间,完美适配题目n≤300的限制。
Go完整代码如下:
.
package main
import (
"fmt"
"slices"
"strings"
)
func lexPalindromicPermutation(s, target string)string {
left := make([]int, 26)
for _, b := range s {
left[b-'a']++
}
midCh := ""
for i, c := range left {
if c%2 == 0 {
continue
}
// s 不能有超过一个字母出现奇数次
if midCh != "" {
return""
}
// 记录填在正中间的字母
midCh = string('a' + byte(i))
left[i]--
}
n := len(s)
// 先假设答案左半与 t 的左半(不含正中间)相同
for _, b := range target[:n/2] {
left[b-'a'] -= 2
}
neg, leftMax := 0, byte(0)
for i, cnt := range left {
if cnt < 0 {
neg++ // 统计 left 中的负数个数
} elseif cnt > 0 {
leftMax = max(leftMax, byte(i)) // 剩余可用字母的最大值
}
}
if neg == 0 {
// 特殊情况:把 target 左半翻转到右半,能否比 target 大?
leftS := target[:n/2]
tmp := []byte(leftS)
slices.Reverse(tmp)
rightS := midCh + string(tmp)
if rightS > target[n/2:] { // 由于左半是一样的,所以只需比右半
return leftS + rightS
}
}
for i := n/2 - 1; i >= 0; i-- {
b := target[i] - 'a'
left[b] += 2// 撤销消耗
if left[b] == 0 {
neg--
} elseif left[b] == 2 {
leftMax = max(leftMax, b)
}
// left 有负数 or 没有大于 target[i] 的字母
if neg > 0 || leftMax <= b {
continue
}
// 找到答案(下面的循环在整个算法中只会跑一次)
j := b + 1
for left[j] == 0 {
j++
}
// 把 target[i] 增大到 j
left[j] -= 2
ans := []byte(target[:i+1])
ans[i] = 'a' + j
// 中间可以随便填
for k, c := range left {
ch := string('a' + byte(k))
ans = append(ans, strings.Repeat(ch, c/2)...)
}
// 镜像翻转
rightS := slices.Clone(ans)
slices.Reverse(rightS)
ans = append(ans, midCh...)
ans = append(ans, rightS...)
returnstring(ans)
}
return""
}
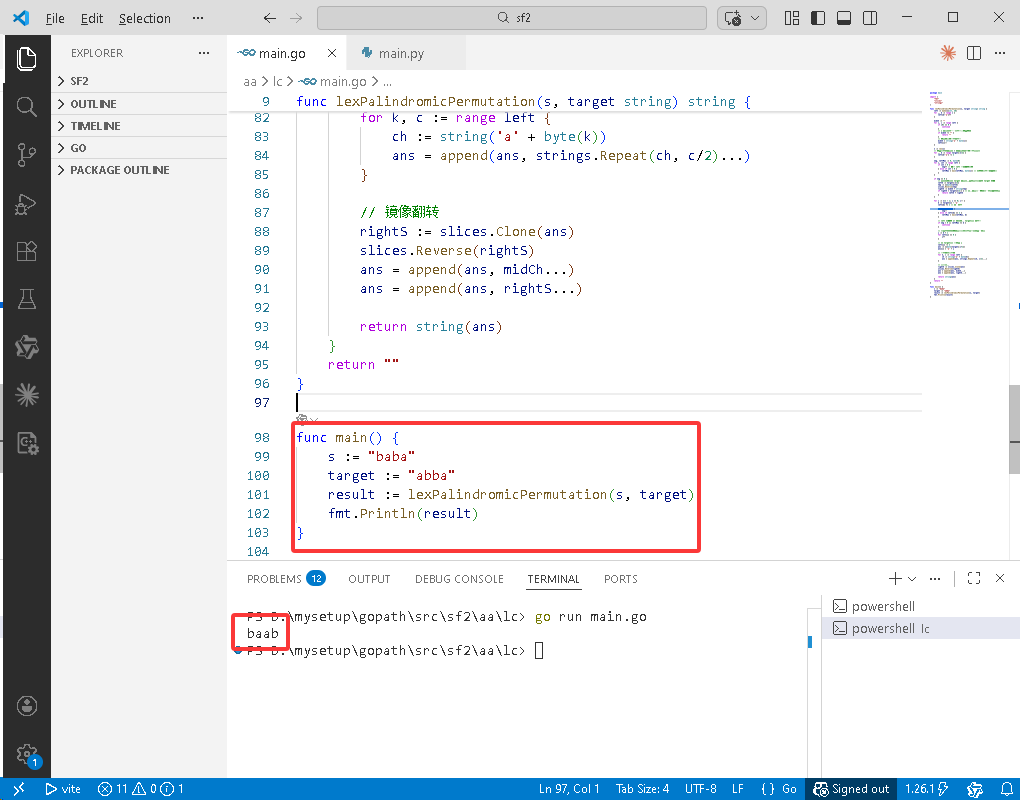
func main() {
s := "baba"
target := "abba"
result := lexPalindromicPermutation(s, target)
fmt.Println(result)
}
在这里插入图片描述
Python完整代码如下:
.
# -*-coding:utf-8-*-
def lex_palindromic_permutation(s: str, target: str) -> str:
left = [0] * 26
for ch in s:
left[ord(ch) - ord('a')] += 1
mid_ch = ""
for i, cnt in enumerate(left):
if cnt % 2 == 0:
continue
# s 不能有超过一个字母出现奇数次
if mid_ch != "":
return""
# 记录填在正中间的字母
mid_ch = chr(ord('a') + i)
left[i] -= 1
n = len(s)
# 先假设答案左半与 t 的左半(不含正中间)相同
for ch in target[:n//2]:
left[ord(ch) - ord('a')] -= 2
neg = 0
left_max = 0
for i, cnt in enumerate(left):
if cnt < 0:
neg += 1 # 统计 left 中的负数个数
elif cnt > 0:
left_max = max(left_max, i) # 剩余可用字母的最大值
if neg == 0:
# 特殊情况:把 target 左半翻转到右半,能否比 target 大?
left_s = target[:n//2]
tmp = list(left_s)
tmp.reverse()
right_s = mid_ch + ''.join(tmp)
if right_s > target[n//2:]: # 由于左半是一样的,所以只需比右半
return left_s + right_s
for i in range(n//2 - 1, -1, -1):
b = ord(target[i]) - ord('a')
left[b] += 2 # 撤销消耗
if left[b] == 0:
neg -= 1
elif left[b] == 2:
left_max = max(left_max, b)
# left 有负数 or 没有大于 target[i] 的字母
if neg > 0 or left_max <= b:
continue
# 找到答案(下面的循环在整个算法中只会跑一次)
j = b + 1
while left[j] == 0:
j += 1
# 把 target[i] 增大到 j
left[j] -= 2
ans = list(target[:i+1])
ans[i] = chr(ord('a') + j)
# 中间可以随便填
for k, cnt in enumerate(left):
if cnt > 0:
ch = chr(ord('a') + k)
ans.extend([ch] * (cnt // 2))
# 镜像翻转
right_s = ans[::-1]
result = ''.join(ans) + mid_ch + ''.join(right_s)
return result
return""
def main():
s = "baba"
target = "abba"
result = lex_palindromic_permutation(s, target)
print(result)
if __name__ == "__main__":
main()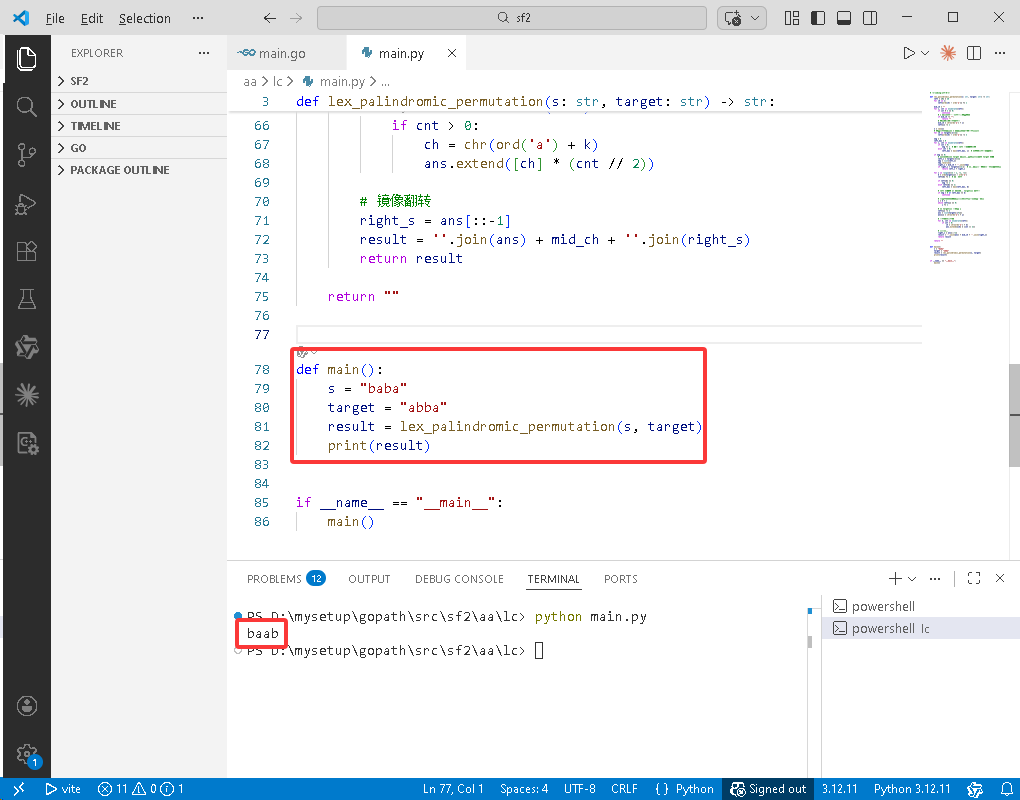
在这里插入图片描述
C++完整代码如下:
.
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
#include <numeric>
using namespace std;
string lexPalindromicPermutation(string s, string target) {
vector<int> left(26, 0);
for (char b : s) {
left[b - 'a']++;
}
string midCh = "";
for (int i = 0; i < 26; i++) {
int cnt = left[i];
if (cnt % 2 == 0) {
continue;
}
// s 不能有超过一个字母出现奇数次
if (!midCh.empty()) {
return"";
}
// 记录填在正中间的字母
midCh = string(1, 'a' + i);
left[i]--;
}
int n = s.length();
// 先假设答案左半与 t 的左半(不含正中间)相同
for (int i = 0; i < n / 2; i++) {
char b = target[i];
left[b - 'a'] -= 2;
}
int neg = 0;
int leftMax = 0;
for (int i = 0; i < 26; i++) {
int cnt = left[i];
if (cnt < 0) {
neg++; // 统计 left 中的负数个数
} elseif (cnt > 0) {
leftMax = max(leftMax, i); // 剩余可用字母的最大值
}
}
if (neg == 0) {
// 特殊情况:把 target 左半翻转到右半,能否比 target 大?
string leftS = target.substr(0, n / 2);
string tmp = leftS;
reverse(tmp.begin(), tmp.end());
string rightS = midCh + tmp;
if (rightS > target.substr(n / 2)) { // 由于左半是一样的,所以只需比右半
return leftS + rightS;
}
}
for (int i = n / 2 - 1; i >= 0; i--) {
int b = target[i] - 'a';
left[b] += 2; // 撤销消耗
if (left[b] == 0) {
neg--;
} elseif (left[b] == 2) {
leftMax = max(leftMax, b);
}
// left 有负数 or 没有大于 target[i] 的字母
if (neg > 0 || leftMax <= b) {
continue;
}
// 找到答案(下面的循环在整个算法中只会跑一次)
int j = b + 1;
while (left[j] == 0) {
j++;
}
// 把 target[i] 增大到 j
left[j] -= 2;
string ans = target.substr(0, i + 1);
ans[i] = 'a' + j;
// 中间可以随便填
for (int k = 0; k < 26; k++) {
int cnt = left[k];
if (cnt > 0) {
char ch = 'a' + k;
ans.append(cnt / 2, ch);
}
}
// 镜像翻转
string rightS = ans;
reverse(rightS.begin(), rightS.end());
ans = ans + midCh + rightS;
return ans;
}
return"";
}
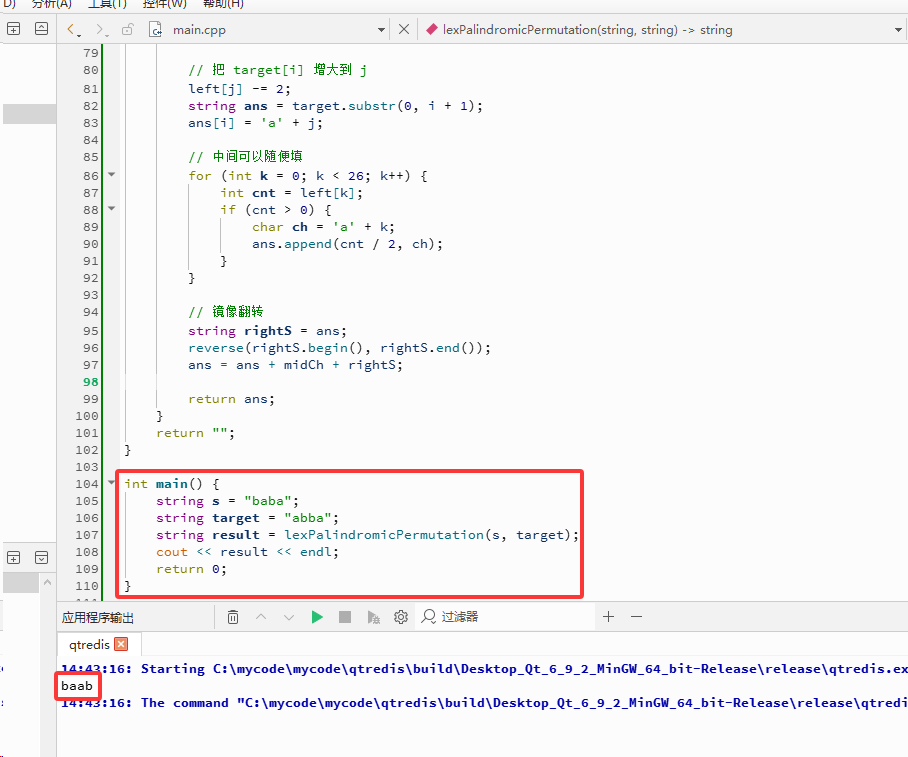
int main() {
string s = "baba";
string target = "abba";
string result = lexPalindromicPermutation(s, target);
cout << result << endl;
return0;
}
在这里插入图片描述
·
我们相信人工智能为普通人提供了一种“增强工具”,并致力于分享全方位的AI知识。在这里,您可以找到最新的AI科普文章、工具评测、提升效率的秘籍以及行业洞察。 欢迎关注“福大大架构师每日一题”,发消息可获得面试资料,让AI助力您的未来发展。
·
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号