SSD扩展显存:群联aiDAPTIV+破局AI本地部署

SSD扩展显存:群联aiDAPTIV+破局AI本地部署

数据存储前沿技术
发布于 2026-04-02 10:41:23
发布于 2026-04-02 10:41:23
阅读收获
- 掌握aiDAPTIV+软硬协同机制:aiDAPTIVLink中间件智能卸载KV Cache与模型分片至高耐久SSD,单站训练70B模型,TCO降90%。
- 理解DSP在计算存储的价值:E28主控内置DSP处理参数更新,消除PCIe瓶颈,GPU利用率max,适用于LoRA微调场景。
- 洞察行业趋势:存储厂商主导显存虚拟化,错位竞争NVIDIA,助力边缘AI普惠,分析师可追踪群联并购与生态动态。
全文概览
在生成式AI浪潮下,企业与高校急于本地部署大模型,却屡屡卡在显存瓶颈:微调70B模型需1.4TB显存,传统方案逼迫采购数十张昂贵GPU,TCO高企;推理时,长上下文KV Cache爆显存,导致延迟飙升。你是否也面临“算力喂不饱、成本压垮身”的窘境?群联aiDAPTIV+横空出世,通过Flash Offload将NVMe SSD变身GPU显存延伸,单机4张GPU搞定集群级任务。更进一步,E28主控内置DSP引擎,实现“近数据计算”,卸载参数更新,性能飙升40%。这不仅是硬件解耦,更是存储厂商向AI算力上游的精准卡位。中小企业如何以低成本拥抱大模型?存储与计算的边界正被重塑。
👉 划线高亮 观点批注
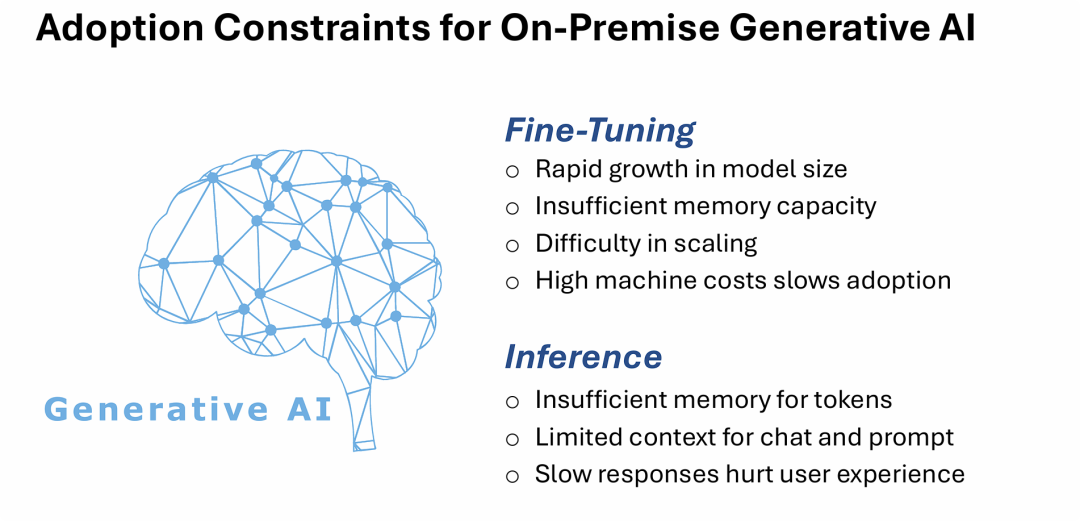
图片的核心观点是:企业在本地环境(On-Premise)部署生成式AI时,主要面临着由底层计算与存储基础设施(尤其是内存/显存资源)引发的严重瓶颈。
这些限制贯穿于AI的“微调”和“推理”两个关键阶段。
- 在微调阶段,不断膨胀的模型规模带来了容量不足、扩展困难以及成本高昂的问题;
- 而在推理阶段,资源的短缺直接导致了上下文处理能力的受限以及响应延迟的增加。
IT基础设施的性能边界(特别是Memory容量与带宽)和高昂的硬件TCO(总拥有成本)是阻碍本地生成式AI大规模落地的最大绊脚石。

图片的核心观点是:通过底层架构的技术创新,打破硬件资源限制,从而大幅降低企业和高校在本地/边缘端部署生成式AI的门槛和成本。
传统的AI硬件架构中,算力(Compute)和显存/内存(DRAM)往往是强绑定的,处理大模型必须购买昂贵的高配服务器。
PPT中提出的解决方案是通过“解耦”思想和名为“aiDaptiv+”的存储管理技术,突破物理内存容量的瓶颈。这使得中小企业(SMB)和教育机构只需使用成本较低的工作站或小型服务器,就能独立且灵活地扩展资源,完成大模型的训练(微调)、推理以及长文本(Context Window / KV Cache)处理。最终实现“硬件自主可控、成本丰俭由人”,极大地提高了AI算力的普惠性和系统效率。
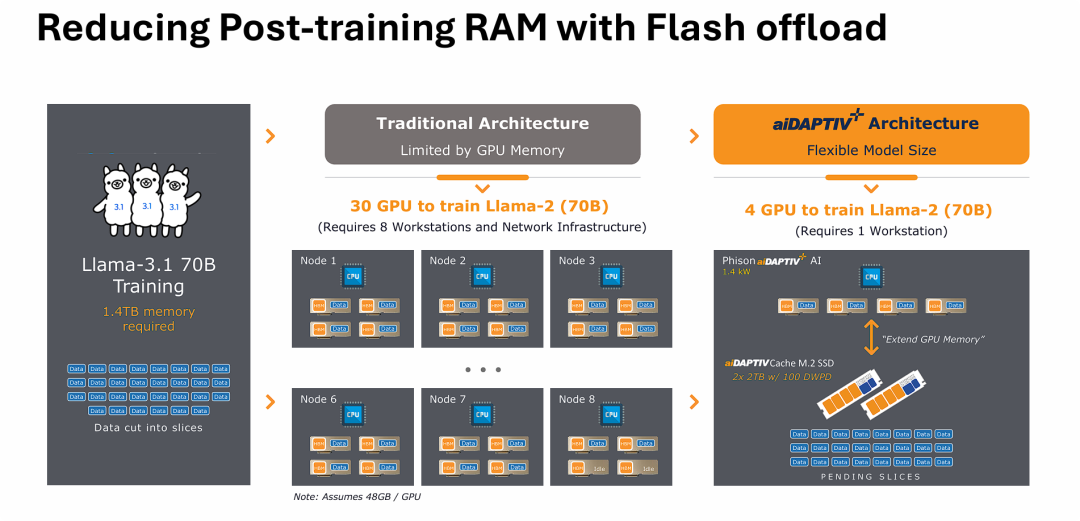
图片的核心观点是:通过将高速、高耐久度的NVMe SSD(固态硬盘)作为GPU显存的扩展(即Flash Offload技术),可以彻底打破传统AI训练中“显存容量决定集群规模”的硬件瓶颈。
在传统架构下,为了凑齐训练70B大模型所需的1.4TB庞大显存,企业不得不采购数十张昂贵的GPU,并搭建复杂的多节点集群和高速网络。
通过引入基于闪存卸载的架构(如群联的aiDAPTIV+),系统可以将无法装入显存的“数据分片”暂时卸载并缓存到高耐久度SSD中。这种创新的存储/内存层级管理技术,使得原本需要8台工作站、30张GPU组成的集群才能完成的训练任务,现在仅靠1台配备4张GPU的单体工作站即可实现,从而以极低的成本和功耗实现了大模型的本地化训练。

图片的核心观点是:群联的 aiDAPTIV+ 解决方案是一个“软硬协同设计(Hardware-Software Co-design)”的创新架构,旨在将专用的企业级闪存转化为 GPU 显存的延伸。
该方案由两部分组成:
- 在软件端,它提供了一个名为 aiDAPTIVLink 的中间件,能够无缝嵌入到标准的 PyTorch AI 框架中,负责智能调度和交换内存数据;
- 在硬件端,它提供名为 aiDAPTIVCache 的高性能专用固态硬盘(如 PASCARI AI100E)作为存储载体。
这种软硬结合的方式打破了传统存储与内存的界限,使得系统能够将超出物理显存容量的数据平滑地卸载到 SSD 上,从而大幅降低大模型训练和推理的硬件门槛。
如何理解aiDAPTIVLink,是否和NVIDIA 的GDS类似?行业来看 通常是GPU计算厂商来主导中间件的设计,存储厂商来做这个事是否合适
aiDAPTIVLink 与 NVIDIA GDS 的核心区别在于设计目标:GDS 是“I/O 加速”技术,通过旁路 CPU 实现 SSD 到 GPU 显存的直接数据传输,以提升带宽、降低延迟,适用于训练数据的高速加载。而 aiDAPTIVLink 是“显存虚拟化扩容”技术,通过将模型参数、KV Cache 等卸载至 SSD 并在需要时预取,突破显存容量限制,实现大模型在有限 GPU 上的低成本部署。
由存储厂商(如群联)主导此类中间件设计是必要且合理的,原因在于:
- 解决 SSD 寿命问题:高频随机读写会快速损耗普通 SSD。存储厂商凭借主控芯片与固件控制权,能通过“软硬协同设计”(如定制 100 DWPD 高耐久 SSD、合并细碎 I/O)极大降低写入放大,保障系统寿命。
- 掩盖物理延迟鸿沟:HBM 显存速度(TB/s)远超 PCIe SSD(GB/s)。存储厂商最了解自身主控的队列深度、缓存与垃圾回收策略,能实现智能预取与流水线,最大化压榨 SSD 性能,避免 I/O 成为计算瓶颈。
- 商业动机契合:NVIDIA 的诉求是销售更多 GPU,缺乏开发“以 SSD 替代显存”中间件的动力。而存储厂商则需开拓高附加值场景,通过此类中间件将高性能 SSD 导入预算有限的中小企业、边缘等市场,形成“以存代算”的错位竞争。
这本质是存储行业基于对底层介质特性的深刻理解,向计算架构上游的一次精准卡位。

图片的核心观点是:群联推出了具备“计算存储(Computational Storage)”能力的下一代 AI 专属 SSD 主控芯片——E28,从硬件底层重塑了 AI 数据流的处理方式。
传统的 SSD 主控只负责数据的读写和存储管理。而这款 E28 芯片的革命性在于,它利用 6nm 工艺在主控内部直接集成了一个数学计算引擎(DSP)。这意味着 SSD 不再仅仅是一个“被动存储池”,而是变成了“协处理器”。它可以就近处理一些相对简单的 AI 运算任务(例如某些数据的预处理或轻量级更新),避免了这些数据在 SSD、CPU 和 GPU 之间来回搬运带来的极高 PCIe 带宽消耗和延迟(即消除了额外的 PCIe hop)。
这种“让计算靠近数据”的创新架构,不仅大幅减轻了 CPU 和 GPU 的负担(性能提升 40%),还能显著降低整体系统的功耗。
如何理解这里的DSP ,通常其他计算型存储方案是基于ASIC或FPGA方案来增强端侧计算能力?
1. 任务特化:为何用 DSP?
核心是 “将低复杂度更新任务从 GPU 卸载”。在 AI 微调(如 LoRA)中,优化器状态更新涉及海量、简单且高度并行的张量运算(加、乘等)。DSP 架构天生为高效 MAC(乘累加) 和向量运算设计,无需处理复杂控制逻辑,能以极高能效比处理这类“低复杂度、高重复性”的数学运算,比对口。
2. 功耗、成本与形态的极致妥协 (PPA)
方案采用标准 M.2 SSD(如 aiDAPTIV+ 的 PASCARI AI100E)。在 M.2 狭小空间与个位数瓦特功耗限制下,塞入发热大、成本高的独立 FPGA 不现实。群联 E28 主控采用 6nm 工艺,将 “Advanced math engine DSP” 作为 IP 模块内置集成到 SoC 内部,实现特定领域 ASIC 化。这未破坏标准 SSD 形态,并极佳地控制了成本与功耗,支持大规模量产。
3. 存储技术的自然延伸(LDPC 与 AI 算力复用)
高端 SSD 主控本就依赖强大 DSP 进行 LDPC(低密度奇偶校验) 软判决解码纠错。群联很可能是将用于信号处理的 DSP 架构深度增强与通用化,使其在闪存纠错间隙或通过专属通道,并行处理 aiDAPTIVLink 下发的 AI 张量计算任务,实现算力复用。
总结: 传统基于 FPGA的方案是“带存储的异构计算平台”,适合定制化科研。而群联 E28 内置 DSP 走的是 “原生存储主控的 AI 算力扩维” 路线。它以最低的硅面积与功耗代价,精准切中“大模型显存卸载与低复杂度预处理”痛点,是一套高度商业化、注重落地性价比的存储架构设计。

通过将 AI 微调中的“参数更新(Update)”环节卸载到存储端的 DSP 上运行,可以构建出高效的异步并行流水线,从而大幅提升 GPU 的利用率和整体训练速度。
在传统的 AI 训练中(上半图),GPU 必须串行完成前向传播、反向传播以及最后的参数更新,这导致 GPU 在处理相对低复杂度的更新任务时,其核心计算资源未能得到最大化利用。
而创新的 DSP 架构(下半图)将“参数更新(U)”这一步骤剥离,交由固态硬盘主控内建的 DSP 异步处理。这使得昂贵的 GPU 资源能够被迅速释放,去执行下一个批次的重度计算任务(F 和 B),最终通过这种近数据并行处理机制,实现了整体耗时缩短和 40% 的性能飞跃。
参数更新任务卸载到DSP端的价值分析
- 参数更新(U):轻度内存带宽密集型(Memory-Bound) 参数更新阶段(例如使用 Adam 或 SGD 优化器),是根据 B 阶段算出的梯度(Gradients)来修改模型的权重(Weights)。在数学上,这主要是张量之间的“逐元素(Element-wise)”运算——也就是简单的对应位置相加、相乘、标量乘法或求平方根。这种线性计算没有复杂的矩阵变换,对算力的要求很低,DSP 完全能够轻松且高效地胜任。
数据局部性与消除 PCIe 瓶颈(Near-Data Processing)
这是从存储架构角度解释最核心的一点。
在大模型微调(特别是像 ZeRO-Offload 这样的显存优化技术)中,由于 GPU 显存装不下所有的东西,系统通常会把最占空间的 “优化器状态(Optimizer States,通常是模型参数大小的 2 到 3 倍)” 存放在主机的内存或 SSD 中。
- 如果让 GPU 做更新任务(传统方式): 系统必须通过 PCIe 总线,将庞大的优化器状态从 SSD 读取到 GPU 显存 GPU 进行简单的逐元素加减乘除 再把更新后的状态通过 PCIe 写回 SSD。这种方式中,GPU 强大的算力大材小用,不仅等待数据浪费了时间(GPU Idle),而且来回搬运海量数据会瞬间把 PCIe 接口的带宽撑爆。
- 如果让 DSP 做更新任务(aiDAPTIV+ 方式): 既然“优化器状态”本来就保存在这块 SSD 里面,那么当 GPU 算完梯度后,只需要把相对较小的“梯度数据”发给 SSD。SSD 内部的 DSP 直接在存储介质旁边“就近”读取状态、完成简单的加减法更新,然后直接写回底层的闪存颗粒。 这不仅完美利用了 DSP 的特性,还彻底消除了数据在 GPU 和 SSD 之间来回搬运的“额外 PCIe 跳数(extra PCIe hop)”。
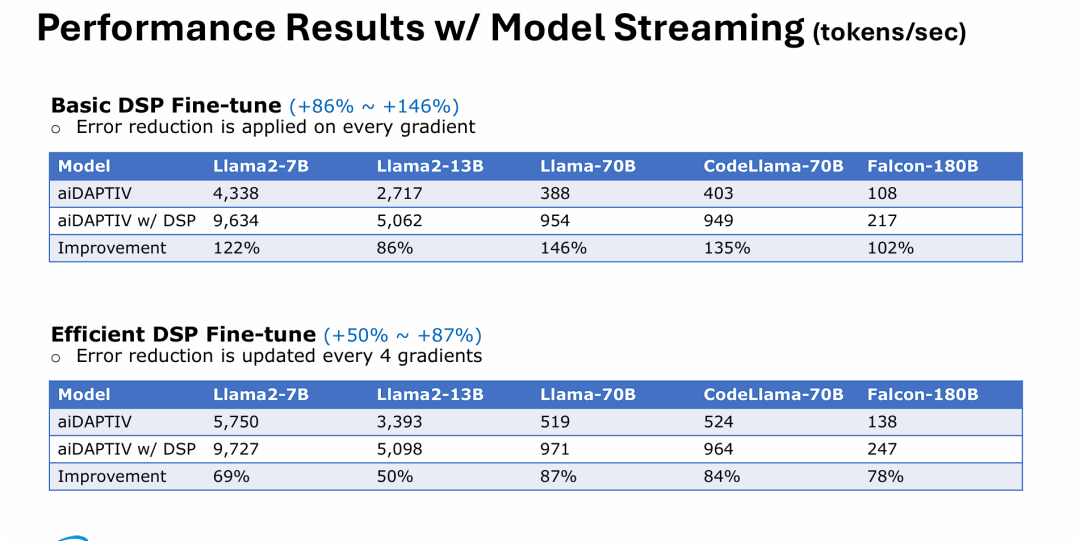
基于实测数据证明,在固态硬盘主控中引入 DSP 进行“参数更新卸载”,能够为各种规模的大模型微调带来极为可观的绝对性能提升。
数据表明,无论是高频更新(Basic)还是低频更新(Efficient)策略,DSP 都能有效打破系统瓶颈。特别值得注意的是,在基础微调模式下,对于像 Llama-70B 这样参数量巨大的模型,性能提升甚至可以达到近乎 1.5 倍(146%)。这从定量角度印证了前一张 PPT(异步并行流水线) 中提到的理论架构优势:即把低复杂度的“脏活累活”交给存储端的 DSP,让 GPU 专注算力输出,确实能实现“1+1>2”的系统级加速效果。
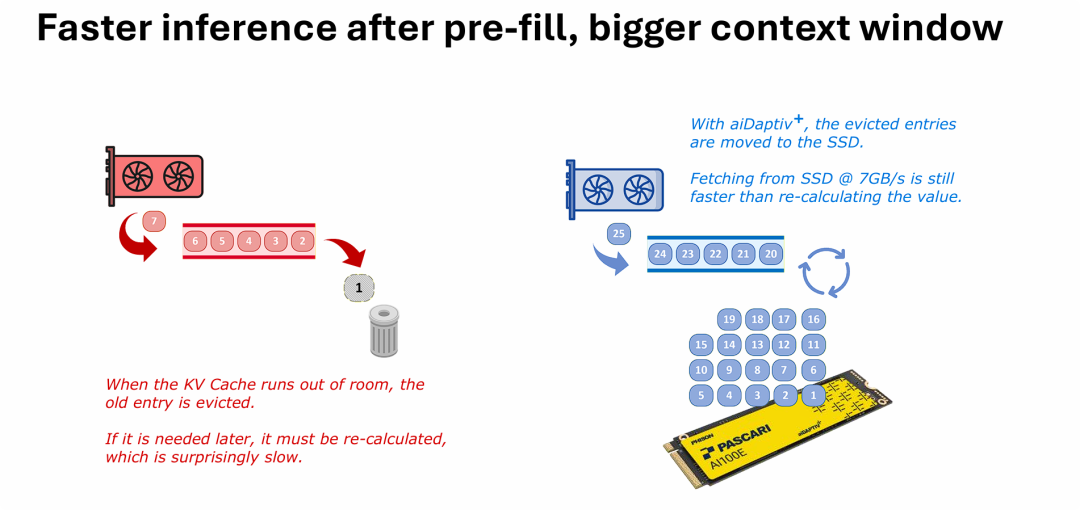
利用高速 SSD 充当大模型推理时的超大外部 KV Cache 池,能够以极低成本解决长文本(上下文窗口)推理时的显存瓶颈与延迟问题。
在生成式 AI 进行长对话或处理长文档时,系统需要维护庞大的 KV Cache(历史上下文状态)来保证生成的连贯性。传统架构受限于昂贵且容量有限的 GPU 显存,一旦显存爆满,系统只能丢弃早期的上下文(Eviction);如果后续生成又需要参考这些被丢弃的上下文,GPU 就必须从头重新计算这些 Token 的状态,这会引发严重的计算延迟。
群联的方案巧妙利用了高性能 NVMe SSD(如图中提供 7GB/s 读写带宽的盘)作为显存的溢出层。当 GPU 显存放不下时,历史 KV 状态会被“转移”而非“丢弃”到 SSD 中。
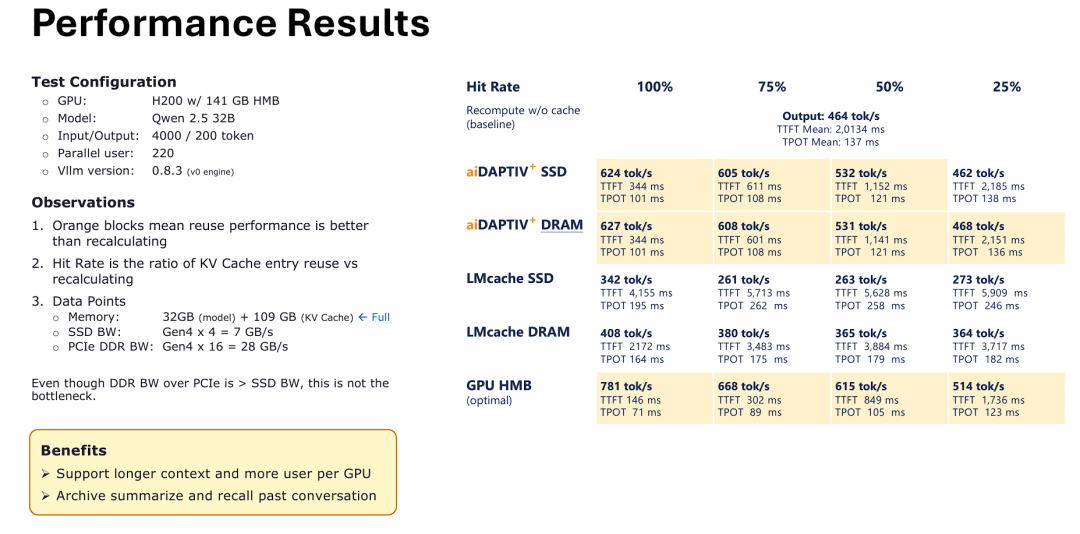
通过量化的 Benchmark 跑分数据,证明了群联 aiDAPTIV+ 架构在处理 LLM 长文本高并发推理时的巨大优越性。
在 220 个并发用户瞬间塞满 H200 这张顶级显卡 141GB 显存的极端压力测试下,传统的卸载框架(如 LMcache)成为了严重的系统累赘——由于 I/O 调度低效,从 SSD 或系统内存(DRAM)中读回 KV Cache 的速度,甚至还不如直接让 GPU 暴力重新计算来得快。(这一测试结果存疑,LMCache虽说核心创新在算法上,但不至于表现如此落后。)
相比之下,aiDAPTIV+ 技术展现出了惊人的调度效率。只要缓存命中率达到 50% 以上,使用普通 PCIe Gen4 SSD 进行卸载的性能就能显著超越 GPU 重算(Gen4 已经在PC端广泛部署)。更令人震撼的是,“aiDAPTIV+ SSD”的性能表现几乎完美咬合了“aiDAPTIV+ DRAM”的表现(624 vs 627 tok/s,100% 命中在现实场景中的可能性不大)。这直接论证了左侧图文的结论:物理带宽(7GB/s vs 28GB/s)在这里已经不是瓶颈,群联的中间件成功掩盖了 SSD 的物理延迟。这项技术切实达成了“用廉价 SSD 容量换取昂贵 GPU 算力”的商业目标。
延伸思考
这次分享的内容就到这里了,或许以下几个问题,能够启发你更多的思考,欢迎留言,说说你的想法~
- aiDAPTIV+在高并发推理中,SSD耐久性与WAF如何长期把控?与CXL内存池化相比,谁更适合企业On-Premise?
- 存储厂商主导AI中间件,能否颠覆GPU生态?DSP卸载会引发哪些新的软件优化挑战?
- 对于预算有限的高校实验室,这种方案的实际落地ROI如何评估?
原文标题:Computational Storage Drive for LLM[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #KVCache优化 ---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号