SSD计算卸载:解锁线性扩展潜力


阅读收获
- 量化传统架构浪费:48盘NVMe柜内部768 GB/s带宽受128 GB/s接口限83%闲置,指导存储选型避开I/O瓶颈。
- 掌握主机编排卸载流程:SSD内CMB处理哈希/压缩/RAID,减少主机DRAM/PCIe负载3.8x-95%,优化数据中心资源分配。
- 对比In-Storage vs DPU:前者线性扩展无集中瓶颈,适用于高吞吐全闪阵列;后者强全局感知,适合分布式网关,提升架构决策准确性。
- 实测验证扩展性:卸载后CPU L3缓存污染减、后台任务加速30%,为证券分析提供TCO降低依据。
背景介绍 | 全闪存存储计算卸载新范式
全闪存时代,SSD性能迅猛提升,高密度NVMe盘柜(如48盘位)内部聚合吞吐可达768 GB/s,但传统“存算分离”架构受外部接口(如128 GB/s)限制,导致超83%的内部PCIe带宽闲置,主机端需堆叠CPU/内存/DPU处理数据缩减(去重/压缩)和保护(RAID/纠删码),引发成本高企和扩展瓶颈。你是否遇到过PCIe带宽“漏斗效应”,或DPU在多SSD场景下成为新瓶颈?
本文基于FMS25 PPT,剖析“主机编排的计算卸载”(Host Orchestrated Compute Offload)架构:在SSD内集成高能效引擎,利用NVMe CMB/SLM闭环执行哈希、压缩、校验任务,主机仅管控制面。实测显示,卸载后主机DRAM带宽降3.8x、CPU释放2核,RAID Scrubbing时间缩短30%。与DPU比较,该方案实现真正线性扩展,盘活闲置带宽。面对AI/数据库高吞吐需求,这种分布式卸载如何重塑存储TCO?
👉 划线高亮 观点批注
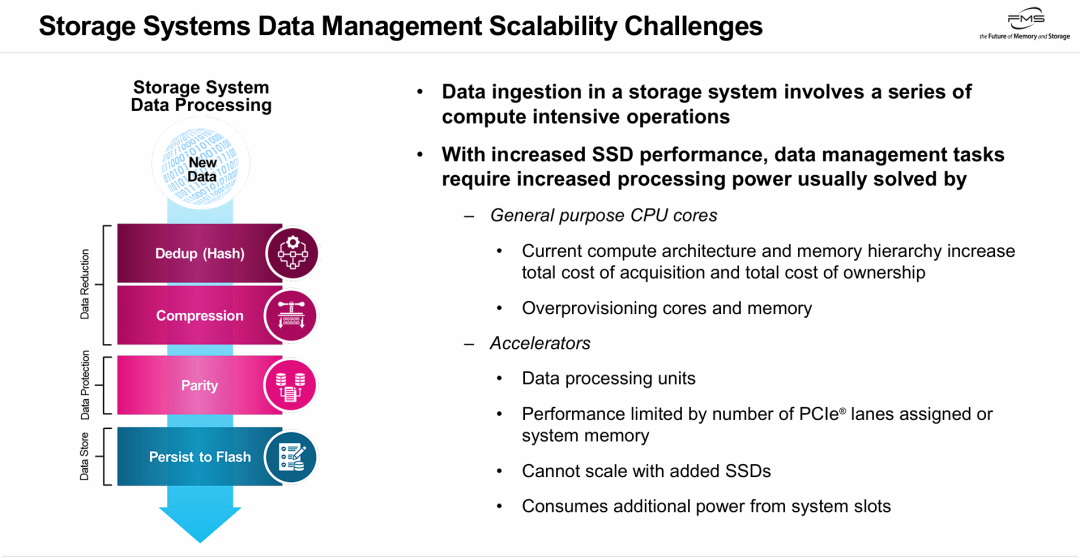
PPT的核心观点是:在全闪存时代,随着SSD性能的快速提升,传统存储系统中负责数据缩减(去重/压缩)和保护(校验计算)的计算密集型流水线面临扩展瓶颈。
为了匹配高性能SSD的数据摄取速度,现有架构若单纯依靠堆叠通用CPU算力,会导致成本高企且资源浪费(过度配置);而若采用DPU等硬件加速器,虽然卸载了计算,但受限于PCIe通道带宽和供电,当系统中增加更多SSD时,加速器本身会成为瓶颈,无法实现线性扩展。存储行业需要新的架构缓解算力与存储介质性能不匹配。
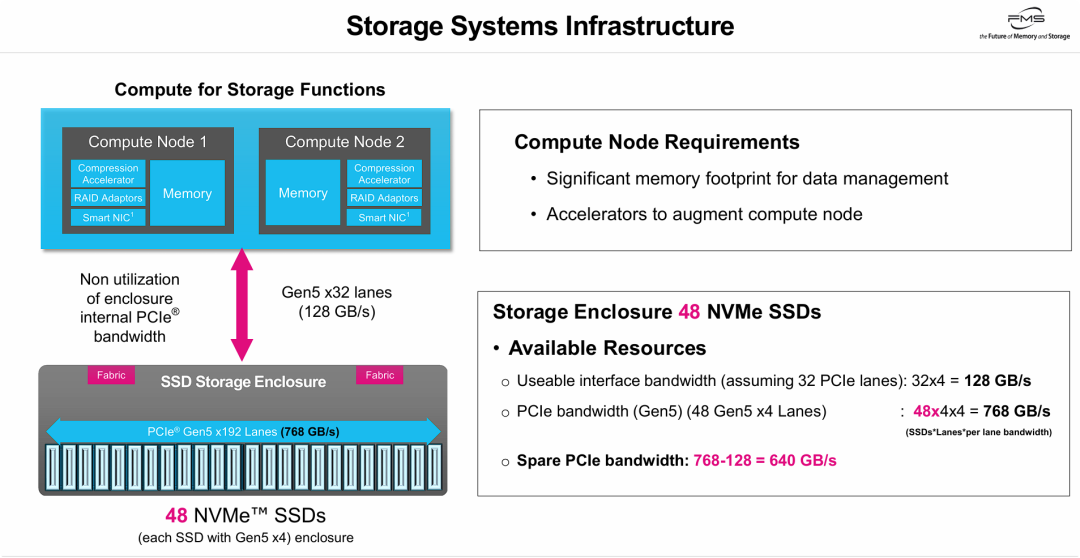
当前“存算分离”或传统外置存储架构在PCIe Gen5时代的带宽错配与资源浪费问题(网络/接口瓶颈)。
其核心观点在于:现代高密度NVMe盘柜(如48盘位)内部聚合吞吐达768 GB/s。然而,由于连接计算节点与存储盘柜的外部接口带宽受限(仅为128 GB/s),导致 640 GB/s(占比超83%)的盘柜内部PCIe带宽无法被前端业务利用。同时,为了处理这些高速数据,前端计算节点需堆叠大量内存和加速器。这种架构造成性能浪费,显示传统计算节点I/O吞吐落后于闪存介质发展。
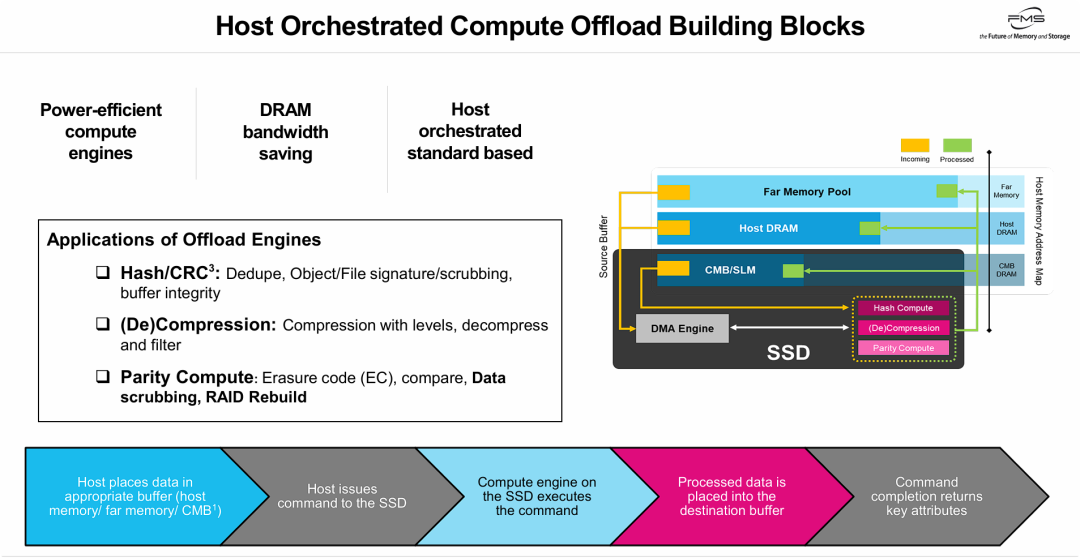
PPT展示了一种名为 “主机编排的计算卸载(Host Orchestrated Compute Offload)” 的新型存储架构解决方案。
其核心观点是:通过在SSD内部集成专用的高能效计算引擎(用于哈希去重、加解压缩、纠删码等计算密集型任务),将原本由主机CPU承担的繁重存储服务下放给底层的SSD硬件来完成。 同时,该架构强调 “主机编排(Host Orchestrated)” ,即控制面和数据面分离——主机端依然保留对整个流程的控制权(决定数据放在哪里、下发什么命令),但数据处理的具体执行面由SSD内的DMA引擎和加速模块来闭环。这种架构显著节省主机DRAM带宽,降低主机CPU负载,基于标准协议(如NVMe的CMB特性)实现,为现代存储系统提供高效、可扩展的数据处理路径。
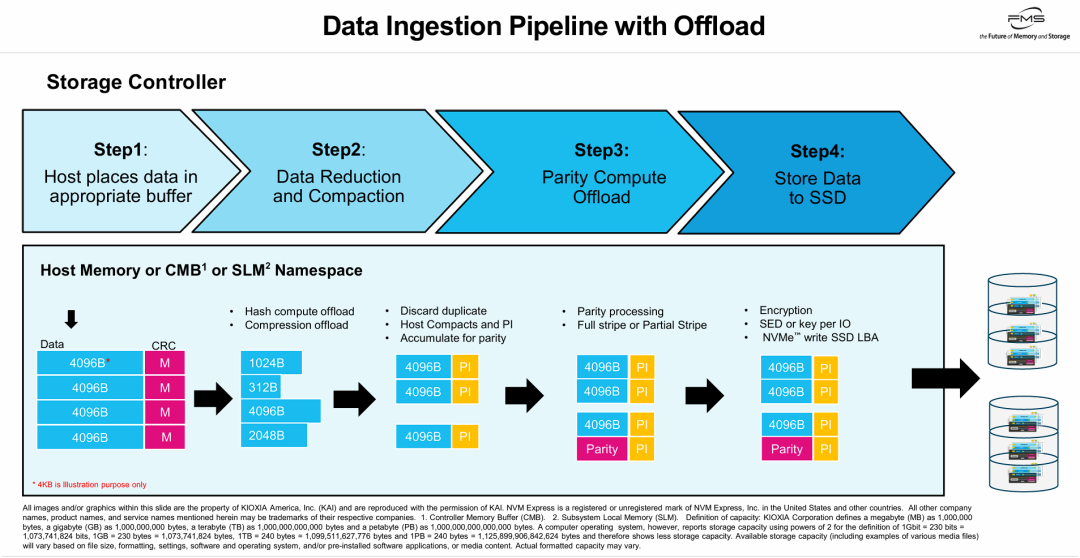
展示了一个结合了硬件加速卸载(Offload)的现代化全闪存存储控制器的数据摄取(Data Ingestion)全生命周期流水线。
其核心观点在于:通过利用CMB(控制器内存缓冲区)或SLM(子系统本地内存)作为数据流转的“枢纽”,存储系统能够将消耗大量CPU资源的“哈希去重”、“数据压缩”和“奇偶校验(如RAID/纠删码)”等重负载任务卸载给专用硬件。 图表清晰地演示了数据在内存中是如何被压缩成变长数据块、去除重复项、重新紧凑打包(Compaction)成对齐的4KB块并附加端到端保护信息(PI),最终生成条带校验位并安全加密写入NVMe SSD的过程。这种流水线设计优化了I/O路径,减少主机计算和内存带宽压力,同时保证数据安全与写入效率。
===
- 初始阶段: 蓝色的原始数据块,每个大小为4096B(下方红字标注“4KB仅供说明之用”),并附带紫色的“CRC (M)”校验码。
- 缩减阶段(对应Step 1向Step 2过渡): 执行“Hash compute offload(哈希计算卸载)”和“Compression offload(压缩卸载)”。可以看到原始的4096B数据被压缩成了不同大小的块(如1024B、312B、2048B,其中一个保持4096B说明不可压缩)。
- 压实阶段(对应Step 2): 执行“Discard duplicate(丢弃重复数据)”、“Host Compacts and PI(主机进行压实并添加保护信息)”、“Accumulate for parity(累积以进行奇偶校验)”。此时,不同大小的压缩数据被重新打包(Compaction)成标准的4096B块,之前的一个重复块被丢弃,并且每个块都附加了黄色的“PI”(Protection Information,数据保护信息,通常指端到端的数据保护如T10-DIF/DIX)。
- 奇偶校验阶段(对应Step 3): 执行“Parity processing(奇偶校验处理)”、“Full stripe or Partial Stripe(全条带或部分条带计算)”。生成了一个粉红色的“Parity(奇偶校验位)”数据块,并同样带有黄色的PI标签,与前述数据块组成一个条带(Stripe)。
- 存储阶段(对应Step 4): 执行“Encryption(加密)”、“SED or key per IO(自加密驱动器或基于每个IO的独立密钥)”、“NVMe™ write SSD LBA(通过NVMe协议写入SSD的逻辑块地址)”。黑色的粗箭头指示这组带有校验和保护信息的数据最终被写入右侧圆柱体代表的底层SSD阵列中。
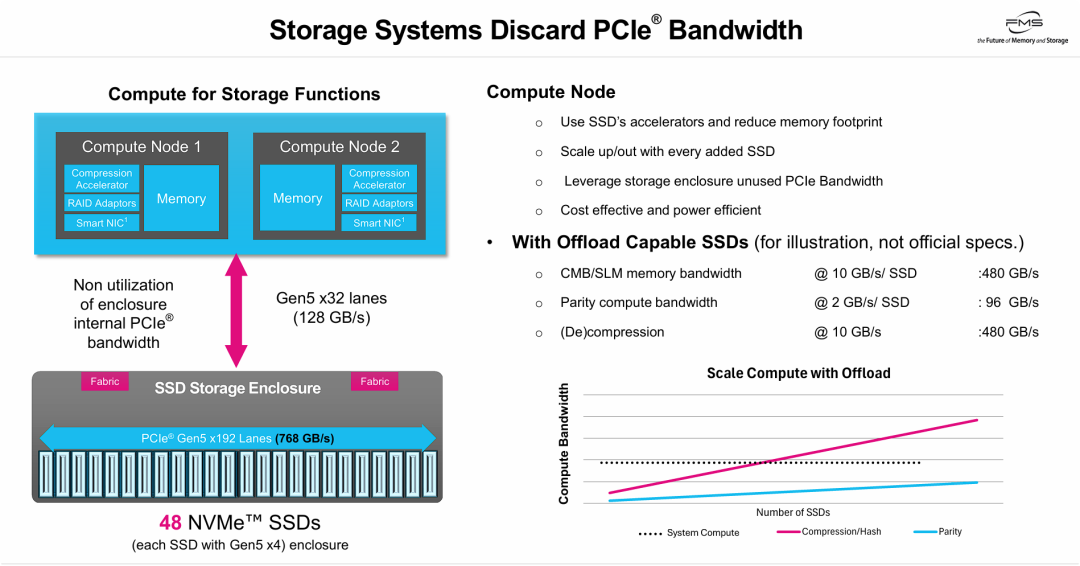
PPT的核心观点是:通过“支持计算卸载的SSD(Offload Capable SSDs)”,有效缓解传统存储架构中PCIe带宽浪费和算力扩展瓶颈。
左侧图表重申传统架构下,存储盘柜内部768 GB/s带宽受限于前端128 GB/s网络接口浪费。右侧给出解决方案:将加解压缩、哈希计算和奇偶校验任务下放到SSD中。右下角图表显示分布式硬件卸载的关键特性——线性扩展性。传统集中式系统算力固定,而卸载架构下,压缩和校验能力随SSD数量按比例提升,盘活盘柜内部数百GB/s带宽,降低主机资源开销和功耗。
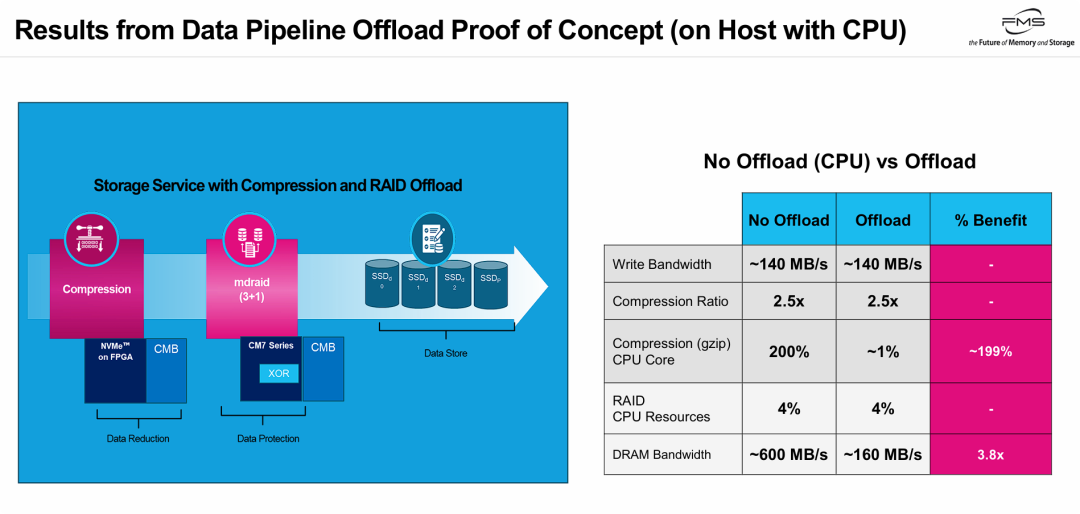
PPT展示了一个完整的数据流水线硬件卸载(硬件压缩 + 硬件RAID计算)概念验证(PoC)的成功结果。
其核心观点通过右侧数据体现:在保持相同存储性能(写入带宽)和数据缩减效果(压缩率)前提下,将计算密集型任务卸载到支持CMB硬件(如FPGA和CM7系列SSD),释放主机资源。
具体而言,该方案消除主机CPU数据压缩负担(释放2个CPU核心),数据在CMB间流转,避免主机内存/PCIe搬移,DRAM带宽占用降3.8x。这种优化让主机CPU/内存投入核心业务(如数据库查询、AI推理),改善数据中心TCO和能效比。
存储内计算卸载 vs DPU卸载
分析维度 | 存储内计算卸载 (In-Storage Compute / 盘级卸载) | DPU 卸载 (DPU Offload / 节点级卸载) |
|---|---|---|
架构重心与位置 | 完全分布式。计算引擎位于单个SSD控制器内部(利用CMB/SLM)。 | 局部集中式。计算引擎位于连接网络与主机的DPU板载SOC中。 |
数据流向与I/O路径 | 主机 PCIe总线 SSD内部闭环处理 NAND介质。 | 网络/主机 PCIe总线 DPU处理 PCIe总线 多个底层SSD。 |
主机CPU/内存负载 | 极低。主机仅负责下发控制指令和元数据。 | 极低甚至为零。DPU接管数据面,裸金属架构下主机甚至不感知底层I/O。 |
PCIe总线负载 (关键差异) | 最小化/负放大。数据在盘内过滤或压缩后,有效减少了在PCIe总线上的物理传输量。 | 易产生瓶颈(漏斗效应)。所有进出后端数十块SSD的数据都必须先挤过DPU有限的PCIe通道。 |
系统扩展性 (Scalability) | 近似线性扩展。每增加一块SSD,系统聚合计算算力和内部带宽按比例增加,无集中瓶颈。 | 受限于DPU性能天花板。后端增加过多高速SSD会导致DPU算力或PCIe接口带宽耗尽。 |
全局感知与处理能力 | 弱(仅限单盘局部)。每块盘只“看”得到自己的数据,无法高效执行跨盘全局去重或分布式纠删码。 | 强(具备节点全局视野)。掌握流经节点的所有数据,非常适合全局数据去重、跨盘RAID/EC计算。 |
核心优势 | 缓解I/O带宽限制,低功耗,按需扩展算力。 | 强大的网络协议转换(如NVMe-oF),多租户隔离,全局存储策略。 |
典型适用场景 | 数据库查询下推(谓词过滤)、单盘透明加解压缩、海量日志检索、极高吞吐要求的全闪阵列。 | 云服务商裸金属架构、分布式存储网关、全局重复数据删除、复杂的存储网络路由。 |
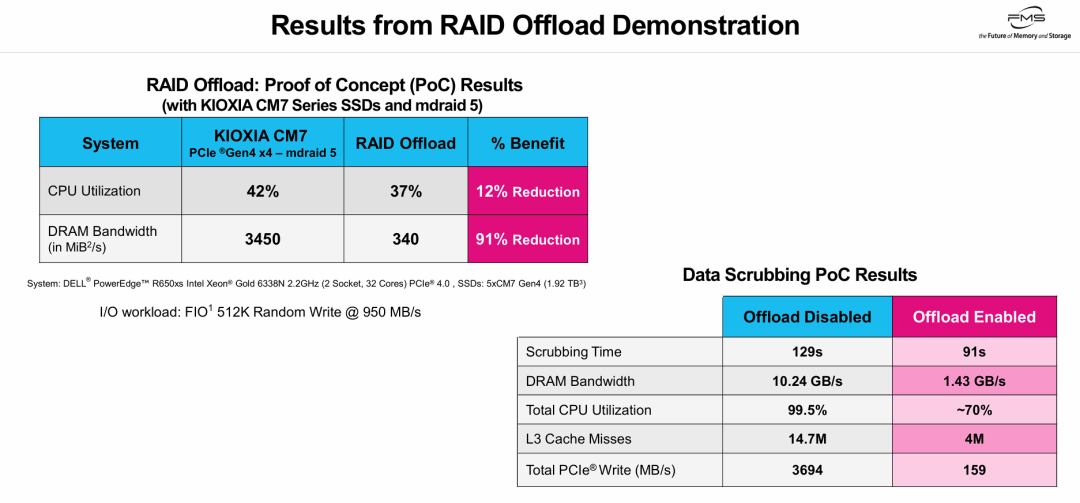
通过两组实测数据(RAID 5随机写与后台清理),显示存储内计算卸载对主机资源的影响。
- 缓解“数据搬运税”: 前台写入和后台Scrubbing中,卸载将DRAM带宽降约90%,PCIe写入流量减95%。底层校验数据在SSD内闭环处理。
- 改善主机效能: 卸载XOR校验后,主机CPU占用降低,L3缓存污染减少(Cache Misses减)。后台任务耗时缩短(129s→91s)。
图表量化卸载效果:服务器CPU/内存从存储计算中释放,服务上层业务。

现代存储数据管理(如压缩、去重、RAID校验)本质为计算任务,卸载到底层硬件是大势。这种主机编排和标准协议卸载,让现有应用平滑接入,盘活盘柜内部PCIe带宽。
它提供良好扩展性:整体算力和吞吐随SSD数量近似线性增长,不再受单一主机CPU或DPU限制。
延伸思考
- 在跨盘全局去重或分布式纠删码场景下,SSD内卸载的局部视野如何与主机编排结合,避免性能折衷?
- 基于NVMe标准协议的卸载兼容现有生态,但面对QLC SSD耐久性和功耗挑战,如何确保大规模部署的经济性?
- 与CXL内存扩展相比,这种分布式计算卸载是否能更好地解决AI负载下的KV Cache瓶颈,为什么?
原文标题:Offload Fixed Function Storage Services to Storage Subsystem[1]
Notice:Human's prompt, Datasets by Gemini-3-Pro
#FMS25 #xPU卸载与计算型存储
---【本文完】---
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号