讨论什么是 企业可信 AI 数据库--疯狂Move杭州 24小时

讨论什么是 企业可信 AI 数据库--疯狂Move杭州 24小时

AustinDatabases
发布于 2026-04-02 17:09:56
发布于 2026-04-02 17:09:56
视频为博主新技能,开始会自己拍摄,剪片子了,多一项技能,多一分精彩。
最近参加了一次小型的,且非常有意思的,基于企业AI数据库的小型播客节目,本片这里仅表达参加此次小型论坛的感想和新的认知。
这次节目最有意思的是,主持节目是业界大名鼎鼎的,中国互联网与TMT领域的资深风险投资人,庄明浩,庄老师。曾任经纬创投(经纬中国)VP、熊猫直播联合创始人。
同时另一位嘉宾也是业界非常著名的数据库专家,戴涛戴老师,他也是OceanBase AI业务总经理。
整体的节目,想在整理一期,具体的对话内容里面资深的数据库专家,戴涛戴老师,那说起数据库是滔滔不绝,我本次去也是本着学习的态度。我也特别想听听,不是数据库圈的投资圈老师的对数据库业界的看法,这不说嘛,当事者迷,圈外又是怎么看数据库这圈里的事情的。
下面是我此次参加这次对话节目我想到的问题!

我们从哪里开始呢,我们从全民养虾开始,OpenClaw,特别想先给OpenClaw泼一盆凉水,没有中大型企业愿意,或者可以去使用openclaw,试用不算。
OpenClaw的核心逻辑是,先执行后思考,他要先读取数据,先进行超级管理员的操作,拿到数据后,再进行思考。如果在操作中有一个 rm -rf ,或者 drop table ,drop database,的命令呢?
同时乌托邦式的“技能包”窃取企业的环境变量,API KEY,甚至是企业内外的访问权限,而且这些技能包集成了主程序的全部权限。
哪个企业敢用呢?那个正规的企业敢用呢?甚至我这个人,有点安全意识的人都不敢用。这和裸体在大街上,闲逛有什么区别。
如果我是一个数据库架构师的角色,或者CTO的角色呢? 现在企业做AI,做Agent的方法是不是也是技术的拼凑呢? 如同曾经大数据的获得数据,处理数据的系统,有各种的数据库的存在,还有各种ETL软件的存在,这些数据经过拼凑,到达了大数据系统。
不同技术之间的连通性,兼容性,适配性是不是都要经历一轮不长不短的时间的磨合,而从数据的角度,我们的数据是不是要在多地存多个版本,多个副本,多个地方的数据留存。
作为企业的数据库架构,或者软件架构,在或者 CTO,我们不禁要问几个问题?
1 数据的一致性如何保障,我怎么能保证从数据库出去的数据,在流转中,到大数据后,数据是完整的,不缺失的,语义正确的。
2 数据传输的效率,数据的延迟,这点非常重要,
3 多种系统的成本,尤其是重复数据的存储成本消耗,与这些数据的对齐的成本
如果我们通过 AI ,AI Agent 去大数据获取数据,作为投喂的数据,获取的数据在不同的数据库中进行,在AI获取投喂的数据因为延迟,获取到了错误的数据,过时的数据,而在错误的数据的指导下 AI Agent操作失误了,造成的企业的经济损失,由谁来承担?
在企业AI的环境中我们更应该保证,数据的准确性,时效性,所以目前很多企业的数据库系统都没有做好准备,迎接AI的时代,能更好的利用AI和AI agent。
这是第一部分的问题。
假设把这些都解决了呢? 这刚刚是第一步,在数据的处理中,我们依然存在着打补丁的情况,传统数据库处理矢量计算,矢量数据,甚至存储矢量数据都是问题,那么我们又引入了矢量数据库,pgvector,MongoDB Altas,Pinecone ,而我们全文索引的查询又要ES来加入。
我们整体在AI 数据库获取,处理,查询的路径太多了,查询效率太低。同时在企业系统运维中,企业的IT管理人员非常希望一个项目中介入的产品少一些,不同产品之间的对接,适配,非常的困难,且容易在运行中出现各种各样的问题。
所以我们现在针对AI有了AI数据库了吗? 我不认为现在的这种缝合式的数据库产品是企业AI数据库应有的样子。
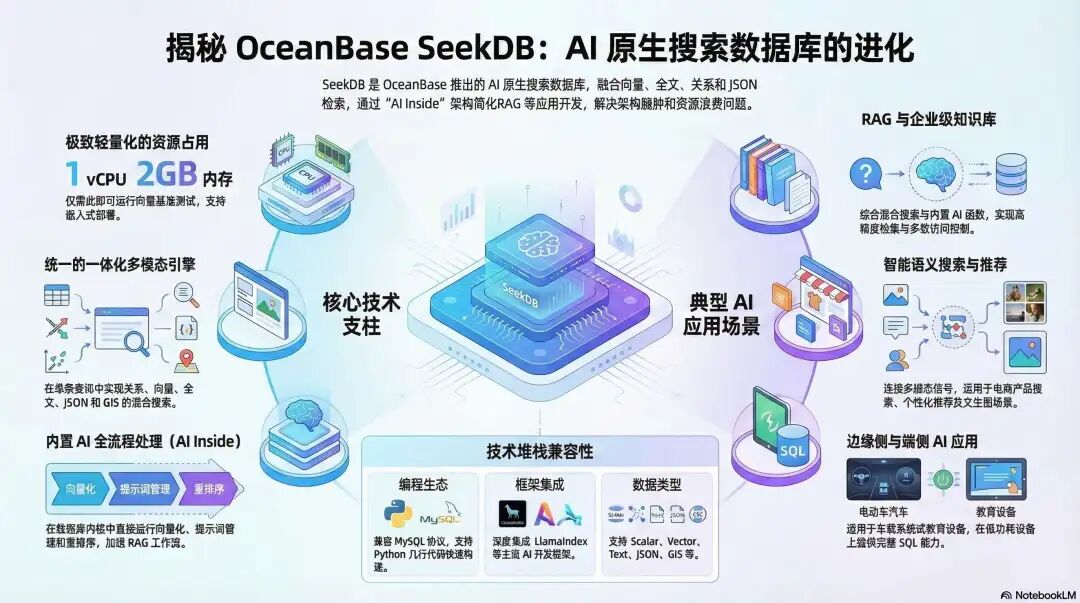
oceanbase AI 图谱
假想我们统一了数据库,统一了数据处理的流程或者路径,就是一个好的AI数据库吗?
这里有一个简单的问题,想问看到这篇文章的读者。
标量计算,和语义的向量搜索,现在都是 hybrid 搜索,在数据的处理中,我们应该怎么去过滤数据的问题,我是应该先处理标量的查询,然后在进行矢量的计算,还是反过来。
怎么样的计算成本更低,如果这些数据分散在不同的类型的数据库中,我又怎么来去界定呢?我应该怎么查询呢?
这些数据如果在一个数据库中存储,且用一个引擎来处理,是不是就能解决问题了,他可以对这些数据以及要进行的查询,进行判断,且有可以优化数据的基础。
除了这些,我们在AI数据处理中,尤其是上下文存储,对话分析的信息存储也是我们注意,上下文其实也有 热点和冷点,比如我现在说的话题,上周也提过,我也发表过一些观点。那么这些信息要存在哪里,怎么进行存储。AI 又怎么利用这些呢?
这些说完,我这里还要补刀,企业使用AI中最重要的一点,也是不可以逾越的一点。企业数据的安全使用,这也是当前openclaw继续是这个状态下,我不看好的根本原因,
企业根本不可能考虑现在的openclaw使用方式,现在的openclaw有三个致命的地方,让企业无法容忍
1 私密数据访问权
2 外部通信的数据把控权直接丧失
3 指令执行中的数据正确获取使用权根本没有地方设置
这里面我们单独挑出一点,企业就完全有100%的底气,拒绝openclaw。关键的问题是,数据库无法处理,或者说数据库是数据库,大模型是大模型,我们希望的AI的终极模式,是将数据库内置推理引擎,通过SQL来调用,数据库就是 AI 数据 处理一体化的产品,这才是企业要的可靠,可信赖,可操作的 AI系统。
在这个节目里面,我和二位老师进行了深层次的讨论,感兴趣的可以看看,庄老师的节目,能不能帮到你,原文也会在整理后,再写一篇。
oceanbase AI 图谱
OB 的AI发展
OB 的AI发展

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-29,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号