CVPR2025|免训练的工业缺陷检测 SUPERAD

CVPR2025|免训练的工业缺陷检测 SUPERAD

OpenCV学堂
发布于 2026-04-02 20:33:48
发布于 2026-04-02 20:33:48
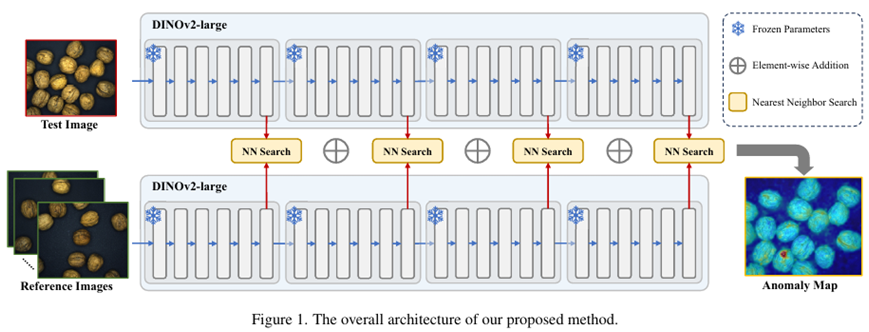
SUPERAD方法的核心思想是对于数据集中的每个类别,构建一个包含16张正常参考图像的记忆库。这些参考图像的选择遵循两步程序。首先使用DINOv2模型从所有训练图像中提取CLS token表示。然后,应用与Patchcore相同的贪心核心选择方法,将这些特征向量分组为16个集群。这种策略在保持所有特征分布不变的情况下,最大限度地提高了类别内不同正常模式覆盖率,从而增强了参考集的代表性,并减少了误报率。

推理测试阶段
对于每个测试图像,首先使用DINOv2模型提取多层次特征。对于每个特征级别,计算测试图像特征与存储在记忆库中的特征之间的相似度,以检索最近的邻居信息。SUPERAD方法基于以下假设:测试图像中的正常区域倾向于在参考图像中找到相似的区域,而异常区域则缺乏这种匹配。通过评估每个空间位置的相似性,为每个级别生成一个异常映射。最后,这些异常映射被平均并上采样到原始分辨率,以生成最终的异常分割图。
方法训练与数据集评估
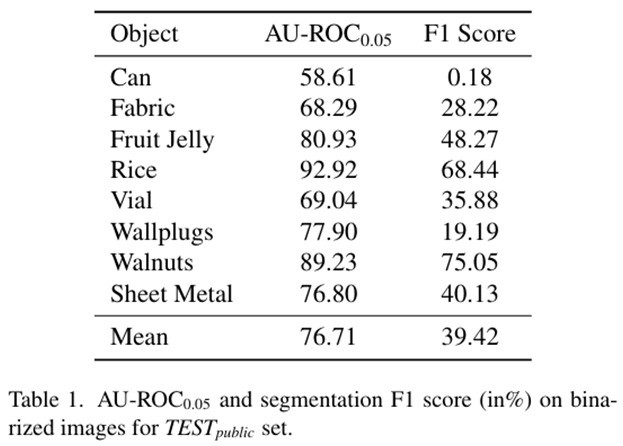
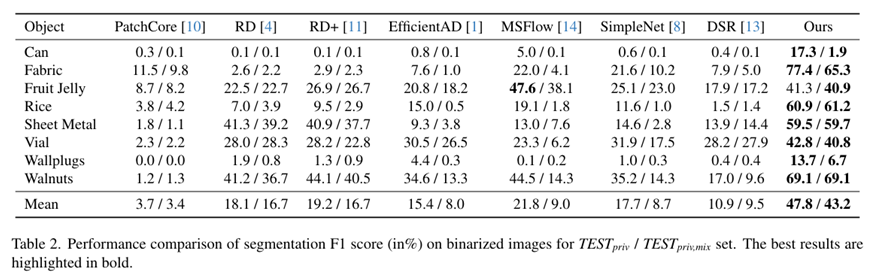
SUPERAD方法不需要训练。对于MVTec AD 2数据集中的每个类别,我们使用训练集中的样本构建少量正常参考图像的特征记忆库。参考样本的数量固定为16。我们采用预训练的DINOv2 ViT-L-14模型作为特征提取器,该模型包含24层变压器和约3亿个参数。从四个特定的层次中提取特征(6、12、18、24)生成最终的异常分割Map。最终在英伟达3090 24G硬件可以直接运行。实验结果对比:
论文地址
https://arxiv.org/pdf/2505.19750学习OpenVINO2025
大模型部署开发
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号