刷爆榜单 | DeepSeek-AI发布3B OCR模型

刷爆榜单 | DeepSeek-AI发布3B OCR模型

OpenCV学堂
发布于 2026-04-02 21:33:04
发布于 2026-04-02 21:33:04

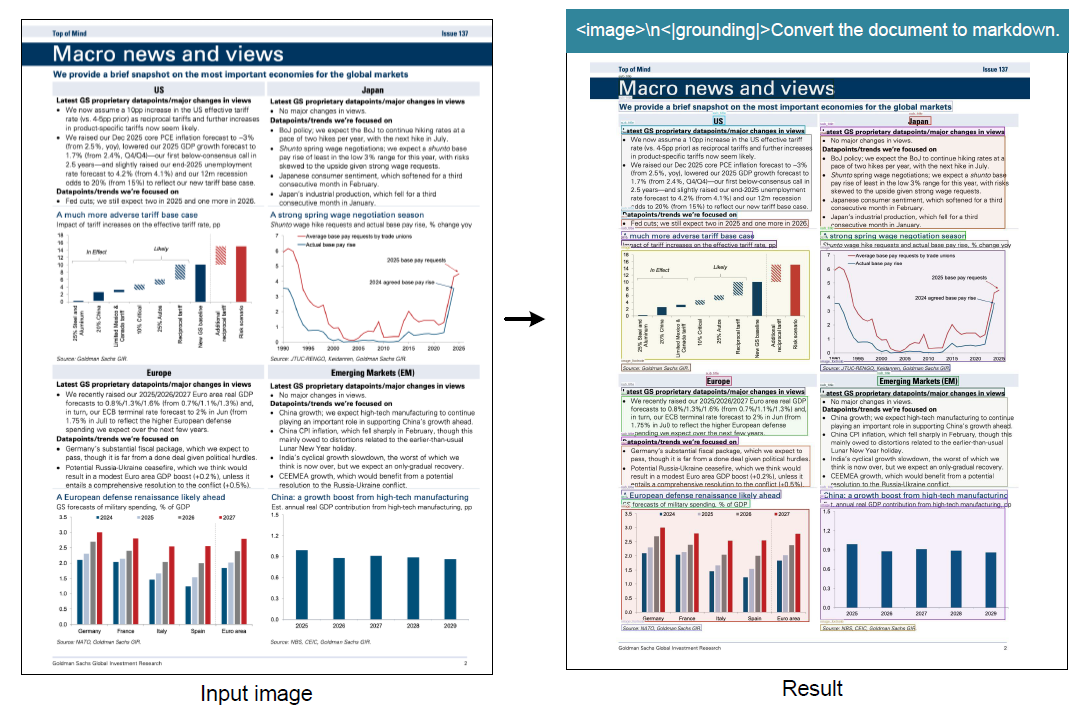
DeepSeek-AI 发布了 3B DeepSeek-OCR,这是一个端到端的 OCR 和文档解析视觉语言模型 (VLM) 系统,可将长文本压缩成一小组视觉标记,然后使用语言模型解码这些标记。该方法很简单,图像带有紧凑的文本表示,从而减少了解码器的序列长度。研究团队报告称,当文本标记在 Fox 基准测试中视觉标记的 10 倍以内时,解码精度为 97%,即使在 20 倍压缩时也有有用的行为。它还在 OmniDocBench 上报告了比常见基线少得多的token的竞争结果。
架构
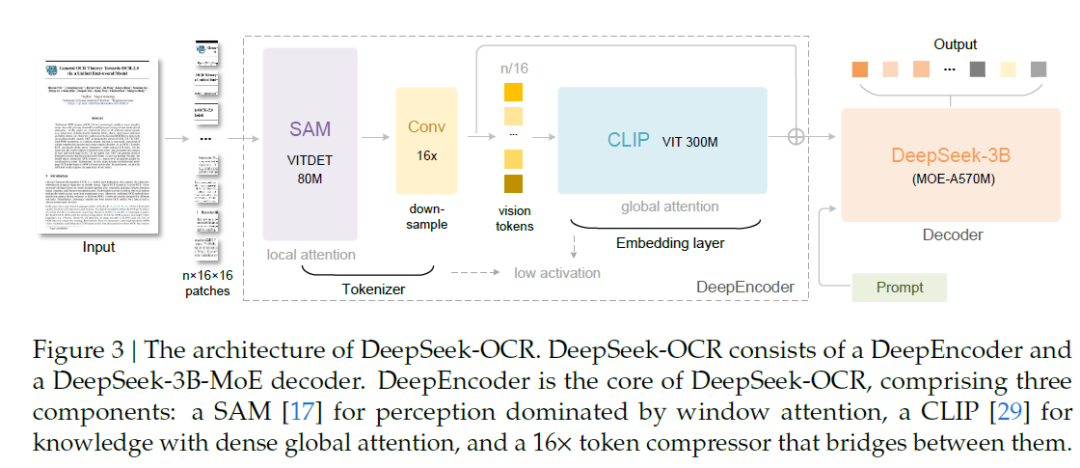
DeepSeek-OCR-3B是典型的VLM模型、它有两个组件,一个名为 DeepEncoder 的视觉编码器和一个名为 DeepSeek3B-MoE-A570M 的 Mixed of Experts 解码器。
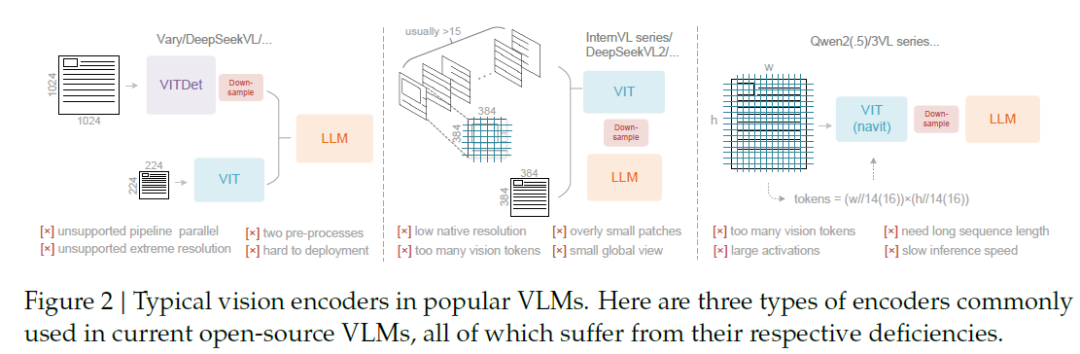
该编码器专为高分辨率输入而设计,激活成本低,输出标记少。它使用基于 SAM 的窗口注意力阶段进行局部感知,使用 2 层卷积压缩器进行 16× token 下采样,以及基于 CLIP 的密集全局注意力阶段进行视觉知识聚合。这种设计使激活内存控制在高分辨率下,并保持视觉标记计数较低。解码器是一个 3B 参数的 MoE 模型(名为 DeepSeek3B-MoE-A570M),每个 token 的活动参数约为 570M。
多分辨率模式,专为token预算而设计
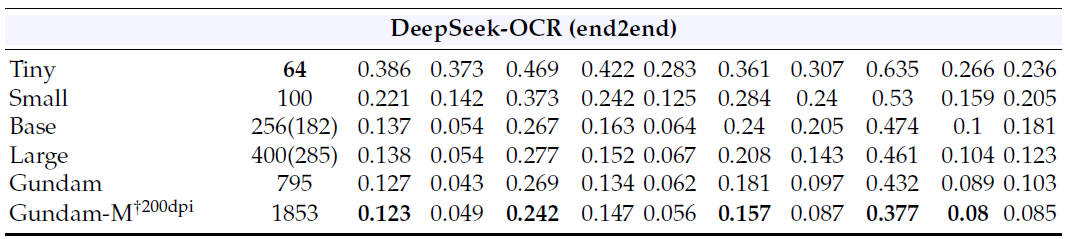
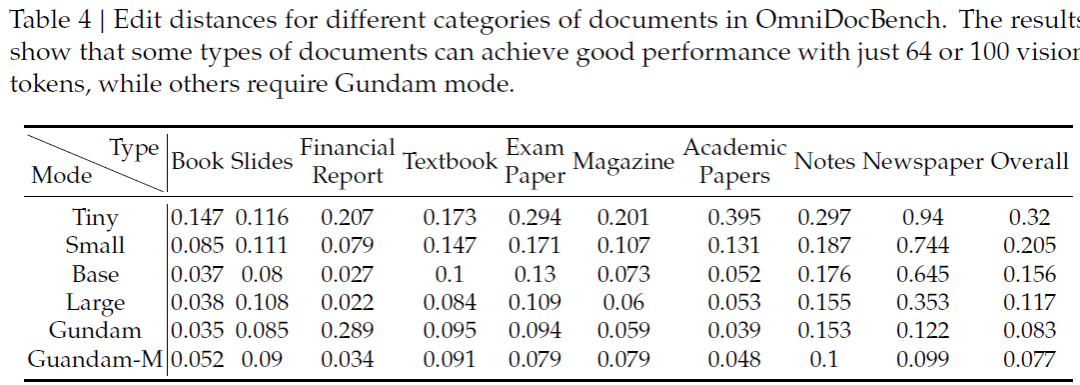
DeepEncoder 支持原生模式和动态模式。原生模式是 Tiny,有 64 个标记,像素为 512 x 512 像素,Small 有 100 个标记,为 640 x 640,Base 有 256 个标记,为 1024 x 1024,Large 有 400 个标记,为 1280 x 1280。名为“高达”和“高达主”的动态模式将平铺的局部视图与全局视图混合在一起。高达产生 n×100 加 256 个token,或 n×256 加 400 个token,其中 n 在 2 到 9 的范围内。对于填充模式,研究团队给出了一个有效令牌的公式,该公式低于原始令牌计数,并且取决于纵横比。这些模式允许人工智能开发人员和研究人员根据页面复杂性调整代币预算。

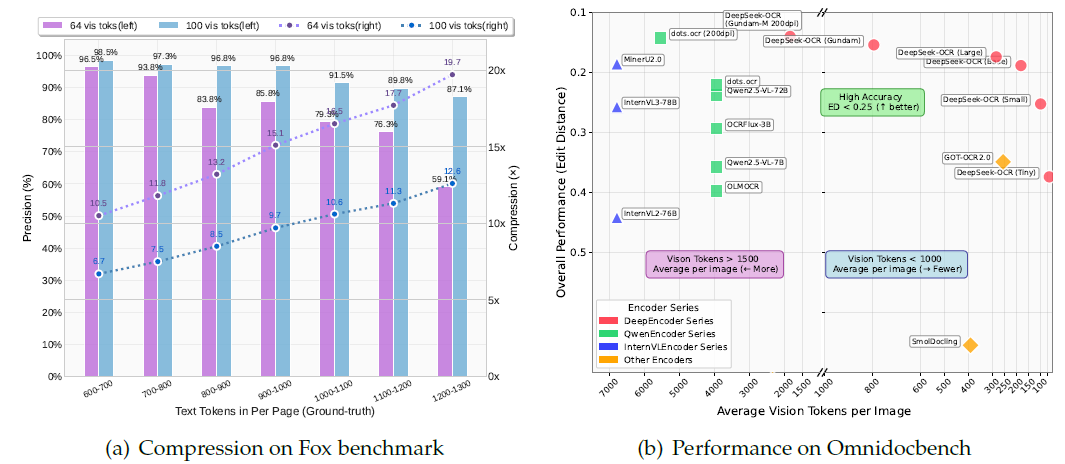
压缩结果,数字说明什么.....
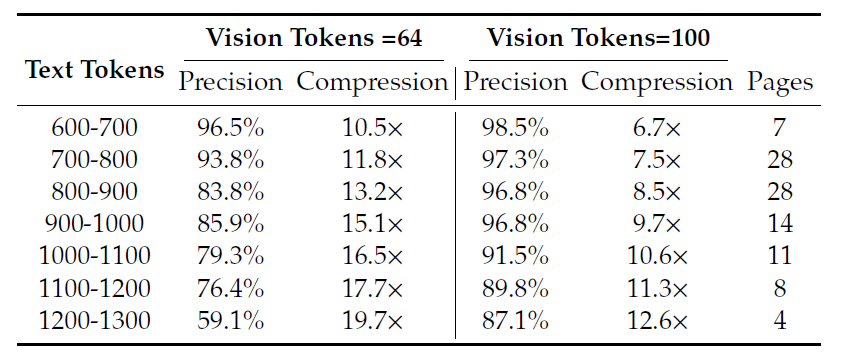
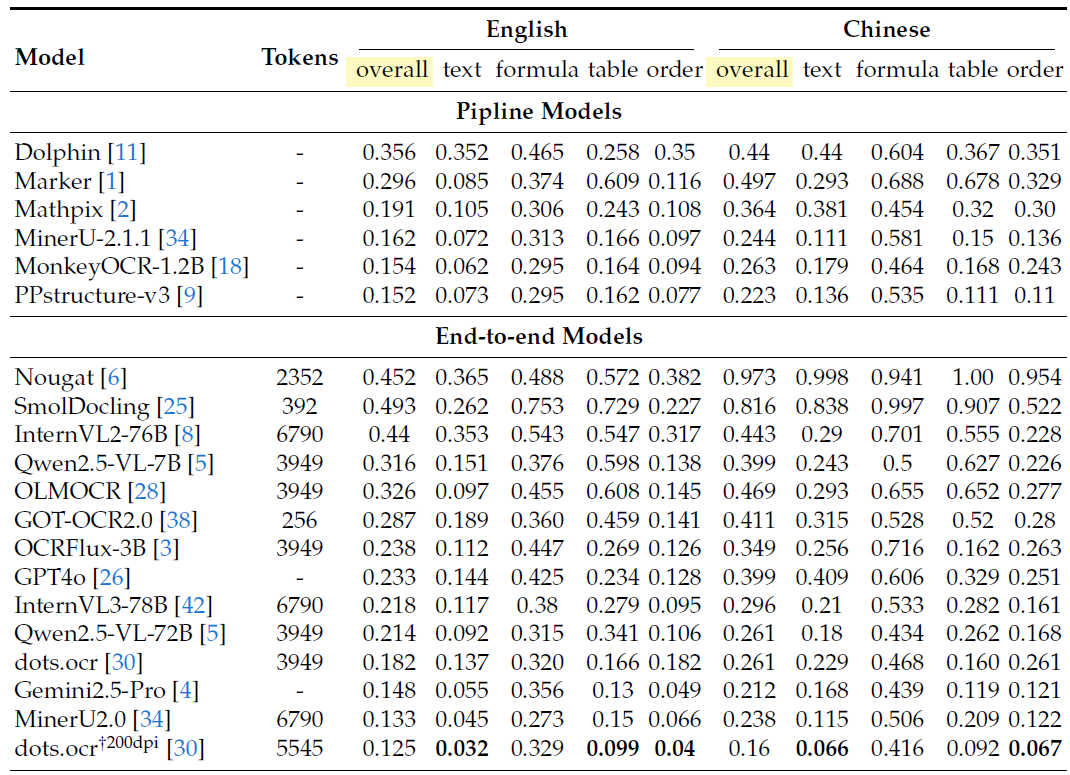
Fox 基准研究在解码后将精度测量为精确的文本匹配。使用 100 个视觉标记,具有 600 到 700 个文本标记的页面在 6.7× 压缩率下达到 98.5% 的精度。具有 900 到 1000 个文本标记的页面在 96.8 的压缩率下达到 9.7× 的精度。对于 64 个视觉标记,精度会随着压缩的增加而降低,例如,对于 1200 到 1300 个文本标记,精度为 59.1%,约为 19.7×。
核心要点
1. DeepSeek OCR 使用光学上下文压缩来提高令牌效率,在大约 10 倍的压缩下进行近乎无损的解码,在大约 60 倍的压缩下实现大约 20% 的精度
2. HF 版本公开了显式token预算,Tiny 以 512 x 512 的速度使用 64 个token,Small 以 640 x 640 的速度使用 100 个token,Base 以 1024 x 1024 的速度使用 256 个代币,Large 以 1280 x 1280 的速度使用 400 个token,Gundam 以 640 x 640 的速度组成 n 个视图,加上 1024 x 1024 的全局视图。
3. 系统结构是将页面压缩为视觉令牌的 DeepEncoder 和具有约 570M 活动参数的 DeepSeek3B MoE 解码器,正如研究团队在技术报告中所描述的那样。
推荐运行环境
Hugging Face 模型卡记录了可立即使用的测试设置
Python 3.12.9
CUDA 11.8
PyTorch 2.6.0
Transformers 4.46.3
Tokenizers 0.20.3
Flash Attention 2.7.3DeepSeek-OCR 不仅仅是另一个 OCR 工具,它还是一种视觉语言模型 (VLM),旨在解决传统文档处理的最大痛点:过多的令牌使用、推理缓慢以及对布局或复杂内容(如表格、公式或化学结构)的处理不力。
参考文档:
https://github.com/deepseek-ai/DeepSeek-OCR/blob/main/DeepSeek_OCR_paper.pdf性能对比
在 OmniDocBench 上,摘要报告称,当每页仅使用 100 个视觉令牌时,DeepSeek-OCR 超过了 GOT-OCR 2.0,并且在 800 个视觉令牌以下,它优于 MinerU 2.0,后者平均每页使用超过 6000 个令牌。基准测试部分显示了编辑距离方面的整体性能。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号