一文带你搞懂什么是LLM、MLLM、LMM、VLM

一文带你搞懂什么是LLM、MLLM、LMM、VLM

OpenCV学堂
发布于 2026-04-02 21:42:25
发布于 2026-04-02 21:42:25
多模态大语言模型(MLLM)

什么是多模态大型语言模型(MLLM)?多模态大型语言模型是能够处理多种输入的大型语言模型,每种“模态”指代特定类型的数据——如文本(如传统大型语言模型)、声音、图像、视频等。为了简化,我们将主要关注图像模态与文本输入并列。
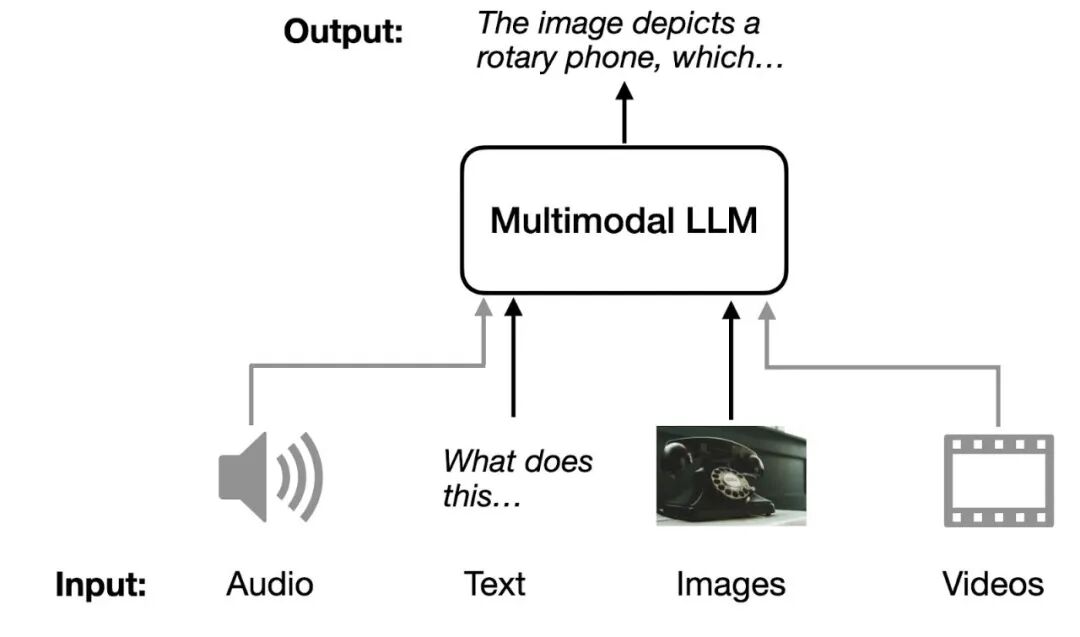
多模态大型语言模型的一个经典且直观的应用是图像标题:你提供输入图像,模型生成图像描述,如上图所示。
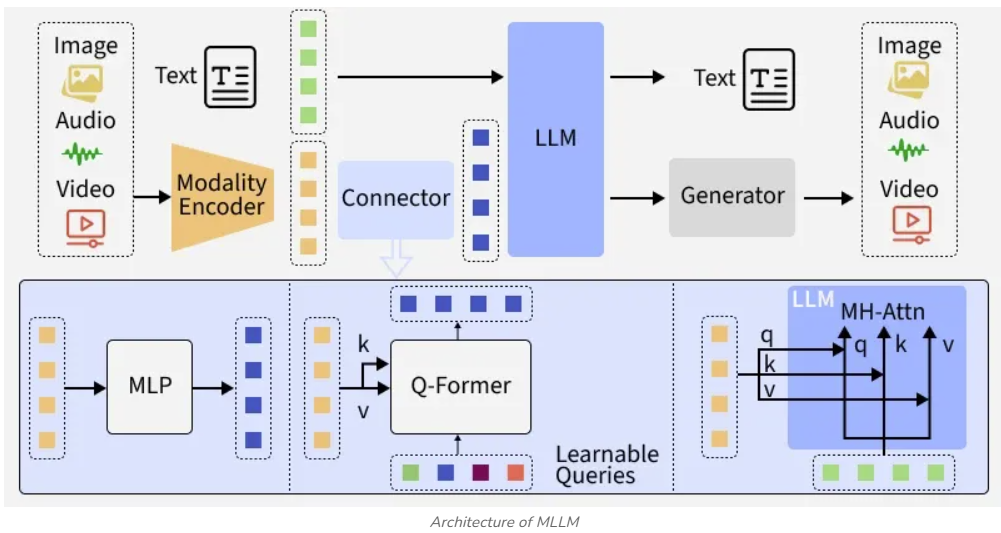
大型多模态模型(LMM)
大型多模态模型是一种先进的人工智能模型,能够处理和理解多种类型的数据模态。这些多模态数据可以包括文本、图像、音频、视频,甚至可能包含其他内容。多模态模型的关键特征是能够整合和解释来自这些不同数据源的信息,通常是同时进行的。
这些可以理解为大型语言模型(LLM)的更高级版本,能够处理文本以及处理多种数据类型。此外,多模态语言模型输出不仅是文本,还包括视觉、听觉等, LMM本质跟MLLM类似。
VLM
传统的计算机视觉需要为每个任务单独建模。VLM通过自然语言指令处理多项视觉任务,采用单一架构:视觉编码器将图像转换为标记,投影层将其与语言模型嵌入对齐,LLM解码器生成响应。
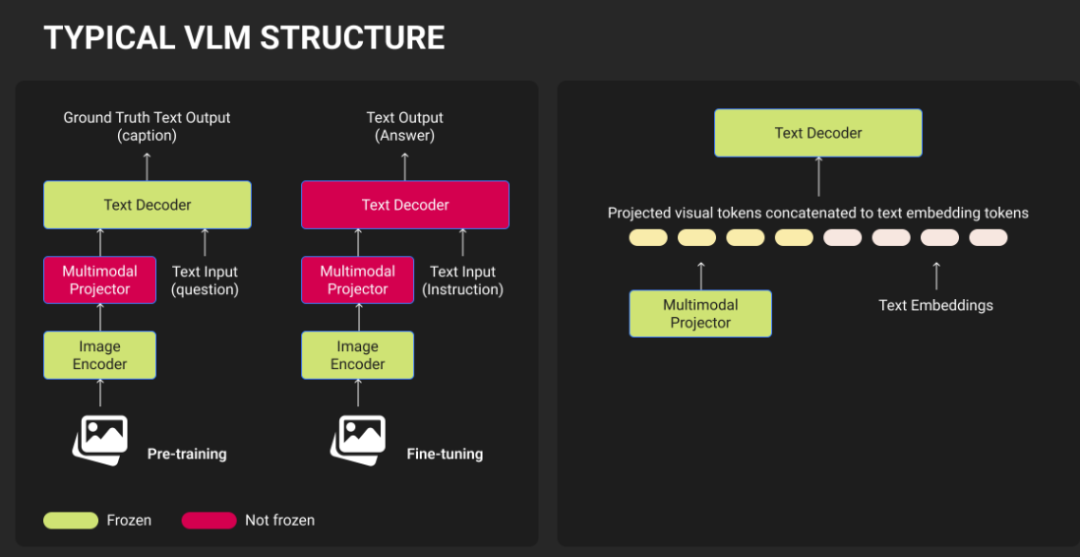
视觉型大型语言模型使用三阶段流水线。视觉编码器将图像转换为数值表示,投影层将这些映射到语言模型的嵌入空间,LLM解码器在处理视觉和文本标记时生成文本。视觉语言模型(VLM)的核心能力包含:
1. 图像描述生成:基于图像内容生成描述性文本。
2. 视觉问答(VQA):回答与图像内容相关的问题。
3. 文本到图像生成:根据文本描述创建图像。
4. 图文互搜:为给定文本查询匹配相关图像,或反之执行图像检索文本。
5. 多模态内容创作:融合图像与文本生成全新内容。
6. 场景理解与目标检测:识别并归类图像中的物体及细节信息。大语言模型(LLM)
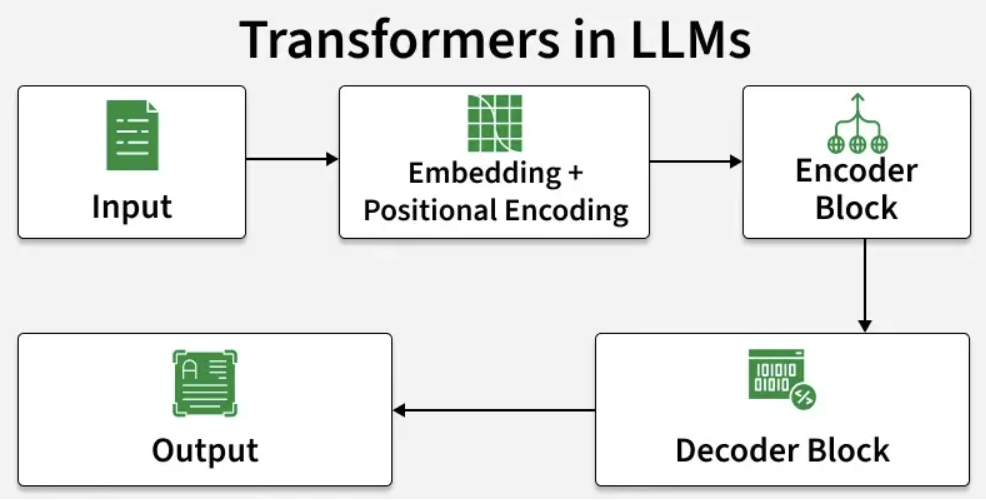
大型语言模型是基于深度神经网络构建的先进人工智能系统,旨在处理、理解并生成类人文本。通过运用海量数据集与数百亿参数,这类模型彻底改变了人机交互的方式。它能够从文本中学习语言模式、语法规则与上下文逻辑,从而实现问答对话、内容创作、语言翻译等多元功能。当前具有代表性的主流模型包括ChatGPT(OpenAI)、谷歌Gemini、文心一言、DeepSeek、千问等。架构主要是基于Transformer系列网络实现:
主要的应用场景包含:
1. 代码生成:大型语言模型能够根据用户指令为特定任务生成精确代码。
2. 调试与文档编写:这类模型可协助识别代码错误、提出修正建议,甚至自动生成项目文档。
3. 智能问答:用户可提出日常或复杂问题,获得具备上下文感知能力的详细回答。
4. 语言翻译与纠错:支持超过50种语言的文本互译,并能自动修正语法错误。
5. 提示词驱动的多功能应用:通过设计具有创造性的提示词,用户可解锁无限可能——得益于大型语言模型在单次学习与零样本学习场景中的卓越表现。深度学习系统化学习
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号