2025年十大主流的视觉语言大模型(VLM)

2025年十大主流的视觉语言大模型(VLM)

OpenCV学堂
发布于 2026-04-02 21:44:03
发布于 2026-04-02 21:44:03
什么是VLM

视觉语言模型(VLM)是同时处理图像和文本的人工智能系统。它们连接了计算机视觉(理解视觉数据的人工智能)与自然语言处理(理解语言的人工智能)。2025年最具影响力的十大视觉语言模型(VLM)的更深入概述,解释它们在不同用例中的差异——涵盖视频、工业工作再到轻量级边缘处理。
十大最佳VLM模型
1. Gemini 2.5 Pro(谷歌)
这是谷歌最先进的专有VLM,其特点是其“思维模型”架构,在响应前“深入思考”问题,一步步进行。它可以理解来自多种模式(文本、图片、视频、音频)的输入,并且拥有超过100万个上下文令牌,正如Gemini 2.5更新的Google博客所宣布,200万个令牌即将推出。
它持续位居LMArena、WebDev Arena等排行榜榜首,并在推理、编程、数学和科学基准测试中表现优异,包括Humanity's Last Exam、AIME 2025和GPQA。
2. InternVL3-78B
InternVL3-78B 之所以成功,是因为它开源且是一款非常受欢迎、强大的工业级VLM,具备工业和三维推理能力。它在MMMU基准测试中达到了72.2,创下开源模型的新纪录,与GPT-4o或Gemini 2.5 Pro等专有巨星相距甚远,正如arXiv上的InternVL3技术报告所记录。
此外,InternVL3-78B在多模态推理基准测试中使用MPO训练方法,较早期版本提升至少4+分。
3. Ovis2-34B(AIDC-AI)
这是一种在计算效率与准确性能之间取得平衡的模型。经过MMBench式评估,它在不同模型中表现良好,非常适合寻求性能与资源之间稳健权衡的团队。虽然目前公开的基准分数仍在深入发布,但其精益架构使其对希望节省计算资源的玩家更具价值。
4. Qwen2.5-VL-72B-Instruct
这是一个高容量开源VLM,采用Apache 2.0授权。Qwen2.5-VL-72B-Ininstruction支持视频输入、定位,并且支持多语言。该模型主要针对需要多功能能力和自由定制的全球应用场景进行优化。
5. Gemma 3 (1B–27B)
Gemma 3 是 Google DeepMind 推出的开放权重 VLM 系列,支持最多 128K 令牌的上下文窗口。它在OCR和多语言理解任务中表现优异,并可扩展到多种部署场景——从小规模部署到企业级。
6. LLaMA 3.2-VL
一个强大的开源VLM,拥有非常长的上下文窗口用于文档理解,包括OCR应用和VQA应用。LLaMA 3.2-Vision 在保持自定义微调灵活性的同时,具有极高的准确性。
7. DeepSeek-VL2系列
采用专家混合架构(MoE),该系列可能拥有1亿到45亿个激活参数。这意味着使用 DeepSeek-VL2 模型可以以极低的延迟进行技术和科学任务的推理。这些型号非常适合在实验室、工厂或移动环境中部署。
8. Phi-4多模态/Pixtral
这类VLM(多模态视频语言模型)是轻量级的、以边缘为先的类型。最终,它们设计注重速度、节能,并能够在解读视觉输入的同时成功执行指令——非常适合增强现实眼镜、智能手机或物联网设备。
9. Tarsier2-7B
另一位视频专精的Tarsier2-7B擅长长长视频描述、帧级问答和流媒体理解。它在视频基准测试中持续优于GPT-4o和Gemini等模型,使其成为视频密集型工作流程中最受欢迎的多模态语言模型之一。
10. Eagle 2.5-8B
Eagle 2.5-8B 是一款多模态通才,擅长高分辨率视频和长时间上下文的图像推理。作为一种开源模型,它在模态性与通用功能之间取得了良好的平衡。
功能对比
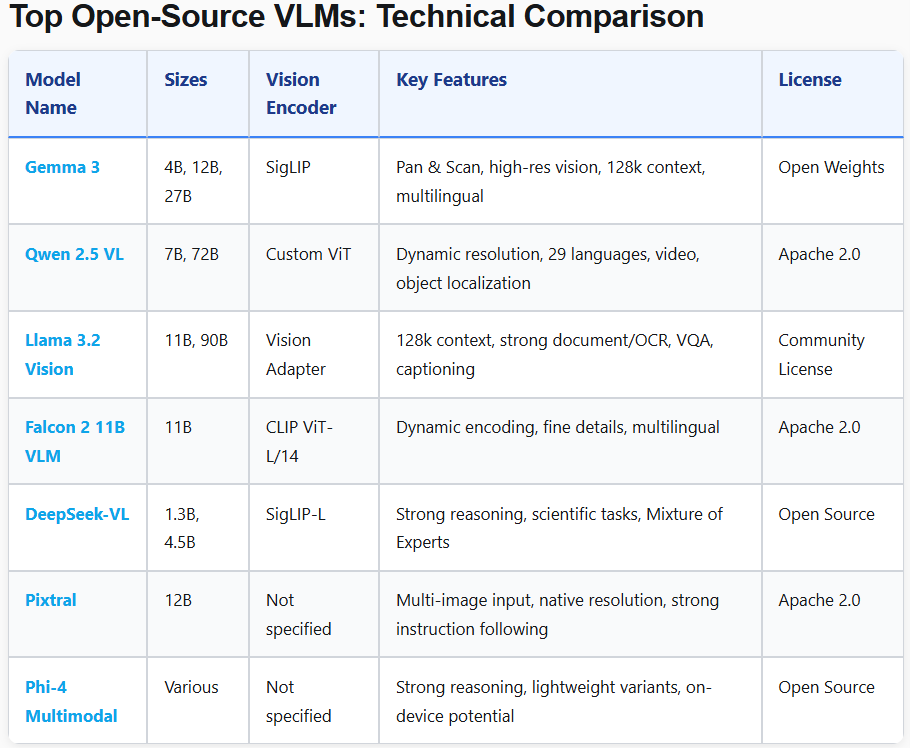
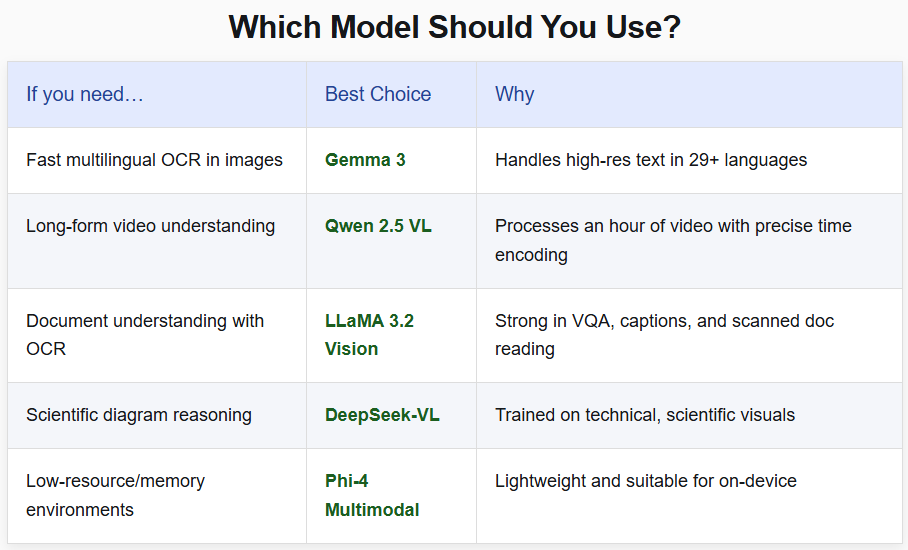
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号