SwinTransformer多尺度特征提取的Vit骨干网络

SwinTransformer多尺度特征提取的Vit骨干网络

OpenCV学堂
发布于 2026-04-02 21:48:24
发布于 2026-04-02 21:48:24
在现有的基于Transformer的模型中,所有标记均采用固定尺度,这一特性并不适用于视觉应用场景。
另一差异在于图像像素的分辨率远高于文本段落中的词汇密度。诸如语义分割等众多视觉任务需要在像素级别进行密集预测,而这对高分辨率图像上的Transformer模型而言难以实现,因为其自注意力机制的计算复杂度与图像尺寸呈平方关系。
为突破这些限制,我们提出了一种名为Swin Transformer的通用Transformer骨干网络,它能够构建分层特征图,并实现与图像尺寸呈线性关系的计算复杂度。
Swin Transformer通过从小尺寸图像块(灰色轮廓标注)开始,并在更深的Transformer层中逐步合并相邻图像块,构建出分层特征表示。这种分层特征图结构使得Swin Transformer能够便捷地应用特征金字塔网络FPN或U-Net等先进技术进行密集预测。

图片
Swin Transformer计算复杂度的实现得益于在划分图像的非重叠局部窗口(红色轮廓标注)内计算自注意力机制。由于每个窗口包含的图像块数量固定,因此计算复杂度与图像尺寸呈线性关系。这些优势使Swin Transformer适用于多种视觉任务的通用骨干网络,与此前仅生成单一分辨率特征图且具有二次计算复杂度的基于Transformer的架构形成鲜明对比。
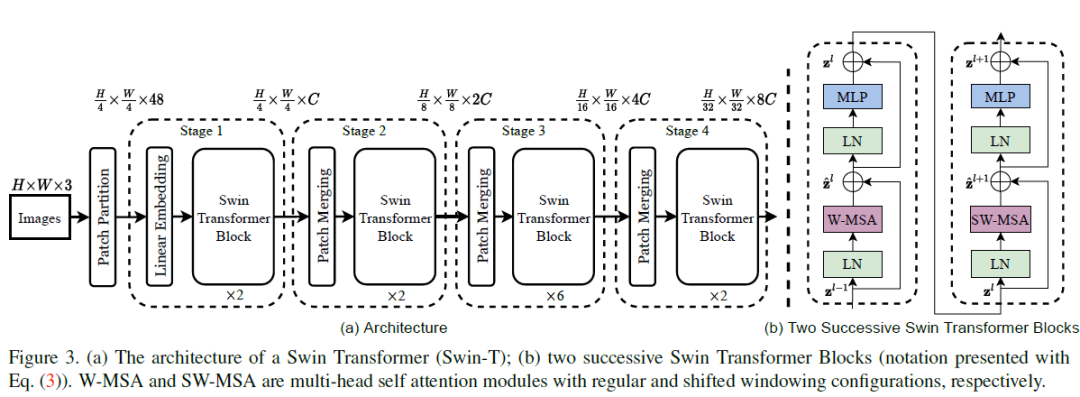
图片
Swin Transformer的一个关键设计要素在于其在连续自注意力层之间采用了窗口分区偏移方案。这种策略在实际延迟方面也表现高效:同一窗口内的所有查询块共享相同的键集,这有助于硬件中的内存访问。
关键解释
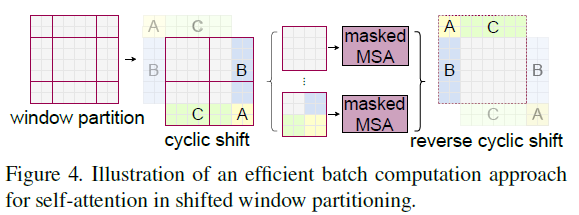
图片
基于非重叠窗口的自注意力机制 为提升模型效率,我们提出在局部窗口内计算自注意力的方法。这些窗口以非重叠方式均匀划分图像。假设每个窗口包含M×M个图像块,全局多头自注意力模块与基于窗口的多头自注意力模块的计算复杂度。对于包含 h × w 个图像块的图片,其计算复杂度分别为:
全局多头自注意力 (MSA):4hwC² + 2(hw)²C (公式1)
基于窗口的多头自注意力 (W-MSA):4hwC² + 2M²hwC (公式2)其中前者与图像块数量 hw 呈二次方关系,而当 M 固定时(默认设置为7),后者复杂度呈线性增长。对于较大的 hw 值,全局自注意力计算通常难以承受,而基于窗口的自注意力则具有良好的可扩展性。
在连续模块中采用移动窗口划分方法 基于窗口的自注意力模块缺乏跨窗口连接,这限制了其建模能力。为了在保持非重叠窗口高效计算的同时引入跨窗口连接,我们提出了一种移动窗口划分方法,该方法在连续的Swin Transformer块中交替使用两种划分配置。
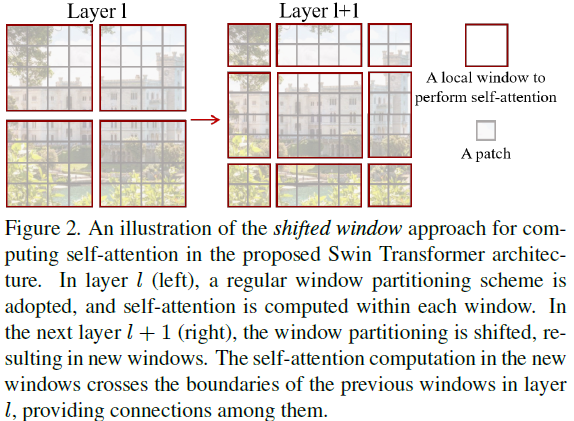
图片
采用移动窗口划分方法后,连续Swin Transformer块的计算公式可表示为
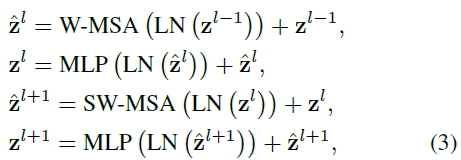
图片
模型变体
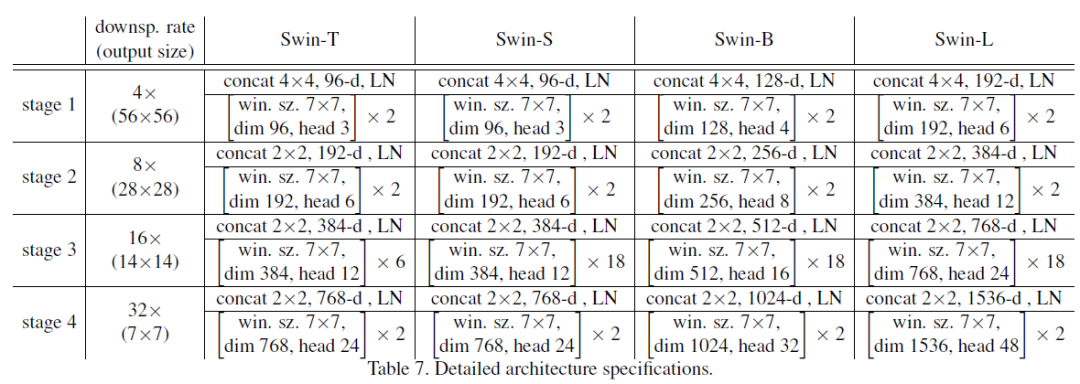
我们构建的基础模型Swin-B,在参数量与计算复杂度方面与ViT-B/DeiT-B相当。同时推出了Swin-T、Swin-S和Swin-L三个变体,其模型规模与计算复杂度分别约为基准模型的0.25倍、0.5倍和2倍。需要说明的是,Swin-T和Swin-S的复杂度分别与ResNet-50(DeiT-S)及ResNet-101相近。默认设置中窗口尺寸M=7,所有实验均采用每个注意力头的查询维度d=32,且每个MLP中的扩展层维度放大系数α=4。这些模型变体的具体架构超参数如下:

图片
图片
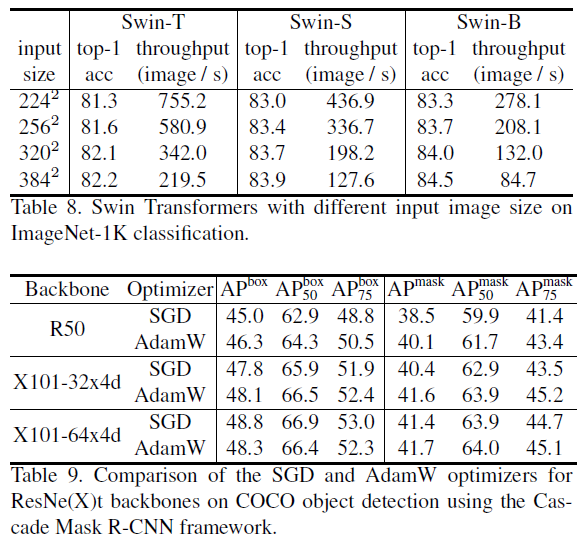
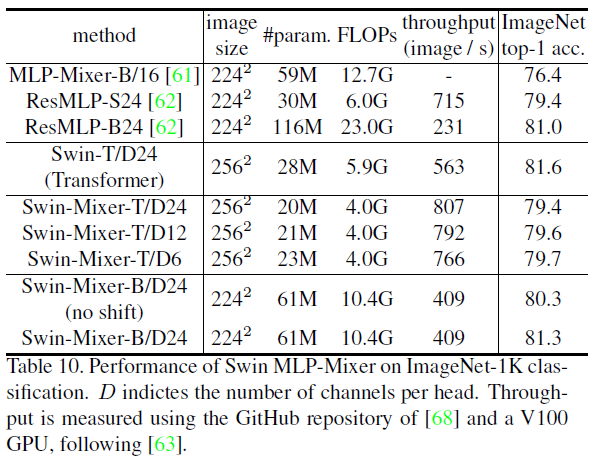
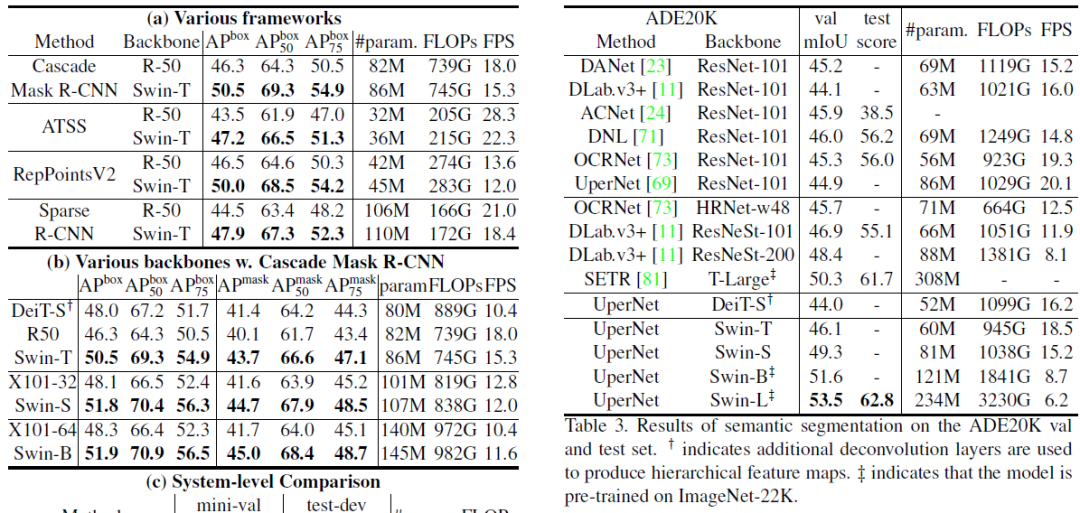
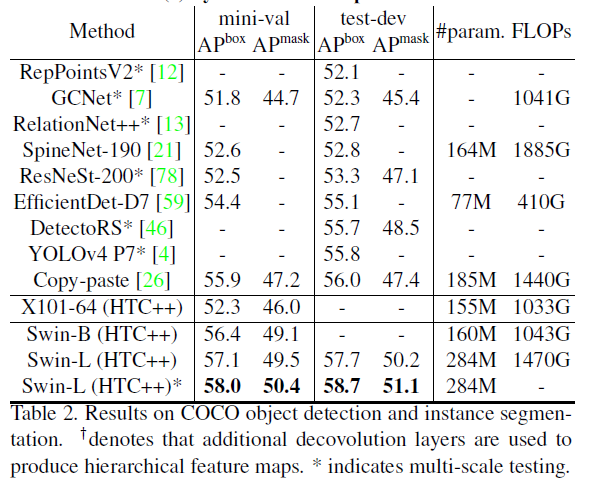
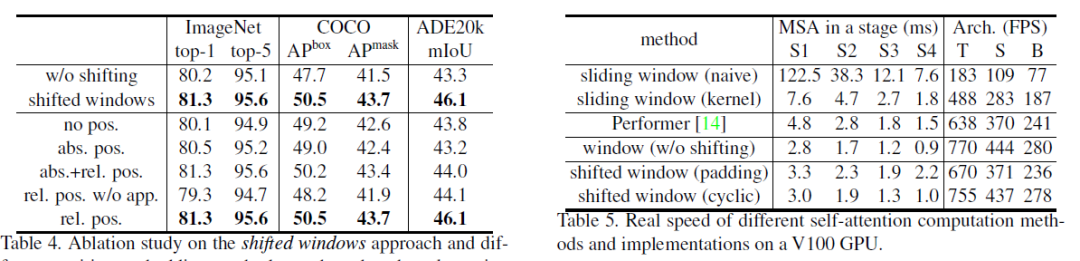
性能与对比
图片
图片
图片
图片
图片
2026年 玩转多模态与视觉大模型开发,实现基于参考样本跟零样本的工业缺陷检测,成为真正的视觉多模态算法工程师,获取多模态与视觉大模型全栈能力
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-12-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号