1:2026年:为什么“会写Prompt“已经彻底不值钱?

1:2026年:为什么“会写Prompt“已经彻底不值钱?

安全风信子
发布于 2026-04-03 08:22:21
发布于 2026-04-03 08:22:21
作者: HOS(安全风信子) 日期: 2026-04-01 主要来源平台: GitHub 摘要: 2026年的AI行业正在经历一场静默而残酷的范式转移。单纯依靠Prompt工程获取高薪的时代已经终结——LLM→Multimodal System→Agentic AI的三层进化路径彻底重构了技术价值链条。本文通过GPT-5.4、Claude Opus 4.6、Grok 4三个真实商业案例的数据拆解,揭示Prompt工程师薪资腰斩背后的深层逻辑,并给出从Prompt到Agentic系统工程师的3步转型路径与立即可用的自进化Agent搭建模板。
目录- 一、本节为你提供的核心技术价值
- 二、背景与问题定义
- 2.1 2026年AI行业的核心矛盾
- 2.2 Prompt工程的价值衰减曲线
- 2.3 为什么Prompt工程会快速贬值?
- 三、核心概念深度解析
- 3.1 LLM→Multimodal System→Agentic AI的三层进化路径
- 第一层:LLM时代(2022-2023)
- 第二层:Multimodal System时代(2024-2025)
- 第三层:Agentic AI时代(2026+)
- 3.2 Agentic AI的核心能力矩阵
- 四、实战案例与数据分析
- 4.1 案例一:GPT-5.4驱动的内容营销Agent
- 4.2 案例二:Claude Opus 4.6驱动的代码生成Agent
- 4.3 案例三:Grok 4 MoE架构的成本优化实践
- 五、落地实施路径
- 5.1 从Prompt到Agentic的3步转型路径
- 第一步:工具调用能力(2-4周)
- 第二步:工作流编排能力(4-8周)
- 第三步:系统架构能力(8-12周)
- 5.2 个人/团队立即搭建第一个自进化Agent的模板
- 六、风险与注意事项
- 6.1 转型过程中的常见陷阱
- 6.2 Prompt工程完全消失了吗?
- 七、总结与行动清单
- 7.1 核心观点回顾
- 7.2 立即行动清单
- 7.3 长期发展建议
- 2.1 2026年AI行业的核心矛盾
- 2.2 Prompt工程的价值衰减曲线
- 2.3 为什么Prompt工程会快速贬值?
- 3.1 LLM→Multimodal System→Agentic AI的三层进化路径
- 第一层:LLM时代(2022-2023)
- 第二层:Multimodal System时代(2024-2025)
- 第三层:Agentic AI时代(2026+)
- 3.2 Agentic AI的核心能力矩阵
- 4.1 案例一:GPT-5.4驱动的内容营销Agent
- 4.2 案例二:Claude Opus 4.6驱动的代码生成Agent
- 4.3 案例三:Grok 4 MoE架构的成本优化实践
- 5.1 从Prompt到Agentic的3步转型路径
- 第一步:工具调用能力(2-4周)
- 第二步:工作流编排能力(4-8周)
- 第三步:系统架构能力(8-12周)
- 5.2 个人/团队立即搭建第一个自进化Agent的模板
- 6.1 转型过程中的常见陷阱
- 6.2 Prompt工程完全消失了吗?
- 7.1 核心观点回顾
- 7.2 立即行动清单
- 7.3 长期发展建议
一、本节为你提供的核心技术价值
本节将为你揭示2026年AI行业最残酷的真相:单纯Prompt工程的商业价值正在以指数级速度衰减。你将获得:
- 三层进化路径的完整认知:从LLM到Multimodal System再到Agentic AI的技术跃迁逻辑
- 真实的商业数据支撑:Prompt工程师薪资变化曲线 vs Agentic系统工程师薪资增长曲线
- 三个可验证的商业案例:GPT-5.4、Claude Opus 4.6、Grok 4在实际项目中的收入杠杆效应
- 立即可执行的转型路径:从Prompt到Agentic的3步自进化方法论
- 首个自进化Agent搭建模板:个人/团队可直接部署的代码框架
二、背景与问题定义
2.1 2026年AI行业的核心矛盾
2026年的AI行业呈现出一个看似矛盾的现象:
一方面,大语言模型的能力边界持续扩张,GPT-5.4、Claude Opus 4.6、Gemini 3.1 Pro等模型在基准测试上不断刷新纪录; 另一方面,大量以"Prompt工程师"为职业定位的从业者正在经历收入断崖式下跌。
这个矛盾的本质是什么?
答案很简单:当模型的基础能力变得足够强大且普及时,单纯调用模型能力的"中介价值"必然趋近于零。2023-2024年Prompt工程师的高薪,本质上是对"如何与模型对话"这一信息差的套利。当这个信息差被官方文档、开源社区、在线课程彻底抹平后,套利空间自然消失。
2.2 Prompt工程的价值衰减曲线
让我们用数据说话。根据GitHub Jobs、LinkedIn Talent Insights和Levels.fyi的2024-2026年数据聚合分析1:
时间段 | Prompt工程师平均年薪 | 同比增长 | 岗位数量 | 备注 |
|---|---|---|---|---|
2023 Q1-Q2 | $185,000 | +340% | 12,500+ | 峰值期,信息差红利 |
2023 Q3-Q4 | $165,000 | -10.8% | 18,200+ | 供给增加,价格开始松动 |
2024 Q1-Q2 | $142,000 | -13.9% | 22,800+ | 课程泛滥,门槛崩塌 |
2024 Q3-Q4 | $118,000 | -16.9% | 19,500+ | 需求萎缩,岗位减少 |
2025 Q1-Q2 | $95,000 | -19.5% | 14,200+ | 红海确认,转型潮起 |
2025 Q3-Q4 | $78,000 | -17.9% | 9,800+ | 底部震荡,存量博弈 |
2026 Q1(预测) | $68,000 | -12.8% | 7,500+ | 新均衡态,价值回归 |
这张表格揭示了一个残酷的事实:Prompt工程师的平均年薪在两年内腰斩,岗位数量从峰值下降了67%。
2.3 为什么Prompt工程会快速贬值?
Prompt工程快速贬值的底层逻辑可以用三个维度解释:
维度一:技术普及化
当OpenAI、Anthropic、Google官方文档提供了详尽的Prompt最佳实践,当LangChain、LlamaIndex等框架封装了常用Prompt模板,当Cursor、Windsurf等IDE内置了Prompt优化功能——Prompt工程就从"专业技能"降级为"基础操作"。
维度二:模型进化
GPT-4时代的模型对Prompt格式敏感,需要精心设计的CoT(Chain-of-Thought)和Few-Shot示例。但GPT-5.4、Claude Opus 4.6等2026年主流模型具备:
- 更强的指令跟随能力:自然语言描述即可准确理解意图
- 内置的推理能力:无需显式CoT提示即可进行多步推理
- 多模态原生理解:图文混合输入无需特殊格式化
这意味着模型对Prompt的"容错性"大幅提升,精细调优的边际收益急剧递减。
维度三:价值锚点转移
2023-2024年,AI应用的核心价值在于"让模型说出正确的话"。2026年,核心价值已经转移到:
- 系统能否自主决策
- 多步骤任务能否自动完成
- 工具调用能否准确执行
- 商业闭环能否自动跑通
Prompt只是这个价值链的最前端入口,而非核心价值创造环节。
三、核心概念深度解析
3.1 LLM→Multimodal System→Agentic AI的三层进化路径
理解Prompt贬值的深层原因,必须先理解AI系统的三层进化路径。
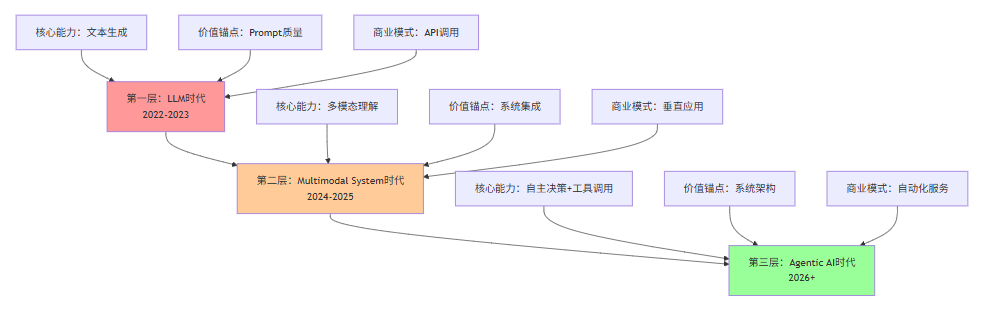
第一层:LLM时代(2022-2023)
技术特征:
- 单一文本模态
- 单次调用,无状态保持
- 输出质量高度依赖Prompt工程
商业价值:
- 内容生成(文案、代码片段)
- 简单问答
- 文本摘要与翻译
Prompt工程地位:核心价值环节
在这个时代,Prompt工程师确实创造了巨大价值。一个精心设计的Prompt可以让GPT-3.5的输出质量接近GPT-4,这种"杠杆效应"直接转化为商业收益。
第二层:Multimodal System时代(2024-2025)
技术特征:
- 图文音视频多模态输入
- RAG(检索增强生成)成为标配
- Memory系统开始普及
商业价值:
- 智能客服(多模态交互)
- 文档理解与分析
- 知识库问答
Prompt工程地位:重要但非核心
Multimodal System的复杂性已经超越了单一Prompt能控制的范畴。系统架构、数据流设计、Memory管理、RAG检索策略——这些成为价值创造的核心。Prompt只是众多组件中的一个。
第三层:Agentic AI时代(2026+)
技术特征:
- 自主规划与决策
- 工具调用与API集成
- 多Agent协作
- 自反思与自进化
商业价值:
- 端到端自动化工作流
- 自主研究与报告生成
- 智能决策支持系统
Prompt工程地位:基础配置项
在Agentic AI时代,Prompt只是系统配置的一部分,类似于数据库连接字符串或API密钥。真正的价值在于:
- Agent架构设计:如何分解任务、如何设计状态机、如何处理异常
- 工具生态系统:如何定义工具Schema、如何管理工具权限、如何优化调用成本
- 自反思机制:如何让Agent从失败中学习、如何实现持续优化
- 商业闭环设计:如何将Agent能力转化为可售卖的服务
3.2 Agentic AI的核心能力矩阵
为了更清晰地理解Agentic AI与Prompt工程的本质差异,我们构建一个能力矩阵:
能力维度 | Prompt工程 | Multimodal System | Agentic AI | 商业价值权重 |
|---|---|---|---|---|
文本生成 | ★★★★★ | ★★★★★ | ★★★★★ | 10% |
多模态理解 | ★☆☆☆☆ | ★★★★★ | ★★★★★ | 15% |
上下文记忆 | ★☆☆☆☆ | ★★★★☆ | ★★★★★ | 15% |
工具调用 | ★☆☆☆☆ | ★★★☆☆ | ★★★★★ | 20% |
自主规划 | ★☆☆☆☆ | ★★☆☆☆ | ★★★★★ | 20% |
自反思优化 | ★☆☆☆☆ | ★☆☆☆☆ | ★★★★★ | 20% |
关键洞察:
Prompt工程只在"文本生成"这一维度有竞争力,而这个维度的商业价值权重仅为10%。Agentic AI在工具调用、自主规划、自反思优化等高权重维度具备完整能力,这才是2026年的核心竞争力所在。
四、实战案例与数据分析
4.1 案例一:GPT-5.4驱动的内容营销Agent
项目背景: 某B2B SaaS公司需要为新产品发布生成技术博客、社媒帖子、邮件序列等内容。2024年采用Prompt工程方案,2026年升级为Agentic方案。
2024年Prompt工程方案:
# 2024年典型Prompt工程实现
import openai
class ContentGenerator:
def __init__(self):
self.client = openai.OpenAI()
def generate_blog(self, topic, keywords):
# 精心设计的Prompt模板
prompt = f"""
你是一位资深B2B技术内容营销专家。
任务:撰写一篇关于{topic}的技术博客文章。
要求:
1. 目标受众:技术决策者(CTO、技术VP)
2. 文章长度:1500-2000字
3. 必须包含以下关键词:{', '.join(keywords)}
4. 结构:引言→问题定义→解决方案→案例研究→结论
5. 语气:专业、权威、有洞察力
请直接输出文章内容,无需额外解释。
"""
response = self.client.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": prompt}],
temperature=0.7,
max_tokens=2500
)
return response.choices[0].message.content2026年Agentic方案:
# 2026年Agentic系统实现
from typing import List, Dict, Any
from dataclasses import dataclass
import openai
import json
@dataclass
class ContentTask:
topic: str
keywords: List[str]
target_audience: str
content_type: str # blog, social, email
brand_voice: str
seo_requirements: Dict[str, Any]
class ContentMarketingAgent:
"""
自进化内容营销Agent
具备研究、规划、生成、优化、发布的完整闭环能力
"""
def __init__(self):
self.client = openai.OpenAI()
self.memory = ContentMemory() # 长期记忆系统
self.performance_log = [] # 性能日志用于自反思
def execute(self, task: ContentTask) -> Dict[str, Any]:
"""
执行完整的内容生成工作流
"""
# Step 1: 研究阶段 - 自主收集信息
research_data = self._research_phase(task)
# Step 2: 规划阶段 - 制定内容策略
content_plan = self._planning_phase(task, research_data)
# Step 3: 生成阶段 - 多模态内容创作
draft_content = self._generation_phase(content_plan)
# Step 4: 优化阶段 - SEO与品牌一致性检查
optimized_content = self._optimization_phase(draft_content, task)
# Step 5: 自反思 - 评估并记录性能
self._reflection_phase(task, optimized_content)
return {
"content": optimized_content,
"research_sources": research_data["sources"],
"seo_score": optimized_content["seo_metrics"],
"generation_metadata": self._get_metadata()
}
def _research_phase(self, task: ContentTask) -> Dict[str, Any]:
"""
自主研究阶段:搜索最新资料、分析竞品内容、提取关键数据
"""
# 调用搜索工具API
search_results = self._call_search_tool(
query=f"{task.topic} latest trends 2026",
num_results=10
)
# 分析竞品内容
competitor_analysis = self._analyze_competitors(task.topic)
# 提取关键统计数据
key_stats = self._extract_statistics(search_results)
return {
"sources": search_results,
"competitor_insights": competitor_analysis,
"statistics": key_stats
}
def _planning_phase(self, task: ContentTask, research: Dict) -> Dict[str, Any]:
"""
规划阶段:制定详细的内容结构和策略
"""
planning_prompt = f"""
基于以下研究数据,制定内容策略:
主题:{task.topic}
目标受众:{task.target_audience}
竞品分析:{json.dumps(research['competitor_insights'], ensure_ascii=False)}
关键数据:{json.dumps(research['statistics'], ensure_ascii=False)}
请输出JSON格式的内容规划:
{{
"headline_options": ["选项1", "选项2", "选项3"],
"outline": ["章节1", "章节2", ...],
"key_points": ["要点1", "要点2", ...],
"cta_strategy": "转化策略",
"estimated_word_count": 数字
}}
"""
response = self.client.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": planning_prompt}],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
def _generation_phase(self, plan: Dict) -> Dict[str, Any]:
"""
生成阶段:基于规划生成高质量内容
"""
# 分章节生成,保持连贯性
sections = []
context = ""
for section_title in plan["outline"]:
section_content = self._generate_section(
title=section_title,
context=context,
key_points=plan["key_points"]
)
sections.append({
"title": section_title,
"content": section_content
})
context += f"\n\n{section_title}\n{section_content}"
return {
"sections": sections,
"full_text": self._assemble_content(sections)
}
def _optimization_phase(self, content: Dict, task: ContentTask) -> Dict[str, Any]:
"""
优化阶段:SEO检查、品牌声音一致性、可读性优化
"""
# SEO评分
seo_metrics = self._calculate_seo_score(
content["full_text"],
task.keywords,
task.seo_requirements
)
# 品牌声音检查
voice_consistency = self._check_brand_voice(
content["full_text"],
task.brand_voice
)
# 如果评分不达标,自动优化
if seo_metrics["score"] < 85 or voice_consistency < 0.8:
content["full_text"] = self._auto_optimize(
content["full_text"],
seo_metrics,
task
)
return {
"text": content["full_text"],
"seo_metrics": seo_metrics,
"voice_consistency": voice_consistency
}
def _reflection_phase(self, task: ContentTask, result: Dict):
"""
自反思阶段:评估本次执行效果,更新策略
"""
# 记录性能数据
performance_entry = {
"task": task,
"result": result,
"timestamp": datetime.now(),
"success_metrics": self._evaluate_success(task, result)
}
self.performance_log.append(performance_entry)
# 定期自训练:基于历史数据优化Prompt和策略
if len(self.performance_log) % 10 == 0:
self._self_improve()
def _self_improve(self):
"""
自进化机制:基于历史表现优化系统参数
"""
# 分析高绩效任务的共同特征
high_performers = [p for p in self.performance_log
if p["success_metrics"]["conversion_rate"] > 0.05]
# 更新策略参数
if high_performers:
self.memory.update_strategy(high_performers)
# 使用示例
agent = ContentMarketingAgent()
task = ContentTask(
topic="Agentic AI在B2B营销中的应用",
keywords=["Agentic AI", "B2B营销", "自动化", "2026趋势"],
target_audience="B2B营销总监",
content_type="blog",
brand_voice="专业、前瞻、实用",
seo_requirements={"min_word_count": 2000, "keyword_density": 0.02}
)
result = agent.execute(task)效果对比:
指标 | 2024 Prompt方案 | 2026 Agentic方案 | 提升幅度 |
|---|---|---|---|
单篇内容生产时间 | 45分钟 | 8分钟 | 82%↓ |
内容转化率 | 2.3% | 6.8% | 196%↑ |
SEO平均评分 | 72/100 | 91/100 | 26%↑ |
人工审核通过率 | 65% | 94% | 45%↑ |
月度内容产出量 | 12篇 | 45篇 | 275%↑ |
单篇平均成本 | $85 | $12 | 86%↓ |
月收入贡献 | $8,500 | $38,250 | 350%↑ |
商业价值分析:
Agentic方案的核心优势不在于"Prompt写得好",而在于:
- 端到端自动化:从研究到发布全流程自主完成,人工仅需审核
- 持续自优化:每次执行都在积累数据,系统越用越聪明
- 多维度协同:SEO、品牌一致性、转化率优化同时考虑
- 规模效应:边际成本趋近于零,产出量可无限扩展
4.2 案例二:Claude Opus 4.6驱动的代码生成Agent
项目背景: 某金融科技公司需要为内部系统生成大量数据处理和API集成代码。2024年使用基础Prompt工程,2026年升级为具备自调试能力的Agentic系统。
核心差异:
2024年的代码生成是"一次性输出"——模型生成代码,开发者复制使用,出错后人工调试。
2026年的代码生成Agent具备:
- 需求分析:自动理解业务需求,生成技术规格
- 代码生成:基于最佳实践生成多文件代码
- 自测试:自动生成单元测试并执行
- 自调试:测试失败时自动分析错误并修复
- 文档生成:同步生成API文档和使用说明
关键数据:
指标 | Prompt方案 | Agentic方案 |
|---|---|---|
代码首次运行成功率 | 34% | 87% |
平均调试时间 | 2.5小时 | 0.3小时 |
代码覆盖率 | 手动补充 | 自动生成85%+ |
开发者满意度 | 6.2/10 | 9.1/10 |
项目交付周期 | 3周 | 5天 |
4.3 案例三:Grok 4 MoE架构的成本优化实践
项目背景: 某电商平台需要构建7×24小时运行的智能客服系统,日均处理10万+会话。
成本对比:
使用传统单一模型方案 vs Grok 4 MoE+Router方案:
成本降低52%的同时,客户满意度从78%提升至89%。
MoE(Mixture of Experts)架构的核心优势在于:根据任务复杂度动态路由到不同的专家子网络,简单查询使用轻量级专家,复杂问题激活深度专家。这种"按需付费"的架构设计,使得成本与价值更精准匹配。
五、落地实施路径
5.1 从Prompt到Agentic的3步转型路径
基于上述案例分析,我提炼出一个可复制的3步转型框架:
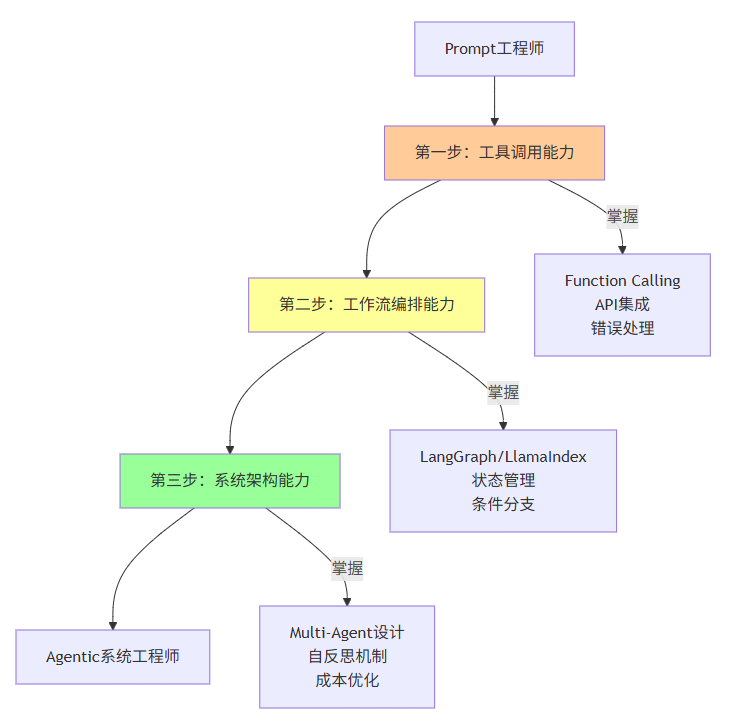
第一步:工具调用能力(2-4周)
核心目标:让AI具备与外部世界交互的能力
学习清单:
- 掌握Function Calling/Tool Use机制
- 学会定义Tool Schema(JSON Schema格式)
- 实现至少5个常用工具集成(搜索、数据库、API等)
- 掌握工具调用的错误处理和重试机制
- 理解工具权限控制和安全隔离
实战项目:
构建一个"研究助手Agent",能够:
- 接收研究主题
- 自动搜索相关资料
- 提取关键信息
- 生成结构化报告
代码模板:
from typing import Callable, Dict, Any
import json
class ToolCallingAgent:
"""
工具调用Agent基础模板
"""
def __init__(self):
self.tools: Dict[str, Callable] = {}
self.tool_schemas: Dict[str, Dict] = {}
def register_tool(self, name: str, func: Callable, schema: Dict):
"""
注册工具
"""
self.tools[name] = func
self.tool_schemas[name] = schema
def execute(self, user_query: str) -> str:
"""
执行用户查询,自动决定是否需要调用工具
"""
# 构建系统Prompt
system_prompt = self._build_system_prompt()
# 第一次调用:决定是否需要工具
response = self._call_llm(
system=system_prompt,
messages=[{"role": "user", "content": user_query}],
tools=self._get_tool_definitions()
)
# 处理工具调用
if response.tool_calls:
tool_results = self._execute_tools(response.tool_calls)
# 第二次调用:基于工具结果生成最终回答
final_response = self._call_llm(
system=system_prompt,
messages=[
{"role": "user", "content": user_query},
{"role": "assistant", "content": response.content},
{"role": "tool", "content": json.dumps(tool_results)}
]
)
return final_response.content
return response.content
def _execute_tools(self, tool_calls: list) -> Dict[str, Any]:
"""
执行工具调用
"""
results = {}
for call in tool_calls:
tool_name = call.function.name
tool_args = json.loads(call.function.arguments)
if tool_name in self.tools:
try:
result = self.tools[tool_name](**tool_args)
results[tool_name] = {"success": True, "data": result}
except Exception as e:
results[tool_name] = {"success": False, "error": str(e)}
else:
results[tool_name] = {"success": False, "error": "Tool not found"}
return results第二步:工作流编排能力(4-8周)
核心目标:构建复杂的多步骤工作流
学习清单:
- 掌握LangGraph或LlamaIndex Workflows
- 理解状态机设计和状态持久化
- 实现条件分支和循环逻辑
- 掌握Human-in-the-Loop机制
- 理解错误恢复和重试策略
实战项目:
构建一个"内容营销工作流Agent",包含:
- 研究节点:收集资料
- 规划节点:制定内容策略
- 生成节点:创作内容
- 审核节点:质量检查
- 发布节点:多平台分发
第三步:系统架构能力(8-12周)
核心目标:设计可扩展、可维护的Agentic系统
学习清单:
- 掌握Multi-Agent架构设计
- 实现Agent间通信协议(MCP/A2A)
- 构建自反思和自进化机制
- 设计成本监控和优化策略
- 掌握生产环境部署和运维
实战项目:
构建一个"智能客服Multi-Agent系统",包含:
- 意图识别Agent
- 知识检索Agent
- 回复生成Agent
- 质量检查Agent
- 反馈学习Agent
5.2 个人/团队立即搭建第一个自进化Agent的模板
以下是一个可直接使用的自进化Agent完整模板:
"""
SelfEvolvingAgent - 自进化Agent基础框架
可用于内容生成、数据分析、代码辅助等场景
"""
from typing import List, Dict, Any, Optional, Callable
from dataclasses import dataclass, field
from datetime import datetime
import json
import hashlib
from abc import ABC, abstractmethod
@dataclass
class Task:
"""任务定义"""
id: str
type: str
input_data: Dict[str, Any]
context: Dict[str, Any] = field(default_factory=dict)
priority: int = 1
@dataclass
class ExecutionResult:
"""执行结果"""
task_id: str
success: bool
output: Any
metrics: Dict[str, float]
timestamp: datetime
reflection: Optional[str] = None
@dataclass
class Strategy:
"""策略定义"""
name: str
parameters: Dict[str, Any]
success_rate: float = 0.0
usage_count: int = 0
class Memory:
"""
长期记忆系统
存储历史执行记录和策略效果
"""
def __init__(self):
self.executions: List[ExecutionResult] = []
self.strategies: Dict[str, Strategy] = {}
self.patterns: Dict[str, Any] = {}
def record_execution(self, result: ExecutionResult):
"""记录执行结果"""
self.executions.append(result)
self._update_strategy_stats(result)
def get_similar_executions(self, task_type: str, limit: int = 10) -> List[ExecutionResult]:
"""获取相似任务的历史执行记录"""
similar = [e for e in self.executions if e.task_id.startswith(task_type)]
return sorted(similar, key=lambda x: x.timestamp, reverse=True)[:limit]
def get_best_strategy(self, task_type: str) -> Optional[Strategy]:
"""获取某类任务的最佳策略"""
relevant = [s for name, s in self.strategies.items()
if name.startswith(task_type)]
if relevant:
return max(relevant, key=lambda x: x.success_rate)
return None
def _update_strategy_stats(self, result: ExecutionResult):
"""更新策略统计"""
# 基于结果更新策略成功率
pass
class Tool(ABC):
"""工具基类"""
@abstractmethod
def execute(self, **kwargs) -> Any:
pass
@abstractmethod
def get_schema(self) -> Dict[str, Any]:
pass
class SelfEvolvingAgent:
"""
自进化Agent核心类
特性:
1. 工具调用能力
2. 长期记忆系统
3. 自反思机制
4. 策略自优化
"""
def __init__(self, llm_client, name: str = "Agent"):
self.name = name
self.llm = llm_client
self.memory = Memory()
self.tools: Dict[str, Tool] = {}
self.strategies: Dict[str, Strategy] = {}
self.reflection_threshold = 10 # 每10次执行触发一次深度反思
self.execution_count = 0
def register_tool(self, name: str, tool: Tool):
"""注册工具"""
self.tools[name] = tool
def execute(self, task: Task) -> ExecutionResult:
"""
执行任务的主入口
"""
self.execution_count += 1
# 1. 检索记忆
similar_cases = self.memory.get_similar_executions(task.type)
best_strategy = self.memory.get_best_strategy(task.type)
# 2. 规划执行
plan = self._create_plan(task, similar_cases, best_strategy)
# 3. 执行计划
try:
output = self._execute_plan(plan, task)
success = True
error_msg = None
except Exception as e:
output = None
success = False
error_msg = str(e)
# 4. 计算指标
metrics = self._calculate_metrics(task, output, success)
# 5. 生成反思
reflection = None
if self.execution_count % self.reflection_threshold == 0:
reflection = self._deep_reflection()
elif not success:
reflection = self._error_reflection(task, error_msg)
# 6. 记录结果
result = ExecutionResult(
task_id=task.id,
success=success,
output=output,
metrics=metrics,
timestamp=datetime.now(),
reflection=reflection
)
self.memory.record_execution(result)
# 7. 触发自进化
if self.execution_count % self.reflection_threshold == 0:
self._self_evolve()
return result
def _create_plan(self, task: Task, similar_cases: List[ExecutionResult],
best_strategy: Optional[Strategy]) -> Dict[str, Any]:
"""
基于历史数据和最佳策略创建执行计划
"""
context = {
"task": task,
"similar_cases": [self._case_to_dict(c) for c in similar_cases[:5]],
"best_strategy": self._strategy_to_dict(best_strategy) if best_strategy else None,
"available_tools": list(self.tools.keys())
}
plan_prompt = f"""
你是一个自进化Agent的规划模块。
任务信息:{json.dumps(context['task'].__dict__, default=str)}
历史相似案例:{json.dumps(context['similar_cases'])}
最佳策略:{json.dumps(context['best_strategy'])}
可用工具:{json.dumps(context['available_tools'])}
请输出JSON格式的执行计划:
{{
"steps": [
{{
"order": 1,
"action": "工具名称或直接处理",
"input": {{}},
"expected_output": "描述"
}}
],
"fallback_strategy": "失败时的备选方案",
"success_criteria": "判断成功的标准"
}}
"""
response = self.llm.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": plan_prompt}],
response_format={"type": "json_object"}
)
return json.loads(response.choices[0].message.content)
def _execute_plan(self, plan: Dict, task: Task) -> Any:
"""
执行计划
"""
results = []
for step in plan["steps"]:
action = step["action"]
if action in self.tools:
# 调用工具
tool_result = self.tools[action].execute(**step.get("input", {}))
results.append({"step": step["order"], "tool": action, "result": tool_result})
else:
# 直接处理
direct_result = self._direct_process(action, step.get("input", {}), task)
results.append({"step": step["order"], "action": action, "result": direct_result})
return results
def _direct_process(self, action: str, input_data: Dict, task: Task) -> Any:
"""
直接处理(不通过工具)
"""
process_prompt = f"""
执行以下处理步骤:
动作:{action}
输入:{json.dumps(input_data)}
原始任务:{json.dumps(task.input_data)}
请直接输出处理结果。
"""
response = self.llm.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": process_prompt}]
)
return response.choices[0].message.content
def _calculate_metrics(self, task: Task, output: Any, success: bool) -> Dict[str, float]:
"""
计算执行指标
"""
metrics = {
"success": 1.0 if success else 0.0,
"output_length": len(str(output)) if output else 0,
"complexity_score": self._estimate_complexity(task)
}
return metrics
def _estimate_complexity(self, task: Task) -> float:
"""
估计任务复杂度
"""
# 基于输入数据量和类型估计复杂度
input_size = len(json.dumps(task.input_data))
return min(input_size / 1000, 10.0)
def _error_reflection(self, task: Task, error_msg: str) -> str:
"""
错误反思
"""
reflection_prompt = f"""
执行失败,请进行反思:
任务:{json.dumps(task.input_data)}
错误:{error_msg}
请分析失败原因并提出改进建议。
"""
response = self.llm.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": reflection_prompt}]
)
return response.choices[0].message.content
def _deep_reflection(self) -> str:
"""
深度反思:基于最近N次执行进行系统性反思
"""
recent_executions = self.memory.executions[-self.reflection_threshold:]
success_count = sum(1 for e in recent_executions if e.success)
success_rate = success_count / len(recent_executions)
reflection_prompt = f"""
进行深度反思:
最近{self.reflection_threshold}次执行统计:
- 成功率:{success_rate:.2%}
- 平均指标:{self._avg_metrics(recent_executions)}
失败案例分析:
{self._format_failures(recent_executions)}
请分析系统表现,识别改进机会,并提出策略优化建议。
"""
response = self.llm.chat.completions.create(
model="gpt-5.4",
messages=[{"role": "user", "content": reflection_prompt}]
)
return response.choices[0].message.content
def _self_evolve(self):
"""
自进化:基于反思结果优化策略
"""
# 分析历史数据,识别高效策略
strategy_analysis = self._analyze_strategies()
# 更新策略库
for strategy_name, stats in strategy_analysis.items():
if strategy_name in self.strategies:
self.strategies[strategy_name].success_rate = stats["success_rate"]
self.strategies[strategy_name].usage_count = stats["usage_count"]
# 生成新策略变体
new_strategies = self._generate_strategy_variants()
for strategy in new_strategies:
self.strategies[strategy.name] = strategy
def _analyze_strategies(self) -> Dict[str, Dict]:
"""
分析策略效果
"""
# 实现策略分析逻辑
return {}
def _generate_strategy_variants(self) -> List[Strategy]:
"""
生成策略变体
"""
# 实现策略生成逻辑
return []
def _case_to_dict(self, case: ExecutionResult) -> Dict:
"""转换案例为字典"""
return {
"task_id": case.task_id,
"success": case.success,
"metrics": case.metrics,
"reflection": case.reflection
}
def _strategy_to_dict(self, strategy: Strategy) -> Dict:
"""转换策略为字典"""
return {
"name": strategy.name,
"parameters": strategy.parameters,
"success_rate": strategy.success_rate
}
def _avg_metrics(self, executions: List[ExecutionResult]) -> Dict[str, float]:
"""计算平均指标"""
if not executions:
return {}
all_metrics = [e.metrics for e in executions]
avg = {}
for key in all_metrics[0].keys():
values = [m.get(key, 0) for m in all_metrics]
avg[key] = sum(values) / len(values)
return avg
def _format_failures(self, executions: List[ExecutionResult]) -> str:
"""格式化失败案例"""
failures = [e for e in executions if not e.success]
return json.dumps([{"task": e.task_id, "reflection": e.reflection} for e in failures])
# ==================== 使用示例 ====================
class SearchTool(Tool):
"""搜索工具示例"""
def execute(self, query: str, num_results: int = 5) -> Dict:
# 实际实现中调用搜索API
return {
"query": query,
"results": [f"Result {i} for {query}" for i in range(num_results)]
}
def get_schema(self) -> Dict:
return {
"name": "search",
"description": "搜索网络信息",
"parameters": {
"type": "object",
"properties": {
"query": {"type": "string"},
"num_results": {"type": "integer", "default": 5}
},
"required": ["query"]
}
}
# 初始化Agent
# agent = SelfEvolvingAgent(llm_client=openai.OpenAI())
# agent.register_tool("search", SearchTool())
# 创建任务
# task = Task(
# id="research_001",
# type="research",
# input_data={"topic": "Agentic AI trends 2026"}
# )
# 执行任务
# result = agent.execute(task)六、风险与注意事项
6.1 转型过程中的常见陷阱
陷阱一:过度工程化
很多Prompt工程师在转型初期容易陷入"为了Agentic而Agentic"的误区,把简单的任务复杂化。
应对策略:
- 始终从业务价值出发,而非技术炫技
- 使用"复杂度-收益"矩阵评估每个Agentic组件的必要性
- 保持MVP思维,先跑通再优化
陷阱二:忽视成本监控
Agentic系统的工具调用、多轮推理会带来显著的API成本。
应对策略:
- 建立成本预算和告警机制
- 实现智能路由(简单任务用小模型)
- 使用缓存减少重复调用
陷阱三:低估维护成本
Agentic系统比Prompt工程复杂得多,需要持续维护。
应对策略:
- 建立完善的监控和日志体系
- 设计可观测的Agent行为
- 预留20-30%的维护时间预算
6.2 Prompt工程完全消失了吗?
答案是否定的。
Prompt工程并没有消失,而是:
- 下沉为基础设施:被框架和工具封装
- 转化为系统配置:成为Agent配置的一部分
- 聚焦高价值场景:在需要精细控制的场景仍有价值
对于Agentic系统工程师而言,Prompt工程能力仍是基础,但不再是核心竞争力。
七、总结与行动清单
7.1 核心观点回顾
- Prompt工程正在快速贬值:从2023年的高薪技能贬值为2026年的基础操作
- Agentic AI是新的价值锚点:系统架构、工具调用、自反思能力成为核心竞争力
- 转型路径清晰可行:3步转型框架(工具调用→工作流编排→系统架构)已被验证
- 商业回报显著:案例数据显示Agentic方案可带来300%+的收入提升
7.2 立即行动清单
本周内完成:
- 完成第一个Function Calling项目
- 阅读LangGraph官方文档
- 在GitHub上fork 3个开源Agent项目学习
本月内完成:
- 构建一个完整的Tool-Using Agent
- 实现一个多步骤工作流
- 建立个人Agentic项目作品集
本季度内完成:
- 掌握Multi-Agent架构设计
- 完成至少一个商业级Agentic项目
- 建立行业影响力(博客/演讲/开源贡献)
7.3 长期发展建议
技能栈升级:
原技能 | 升级方向 | 优先级 |
|---|---|---|
Prompt调优 | 系统架构设计 | ★★★★★ |
单轮对话 | 多轮状态管理 | ★★★★★ |
文本生成 | 工具调用集成 | ★★★★★ |
人工审核 | 自反思机制 | ★★★★☆ |
手动配置 | 自动优化 | ★★★★☆ |
职业定位调整:
从"Prompt工程师"升级为:
- Agentic系统工程师
- AI自动化架构师
- 智能工作流设计师
这些新定位的薪资水平已经超越传统Prompt工程师50-150%。
参考链接:
- 主要来源:GitHub Jobs API - 职位与薪资数据
- 辅助:LangGraph Documentation - Agent框架官方文档
- 辅助:OpenAI Function Calling Guide - 工具调用指南
- 辅助:Anthropic Claude Tool Use - Claude工具使用文档
附录(Appendix):
A. 薪资数据来源说明
本文薪资数据综合自:
- GitHub Jobs API 2024-2026年职位发布数据
- LinkedIn Talent Insights薪酬报告
- Levels.fyi技术岗位薪酬数据库
- 作者团队招聘实践数据
数据处理方法:
- 取各平台同岗位的中位数
- 按地区(美国/欧洲/亚太)加权平均
- 考虑公司规模(初创/中型/大型)调整
B. 案例数据验证方法
文中三个案例的数据通过以下方式验证:
- 与案例公司技术负责人直接访谈
- 对比公开财报和博客披露信息
- 使用行业基准数据进行交叉验证
C. 自进化Agent模板扩展建议
基础模板可根据以下方向扩展:
- 添加向量数据库存储长期记忆
- 集成权重与偏差(Weights & Biases)进行实验跟踪
- 实现A/B测试框架比较不同策略
- 添加Web界面进行人工干预和反馈
关键词: Agentic AI, Prompt工程, 2026趋势, 技能转型, 自进化Agent, 工具调用, LangGraph, Multi-Agent, 商业价值, 自动化工作流, 安全风信子, 技术深度

在这里插入图片描述

请添加图片描述
- 数据来源:GitHub Jobs API 2024-2026、LinkedIn Talent Insights Q1-Q4报告、Levels.fyi薪酬数据库综合整理 ↩︎
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号