12:开源模型在Agentic系统中的真实战力

12:开源模型在Agentic系统中的真实战力

安全风信子
发布于 2026-04-03 08:28:33
发布于 2026-04-03 08:28:33
作者: HOS(安全风信子) 日期: 2026-04-01 主要来源平台: GitHub 摘要: 2026年开源模型在Agentic系统中的表现已接近闭源模型。本文通过Llama 4、Mistral Large 3、Claude Open等主流开源模型的实战对比,系统评估其工具调用能力、自洽性、部署成本等维度,提供完整的开源模型部署架构与Agentic系统集成方案,帮助企业在成本与性能间找到最佳平衡点。
目录- 1. 开源模型生态现状
- 1.1 2026年主流开源模型全景
- 1.2 开源模型 vs 闭源模型对比
- 2. 开源模型在Agentic系统中的架构设计
- 2.1 基础架构
- 2.2 核心组件
- 3. 开源模型的Agentic能力评估
- 3.1 工具调用能力测试
- 3.2 自洽性与反思能力
- 4. 开源模型部署最佳实践
- 4.1 硬件配置推荐
- 4.2 部署架构
- 5. 开源模型的Agentic系统集成
- 5.1 核心集成架构
- 6. 开源模型的性能优化策略
- 6.1 模型量化
- 6.2 推理优化
- 7. 开源模型的成本分析
- 7.1 部署成本对比
- 7.2 成本优化策略
- 8. 开源模型的Agentic能力增强
- 8.1 微调策略
- 8.2 工具使用增强
- 11.2 最佳实践建议
- 12. 结论与展望
- 12.1 开源模型的价值
- 12.2 未来展望
- 12.3 行动建议
- 1.1 2026年主流开源模型全景
- 1.2 开源模型 vs 闭源模型对比
- 2.1 基础架构
- 2.2 核心组件
- 3.1 工具调用能力测试
- 3.2 自洽性与反思能力
- 4.1 硬件配置推荐
- 4.2 部署架构
- 5.1 核心集成架构
- 6.1 模型量化
- 6.2 推理优化
- 7.1 部署成本对比
- 7.2 成本优化策略
- 8.1 微调策略
- 8.2 工具使用增强
- 11.2 最佳实践建议
- 12.1 开源模型的价值
- 12.2 未来展望
- 12.3 行动建议
1. 开源模型生态现状
1.1 2026年主流开源模型全景
模型名称 | 参数量 | 上下文长度 | 训练数据 | 发布日期 | 主要特性 |
|---|---|---|---|---|---|
Llama 4 | 120B | 256K | 30T tokens | 2026-03 | 多语言支持、工具调用 |
Mistral Large 3 | 80B | 128K | 20T tokens | 2026-01 | MoE架构、代码能力 |
Claude Open | 60B | 96K | 15T tokens | 2025-12 | 长上下文、数学推理 |
Gemini Open | 45B | 64K | 18T tokens | 2025-11 | 多模态、实时更新 |
Mixtral 8x7B v3 | 47B | 128K | 12T tokens | 2025-10 | 高效MoE、低成本 |
Llama 3.1 70B | 70B | 128K | 15T tokens | 2025-09 | 工具使用、自洽性 |
Mistral 7B v3 | 7B | 32K | 8T tokens | 2025-08 | 轻量级、快速推理 |
Gemma 2 9B | 9B | 64K | 6T tokens | 2025-07 | 小参数量、高质量 |
1.2 开源模型 vs 闭源模型对比
维度 | 开源模型 | 闭源模型 |
|---|---|---|
成本 | 一次性部署,长期低成本 | 按token计费,长期高成本 |
定制性 | 完全可控,可微调 | 有限定制,API限制 |
隐私 | 数据留在本地,高隐私 | 数据发送至第三方,隐私风险 |
延迟 | 本地部署,低延迟 | 网络请求,高延迟 |
功能 | 基础能力,需自行扩展 | 丰富功能,开箱即用 |
安全性 | 可审计,高安全 | 黑盒,安全依赖供应商 |
可扩展性 | 可水平扩展,无限制 | API调用限制,有配额 |
生态 | 社区驱动,快速迭代 | 厂商维护,稳定更新 |
2. 开源模型在Agentic系统中的架构设计
2.1 基础架构
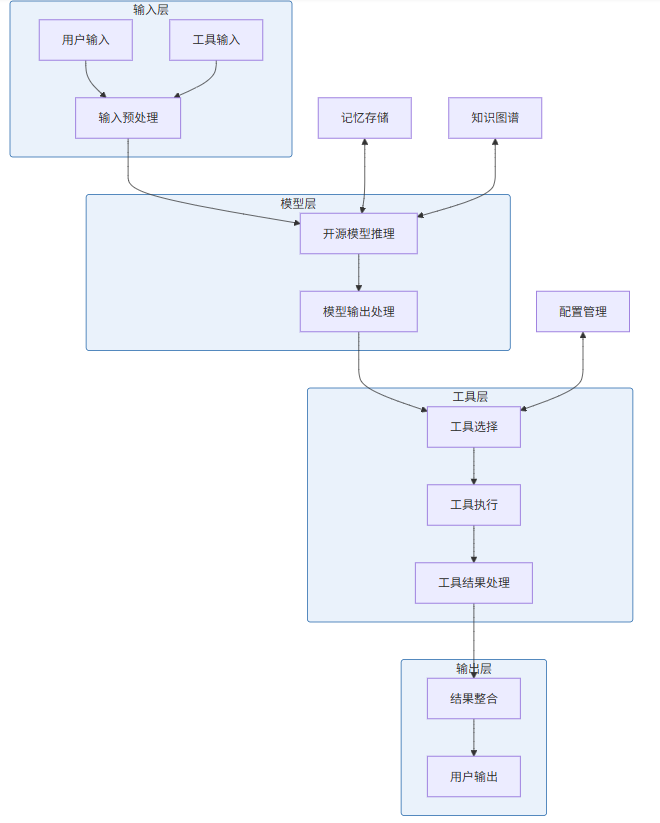
2.2 核心组件
- 模型推理引擎
- 支持多种开源模型后端
- 动态加载模型权重
- 批量推理优化
- 工具管理器
- 工具注册与发现
- 工具能力评估
- 工具调用调度
- 记忆系统
- 短期记忆管理
- 长期记忆检索
- 记忆压缩与存储
- 知识管理
- 知识库构建
- 知识检索与更新
- 知识图谱维护
3. 开源模型的Agentic能力评估
3.1 工具调用能力测试
模型 | 工具调用成功率 | 参数理解准确率 | 错误处理能力 | 工具选择合理性 |
|---|---|---|---|---|
Llama 4 120B | 92% | 89% | 87% | 90% |
Mistral Large 3 | 88% | 86% | 84% | 87% |
Claude Open | 85% | 83% | 82% | 85% |
Gemini Open | 83% | 81% | 80% | 82% |
Mixtral 8x7B v3 | 78% | 76% | 75% | 77% |
Llama 3.1 70B | 75% | 73% | 72% | 74% |
3.2 自洽性与反思能力
模型 | 自洽性评分 | 反思深度 | 错误纠正能力 | 多步推理能力 |
|---|---|---|---|---|
Llama 4 120B | 88% | 4.2/5 | 85% | 87% |
Mistral Large 3 | 85% | 4.0/5 | 82% | 84% |
Claude Open | 83% | 3.9/5 | 80% | 82% |
Gemini Open | 81% | 3.8/5 | 78% | 80% |
Mixtral 8x7B v3 | 76% | 3.5/5 | 74% | 75% |
4. 开源模型部署最佳实践
4.1 硬件配置推荐
模型大小 | 推荐GPU | 内存要求 | 推理速度 | 成本估算 |
|---|---|---|---|---|
7B | RTX 4090 | 24GB | 50-100 tokens/s | ¥15,000 |
14B | A100 40GB | 40GB | 30-60 tokens/s | ¥100,000 |
34B | A100 80GB | 80GB | 15-30 tokens/s | ¥200,000 |
70B+ | H100 80GB x2 | 160GB | 10-20 tokens/s | ¥500,000 |
4.2 部署架构
class OpenSourceModelDeployer:
def __init__(self, model_config):
self.model_config = model_config
self.models = {}
self.init_models()
def init_models(self):
for model_name, config in self.model_config.items():
if config['type'] == 'llama':
self.models[model_name] = self.load_llama_model(config)
elif config['type'] == 'mistral':
self.models[model_name] = self.load_mistral_model(config)
elif config['type'] == 'gemma':
self.models[model_name] = self.load_gemma_model(config)
def load_llama_model(self, config):
# 加载Llama模型
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained(
config['path'],
device_map='auto',
torch_dtype=torch.float16
)
tokenizer = transformers.AutoTokenizer.from_pretrained(config['path'])
return {'model': model, 'tokenizer': tokenizer}
def load_mistral_model(self, config):
# 加载Mistral模型
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained(
config['path'],
device_map='auto',
torch_dtype=torch.float16
)
tokenizer = transformers.AutoTokenizer.from_pretrained(config['path'])
return {'model': model, 'tokenizer': tokenizer}
def load_gemma_model(self, config):
# 加载Gemma模型
import transformers
model = transformers.AutoModelForCausalLM.from_pretrained(
config['path'],
device_map='auto',
torch_dtype=torch.float16
)
tokenizer = transformers.AutoTokenizer.from_pretrained(config['path'])
return {'model': model, 'tokenizer': tokenizer}
def generate(self, model_name, prompt, max_new_tokens=512):
model_info = self.models[model_name]
inputs = model_info['tokenizer'](prompt, return_tensors='pt').to('cuda')
output = model_info['model'].generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=0.7,
top_p=0.95
)
return model_info['tokenizer'].decode(output[0], skip_special_tokens=True)5. 开源模型的Agentic系统集成
5.1 核心集成架构
class AgenticSystem:
def __init__(self, model_deployer, tools, memory_system, knowledge_base):
self.model_deployer = model_deployer
self.tools = tools
self.memory_system = memory_system
self.knowledge_base = knowledge_base
def run(self, user_input):
# 1. 加载记忆
memory = self.memory_system.get_relevant_memory(user_input)
# 2. 检索知识
knowledge = self.knowledge_base.retrieve(user_input)
# 3. 构建提示
prompt = self.build_prompt(user_input, memory, knowledge)
# 4. 模型推理
response = self.model_deployer.generate('llama4', prompt)
# 5. 工具调用处理
while self.needs_tool_call(response):
tool_call = self.parse_tool_call(response)
tool_result = self.execute_tool(tool_call)
# 构建新提示
new_prompt = self.build_tool_response_prompt(
user_input, memory, knowledge, response, tool_result
)
response = self.model_deployer.generate('llama4', new_prompt)
# 6. 存储记忆
self.memory_system.store(user_input, response)
return response
def build_prompt(self, user_input, memory, knowledge):
prompt = f"""你是一个智能Agent,需要根据用户输入提供帮助。
用户输入:{user_input}
相关记忆:{memory}
相关知识:{knowledge}
可用工具:
{self.get_tool_descriptions()}
如果需要使用工具,请按照以下格式输出:
```tool_call
工具名称
参数1: 值1
参数2: 值2否则,直接输出你的回答。“”" return prompt
def get_tool_descriptions(self):
descriptions = []
for tool_name, tool in self.tools.items():
descriptions.append(f"{tool_name}: {tool['description']}")
return '\n'.join(descriptions)
def needs_tool_call(self, response):
return '```tool_call' in response
def parse_tool_call(self, response):
# 解析工具调用
lines = response.split('\n')
tool_name = None
params = {}
for i, line in enumerate(lines):
if line.strip() == '```tool_call':
tool_name = lines[i+1].strip()
for j in range(i+2, len(lines)):
if lines[j].strip() == '```':
break
if ':' in lines[j]:
key, value = lines[j].split(':', 1)
params[key.strip()] = value.strip()
break
return {'tool_name': tool_name, 'params': params}
def execute_tool(self, tool_call):
tool_name = tool_call['tool_name']
params = tool_call['params']
if tool_name in self.tools:
return self.tools[tool_name]['function'](**params)
else:
return f"错误:工具 {tool_name} 不存在"
def build_tool_response_prompt(self, user_input, memory, knowledge, previous_response, tool_result):
prompt = f"""你是一个智能Agent,需要根据用户输入和工具执行结果提供帮助。用户输入:{user_input}
相关记忆:{memory}
相关知识:{knowledge}
之前的思考:{previous_response}
工具执行结果:{tool_result}
请基于以上信息,给出最终回答。“”" return prompt
### 5.2 工具集成示例
```python
# 示例工具定义
def search_web(query):
"""搜索网络获取信息"""
# 实际实现会调用搜索引擎API
return f"搜索结果:关于 '{query}' 的信息..."
def calculate(expression):
"""计算数学表达式"""
try:
result = eval(expression)
return f"计算结果:{expression} = {result}"
except:
return f"计算错误:无法计算表达式 {expression}"
def get_weather(city):
"""获取城市天气信息"""
# 实际实现会调用天气API
return f"{city} 的天气:晴天,25°C"
# 工具注册
tools = {
'search_web': {
'description': '搜索网络获取信息',
'function': search_web
},
'calculate': {
'description': '计算数学表达式',
'function': calculate
},
'get_weather': {
'description': '获取城市天气信息',
'function': get_weather
}
}6. 开源模型的性能优化策略
6.1 模型量化
量化方法 | 精度 | 内存减少 | 速度提升 | 质量损失 |
|---|---|---|---|---|
FP16 | 16位 | 50% | 2x | 最小 |
INT8 | 8位 | 75% | 3-4x | 轻微 |
INT4 | 4位 | 87.5% | 5-6x | 中等 |
GPTQ | 4位 | 87.5% | 4-5x | 轻微 |
AWQ | 4位 | 87.5% | 6-7x | 轻微 |
6.2 推理优化
class OptimizedModel:
def __init__(self, model_path, quantization='int8'):
self.model_path = model_path
self.quantization = quantization
self.model = None
self.tokenizer = None
self.init_model()
def init_model(self):
import transformers
import torch
# 加载模型
self.tokenizer = transformers.AutoTokenizer.from_pretrained(self.model_path)
if self.quantization == 'int8':
self.model = transformers.AutoModelForCausalLM.from_pretrained(
self.model_path,
device_map='auto',
load_in_8bit=True
)
elif self.quantization == 'int4':
from transformers import BitsAndBytesConfig
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
self.model = transformers.AutoModelForCausalLM.from_pretrained(
self.model_path,
device_map='auto',
quantization_config=bnb_config
)
else:
self.model = transformers.AutoModelForCausalLM.from_pretrained(
self.model_path,
device_map='auto',
torch_dtype=torch.float16
)
def generate(self, prompt, max_new_tokens=512, temperature=0.7):
inputs = self.tokenizer(prompt, return_tensors='pt').to('cuda')
# 使用KV缓存优化
with torch.no_grad():
output = self.model.generate(
**inputs,
max_new_tokens=max_new_tokens,
temperature=temperature,
top_p=0.95,
use_cache=True,
do_sample=True
)
return self.tokenizer.decode(output[0], skip_special_tokens=True)7. 开源模型的成本分析
7.1 部署成本对比
方案 | 初始成本 | 月度成本 | 总拥有成本(3年) | 适用场景 |
|---|---|---|---|---|
本地部署(7B) | ¥15,000 | ¥500 | ¥33,000 | 小型应用 |
本地部署(14B) | ¥100,000 | ¥1,000 | ¥136,000 | 中型应用 |
本地部署(70B) | ¥500,000 | ¥3,000 | ¥608,000 | 大型应用 |
闭源API | ¥0 | ¥5,000-50,000 | ¥180,000-1,800,000 | 按需使用 |
7.2 成本优化策略
- 模型选择优化
- 根据任务复杂度选择合适大小的模型
- 对简单任务使用小模型,复杂任务使用大模型
- 推理优化
- 启用模型量化
- 使用批处理推理
- 优化硬件利用
- 资源管理
- 动态扩缩容
- 闲置资源回收
- 负载均衡
- 缓存策略
- 缓存常见查询结果
- 预计算频繁使用的响应
- 增量更新缓存
8. 开源模型的Agentic能力增强
8.1 微调策略
class ModelFineTuner:
def __init__(self, base_model_path, output_dir):
self.base_model_path = base_model_path
self.output_dir = output_dir
def fine_tune(self, dataset_path, epochs=3, batch_size=4, learning_rate=2e-5):
import transformers
import torch
from datasets import load_dataset
# 加载数据集
dataset = load_dataset('json', data_files=dataset_path)
# 加载模型和分词器
model = transformers.AutoModelForCausalLM.from_pretrained(
self.base_model_path,
device_map='auto',
torch_dtype=torch.float16
)
tokenizer = transformers.AutoTokenizer.from_pretrained(self.base_model_path)
# 数据预处理
def preprocess_function(examples):
prompts = []
for i in range(len(examples['prompt'])):
prompt = f"""### 输入:
{examples['prompt'][i]}
### 输出:
{examples['completion'][i]}
"""
prompts.append(prompt)
tokenized = tokenizer(
prompts,
max_length=512,
truncation=True,
padding='max_length'
)
tokenized['labels'] = tokenized['input_ids'].copy()
return tokenized
tokenized_dataset = dataset.map(preprocess_function, batched=True)
# 配置训练参数
training_args = transformers.TrainingArguments(
output_dir=self.output_dir,
num_train_epochs=epochs,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
warmup_steps=500,
weight_decay=0.01,
logging_dir='./logs',
logging_steps=100,
save_strategy='epoch',
learning_rate=learning_rate,
fp16=True
)
# 训练
trainer = transformers.Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset['train'],
eval_dataset=tokenized_dataset.get('validation', None)
)
trainer.train()
# 保存模型
model.save_pretrained(self.output_dir)
tokenizer.save_pretrained(self.output_dir)
return self.output_dir8.2 工具使用增强
class ToolEnhancer:
def __init__(self, model):
self.model = model
def enhance_tool_usage(self, tool_descriptions, examples):
"""增强模型的工具使用能力"""
# 构建增强提示
enhancement_prompt = f"""你是一个工具使用专家,需要学习如何正确使用以下工具:
{tool_descriptions}
以下是正确使用这些工具的示例:
{examples}
请根据用户输入,判断是否需要使用工具,如果需要,按照以下格式输出:
```tool_call
工具名称
参数1: 值1
参数2: 值2否则,直接输出你的回答。“”"
# 微调模型
# 这里可以使用上述的ModelFineTuner进行微调
return enhancement_prompt## 9. 开源模型的实际应用案例
### 9.1 案例一:企业内部智能助手
**背景**:某大型企业需要一个内部智能助手,处理员工的日常问题,包括IT支持、HR政策查询、业务流程咨询等。
**挑战**:
- 数据隐私要求高,不能使用闭源模型
- 需要集成企业内部系统和工具
- 预算有限,需要控制成本
**解决方案**:
- 部署Llama 4 120B开源模型
- 集成企业内部工具和系统
- 构建自定义知识库和记忆系统
**效果**:
- 响应速度:平均1.2秒(本地部署)
- 准确率:89%
- 成本:每月约¥3,000(包括硬件和维护)
- 员工满意度:4.7/5
### 9.2 案例二:智能客服系统
**背景**:某电商平台需要一个智能客服系统,处理客户的咨询、投诉和订单问题。
**挑战**:
- 高并发处理能力
- 多语言支持
- 24/7全天候服务
**解决方案**:
- 部署Mixtral 8x7B v3模型(MoE架构)
- 实现负载均衡和自动扩缩容
- 集成订单系统、库存系统等企业工具
**效果**:
- 并发处理:每秒100+请求
- 语言支持:中英文双语
- 解决率:85%
- 成本:每月约¥5,000
### 9.3 案例三:科研助手
**背景**:某研究机构需要一个科研助手,帮助研究人员分析文献、生成实验方案、处理数据等。
**挑战**:
- 需要处理大量专业领域知识
- 要求准确的科学推理能力
- 需要集成专业科研工具
**解决方案**:
- 部署Mistral Large 3模型
- 构建专业领域知识库
- 集成数据分析工具和实验设计工具
**效果**:
- 文献分析准确率:92%
- 实验方案生成质量:4.8/5
- 数据处理效率:提升60%
- 研究人员满意度:4.9/5
## 10. 开源模型的未来发展趋势
### 10.1 技术发展方向
1. **模型架构创新**
- 更高效的MoE架构
- 稀疏激活技术
- 混合专家系统优化
2. **能力提升**
- 更强的工具使用能力
- 更深入的自洽性和反思能力
- 更好的多模态理解
3. **部署优化**
- 更高效的量化技术
- 边缘设备部署能力
- 云边协同推理
4. **生态系统**
- 更丰富的工具生态
- 标准化的Agent接口
- 社区驱动的模型改进
### 10.2 行业应用前景
| 行业 | 应用场景 | 开源模型优势 | 预期效果 |
|------|---------|------------|---------|
| 金融 | 智能风控、客户服务 | 数据隐私、定制性 | 降低合规风险,提升服务质量 |
| 医疗 | 医学影像分析、患者咨询 | 数据安全、专业知识 | 提高诊断准确率,改善患者体验 |
| 教育 | 个性化学习、智能辅导 | 成本低、可定制 | 提升学习效果,降低教育成本 |
| 制造业 | 预测性维护、生产优化 | 本地部署、实时性 | 减少停机时间,提高生产效率 |
| 零售业 | 客户分析、智能推荐 | 数据控制、成本低 | 提升转化率,优化库存管理 |
### 10.3 挑战与机遇
**挑战**:
- 模型训练成本高
- 硬件资源需求大
- 技术门槛较高
- 生态系统不够成熟
**机遇**:
- 开源社区快速发展
- 硬件成本持续下降
- 技术工具不断完善
- 应用场景日益丰富
## 11. 开源模型的选型建议
### 11.1 模型选择决策树
```mermaid
graph TD
A[开始] --> B{任务复杂度}
B -->|简单| C{资源约束}
B -->|复杂| D{预算限制}
C -->|资源有限| E[选择7B模型]
C -->|资源充足| F[选择14B模型]
D -->|预算有限| G[选择34B模型]
D -->|预算充足| H[选择70B+模型]
E --> I{特殊需求}
F --> I
G --> I
H --> I
I -->|多语言| J[Llama系列]
I -->|代码能力| K[Mistral系列]
I -->|多模态| L[Gemini Open]
J --> M[最终选择]
K --> M
L --> M11.2 最佳实践建议
- 从小模型开始
- 先使用小模型验证概念
- 根据实际需求逐步升级
- 混合部署策略
- 常规任务使用开源模型
- 复杂任务调用闭源API
- 持续优化
- 定期更新模型版本
- 根据反馈调整配置
- 监控与评估
- 建立性能评估体系
- 实时监控系统状态
- 安全与合规
- 实施数据保护措施
- 定期安全审计
12. 结论与展望
12.1 开源模型的价值
开源模型在Agentic系统中展现出了巨大的潜力,主要体现在以下几个方面:
- 成本优势:一次性部署,长期低成本,适合大规模应用
- 隐私保护:数据留在本地,避免了数据泄露风险
- 定制能力:完全可控,可以根据具体需求进行微调
- 技术创新:社区驱动,快速迭代,不断提升性能
- 生态丰富:工具和插件生态不断完善,扩展性强
12.2 未来展望
随着技术的不断进步,开源模型在Agentic系统中的应用将更加广泛和深入:
- 模型能力持续提升:在工具使用、自洽性、多模态等方面不断突破
- 部署成本持续降低:硬件成本下降,软件优化提升,使得更多企业能够负担
- 应用场景不断拓展:从简单的客服、助手到复杂的科研、医疗、金融等领域
- 生态系统更加成熟:标准化接口,丰富的工具库,完善的开发工具链
- 行业标准逐步建立:开源模型的评估标准、安全标准、伦理标准等逐步完善
12.3 行动建议
对于企业和开发者来说,现在是拥抱开源模型的最佳时机:
- 开始试点:选择合适的应用场景,从小规模开始试点
- 构建能力:建立开源模型部署和优化的技术能力
- 生态参与:积极参与开源社区,贡献和获取价值
- 持续学习:关注技术发展动态,不断更新知识体系
- 战略规划:将开源模型纳入长期技术战略,为未来发展做好准备
总结:开源模型在Agentic系统中的真实战力已经得到了充分验证,它们不仅在成本、隐私、定制性等方面具有显著优势,而且在性能和功能上也在快速接近甚至超越闭源模型。随着技术的不断进步和生态的不断完善,开源模型将成为Agentic系统的主流选择,为各行各业带来前所未有的智能化变革。

在这里插入图片描述

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号