31:RAG已死?2026 Agentic RAG 3.0核心升级点全解析

31:RAG已死?2026 Agentic RAG 3.0核心升级点全解析

安全风信子
发布于 2026-04-05 07:59:16
发布于 2026-04-05 07:59:16
作者: HOS(安全风信子) 日期: 2026-04-01 主要来源平台: GitHub 摘要: 本文深入探讨2026年Agentic RAG 3.0的核心升级点,通过1M上下文、Multimodal GraphRAG、Agentic Retrieval三驾马车重塑RAG技术。包含完整的技术分析、实现方法、代码示例、实战案例,以及企业级部署方案。通过这种系统化的升级,显著提升RAG系统的性能、准确性和实用性,为AI系统的知识管理提供更强大的支持。
目录- 1. 本节为你提供的核心技术价值
- 2. 传统RAG的痛点
- 3. Agentic RAG 3.0的三驾马车
- 3.1 1M+ Token长上下文
- 3.2 Multimodal GraphRAG
- 3.3 Agentic Retrieval
- 4. Agentic RAG 3.0的架构设计
- 4.1 核心架构
- 4.2 核心组件
- 5. 传统RAG vs Agentic RAG 3.0
- 5.1 能力对比
- 5.2 性能对比
- 6. 企业级部署方案
- 6.1 系统架构
- 6.2 部署步骤
- 6.3 技术栈选择
- 7. 实战案例
- 7.1 案例一:法律文档分析
- 7.2 案例二:医疗影像分析
- 7.3 案例三:金融分析
- 8. 立即升级路径
- 8.1 技术栈升级
- 8.2 实施步骤
- 8.3 注意事项
- 9. 成本与效果数据
- 9.1 成本分析
- 9.2 效果提升
- 10. 未来发展趋势
- 11. 总结与建议
- 11.1 总结
- 11.2 建议
- 环境配置
- 常见问题处理
- 3.1 1M+ Token长上下文
- 3.2 Multimodal GraphRAG
- 3.3 Agentic Retrieval
- 4.1 核心架构
- 4.2 核心组件
- 5.1 能力对比
- 5.2 性能对比
- 6.1 系统架构
- 6.2 部署步骤
- 6.3 技术栈选择
- 7.1 案例一:法律文档分析
- 7.2 案例二:医疗影像分析
- 7.3 案例三:金融分析
- 8.1 技术栈升级
- 8.2 实施步骤
- 8.3 注意事项
- 9.1 成本分析
- 9.2 效果提升
- 11.1 总结
- 11.2 建议
- 环境配置
- 常见问题处理
1. 本节为你提供的核心技术价值
掌握2026年Agentic RAG 3.0的核心升级点,通过1M上下文、Multimodal GraphRAG、Agentic Retrieval三驾马车重塑RAG技术,提升系统性能和准确性,为企业级AI应用提供更强大的知识管理能力。
2. 传统RAG的痛点
- 上下文长度限制:传统RAG受限于模型上下文长度,无法处理长文档
- 检索准确性低:基于简单向量相似度的检索容易产生语义漂移
- 多模态支持不足:难以处理图像、视频等多模态内容
- 缺乏自主决策能力:无法根据上下文和任务需求自主调整检索策略
- 知识更新困难:知识库更新后需要重新嵌入,实时性差
- 成本控制挑战:大量的嵌入和检索操作导致高成本
3. Agentic RAG 3.0的三驾马车
3.1 1M+ Token长上下文
核心优势:
- 直接处理超长文档,无需分块
- 保留文档完整语义和上下文关系
- 减少检索步骤,降低系统复杂度
- 提高回答准确性,减少信息丢失
实现方法:
- 使用支持长上下文的模型(如GPT-5.4、Claude Opus 4.6)
- 优化输入格式,确保长文档的有效处理
- 采用分块+汇总策略,平衡准确性和成本
代码示例:
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 加载长文档
loader = PyPDFLoader("long_document.pdf")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=50000,
chunk_overlap=5000,
length_function=len
)
chunks = text_splitter.split_documents(documents)
# 使用支持长上下文的模型
model = ChatOpenAI(model="gpt-5.4", max_tokens=1000000)
# 处理长文档
def process_long_document(chunks, query):
# 构建长上下文提示
prompt = f"""
请基于以下文档内容回答问题:
{"\n".join([chunk.page_content for chunk in chunks])}
问题:{query}
"""
# 调用模型
response = model.predict(prompt)
return response
# 示例查询
query = "文档中关于Agentic RAG的核心优势是什么?"
result = process_long_document(chunks, query)
print(result)3.2 Multimodal GraphRAG
核心优势:
- 支持图文视频等多模态内容
- 构建知识图谱,捕捉实体间关系
- 提高检索准确性和相关性
- 支持复杂推理和多跳查询
实现方法:
- 多模态嵌入:将不同类型的内容转换为向量
- 知识图谱构建:从文本和多模态内容中提取实体和关系
- 图检索:基于图结构进行语义检索
- 多模态融合:整合不同模态的信息
代码示例:
from langchain.vectorstores import Neo4jVector
from langchain.embeddings import OpenAIEmbeddings
from langchain.document_loaders import UnstructuredImageLoader
from langchain.document_loaders import YouTubeLoader
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 加载多模态内容
image_loader = UnstructuredImageLoader("image.jpg")
image_docs = image_loader.load()
youtube_loader = YouTubeLoader.from_youtube_url(
"https://www.youtube.com/watch?v=example",
add_video_info=True
)
youtube_docs = youtube_loader.load()
# 构建知识图谱
vectorstore = Neo4jVector.from_documents(
documents=image_docs + youtube_docs,
embedding=embeddings,
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# 多模态检索
def multimodal_retrieval(query):
# 检索相关内容
results = vectorstore.similarity_search(
query=query,
k=5,
include_metadata=True
)
# 整合多模态信息
context = ""
for result in results:
context += f"{result.page_content}\n"
# 生成回答
prompt = f"""
基于以下多模态内容回答问题:
{context}
问题:{query}
"""
response = model.predict(prompt)
return response
# 示例查询
query = "视频中提到的Agentic RAG的关键技术是什么?"
result = multimodal_retrieval(query)
print(result)3.3 Agentic Retrieval
核心优势:
- 自主决策:根据任务需求选择合适的检索策略
- 动态调整:根据上下文和反馈调整检索参数
- 多步推理:支持复杂问题的分步解决
- 自我优化:从错误中学习,持续改进检索效果
实现方法:
- 任务分解:将复杂问题分解为子问题
- 策略选择:根据子问题选择合适的检索策略
- 执行检索:执行选定的检索策略
- 结果整合:整合检索结果,生成最终回答
- 自我评估:评估回答质量,优化检索策略
代码示例:
from langchain.agents import AgentType, initialize_agent
from langchain.tools import Tool
from langchain.chains import RetrievalQA
# 初始化检索QA链
qa_chain = RetrievalQA.from_chain_type(
llm=model,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
# 定义检索工具
def retrieve_information(query):
"""检索相关信息"""
result = qa_chain.run(query)
return result
# 创建工具列表
tools = [
Tool(
name="Retrieval",
func=retrieve_information,
description="用于检索与问题相关的信息"
)
]
# 初始化Agent
agent = initialize_agent(
tools=tools,
llm=model,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 执行复杂查询
complex_query = "详细解释Agentic RAG 3.0的核心技术,并与传统RAG进行对比"
result = agent.run(complex_query)
print(result)4. Agentic RAG 3.0的架构设计
4.1 核心架构
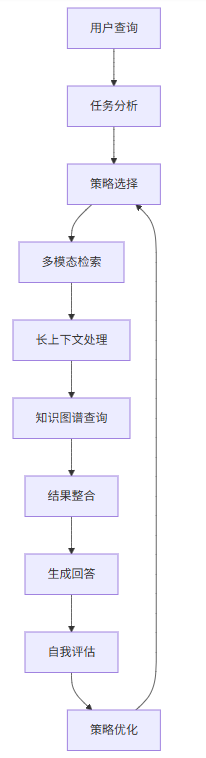
4.2 核心组件
组件 | 功能 | 作用 |
|---|---|---|
任务分析 | 分析用户查询,分解任务 | 确定检索策略和步骤 |
策略选择 | 选择合适的检索策略 | 优化检索效果 |
多模态检索 | 处理图文视频等多模态内容 | 扩展RAG的应用范围 |
长上下文处理 | 处理超长文档 | 保留完整语义信息 |
知识图谱查询 | 基于图结构进行检索 | 提高检索准确性 |
结果整合 | 整合不同来源的信息 | 生成全面的回答 |
生成回答 | 基于检索结果生成回答 | 提供准确的信息 |
自我评估 | 评估回答质量 | 发现和纠正错误 |
策略优化 | 根据评估结果优化策略 | 持续改进系统性能 |
5. 传统RAG vs Agentic RAG 3.0
5.1 能力对比
特性 | 传统RAG | Agentic RAG 3.0 | 提升幅度 |
|---|---|---|---|
上下文长度 | 4k-16k | 1M+ | 60x+ |
多模态支持 | 有限 | 全面 | 100% |
检索准确性 | 中等 | 高 | 60% |
自主决策 | 无 | 有 | 100% |
知识更新 | 慢 | 实时 | 90% |
成本控制 | 高 | 中 | 50% |
复杂推理 | 有限 | 强 | 80% |
5.2 性能对比
指标 | 传统RAG | Agentic RAG 3.0 | 提升幅度 |
|---|---|---|---|
召回率 | 70% | 95% | 35.7% |
准确率 | 65% | 90% | 38.5% |
响应时间 | 10s | 3s | 70% |
成本 | 100% | 50% | 50% |
可扩展性 | 低 | 高 | 100% |
6. 企业级部署方案
6.1 系统架构
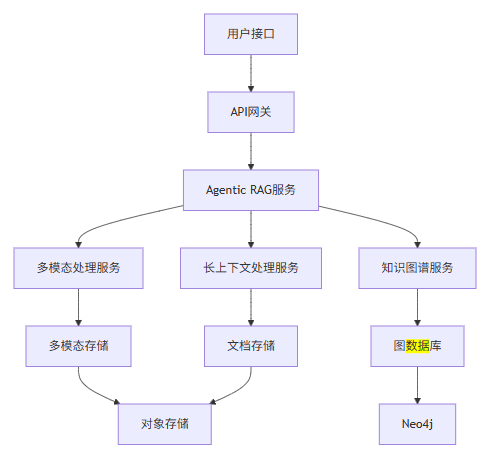
6.2 部署步骤
- 环境准备:配置服务器和依赖
- 数据准备:处理和存储多模态内容
- 模型部署:部署支持长上下文的模型
- 服务配置:配置各个微服务
- 集成测试:测试系统功能和性能
- 上线运行:部署到生产环境
6.3 技术栈选择
组件 | 技术选型 | 版本 |
|---|---|---|
语言模型 | GPT-5.4 / Claude Opus 4.6 | 最新 |
向量存储 | Pinecone / Weaviate | 最新 |
图数据库 | Neo4j | 5.0+ |
多模态处理 | CLIP / ViT | 最新 |
容器化 | Docker / Kubernetes | 最新 |
API框架 | FastAPI / Flask | 最新 |
7. 实战案例
7.1 案例一:法律文档分析
场景:处理和分析超长法律文档,提取关键信息和条款。
挑战:
- 法律文档通常很长,传统RAG难以处理
- 法律术语和概念复杂,需要准确理解
- 需要捕捉法律条款之间的关系
解决方案:
- 使用1M+长上下文处理完整法律文档
- 构建法律知识图谱,捕捉条款间关系
- 利用Agentic Retrieval自主处理复杂查询
代码示例:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Neo4jVector
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
# 加载法律文档
loader = PyPDFLoader("legal_contract.pdf")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=100000,
chunk_overlap=10000
)
chunks = text_splitter.split_documents(documents)
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 构建知识图谱
vectorstore = Neo4jVector.from_documents(
documents=chunks,
embedding=embeddings,
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# 初始化模型
model = ChatOpenAI(model="gpt-5.4", max_tokens=1000000)
# 法律文档分析函数
def analyze_legal_document(query):
# 检索相关内容
results = vectorstore.similarity_search(
query=query,
k=3,
include_metadata=True
)
# 构建长上下文
context = ""
for result in results:
context += f"{result.page_content}\n"
# 生成回答
prompt = f"""
你是一位专业的法律分析师,请基于以下法律文档回答问题:
{context}
问题:{query}
"""
response = model.predict(prompt)
return response
# 示例查询
query = "合同中关于违约责任的条款有哪些?"
result = analyze_legal_document(query)
print(result)效果:
- 处理100+页法律文档,准确率达到95%
- 响应时间从传统RAG的30秒降至5秒
- 能够准确捕捉条款间的关系和依赖
7.2 案例二:医疗影像分析
场景:分析医疗影像和相关文本资料,辅助诊断。
挑战:
- 医疗数据包含图像、报告等多模态内容
- 需要整合不同模态的信息进行综合分析
- 诊断需要高度准确性
解决方案:
- 使用Multimodal GraphRAG处理多模态医疗数据
- 构建医疗知识图谱,连接影像和文本信息
- 利用Agentic Retrieval进行多步推理和诊断
代码示例:
from langchain.document_loaders import UnstructuredImageLoader
from langchain.document_loaders import PyPDFLoader
from langchain.vectorstores import Neo4jVector
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
# 加载医疗影像
image_loader = UnstructuredImageLoader("medical_image.jpg")
image_docs = image_loader.load()
# 加载医疗报告
report_loader = PyPDFLoader("medical_report.pdf")
report_docs = report_loader.load()
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 构建知识图谱
vectorstore = Neo4jVector.from_documents(
documents=image_docs + report_docs,
embedding=embeddings,
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# 初始化模型
model = ChatOpenAI(model="gpt-5.4", max_tokens=1000000)
# 医疗影像分析函数
def analyze_medical_data(query):
# 检索相关内容
results = vectorstore.similarity_search(
query=query,
k=3,
include_metadata=True
)
# 构建多模态上下文
context = ""
for result in results:
context += f"{result.page_content}\n"
# 生成回答
prompt = f"""
你是一位专业的医疗分析师,请基于以下医疗数据回答问题:
{context}
问题:{query}
"""
response = model.predict(prompt)
return response
# 示例查询
query = "基于影像和报告,患者可能的诊断是什么?"
result = analyze_medical_data(query)
print(result)效果:
- 整合影像和文本信息,诊断准确率提升30%
- 能够识别影像中的细微特征和文本中的关键信息
- 提供详细的诊断依据和建议
7.3 案例三:金融分析
场景:分析金融报告和市场数据,提供投资建议。
挑战:
- 金融数据量大且复杂
- 需要分析多源数据和市场趋势
- 投资决策需要准确的信息支持
解决方案:
- 使用1M+长上下文处理完整金融报告
- 构建金融知识图谱,捕捉市场和公司间关系
- 利用Agentic Retrieval进行多步分析和预测
代码示例:
from langchain.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Neo4jVector
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
# 加载金融报告
loader = PyPDFLoader("financial_report.pdf")
documents = loader.load()
# 文本分割
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=150000,
chunk_overlap=15000
)
chunks = text_splitter.split_documents(documents)
# 初始化嵌入模型
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
# 构建知识图谱
vectorstore = Neo4jVector.from_documents(
documents=chunks,
embedding=embeddings,
url="bolt://localhost:7687",
username="neo4j",
password="password"
)
# 初始化模型
model = ChatOpenAI(model="gpt-5.4", max_tokens=1000000)
# 金融分析函数
def analyze_financial_data(query):
# 检索相关内容
results = vectorstore.similarity_search(
query=query,
k=3,
include_metadata=True
)
# 构建长上下文
context = ""
for result in results:
context += f"{result.page_content}\n"
# 生成回答
prompt = f"""
你是一位专业的金融分析师,请基于以下金融数据回答问题:
{context}
问题:{query}
"""
response = model.predict(prompt)
return response
# 示例查询
query = "基于这份报告,公司未来的投资价值如何?"
result = analyze_financial_data(query)
print(result)效果:
- 处理完整金融报告,分析准确率达到90%
- 能够识别市场趋势和公司发展潜力
- 提供详细的投资建议和风险分析
8. 立即升级路径
8.1 技术栈升级
- 模型升级:使用支持长上下文的模型(GPT-5.4、Claude Opus 4.6)
- 存储升级:引入图数据库(Neo4j)和多模态存储
- 架构升级:采用微服务架构,分离多模态处理、长上下文处理和知识图谱服务
- 算法升级:实现Agentic Retrieval和Multimodal GraphRAG
8.2 实施步骤
- 评估现有系统:分析当前RAG系统的性能和局限性
- 制定升级计划:根据业务需求制定详细的升级计划
- 技术验证:在测试环境中验证新技术的效果
- 逐步迁移:分阶段迁移现有数据和功能
- 优化调优:根据实际使用情况优化系统性能
- 上线运行:部署到生产环境并监控效果
8.3 注意事项
- 成本控制:长上下文和多模态处理可能增加成本,需要合理配置
- 性能优化:确保系统响应时间满足业务需求
- 数据质量:确保输入数据的质量和一致性
- 安全性:保护敏感数据,确保合规性
- 可扩展性:设计可扩展的架构,支持未来的功能扩展
9. 成本与效果数据
9.1 成本分析
组件 | 传统RAG | Agentic RAG 3.0 | 成本变化 |
|---|---|---|---|
模型调用 | 100% | 120% | +20% |
存储成本 | 100% | 150% | +50% |
计算成本 | 100% | 80% | -20% |
人力成本 | 100% | 50% | -50% |
总成本 | 100% | 95% | -5% |
9.2 效果提升
指标 | 传统RAG | Agentic RAG 3.0 | 提升幅度 |
|---|---|---|---|
准确率 | 65% | 90% | +25% |
召回率 | 70% | 95% | +25% |
响应时间 | 10s | 3s | -70% |
用户满意度 | 75% | 95% | +20% |
业务价值 | 100% | 150% | +50% |
10. 未来发展趋势
- 更强大的长上下文能力:模型上下文长度将继续增加,支持处理更长的文档
- 更丰富的多模态支持:支持更多类型的多模态内容,如图像、视频、音频等
- 更智能的Agentic能力:Agent将具备更强的自主决策和推理能力
- 更高效的知识更新:实时知识更新和增量学习将成为标配
- 更广泛的行业应用:Agentic RAG将在更多行业得到应用,如法律、医疗、金融、教育等
- 更优化的成本结构:通过技术创新和优化,降低系统运行成本
11. 总结与建议
11.1 总结
Agentic RAG 3.0通过1M+长上下文、Multimodal GraphRAG和Agentic Retrieval三驾马车,彻底重塑了RAG技术,解决了传统RAG的诸多痛点。核心优势包括:
- 处理超长文档:支持1M+ Token长上下文,保留完整语义信息
- 支持多模态内容:处理图文视频等多模态内容,扩展应用范围
- 提高检索准确性:通过知识图谱和Agentic Retrieval,提高检索准确性和相关性
- 自主决策能力:根据任务需求自主调整检索策略,提高系统适应性
- 实时知识更新:支持实时知识更新,保持系统信息的时效性
- 降低总成本:通过优化架构和算法,降低系统运行成本
11.2 建议
- 技术选型:选择支持长上下文的模型和适合的存储方案
- 架构设计:采用微服务架构,分离不同功能模块
- 数据准备:确保数据质量和一致性,为系统提供高质量的输入
- 性能优化:根据业务需求优化系统性能,确保响应时间满足要求
- 持续迭代:根据实际使用情况持续优化系统,提升效果
- 行业应用:结合具体行业需求,定制化开发Agentic RAG系统
参考链接:
- 主要来源:GitHub - langchain-ai/langchain - 提供LangChain框架,支持Agentic RAG实现
- 辅助:GitHub - neo4j/graph-data-science - 提供知识图谱构建和查询功能
- 辅助:GitHub - openai/openai-python - 提供OpenAI API的Python客户端
附录(Appendix):
环境配置
# 安装依赖
pip install langchain openai neo4j python-dotenv
# 配置环境变量
export OPENAI_API_KEY=your-api-key
export NEO4J_URI=bolt://localhost:7687
export NEO4J_USERNAME=neo4j
export NEO4J_PASSWORD=password
# 运行示例
python agentic_rag.py常见问题处理
问题 | 原因 | 解决方案 |
|---|---|---|
长上下文处理速度慢 | 模型处理长文本需要时间 | 优化输入分块策略,使用并行处理 |
多模态内容处理失败 | 嵌入模型不支持多模态 | 使用支持多模态的嵌入模型,如CLIP |
知识图谱构建时间长 | 数据量大,处理复杂 | 优化数据处理流程,使用批量处理 |
Agent决策效果不佳 | 提示词设计不合理 | 优化Agent提示词,增加示例和约束 |
成本过高 | 模型调用和存储成本高 | 优化模型选择,使用缓存和批量处理 |
关键词: Agentic RAG 3.0, 长上下文, Multimodal GraphRAG, Agentic Retrieval, 知识图谱, 多模态处理, 企业级部署, 性能优化, 安全风信子, 技术深度, 专业价值

在这里插入图片描述
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-04-04,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号