3人干16人的活:Meta首次公开内部自主ML工程Agent架构——REA全拆解
原创
3人干16人的活:Meta首次公开内部自主ML工程Agent架构——REA全拆解
原创
CoovallyAIHub
发布于 2026-04-08 17:13:47
发布于 2026-04-08 17:13:47
导读
一个广告排序模型的改进,传统流程需要2名工程师投入数周时间。当Meta同时面对8个模型的迭代需求时,16人的工程团队似乎是唯一选项。但如果告诉你,现在3名工程师就能完成这些工作,而且模型准确度还翻了一倍呢?
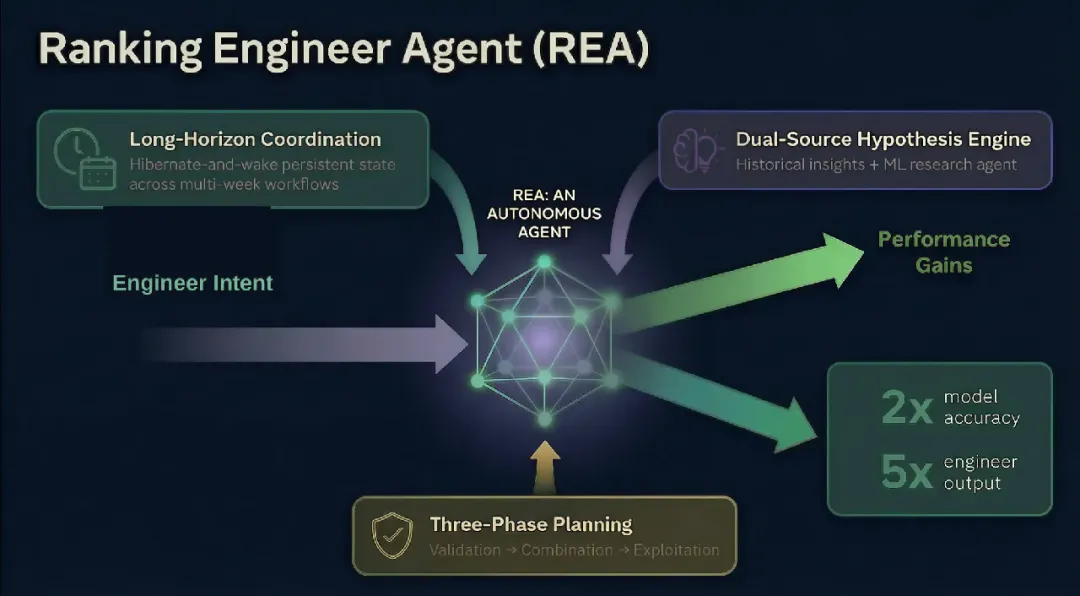
这背后是Meta内部一个名为REA(Ranking Engineer Agent)的自主AI Agent系统。2026年3月,Meta工程博客首次公开了这套系统的完整架构:Planner + Executor双组件设计、能跨天甚至跨周运行的Hibernate-and-Wake机制、融合历史实验与前沿研究的双源假设引擎,以及从验证到利用的三阶段规划框架。这是大厂少见地系统性披露内部自主ML工程Agent的设计细节。
本文将从REA要解决的工程瓶颈出发,逐层拆解其架构设计、核心机制和规划策略,帮助读者理解一个真正投入生产的ML Agent是如何工作的。
来源信息
项目 | 内容 |
|---|---|
来源 | Meta Engineering Blog |
发布时间 | 2026年3月17日 |
作者 | Ashwin Kumar, Erwin Gao, Matan Levi, Sheela Yadawad, Sherman Wong, Sneha Iyer, Vinodh Kumar Sunkara |
所属团队 | Meta DevInfra / ML Applications |
底层框架 | Confucius(Meta与Harvard合作开发的AI Agent框架) |
原文链接 | https://engineering.fb.com/2026/03/17/developer-tools/ranking-engineer-agent-rea-autonomous-ai-system-accelerating-meta-ads-ranking-innovation/ |
一、REA解决什么问题?——广告排序模型迭代的工程瓶颈
Meta的广告系统服务于Facebook、Instagram、Messenger、WhatsApp上的数十亿用户,底层依赖高度复杂的大规模分布式ML模型。这些模型需要持续迭代优化,而传统的ML实验流程是这样的:工程师提出假设、设计实验、启动训练、跨复杂代码库调试故障、分析结果、再迭代。每个完整周期可能需要数天到数周。
更关键的问题是:随着Meta的模型经过多年成熟演化,找到有意义的改进变得越来越困难。改进空间在缩小,但业务对模型精度的要求在持续提高。
传统的ML辅助工具本质上是反应式、任务级、会话绑定的(reactive, task-scoped, session-bound)。它们可以帮忙完成单个步骤——起草假设、编写配置文件、解释日志——但无法端到端地运行一轮完整实验,更无法自主协调跨多天的工作流。
REA要解决的正是这个瓶颈。博文将其定位为:一个自主Agent,能以最少的人类干预,跨多天工作流协调和推进ML实验。
具体来说,REA面对三大核心挑战:
- 长时程异步工作流自主性:ML训练任务运行数小时甚至数天,远超任何会话式助手的能力范围
- 高质量多样化假设生成:实验质量取决于假设质量,需要综合历史经验和前沿研究
- 真实约束下的韧性运行:基础设施故障、意外错误、计算预算限制不应中断Agent的自主运行
从首次生产验证的结果来看,REA的效果相当显著:
指标 | 数据 | 说明 |
|---|---|---|
模型准确度 | 2x(翻倍) | 横跨6个模型,对比基线方法的平均准确度翻倍 |
工程效率 | 5x | 3名工程师完成8个模型的改进提案,传统模式需16人 |
改进提案数 | 1个 → 5个 | 同等时间内,使用REA的工程师提案数量增至5倍 |
时间压缩 | 数周 → 数天 | 复杂架构改进的完成周期大幅缩短 |
图片来源于原文
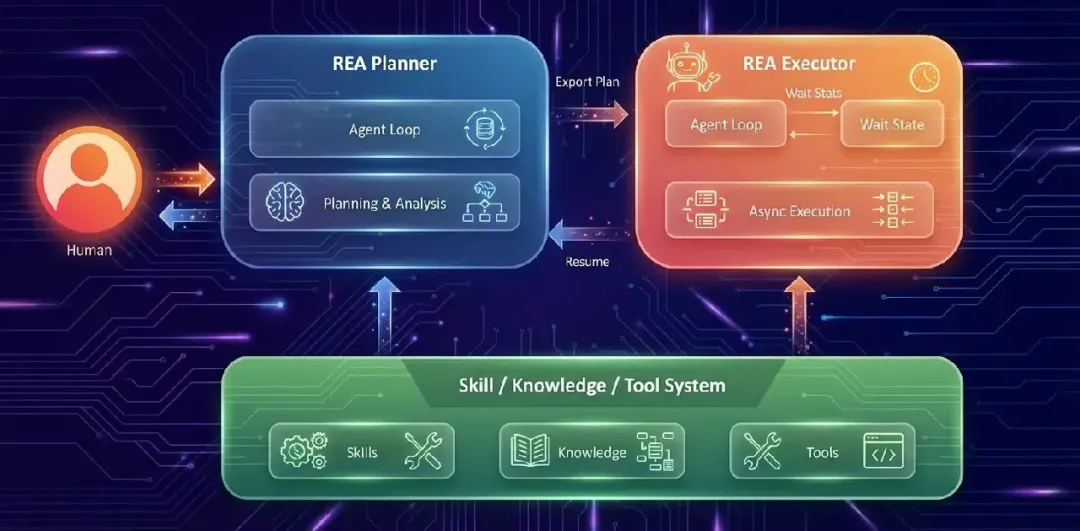
二、Planner + Executor双组件架构
REA的系统架构由两个核心组件和一套共享支撑系统构成。
REA Planner(规划器)
Planner负责实验的规划阶段。它与假设生成器(Hypothesis Generator)协作,生成详细的实验计划。具体工作流程:
- 工程师与假设生成器协作,创建详细的实验计划
- Planner提出探索策略
- 估算总GPU计算成本
- 与工程师确认方案后,将计划导出给Executor执行
值得注意的是,工程师在规划阶段深度参与。Planner不是完全自主地制定计划,而是与人协作完成方向把控和资源确认——这是"战略决策由人做"理念的体现。
REA Executor(执行器)
Executor负责实验的执行、监控和迭代。它管理异步任务执行,通过Agent Loop和Wait State管理整个工作流:
- 接收来自Planner的实验计划
- 启动训练任务
- 进入休眠状态(释放计算资源)
- 训练完成后自动恢复
- 分析结果
- 遇到故障时自主调试
- 将结果反馈给Planner
共享Skill, Knowledge & Tool系统
两个组件共享一套底层支撑系统,提供三类能力:
- ML能力(ML Capabilities):机器学习相关的技能集
- 历史实验数据(Historical Experiment Data):过去的实验记录和洞察
- Meta内部基础设施集成:连接任务调度器、实验跟踪基础设施、代码库导航工具等内部工具链
这套共享系统构建在Meta内部的Confucius框架之上。Confucius是Meta与Harvard合作开发的AI Agent框架,专为复杂多步推理任务设计,提供强代码生成能力和灵活的SDK来集成Meta内部工具系统。
图片来源于原文
三、Hibernate-and-Wake:跨天异步工作流的关键机制
如果说双组件架构定义了REA"做什么",那么Hibernate-and-Wake机制则解决了"怎么跨天做"的问题。这是REA区别于所有传统AI助手的核心设计。
为什么需要这个机制?
ML训练任务的运行时间通常以小时甚至天计。传统AI助手是会话绑定的:一次会话结束,状态就丢失了。如果一个训练任务需要跑8小时,没有任何会话式工具能在这期间保持上下文、等待结果、然后继续下一步操作。
工作原理
REA的做法是:当Agent启动训练任务后,它将等待委托给一个后台系统,关闭自身以节省资源,训练完成后自动恢复到上次离开的位置继续工作。
详细流程如下:
- REA启动一个训练任务
- 序列化当前工作流状态(将所有上下文信息持久化存储)
- 关闭自身,释放计算资源(hibernate)
- 后台系统监听训练任务状态
- 训练任务完成后,后台系统触发回调
- REA从序列化状态恢复(wake),继续后续工作流
技术特征
这一机制有几个关键特征:
- 多实例并行:多个REA实例可以同时运行,等待期间不消耗活跃计算资源
- 跨周运行:支持跨数天乃至数周的连续工作流
- 无需持续监控:工程师提供周期性监督而非实时盯守
与传统AI助手的根本区别
维度 | 传统AI助手 | REA |
|---|---|---|
运行模式 | 会话绑定,响应后等待下一个查询 | 长时程自主运行,跨天/周级工作流 |
状态管理 | 会话结束即失去上下文 | 序列化状态,支持持久记忆 |
等待策略 | 无法处理长时间等待 | 休眠释放资源,完成后自动恢复 |
人类参与 | 每一步都需要人类触发 | 战略节点介入,迭代过程自主完成 |
这意味着REA的工作方式更接近一个异步工作的同事,而不是一个即时响应的工具——它可以在你下班后继续跑实验,第二天早上把结果准备好。
四、双源假设引擎与三阶段规划
实验质量取决于假设质量。REA在假设生成上采用了双源策略,在实验规划上采用了三阶段框架,两者共同确保实验既有深度又有效率。
双源假设引擎
REA的假设来自两个互补的来源:
来源一:历史洞察数据库(Historical Insights Database)
这是一个精选的过去实验存储库,支持上下文学习(in-context learning)和模式识别。它涵盖历史上的成功和失败经验,让Agent能够识别哪些方向值得尝试、哪些坑已经踩过。
来源二:ML研究Agent(ML Research Agent)
这是一个深度研究组件,负责调查当前基线模型的配置,并参考ML领域的前沿研究,提出新的优化策略。它不是简单地套用已知方法,而是主动探索潜在的改进方向。
两个来源的协同效应是REA产出高质量假设的关键。博文指出,REA最有影响力的改进来自架构优化与训练效率技术的组合——这种跨领域的交叉配置,正是双源方法论使Agent能发现而单一来源难以产生的。
知识闭环
值得单独说明的是REA的知识积累机制:Executor完成每轮实验后,专用实验记录器(Experiment Logger)会记录结果、关键指标和配置,存入集中式假设实验洞察数据库。假设生成器在后续轮次中利用这些洞察识别模式、学习成败经验,提出越来越复杂的假设。
用博文原文的表述:"这种持久记忆跨越Agent运行的全部历史积累知识,形成闭环并随时间复合系统的智能。"
这意味着REA不只是一个执行工具,而是一个能越用越聪明的学习系统。
三阶段规划框架
在执行实验前,REA会提出详细的探索策略、估算总GPU计算成本,并与工程师确认方案。具体的实验推进分为三个阶段:
阶段 | 名称 | 策略 |
|---|---|---|
Phase 1 | Validation(验证) | 来自不同来源的独立假设并行测试,建立质量基线,早期过滤弱假设 |
Phase 2 | Combination(组合) | 将有前景的假设组合起来,搜索协同改进效果 |
Phase 3 | Exploitation(利用) | 对最有前景的候选方案进行密集优化,在批准的计算预算内最大化结果 |
这个三阶段框架本质上是一个漏斗式的实验策略:先广撒网建立基线(验证),再交叉组合找协同效应(组合),最后集中资源冲刺最佳方案(利用)。每个阶段都有明确的目标和淘汰机制,避免了盲目消耗GPU资源。
安全与人类监督
REA的安全设计也值得关注:
- 限定范围:仅限于Meta广告排序模型代码库
- 预检清单:工程师通过preflight checklist审查授予访问权限
- 计算预算控制:预先确认GPU预算,达到阈值时自动暂停
- 故障韧性:参考runbook处理常见故障模式,能自主排除OOM错误、检测训练不稳定信号(如loss explosion),并从第一性原理调试基础设施故障
五、总结与思考
REA的核心价值可以用三个层次概括:效率层面,3人完成16人的工作量,模型准确度翻倍;架构层面,Planner + Executor分离、Hibernate-and-Wake跨天运行、双源假设引擎形成知识闭环,这些设计共同回答了"如何让Agent自主驱动需要数天才能完成的ML实验"这个工程问题;范式层面,工程师的角色从亲自执行实验转向战略监督、假设方向把控和架构决策,Agent处理迭代机制,人类做战略判断和最终审批。
在此基础上,有几点值得进一步关注。一是Hibernate-and-Wake机制的通用性——ML实验只是长时程异步任务的一种,任何需要"启动任务→等待数小时→分析结果→迭代"的工程场景,理论上都可以借鉴这一设计。二是知识闭环的复合效应——REA每一轮实验都在积累洞察,这意味着它的价值会随使用时间增长。三是Meta选择公开这些设计细节本身就是一个信号:当Agent从辅助工具演进为自主系统,其工程架构的复杂度已经值得作为独立的技术贡献来讨论。博文也预告了后续将披露更多REA的能力细节,值得持续关注。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号