实测两款预测型大模型:Echo 押对了交易,MiroThinker 提前15天算准金价走势

实测两款预测型大模型:Echo 押对了交易,MiroThinker 提前15天算准金价走势

技术人生黄勇
发布于 2026-04-09 10:43:56
发布于 2026-04-09 10:43:56
一个提前15天预测黄金价格,误差仅0.08%。
另一个在全球预测排行榜上,以 Elo 1034.2 分碾压 GPT-5.2、Claude-4.6-Opus,拿下第一。
大模型正在从「帮你写」,进化到「帮你判断」。
Echo:「面向未来训练」 的大模型
Echo 是 UniPat AI 和北京大学联合推出的预测大模型——一个全栈预测智能系统。它的核心能力不是生成文本,也不是画图写代码,而是: 预测未来。 不是占卜,不是猜测,而是基于证据、推理、概率分布,给出结构化的预测报告。 更反常识的是它的训练方式——「在未来的数据上训练」。
Echo 的三大支柱
Echo 不是单一模型,而是一个完整的预测系统,围绕核心模型 EchoZ-1.0 构建,包含三大组件:
1. General AI Prediction Leaderboard(通用AI预测排行榜)
这是一个动态评估引擎,用来评估模型的预测能力。
为什么要单独做一个排行榜?
现有的预测基准有两个致命缺陷:
- • 时间不对称性:
- 临近事件解决时,信息更丰富,早期预测更难。
- 一个在事件发生前 7 天预测的模型,和一个在事件发生前 1 天预测的模型,难度完全不同。直接比较它们的准确率是不公平的。
- • 问题来源单一:
- 现有基准过度依赖预测市场(如 Polymarket),忽视了专业领域(科学、工程、医学)和新兴话题。
Leaderboard 如何解决?
它采用了一个「多时点对齐的 Elo 框架」:
- • 只在同一问题、同一预测时点比较模型
- • 使用 Brier Score(布赖尔分数)评估预测质量
- • 通过 Bradley-Terry 模型和最大似然估计计算 Elo 评分
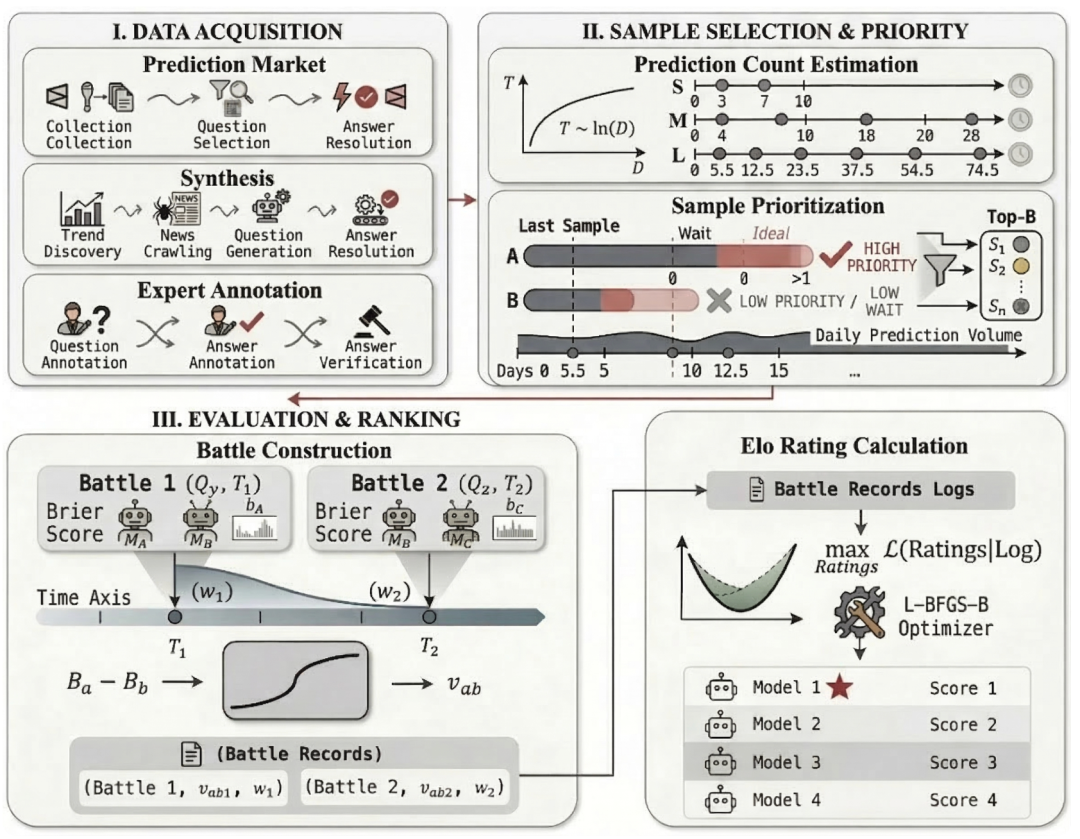
Leaderboard 构建了一个三阶段流程,以实现公平且可扩展的预测评估。
首先,它从三个互补的数据源获取问题,以确保覆盖面广。
其次,它在每个问题的生命周期内安排预测样本的优先级。
最后,评估过程被设计成两两对决,并采用全局 Elo 式优化算法生成最终排行榜。
该算法强调稳健性、可靠性、速度、多样性和灵活性。
评估指标的优势:
指标 | 表现 |
|---|---|
鲁棒性 | 在缺失预测时点下,Elo 排名波动比平均 Brier Score 低 1.4–1.8 倍 |
可靠性 | 移除部分模型后,排名一致性高达 0.978–0.994 |
快速收敛 | 新模型加入后,Elo 排名在 5.4 天收敛,比平均 Brier 快 2.7 倍 |
多样性 | 覆盖政治、经济、体育、加密货币等 7 大领域 |
灵活性 | 支持自由提交预测,无需固定时间表 |
数据从哪里来?
Leaderboard 从三个来源采集数据:
- 1. 预测市场:如 Polymarket
- 2. 趋势合成:基于 Google Trends 和网络爬虫
- 3. 专家标注:科学、工程、医学等领域的专业问题
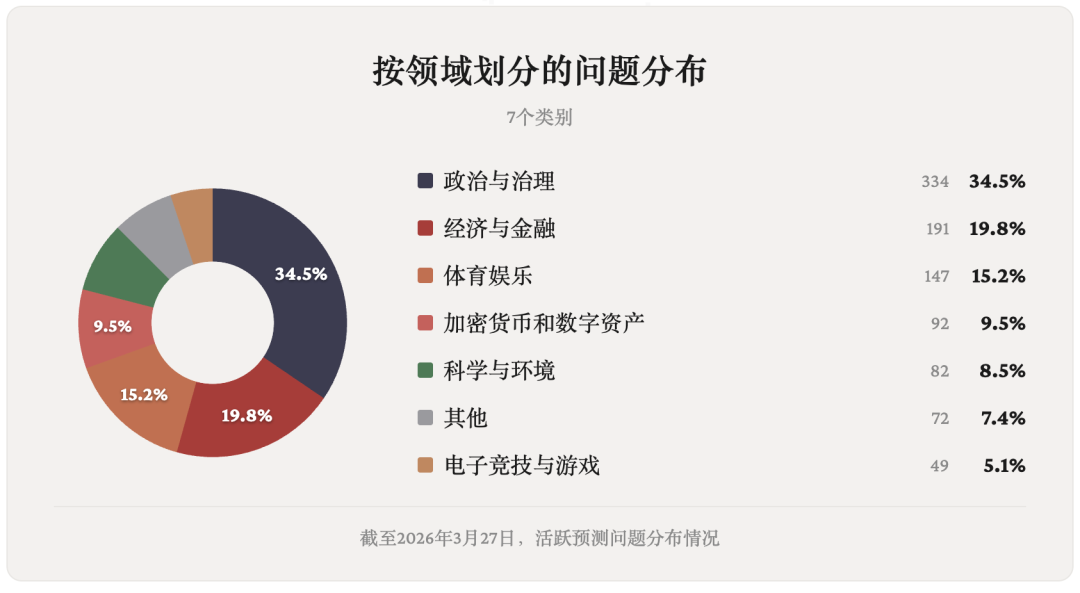
Echo 的题库涵盖 7 个领域:
政治与治理、经济与金融、体育与娱乐、科学与环境、加密货币与数字资产、电子竞技与游戏以及其他。
每天都会添加新问题,以确保基准测试能够持续涵盖正在发生的现实世界事件。
各领域的分布情况如下:
如何调度预测?
它采用一个「两阶段预测调度算法」:
- • Phase 1:根据问题生命周期,按对数函数估算预测点数(Ti = round(1.35·ln(Di) + 0.5))
- • Phase 2:基于优先级分数(Si = Wi·Ri/Di')选择每日预测问题
2. Train-on-Future(面向未来上训练)
这是 Echo 的核心创新。
传统模型的训练方式是 Train-on-Past——在历史数据上训练,让模型学习过去的模式。
但预测任务有个特殊情况:历史数据里藏着答案。
Train-on-Past 的两个缺陷:
- • 工程悖论:无法完全屏蔽历史答案泄露。模型可能「偷看」到了结果,而不是学会了推理。
- • 结果导向偏差:模型容易过拟合噪声事件,学会了「事后诸葛亮」,而不是前瞻推理。
Train-on-Future 如何解决?
它采用三大机制:
机制一:动态问题合成
基于实时数据流生成未来事件问题,避免数据泄露。
问题不是从历史数据库里提取的,而是从实时数据流中合成的。这些问题在未来才会解决,所以模型无法「偷看」答案。
机制二:规则搜索(Rubrics Search)
为每个领域搜索最佳评分规则,使模型排名与真实 Elo 排名一致。
预测轨迹会按多个维度评分,比如:
- • 解析解决标准
- • 区分修辞与执行
- • 主要机构来源验证
- • 程序约束评估
这些维度不是人工设计的,而是通过 Spearman's ρ 最大化 自动搜索出来的——让规则排名与 Elo 排名一致。
机制三:Map-Reduce 智能体架构
基于 ReAct(Reasoning-Acting)框架,模型通过多步推理生成预测:
- • Map 阶段:将宏观问题分解为子任务,并行收集信息
- • Reduce 阶段:聚合多源信息,输出合成概率决策
这就像一个研究团队:有人负责收集数据,有人负责分析,最后汇总形成结论。
3. AI-native Prediction API(AI原生预测接口)
这是 Echo 的应用层。
输入一个结构化的预测问题,返回完整的分析报告,包括:
- • 概率分布:不是单一答案,而是候选答案的概率分布
- • 证据库:支持结论的证据来源
- • 反事实脆弱性评估:什么情况下预测会逆转
- • 监控建议:应该关注哪些时间节点
示例输出(摘要):
领域 | 预测问题 | 结论 | 概率 |
|---|---|---|---|
金融 | NVIDIA 在 2026年3月31日是否为全球最大市值公司 | 是 | 0.98 |
政治 | 伊利诺伊州共和党初选胜者 | Darren Bailey | 0.999 |
加密货币 | ETH 是否在3月31日前创历史新高 | 否 | 0.99 |
体育 | NBA 西部第一种子 | Oklahoma City Thunder | 0.899 |
电子游戏 | GTA VI 新预告片是否在3月发布 | 否 | 0.96 |
报告质量特征:
- • 证据粒度:每份报告包含 4–6 条分类证据
- • 概率严谨性:基于数学约束和市场共识
- • 反事实完整性:明确逆转场景
- • 可操作监控:具体时间戳监控项
Echo 的性能如何?
参数敏感性测试:
Elo 排名在 σ∈[0.01, 0.50] 范围内稳定,EchoZ 始终排名第一。
胜率对比人类市场:

在政治领域、长期预测、市场不确定场景下,Echo 都超越了人类市场预测。
在 Echo 的官网上展示了它对未来一些问题的预测,有兴趣的可以去验证:
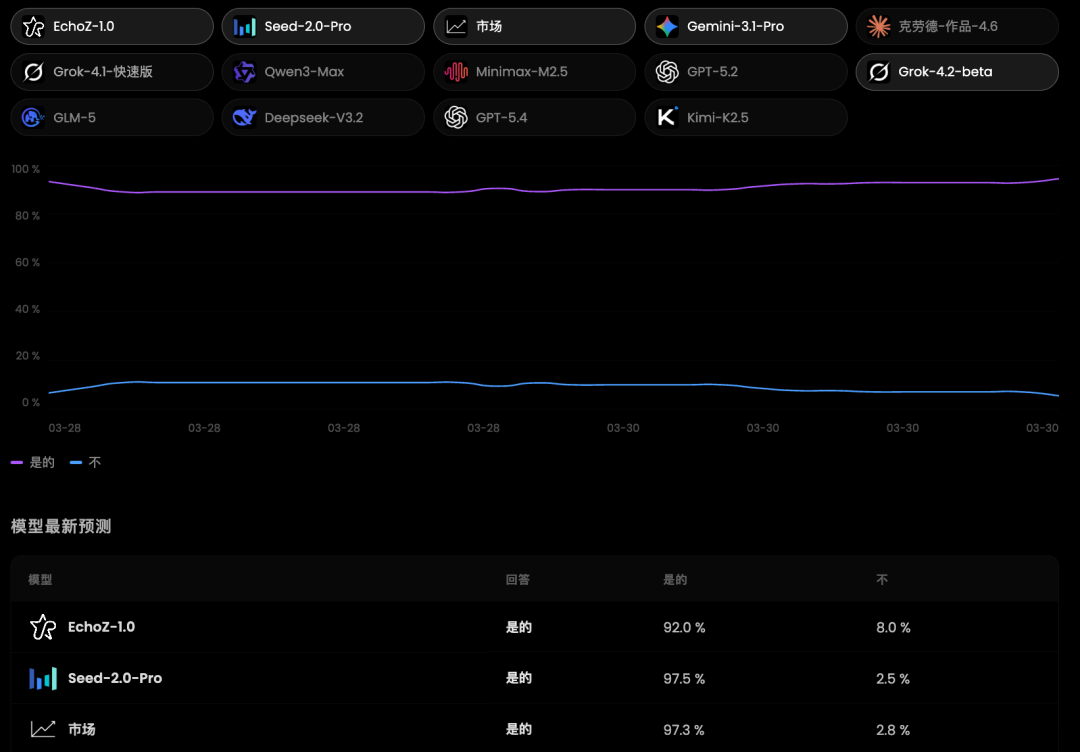
像上图中的第二个问题:
2026年4月1日美国东部时间中午12点,比特币的价格会超过6万美元吗?
总结:Echo
Echo 不是单一的技术突破,而是三层能力的整合:
- 1. 评估层:General AI Prediction Leaderboard 解决了预测评估的时间不对称性和来源单一性。
- 2. 训练层:Train-on-Future 范式避免了历史答案泄露和结果导向偏差。
- 3. 应用层:AI-native Prediction API 提供了结构化、可解释的预测报告。
它提出了一个新的研究方向:
大模型的价值不只是生成内容,而是推理未来。
预测的核心不是信息量,而是推理过程的严谨性。
证据从哪里来?如何权衡?概率如何计算?在什么情况下会逆转?
Echo 的解法是:
用未来的数据训练,用推理的过程预测,用结构化的报告交付。
下面我们来看另外一个预测未来的大模型。
MiroThinker 不追求速度,追求可验证
MiroThinker 是陈天桥投资的 MiroMind 团队推出的推理大模型,最新版本为 MiroThinker-1.7 和 MiroThinker-H1。
MiroThinker-1.7 系列发布即霸榜多项深度研究任务测试。
MiroThinker-H1 刷新 SOTA,超越 Gemini-3.1-Pro、GPT-5.4-Thinking、Claude-4.6-Opus 等一众行业顶尖闭源模型:
- BrowseComp(网页检索类大模型基准测试):88.2%
- BrowseComp-ZH(BrowseComp 的中文适配版本):84.4%
- GAIA-Val-165(GAIA 基准测试验证集):88.5%
- HLE-Text(人类终极测试):47.7%
另外开源模型 MiroThinker-1.7(235B)和小尺寸的 MiroThinker-1.7-mini(30B)也在效率与性能之间达到了最优平衡。
新模型不仅通用任务强,在科技金融等专业领域同样表现亮眼。
它跳出了传统 LLM 聊天交互的范畴,转而能够承担起真实的长链条智力任务。
而这是以牺牲模型推理速度为代价的。
当其它大模型厂商都在卷速度,MiroThinker 系列专为复杂长期任务而生,结果 V1.5 大获全胜、V1.7 再度突破。
下面介绍它的战绩。
预测赛车结果、黄金价格
F1 上海站正赛预测
众所周知,受赛车性能、车手状态、环境因素影响,F1 比赛结果预测难度相当之高。
这就非常考验模型实时抓取信息、综合判断多方面因素的能力。
测试团队在比赛前 2 小时、比赛中 1 小时、比赛最后半小时三个关键时间节点,分别让 MiroThinker 实时预测排名情况,并与真实结果进行比对。
赛前 2 小时:
在即将举办的 F1 上海站上,对选手排名进行预测。
预测结果如何暂且不提,光论推理过程和答案的详实程度,就已经遥遥领先。
仔细看模型思考过程,MiroThinker 建立起一条极为完整的信息搜索路径,包括比赛策略、车队实力情况、潜在变数等:
确认正赛时间和地点 → 收集最新的上海站排位赛、冲刺赛以及当前赛季情况辅助 → 从规则变化到天气情况逐步细化 → 汇总给出合理预测。
其中每一步都在反复验证,以确保后续推理的可靠性。
至于最终给出的赛前预测也很全面,先是直接甩出核心结论一目了然,预测梅赛德斯大获全胜、法拉利紧随、迈凯伦和红牛位列第二梯队。
然后给出简要的预测逻辑以及观赛建议,用户体验感拉满。
值得一提的是,MiroThinker 还支持一键生成网页报告。就这排版这审美,妥妥的打工人福音。
测试团队也将该问题同时交给 ChatGPT、Gemini 和 DeepSeek 进行预测:
ChatGPT:回答相对简略,对影响变量和预测理由描述较少。
Gemini:亮点是除了列举选手排名,还提供赛事核心看点,但在整个答案的完整度上还是 MiroThinker 占优。
DeepSeek:预测结果只关注到了选手历史成绩和车辆情况,考虑得不够深入。
反观 MiroThinker,它是所有模型中,唯一关注到当前天气状况的推理大模型,足以证明其专业度。
提前 15 天预测黄金价格
2026 年 2 月 25 日,测试团队问 MiroThinker:2026 年 2 月 25 日的黄金价格(XAU/USD)会是多少?
模型当时预测金价是 5185/oz,实际 Fortune 报价 5181,150 Currency 报价 5185.89,CME GCG26 收盘价为 5206.40,误差仅为 0.08%(
综合来看,无论是短期的通用场景预测,还是中长期的专业场景预估,MiroThinker 都能做到有理有据,实际结果与模型预测高度吻合,且思考过程全部清晰可见。
虽然它还没有做到像其它模型一样秒出答案,需要一到两分钟的等待时间,但在答案完整度和逻辑链上已经是不在一个层级,足以应对绝大多数真实推理任务。
并非简单做加法,而是精准 Scaling
为什么 MiroThinker 能够做到这一点?
还要说回模型的核心技术突破——重型求解器(heavy-duty solver)。
当前行业内要提升推理深度,普遍采用的方案是通过强化学习将模型 CoT 运算时间延长,这类优化后的模型在数学、编程等领域表现突出。
而 MiroThinker-1.7 不仅仅是延长思考时间,更是强调模型的可验证性和有效交互。具体表现在两项关键技术升级上:
① 升级智能体原生训练
MiroMind 注意到一个现象,如果模型每一步决策本身就质量不高,即使让模型完成更多轮的交互,最终结果也只是在放大低质量决策。
所以提升推理性能的关键不是交互次数的叠加,而是专注增强每一步的质量,也就是提升模型的智能体原生能力(agent-native competence),包括三步:
规划更可靠: 一开始就把问题拆对、把路选对。
推理更准确:每一步判断都经得起验证和反思。
长程不走偏:在复杂任务中始终对齐最终目标。
为此,MiroThinker-1.7 在训练过程中新增了一个 mid-training(中期训练)阶段。
借助大规模的高质量任务数据,重点训练模型的规划、推理和总结能力,使其建立起更强的 Agent 基础能力。
比如目标分解、选择合适的工具调用、理解工具返回结果、整合生成最终答案。
同时该阶段也扩大了模型的通用性。
在此基础之上,还会加入 SFT(监督微调)、DPO(偏好优化)、RL(强化学习)进一步将 Agent 能力内化,实现长时任务稳定推理。
② 以验证为核心的重型推理模式
然而,要提升单步推理质量,也不能仅仅依靠模型自身的 Agent 推理能力,还需要引入验证器加以约束,可分为局部验证和全局验证:
局部验证:
在推理的每一步,系统都会停下来自我审查。
只有通过了局部验证,系统才会允许继续探索该条路径。
在一定程度上,局部验证能够打破传统 AI 的概率偏置,找到也许当下瞬时概率较低但实则最正确的路径。
全局验证:
在系统生成了几条完整的推理路径后,模型会回溯整条数据链,确保最终答案是推理环节最严密的,而不是语义最流畅、看似逻辑自洽的。
总的来说,前者显著增强智能体原生能力,后者提升交叉验证可信度,二者深度融合,让模型在面对复杂推理问题时能够表现出精准可验证的交互潜力。
一个反直觉现象
另外值得关注的是,MiroMind 还观察到一个「反直觉」现象:在引入验证机制后,模型交互步骤数量明显减少。
按照常规逻辑,往往步数越多、思考越久,模型性能就越强,即 Heavy-duty(重型)。
而该现象则说明验证器在这里充当的还有过滤器的作用,能够帮助模型及时筛除掉没有信息增益的步骤,将算力集中分配到真正推动问题求解的环节上。
虽然总步数减少了,但每一步包含的逻辑推理质量更高了,整个推理过程变得高效且精密。这就引出了 MiroThinker 系列模型的核心理念——扩展有效交互。
抓住交互关键,「慢」也能弯道超车
从 V1.5 到 V1.7,模型的每一次迭代都能产生行之有效的结果,这未尝不是对 MiroThinker 交互理念的有力验证。简单来说,MiroThinker 强调慢下来、想更多。
虽然通过增加对话次数、工具调用,能够非常直观迅速地刷新基准测试分数,但一旦中间步骤错误,错误就会像滚雪球一样累积,直至系统彻底崩溃。
而「慢」推理不追求秒回,而是在行动前暂停、验证、权衡,确保在当前复杂场景下推得深、推得对。
这种看似不讨巧的选择,反而成就了 MiroThinker 在大模型市场中独树一帜的风格——不急于给出答案,而是专注求证问题背后的深层逻辑。
在算力约束与复杂任务的博弈中,MiroThinker 没有盲目堆砌算力,而是更像一位深谙最优路径的理科生,精打细算将算力落在该去的地方。
结果也很显而易见,只要踏实做好有效交互,慢也不等同于落后,反倒是助力 LLM 走向真实物理世界更扎实。
所以我去测试了一个问题:
美以伊战争会如何走向,它对全球的经济、黄金、A股会有什么影响?
经过它的搜索资料,推理,再搜集资料,再推理,总结如下:

你可以点击这个地址查看最终推理的结果:
https://dr.miromind.ai/report/share/eOHyjeG4tTkAL6Dj
这两款模型目前都已经对外开放:
- Echo,提供预测问题和排行榜,提供API,没有对话框。
- https://echo.unipat.ai
- MiroThinker:提供对话式推理,可以提问预测。
- https://dr.miromind.ai,
它们不是水晶球,预测结果不能作为投资建议。
它们提供了一种新的决策辅助方式:给你一个完整的推理过程和证据链。
预测的核心不是信息量,是推理过程的严谨性。
如果有希望大模型能预测,你希望问什么问题?
欢迎评论区留言。
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-31,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号