「AI开源组件安全风险」系列二:VulnAgent发现 NVIDIA 3个AI基础设施漏洞,并获官方致谢

「AI开源组件安全风险」系列二:VulnAgent发现 NVIDIA 3个AI基础设施漏洞,并获官方致谢

云鼎实验室
修改于 2026-04-09 14:51:49
修改于 2026-04-09 14:51:49
一、 引言:当AI基础设施成为攻击目标
随着大语言模型(LLM)的爆发式发展,AI 训练和推理框架已成为支撑整个行业的关键基础设施。NVIDIA Megatron-LM 作为分布式训练框架的翘楚,在 GitHub 上斩获超过15K Stars,被广泛应用于 GPT、DeepSeek、GLM 等主流大模型的训练过程。而 NVIDIA Model Optimizer 则是模型部署优化的核心工具,负责将训练好的模型量化压缩,适配TensorRT-LLM、vLLM 等推理引擎。
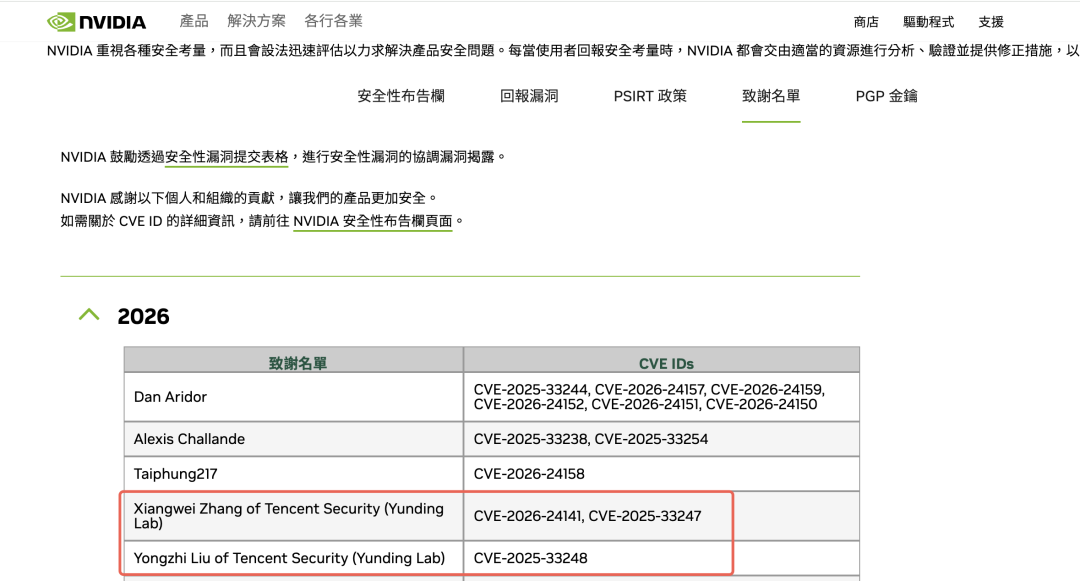
而近年来,Megatron-LM、vLLM、Model Optimizer等主流框架频繁披露安全漏洞,这些被视为"AI时代操作系统"的基础设施,其安全水位可能偏低,暴露了模型加载、推理服务等关键环节的安全缺陷。一旦这些漏洞被攻击者利用,其背后价值数亿美元的高性能算力资源将面临劫持风险,核心模型资产亦可能遭到窃取。腾讯安全云鼎实验室借助自研漏洞挖掘智能体VulnAgent,对这些主流AI框架进行深度安全审计,连续发现三个高危反序列化漏洞:CVE-2025-33248、CVE-2025-33247(Megatron-LM)以及 CVE-2026-24141(Model Optimizer),均获得 NVIDIA 官方致谢。
本文将以这三个漏洞为切入点,重点分析AI基础设施中因反序列化导致的安全漏洞,剖析AI基础设施面临的系统性安全风险。
二、 反序列化漏洞:AI框架中普遍存在的安全问题
2.1 什么是反序列化漏洞?
反序列化漏洞是 Python 生态中最为危险的漏洞类型之一。当程序使用 pickle、torch.load()、numpy.load()等函数加载数据时,如果数据源被攻击者控制,便可触发任意代码执行。
在AI训练场景中,模型文件、数据集文件、量化校准数据等都需要频繁序列化/反序列化,这为攻击者提供了大量的攻击面。
2.2 为何AI框架频发此类漏洞?
可能原因:
1. 功能优先导向:AI 框架设计历史上优先考虑训练效率,安全功能滞后。PyTorch 在 2025 年发布的 2.6 版本才默认启用 weights_only=True,此前近9年(2016-2025)允许加载任意对象
2. 生态依赖复杂:PyTorch 2.6 之前版本、 NumPy 1.16.3 之前版本、Yaml 5.3.1 之前版本及 Pickle 等底层库默认允许反序列化任意对象,缺乏安全边界
3. 使用场景特殊:模型文件体积庞大(GB级别),安全校验成本高,开发者习惯直接加载,缺乏校验机制
2.3 典型案例
以下是近年来AI基础设施中已公开的反序列化相关漏洞:
组件 | 漏洞编号 | 核心问题 |
|---|---|---|
PyTorch | CVE-2024-48063 | 分布式RPC框架中 RemoteModule 反序列化未校验输入,可远程执行任意命令 |
Keras | CVE-2024-3660 | 加载恶意模型文件时,通过 Lambda 层注入并执行任意代码,绕过 safe_mode 防护 |
Megatron-LM | CVE-2025-23354 | ensemble_classifier 脚本允许攻击者篡改输入并执行任意代码 |
MLflow | CVE-2024-37052 ~ 37060 | 模型存储、实验追踪等多个模块存在 pickle 反序列化漏洞,共计9个高危CVE |
vLLM | CVE-2025-62164 | Completions API 中通过恶意嵌入向量触发 torch.load() 反序列化,导致远程代码执行 |
可以看到,不安全的反序列化问题贯穿了从底层框架(PyTorch、Keras)到训练框架(Megatron-LM)、模型管理(MLflow)及推理服务(vLLM)的整个AI技术栈。而本文发现的三个NVIDIA CVE进一步印证了这一趋势。
三、 漏洞详解:从不安全反序列化到任意代码执行
⚠️ 重要说明:本文涉及的漏洞均已通过 CNVD 和 NVDB 提交,并获得 NVIDIA 官方确认,官方已发布修复方案。请相关用户及时更新至最新版本以修复相关漏洞,避免因版本滞后导致运行环境暴露于安全风险之中。
3.1 Megatron-LM 反序列化漏洞
CVE-2025-33248
漏洞原理
Megatron-LM的hybrid_conversion.py 模块用于处理混合 Mamba-Transformer 架构模型在不同并行配置间的转换。这是 Megatron-LM 支持新兴架构的关键组件,直接影响模型的灵活部署能力。漏洞产生的根本原因:在加载模型文件时直接调用 torch.load(),未设置 weights_only=True 参数:
# get the latest iteration
tracker_filename = os.path.join(args.load_dir,'latest_checkpointed_iteration.txt')
withopen(tracker_filename,'r')as f:
metastring = f.read().strip()
try:
iteration =int(metastring)
except ValueError:
raise Exception("Invalid iteration found in latest_checkpointed_iteration.txt!")
out_iteration = iteration ifnot args.reset_iterations else0
# get model directory and model parallel ranks
input_model_dir = os.path.join(args.load_dir,'iter_{:07d}'.format(iteration))
input_sub_models = os.listdir(input_model_dir)
# load one of the model parallel ranks to get arguments
sample_model_file = os.path.join(input_model_dir, input_sub_models[0],"model_optim_rng.pt")
# 危险:直接执行恶意代码
sample_model = torch.load(sample_model_file)# 默认 weights_only=False
在 PyTorch 2.6 之前,torch.load()的默认行为允许加载任意 Python 对象,攻击者可借此执行任意代码。这意味着,一旦用户加载恶意 checkpoint 文件,攻击者精心编造的任意代码就会在目标机器上执行。
官方修复方案
CVE-2025-33248 漏洞披露后,Megatron-LM官方修复方案是强制设置 torch 版本为2.6+,从而保证 torch.load() 的参数 weights_only 默认为 True。
dependencies = ["torch>=2.6.0", "numpy", "packaging>=24.2"]
CVE-2025-33247
漏洞原理
Megatron-LM的pretrain_gpt.py 模块用于 GPT 模型预训练和 SFT(监督微调)。漏洞产生的根本原因:在于其量化配置(Quantization Recipe)加载流程中直接调用yaml.load(Loader=yaml.FullLoader), 而非使用yaml.SafeLoader。
def from_yaml_file(recipe_yaml_path:str)->"RecipeConfig":
"""Loads recipe from yaml configuration."""
ifnot HAVE_YAML:
raise ImportError("yaml is not installed. Please install it with `pip install pyyaml`.")
withopen(recipe_yaml_path,"r")as f:
# 危险:直接执行恶意代码
config = yaml.load(f, Loader=yaml.FullLoader)#
return RecipeConfig.from_config_dict(config)
yaml.FullLoader 支持 Python 对象构造标签,攻击者构造恶意 YAML 文件即可在加载时执行任意代码。这意味着,一旦用户加载恶意 YAML 文件,攻击者精心编造的任意代码就会在目标机器上执行。
官方修复方案
CVE-2025-33247 漏洞披露后,Megatron-LM 官方修复方案是强制设置 yaml.load() 的参数 Loader 为 SafeLoader。
withopen(recipe_yaml_path,"r")as f:
config = yaml.load(f, Loader=yaml.SafeLoader)
3.2 Model Optimizer 反序列化漏洞(CVE-2026-24141)
漏洞原理
Model Optimizer 的 ONNX 量化模块(modelopt.onnx.quantization)是模型部署前压缩的关键步骤,用于将 FP32 模型量化为 INT8,大幅降低推理成本。漏洞产生的根本原因:在加载量化校准数据时,使用了numpy.load(allow_pickle=True):
# 不安全的实现
calibration_data = np.load(args.calibration_data_path, allow_pickle=True)
NumPy的allow_pickle参数在True时,可加载包含任意Python对象的.npy文件,与pickle模块存在相同的安全风险。这意味着,一旦用户加载恶意文件,攻击者精心编造的任意代码就会在目标机器上执行。
官方修复方案
CVE-2026-24141漏洞披露后,Model Optimizer官方修复方案是在加载量化校准数据时采用用户的输入参数trust_calibration_data,默认值False:
calibration_data = np.load(
args.calibration_data_path, allow_pickle=args.trust_calibration_data
)
四、 AI基础设施面临的三重风险
4.1 算力资产劫持风险
算力即金钱。现代 GPU 集群的算力价值远超传统服务器:
- 单卡价值高昂:NVIDIA H100单卡售价约2.5~3万美元,一个千卡训练集群的硬件价值可达数千万美元
- 训练成本惊人:据公开报道估算,GPT-4的训练成本超过1亿美元;Meta 训练 Llama 3 使用了 16,000 张 H100,消耗超过 2,000万 GPU 小时攻击者通过反序列化漏洞获得服务器控制权后,可:
- 挖矿牟利:部署加密货币挖矿程序,持续消耗高价 GPU 算力
- 算力盗用:私自运行模型训练任务,窃取企业算力资源
- 资源转售:将算力挂到黑市二次租赁,非法牟利
4.2 模型资产窃取风险
大模型训练成本动辄数百上千万美元,模型权重是企业的核心资产:
- 直接窃取:下载模型文件(数十GB至数百GB)
- 数据泄露:窃取训练数据集,可能包含敏感信息
4.3 供应链污染风险
AI模型供应链呈现**“中心化+长链条”**特征:
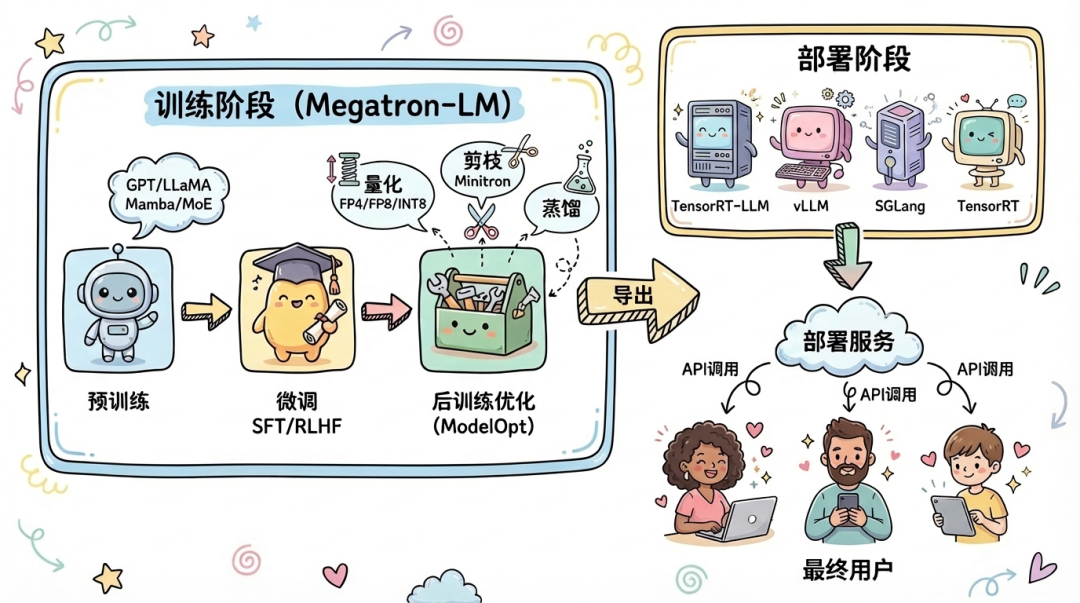
攻击者只需在任一环节注入恶意代码:
- 预训练模型投毒:在 Hugging Face 等平台上传含恶意 pickle 的模型文件,用户加载后即触发代码执行
- 量化数据投毒:构造恶意量化校准数据(.npy文件),在模型量化环节触发代码执行
- 训练配置投毒:发布恶意训练配置,加载时触发代码执行
此次发现的三个CVE正是典型的供应链攻击节点:
- Megatron-LM 负责训练阶段(源头)
- Model Optimizer 负责部署阶段(出口)
一旦被利用,可实现对整个AI生产链的渗透。
五、 安全缓解措施
5.1 安全编码规范
- 禁用不安全的反序列化调用:在代码中严格避免使用 torch.load() 的默认参数,强制设置 weights_only=True;使用 yaml.SafeLoader 替代 yaml.FullLoader;禁止 numpy.load(allow_pickle=True) 加载不可信数据
- 升级依赖版本:将 PyTorch 升级至 2.6+ 版本(默认启用 weights_only=True);将 PyYAML 升级至 6.0+ 版本;定期使用 SCA 工具扫描第三方依赖的已知漏洞
- 使用安全数据格式:优先采用 Safetensors 格式替代传统的 .pt/.pkl 模型文件,从根本上杜绝反序列化攻击面;量化校准数据使用 JSON、CSV 等纯数据格式替代 .npy(pickle模式)
- 代码安全审查:使用 SAST 工具自动化扫描 pickle.load()、torch.load()、yaml.load(FullLoader)、numpy.load(allow_pickle=True) 等危险调用模式,将安全检查纳入 CI/CD 流程
5.2 模型文件与数据完整性校验
- 来源验证:仅从官方渠道或可信源获取模型文件和预训练权重,避免使用来路不明的 checkpoint 文件
- 哈希校验:对模型文件、量化校准数据、训练配置文件进行 SHA-256 哈希校验,确保文件未被篡改
- 模型扫描:在加载前使用安全工具(如 Hugging Face 的 picklescan)扫描模型文件中是否包含恶意序列化对象
5.3 运行环境隔离
- 最小权限原则:AI 训练和推理服务以非 root 用户运行,限制文件系统和网络访问权限
- 容器化部署:使用容器隔离训练/推理环境,限制容器的系统调用能力(如通过 seccomp、AppArmor 策略)
- 网络隔离:训练集群与外部网络严格隔离,仅开放必要的数据传输通道,防止攻击者在获取代码执行权限后进行横向移动或数据外传
注:腾讯安全产品已全线支持上述漏洞的检测。
六、 结语
此次针对 NVIDIA Megatron-LM 与 Model Optimizer 的安全研究表明,反序列化风险已成为AI基础设施中不可忽视的系统性安全短板:
1. 漏洞普遍性:三个高危漏洞分布在预训练和后训练两个关键环节,涵盖模型文件加载、量化配置解析、校准数据加载等核心流程
2. 影响严重性:可导致算力劫持、模型窃取、供应链污染,直接威胁价值数亿美元的GPU集群和核心模型资产
3. 生态脆弱性:在供应链场景下,从代码缺陷到攻击实现的路径清晰且利用门槛低,攻击者仅需构造恶意模型文件或配置文件即可触发远程代码执行
附录:
「AI开源组件安全风险」系列一:配置缺陷,让你的 GPU 沦为矿机
_END_
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号