超轻量级 Openclaw - Nanobot 源码学习

超轻量级 Openclaw - Nanobot 源码学习

co松柏
发布于 2026-04-09 12:51:01
发布于 2026-04-09 12:51:01
前言
大家好,我是松柏!
最近 OpenClaw 真的太火了,因此也出现很多的衍生产品,比如超级轻量的 Nanobot:https://github.com/HKUDS/nanobot

nanobot 是一个超轻量级的个人 AI 助手框架,实现了 LLM 对话、工具调用、多渠道通信(Discord/飞书)、会话记忆、定时任务和后台子 Agent 等核心能力。
据官方文档介绍,它只用了 3510 行核心代码,就实现了跟 OpenClaw 类似的功能,比 OpenClaw 的 430k+ 行代码少了 99%!正好我对 OpenClaw 的实现也非常感兴趣,但是又没有精力研究 OpenClaw 的海量代码,所以功能类似的 nanobot 就成了一个非常好的学习研究对象,这也是这个项目的核心特性之一:

这也能说明作者对这个项目的代码质量是非常有信心的,所以本期我们就一起学习一下这个项目的源码,借它探究下 OpenClaw 的核心实现原理,同时也学习一下 nanobot 的设计思想。
项目骨架
整体架构
我们先整体看下整个项目的架构设计,做到对整个项目有一个大概的了解:
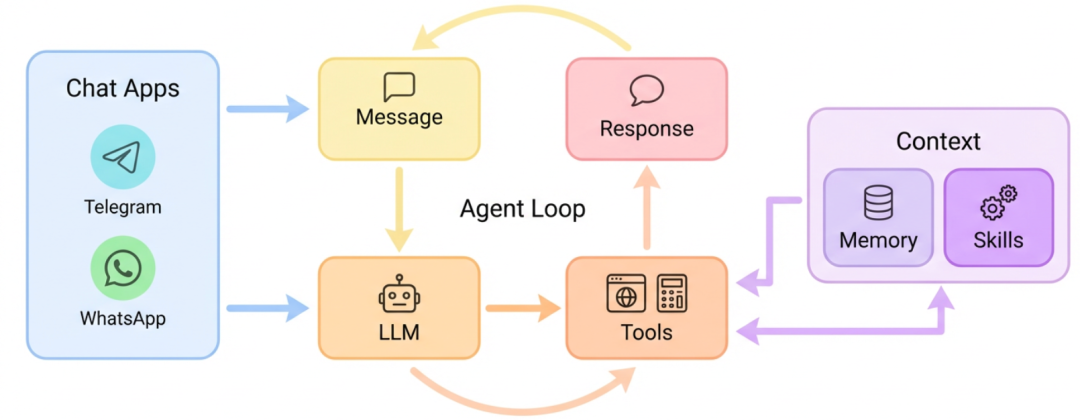
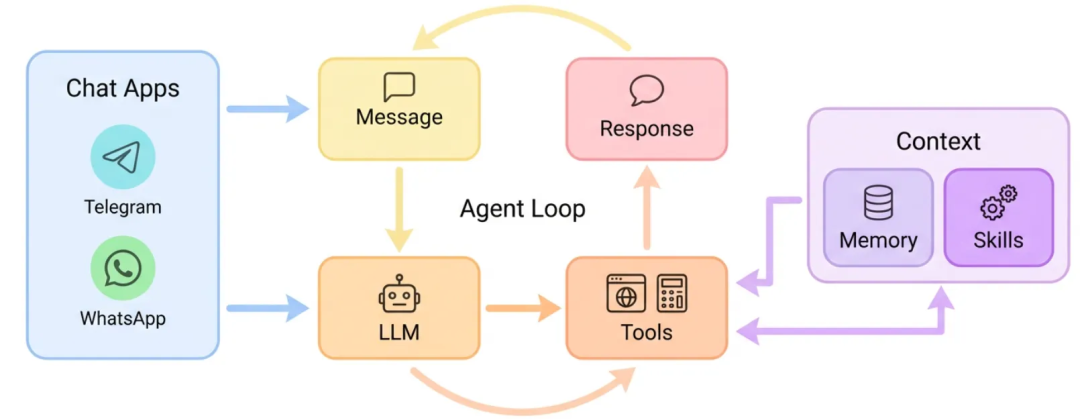
这是官方给的图,还是比较清晰的:我们通过聊天软件发消息,AI 大模型收到消息之后为了完成任务会调用各种各样的工具,比如联网工具、写文件工具等,工具的执行结果会被拼接到给 AI 的上下文里,AI 根据执行结果再决定给用户回复还是继续调用工具,AI 会一直循环这个过程直到用户的问题被解决并给出用户回复或者任务被人为中断。而 Memory 和 Skills 作为 Context 贯穿始终这个过程,为 LLM 提供记忆和能力扩展。
对应到项目目录中,每个包的作用如下图:

其实通过包名大家也能知道每个包大概是做什么的,现有一个印象,下文中每个包都会讲到。
核心配置文件
我们先来看下整个项目的核心配置文件 pyproject.toml ,可以发现这个项目的依赖非常少,而且都是些很常用的库:
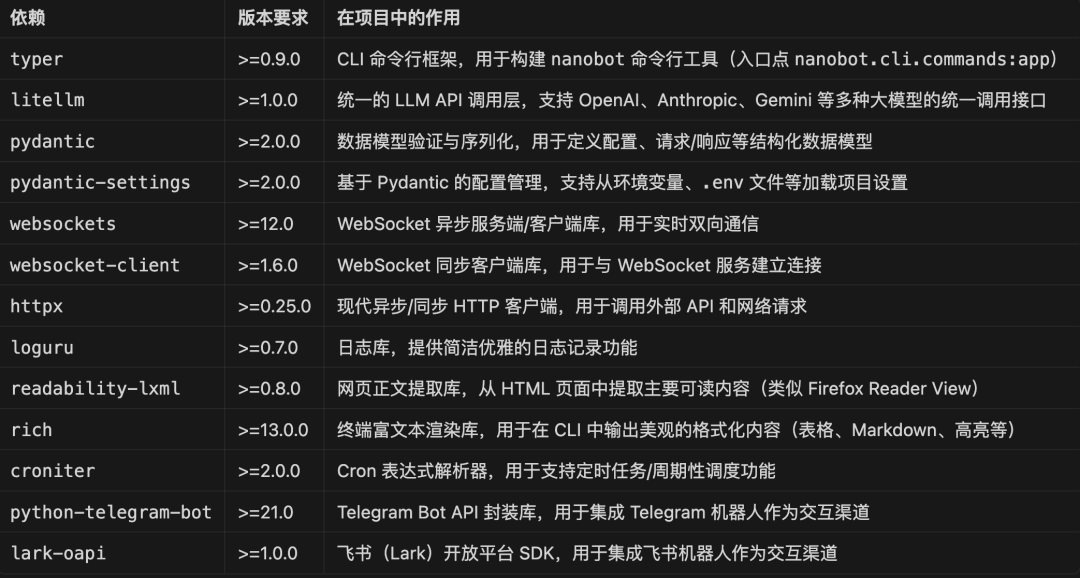
这就减少了很多的学习成本,更有利于我们掌握这个项目了。
除此之外,配置还有一行核心内容:
[project.scripts]
nanobot = "nanobot.cli.commands:app"
这两行是说,当用户通过 pip 或者 uv 安装这个包之后,系统就会生成一个名为 nanobot 的命令,而命令对应的实际代码位于 nanobot.cli.commands 包下的 app 对象里,也就是说这个 app 对象基本就是整个项目的入口了,待会我们也会详细的聊这个文件的内容。
基建服务
接下来我们看下整个项目中的基建服务,主要是 bus 和 providers 的 base.py,因为这几个模块包含了 消息格式、消息传输、LLM 接口 这些整个项目中的基础概念,方便我们建立全局认知。
bus
首先是 bus 中的 events.py 文件,这个文件里定义了两个类:用户发的消息 InboundMessage 和 回复给用户的 OutboundMessage。
而 queue.py 中定义了两个队列以及对应的发布、消费消息的方法,也都非常简单易懂:
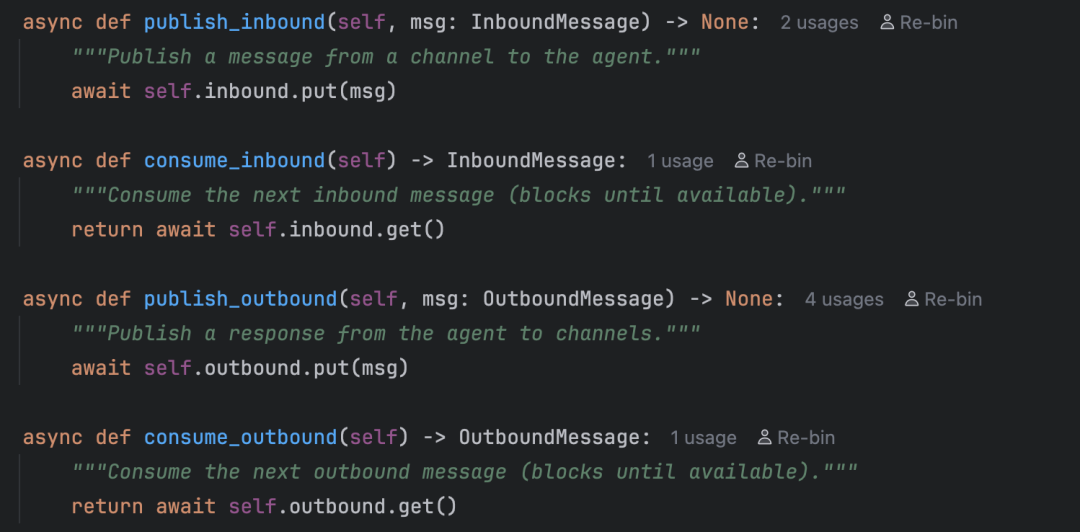
bus/ 消息总线
├── events.py 定义两种消息格式
│ ├── InboundMessage → 进来的消息(用户发的)
│ └── OutboundMessage → 出去的消息(回复给用户的)
└── queue.py MessageBus:两个异步队列 + 订阅分发机制
├── inbound 队列 → 渠道放消息,Agent 取消息
└── outbound 队列 → Agent 放回复,渠道取回复
也就是说,Agent 和各个聊天渠道不会直接通信,所有的消息都要通过消息总线。这样做的最大好处就是,渠道和 Agent 都只需要处理一种消息格式。
比如 QQ 和 飞书 发出的消息格式很可能不同,但是在放到消息总线的队列时,他们都会被转为相同的格式即 InboundMessage 对象。这样大模型不需要关注消息原来的格式,只需要针对 InboundMessage 类型处理即可。
OutboundMessage 的作用也是类似,如果没有 OutboundMessage,那么 Agent 就要自己知道怎么把消息发送给不同的平台,比如 Telegram 要把 Markdown 转成 Telegram HTML、飞书要判断 ID 类型是个人还是群聊、Discord 要处理限流重试等等。伪代码:
# ❌ 没有 OutboundMessage 的情况
if msg.channel == "telegram":
html = markdown_to_html(final_content)
await telegram_bot.send_message(chat_id=int(msg.chat_id), text=html, parse_mode="HTML")
elif msg.channel == "discord":
await http.post(f"https://discord.com/api/channels/{msg.chat_id}/messages", ...)
elif msg.channel == "feishu":
receive_id_type = "chat_id" if msg.chat_id.startswith("oc_") else "open_id"
await feishu_client.send(...)
elif msg.channel == "whatsapp":
await ws.send(json.dumps({"type": "send", "to": msg.chat_id, ...}))
所有渠道的发送逻辑都耦合在 Agent 的核心模块里,每加一个新渠道就得改核心代码。
但有了 OutboundMessage 之后,Agent 只负责把响应放到发布(publish)到 outbound 队列即可,后续的逻辑由各个渠道自行处理,整个过程中 Agent 不需要知道渠道细节,渠道不需要知道 Agent 逻辑,也就是实现了逻辑上的解耦。
providers.base.py
这个文件中主要是定义了 LLMProvider,这个抽象类的核心方法是 Chat ,响应结构是 LLMResponse ,也就是说,所有接入的大模型都需要继承 LLMProvider 并实现 Chat 方法,大模型的响应要转为 LLMResponse 类型。
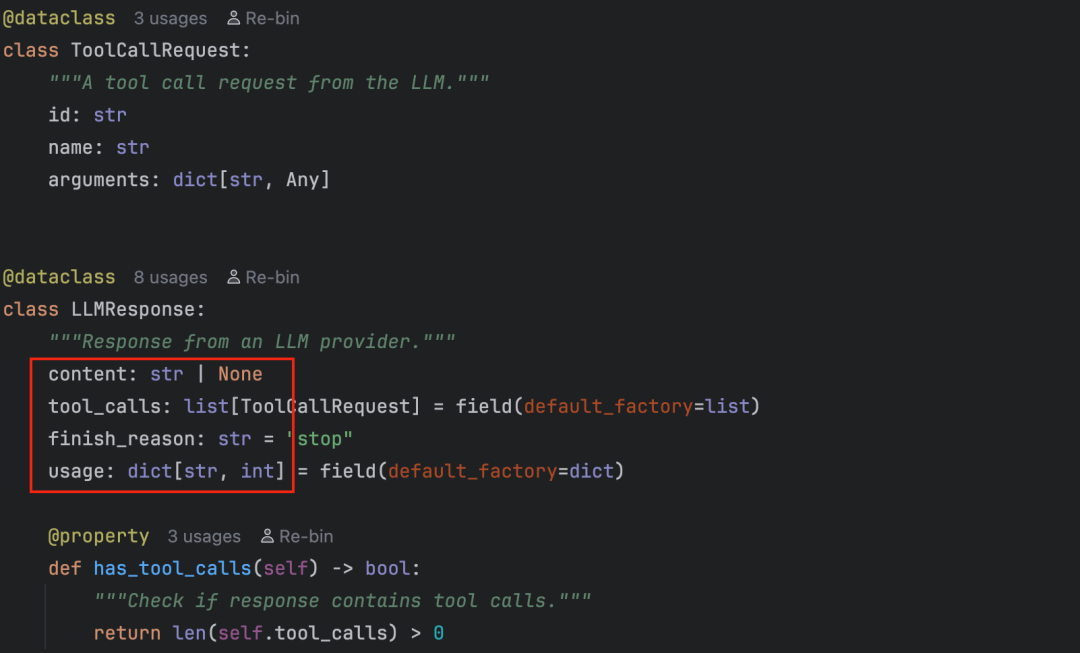
这样做的好处是无论接入多少种大模型,只需要专注于写新的实现类即可。
工具系统
接下来我们看这个项目的工具系统,工具基本就是 AI 的手脚。
nanobot 一共内置了 10 个工具,涵盖文件操作、Shell 命令、网络搜索、主动发消息、后台子任务、定时任务等能力,全部在 agent/tools/ 目录下:
agent/tools/
├── base.py # 工具抽象基类(所有工具的模板)
├── registry.py # 工具注册表(管理所有工具)
├── filesystem.py # 文件工具:读、写、编辑、列目录
├── shell.py # Shell 工具:执行命令
├── web.py # 网络工具:搜索、抓取网页
├── message.py # 消息工具:主动给用户发消息
├── spawn.py # 子任务工具:启动后台 Agent
└── cron.py # 定时工具:创建/管理定时任务
工具基类 Tool
先来看 base.py,这里定义了所有工具的模板Tool 。
任何一个工具都必须提供这 4 样东西:
属性/方法 | 类型 | 作用 |
|---|---|---|
name | 属性 | 工具名称,比如 "read_file"、"exec" |
description | 属性 | 工具的描述,告诉 LLM 这个工具能做什么 |
parameters | 属性 | 参数定义,用 JSON Schema 格式描述,告诉 LLM 需要传哪些参数 |
execute() | 方法 | 实际执行逻辑,接收参数,返回字符串结果 |
除了这 4 个必须实现的接口,Tool 基类还提供了两个通用方法:
to_schema():把工具信息转换成 OpenAI function calling 格式。这个格式是 LLM 识别工具的说明书,通过这个 schema 来知道有哪些工具可用、每个工具需要什么参数。validate_params():在执行工具之前校验 LLM 传来的参数是否合法,比如类型对不对、必填参数有没有漏。
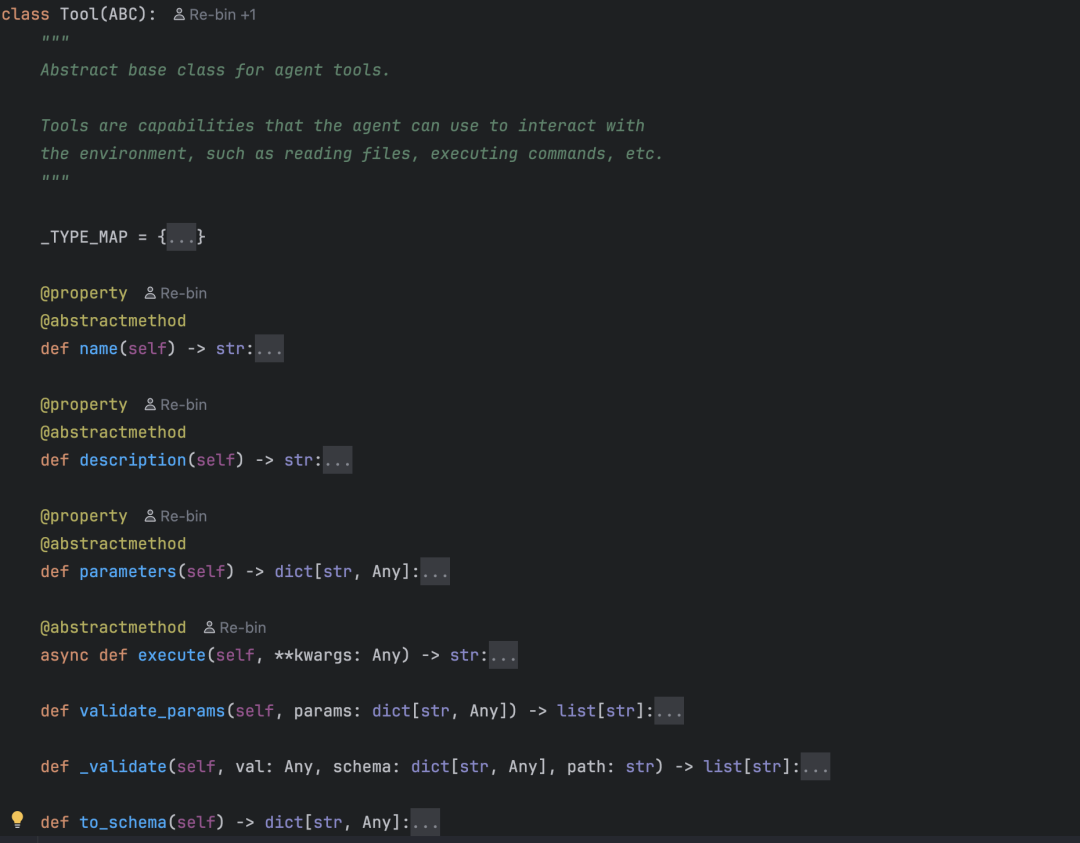
这里有一个设计上的细节值得注意:execute() 方法的返回值统一是字符串。不管是读文件、执行命令还是搜索网页,返回值都是 str。因为工具的执行结果最终要塞回给 LLM 作为上下文(后面讲 Agent Loop 时会详细看到这个过程),所以统一返回字符串是最简单的做法。
工具注册表 ToolRegistry
有了工具的模板,还需要一个地方来统一管理这些工具。registry.py 中的 ToolRegistry 就是干这个的,它内部就是一个字典 dict[str, Tool],以工具名称作为 key:

它有三个核心方法:
register(tool):注册一个工具,存到字典里get_definitions():遍历所有工具,调用每个工具的to_schema()方法,生成一个工具列表传给 LLMexecute(name, params):根据工具名找到工具对象,先调validate_params()校验参数,通过后调execute()执行
execute() 方法的错误处理也很有经典:如果工具执行出错,它不会抛异常,而是返回一个以 "Error:" 开头的字符串。这样 LLM 收到错误信息后可以自行决定怎么处理,比如换个参数重试,或者告诉用户出了什么问题。这种设计让 Agent 变得更健壮,不会因为一个工具执行失败就整个崩掉。
那这些工具是什么时候被注册到 ToolRegistry 里的呢?答案在 agent/loop.py 的 _register_default_tools() 方法中:
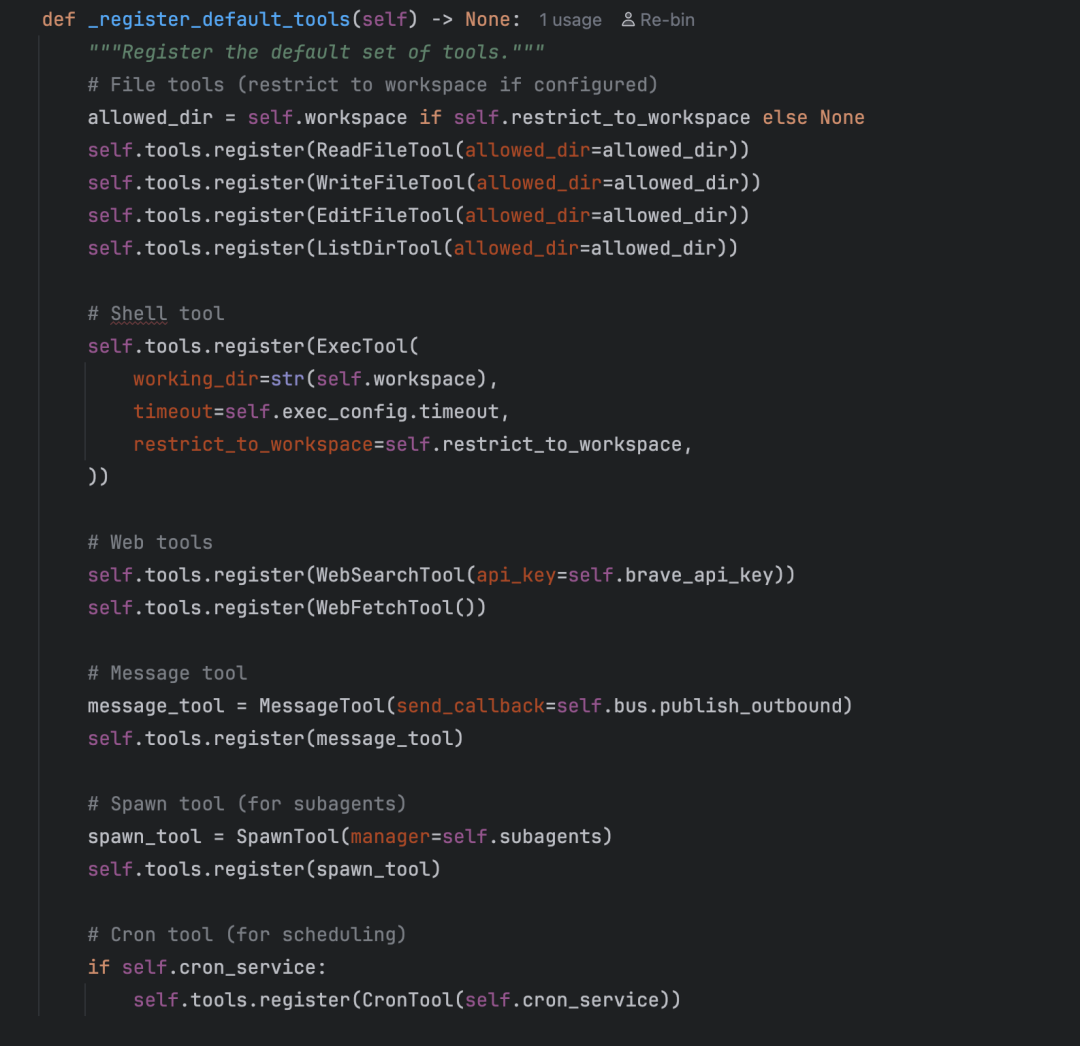
可以看到,系统在初始化时把 10 个工具全部注册了进去。到这里,工具系统就很清晰了:Tool 定义模板 → 各工具类继承实现 → ToolRegistry 统一管理 → Agent Loop 启动时注册。
LLM Provider
前面我们说工具是 AI 的手脚,那么 AI 就是工具的大脑,指挥着不同的工具干活。在上面的基建服务中,我们已经见过 LLMProvider 抽象类和 LLMResponse 数据结构。接下来看它的唯一实现类LiteLLMProvider。
为什么只需要一个实现类呢?nanobot 需要对接十几种大模型(OpenRouter、Anthropic、OpenAI、Gemini、DeepSeek、智谱、通义千问、Moonshot 等),但它并没有为每个模型写一个实现类,而是借助了一个叫 LiteLLM 的开源库。LiteLLM 的作用就是统一接口调用,把我们的代码转换成各家大模型各自的 API 格式。所以 nanobot 只需要写一个 LiteLLMProvider,就能通吃所有大模型。
LiteLLMProvider 的核心方法继承自LLMProvider 的 chat() ,整个流程分三步:
第一步:模型前缀处理
LiteLLM 有一个约定:不同的大模型需要加不同的前缀。比如通过 OpenRouter 调用的模型要加 openrouter/,通过 vLLM 本地部署的要加 hosted_vllm/,通义千问要加 dashscope/,等等。chat() 方法的前半部分做的就是这件事——根据你配置的模型名自动判断并补上正确的前缀:
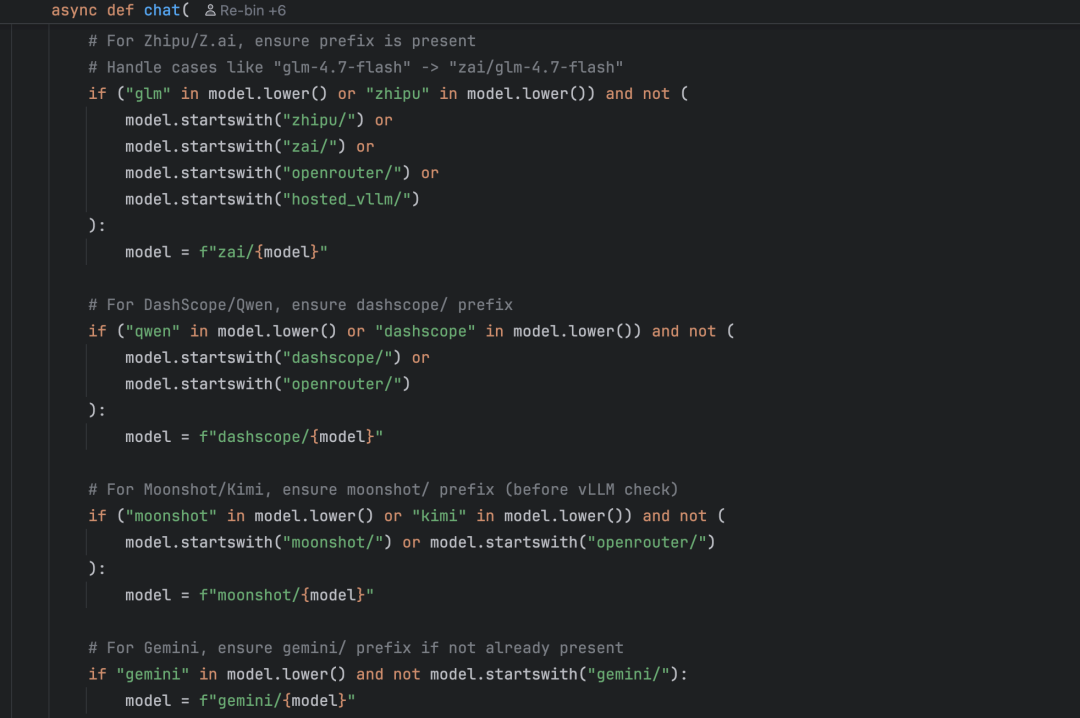
比如用户只需要在配置文件里写 "qwen-max",代码会自动转成 "dashscope/qwen-max" 传给 LiteLLM。
第二步:调用 LiteLLM
前缀处理完之后,就是构建参数并调用 LiteLLM 的 acompletion(异步版本的 completion):
注意这里如果传了 tools 参数,还会设置 tool_choice = "auto",意思是让 LLM 自己决定是否调用工具。
第三步:解析响应
LiteLLM 返回的原始响应格式比较复杂,_parse_response() 方法把它转换成 LLMResponse。
上下文构建
每次调用 LLM 时,你不能光把用户的消息扔过去就完事了——你得告诉它 “你叫什么名字”、“你有什么技能”、“你之前记住了什么”。这些信息的组装就是 ContextBuilder 的工作。
这里涉及三个文件,我们按依赖顺序来讲:先看两个数据源——MemoryStore 和 SkillsLoader,然后看把它们组装起来的 ContextBuilder。
agent/memory.py 中的 MemoryStore 管理 Agent 的记忆。它的存储方式非常朴素:直接读写 Markdown 文件:
- 长期记忆:
workspace/memory/MEMORY.md,记录跨越时间的重要信息,比如 用户喜欢简洁回复 - 每日笔记:
workspace/memory/YYYY-MM-DD.md,按天记录
核心方法 get_memory_context() 会把长期记忆和今日笔记拼接成一段文本,后续注入到 LLM 的 system prompt 中。
agent/skills.py 中的 SkillsLoader 负责加载 Agent 的技能。技能本质上也是 Markdown 文件,存放在 skills/ 目录下。
技能分两个来源:
- workspace 技能(优先级高):用户自己放在
workspace/skills/下的 - 内置技能:项目自带的,在
nanobot/skills/目录下
加载策略也很聪明,采用的是渐进式加载:
- always 技能:标记了
always=true的技能,完整内容直接注入 prompt - 按需技能:只注入一个摘要列表(名称+描述+文件路径),Agent 需要时自己用
read_file工具去读完整内容
# 1. Always-loaded skills: 完整内容注入
always_skills = self.skills.get_always_skills()
# 2. Available skills: 只注入摘要
skills_summary = self.skills.build_skills_summary()
为什么这么设计?因为 LLM 的上下文窗口是有限的,如果把所有技能的完整内容都塞进去,prompt 会非常长,既浪费 token 又可能影响效果。渐进式加载在省 token和保留能力之间取得了很好的平衡。
agent/context.py 中的 ContextBuilder 把上面的记忆、技能,加上各种引导文件,组装成发给 LLM 的完整上下文。
build_system_prompt() 组装系统提示词的过程:
1. 核心身份 _get_identity()
→ "你是 nanobot,一个 AI 助手"、当前时间、系统信息、workspace 路径
2. 引导文件 _load_bootstrap_files()
→ AGENTS.md(行为准则)、SOUL.md(人格定义)、USER.md(用户画像)、TOOLS.md(工具说明)、IDENTITY.md(身份标识)
3. 记忆 memory.get_memory_context()
→ 长期记忆 + 今日笔记
4. 技能 skills
→ always 技能完整内容 + 其他技能摘要列表
build_messages() 则是在 system prompt 的基础上,加入历史对话和当前用户消息,组成最终发给 LLM 的 messages 列表:
messages = [
{"role": "system", "content": system_prompt}, # 系统提示词
*history, # 历史对话(来自 Session)
{"role": "user", "content": current_message}, # 当前用户消息
]
前面提到的引导文件都在 workspace 目录下,它们各自的职责如下:
文件 | 作用 |
|---|---|
SOUL.md | Agent 的人格定义(性格、价值观) |
AGENTS.md | 行为准则(怎么回答、什么该做什么不该做) |
USER.md | 用户画像(用户的偏好、时区、语言等) |
TOOLS.md | 工具使用文档(对工具的补充说明) |
IDENTITY.md | 身份标识 |
memory/MEMORY.md | 长期记忆 |
这些文件都是普通的 Markdown,用户可以随时手动编辑来调整 Agent 的行为。
会话管理
session/manager.py 里定义了两个类:Session 和 SessionManager。
Session 代表跟某个用户的一次对话,核心就是一个消息列表 messages。每条消息是一个字典,包含 role(角色:user/assistant)、content(内容)、timestamp(时间戳)。
get_history() 方法返回最近 N 条消息(默认50条),并且只保留 role 和 content 两个字段,因为这是 LLM 需要的格式。
SessionManager 用一个 session_key 来区分不同的会话。这个 key 的格式是 渠道:聊天ID,比如 feishu:12345 代表 feishu 上 ID 为 12345 的用户的会话,cli:direct 代表命令行直接对话。
它的核心逻辑:
- 内存缓存,避免每次都读磁盘
- 磁盘持久化,每个会话存储为一个
.jsonl文件,每行一条消息 - get_or_create(key):先查缓存 → 再查磁盘 → 都没有就新建
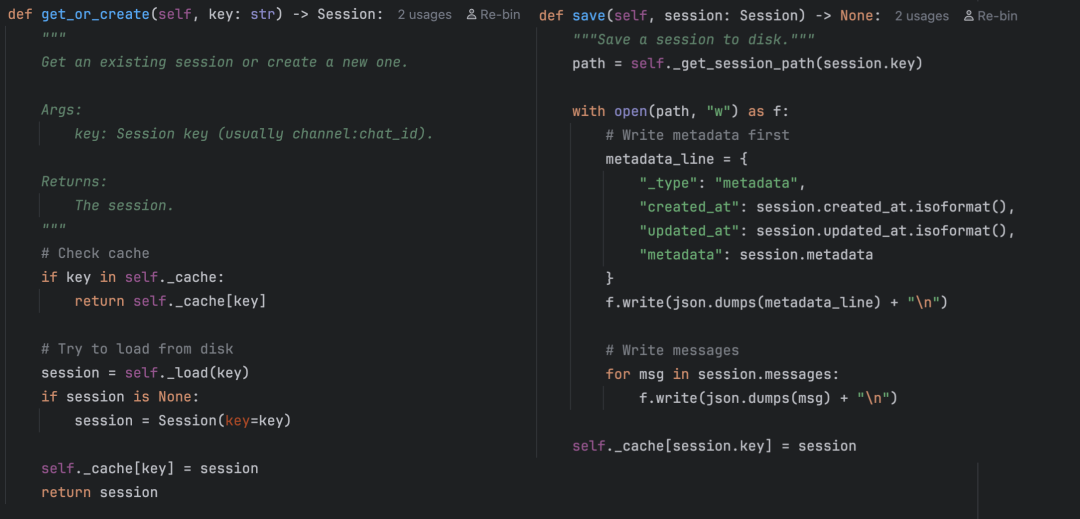
JSONL 格式的好处是简单且追加友好,每条新消息只需要往文件末尾追加一行,不需要像 JSON 那样每次重写整个文件(但当前实现 save() 是全量写入的)。
Agent Loop(核心模块)
终于到了全文的高潮部分。前面讲的所有组件 消息格式、消息总线、工具系统、LLM Provider、上下文构建、会话管理 全部在这里汇聚。
agent/loop.py 中的 AgentLoop 只有一个类,但它就是整个项目的灵魂。
把零件组装起来
先看 __init__ 方法接收的参数,每个都能对应到前面的章节:
参数 | 作用 |
|---|---|
bus | 消息总线 |
provider | LLM 提供商 |
workspace | 工作空间路径 |
brave_api_key | 搜索API Key (工具系统的 WebSearchTool) |
cron_service | 定时任务服务 (后文会讲) |
初始化过程中创建了三个重要的部分:
self.context = ContextBuilder(workspace) # 上下文组装
self.sessions = SessionManager(workspace) # 会话管理
self.tools = ToolRegistry() # 工具注册表
然后调用 _register_default_tools(),把 10 个工具全部注册进来。
等待消息
run() 方法是 Agent 的主循环,它不停地从消息总线中取 InboundMessage,取到并处理(使用 _process_message()方法,先有个印象,下文会讲)之后把结果以 OutboundMessage 的形式发布回消息总线:
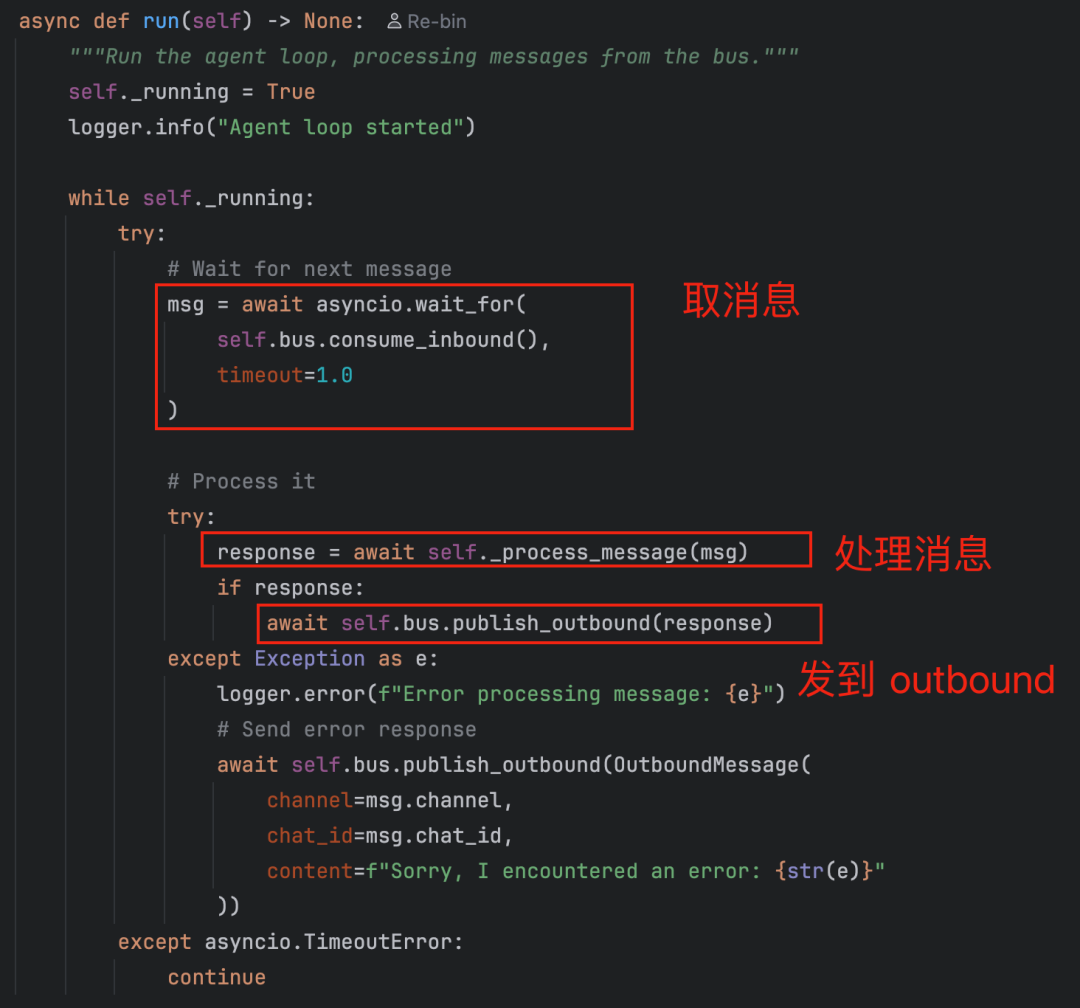
这里还用了 asyncio.wait_for 加 1 秒超时,如果 1 秒内没有新消息就 continue 继续等。这种非阻塞的轮询方式保证了 stop() 可以随时打断循环。
核心方法 _process_message() 的四个阶段
这是整个项目最核心的方法,处理一条用户消息分为四个阶段:
1)准备会话
session = self.sessions.get_or_create(msg.session_key) # 获取或创建会话
2)组装上下文
messages = self.context.build_messages(
history=session.get_history(), # 历史对话(第八章)
current_message=msg.content, # 当前用户消息
channel=msg.channel, # 渠道信息
chat_id=msg.chat_id, # 聊天 ID
)
3)LLM ↔ Tools 循环
while iteration < self.max_iterations:
iteration += 1
# 调 LLM
response = await self.provider.chat(
messages=messages,
tools=self.tools.get_definitions(),
)
# LLM 要调用工具?
if response.has_tool_calls:
# 把 LLM 的回复(包含工具调用)追加到 messages
messages = self.context.add_assistant_message(messages, response.content, tool_call_dicts)
# 执行工具,把结果追加到 messages
for tool_call in response.tool_calls:
result = await self.tools.execute(tool_call.name, tool_call.arguments)
messages = self.context.add_tool_result(messages, tool_call.id, tool_call.name, result)
else:
# LLM 不需要工具了,直接输出文本回复
final_content = response.content
break
这个 while 循环就是官方架构图中 Agent Loop 那个橙色圆环的具体实现。每一轮循环:LLM 思考 → 决定是否调工具 → 是就执行工具并把结果喂回去 → 不是就输出最终回复。最多循环 max_iterations 次(默认20次),防止无限循环。
这里也是经典的 ReAct (Reasoning + Acting)模式,LLM 先推理(Reasoning)决定下一步该做什么,然后执行(Acting)一个工具动作,再根据执行结果继续推理,如此循环往复,直到任务完成。
我们用一个具体例子来理解。假设用户问“帮我查下北京天气,然后写到 weather.txt 文件里”:
- 第1轮:LLM 收到用户消息,决定调用
web_search工具搜索“北京天气” - 第2轮:LLM 收到搜索结果,决定调用
write_file工具把天气信息写入文件 - 第3轮:LLM 收到“文件写入成功”的结果,判断任务完成,直接回复用户“已经帮你查好了并写入了 weather.txt”
三轮循环,每轮 messages 列表都在增长,LLM 看到的上下文越来越完整,直到它认为任务完成。
4)收尾
session.add_message("user", msg.content)
session.add_message("assistant", final_content)
self.sessions.save(session) # 保存会话
return OutboundMessage(channel=msg.channel, chat_id=msg.chat_id, content=final_content)
保存对话记录到 Session(下次对话时可以读出来作为历史),然后包装成 OutboundMessage 返回。
CLI 快捷入口
除了通过消息总线处理消息的 run() 方法,AgentLoop 还提供了一个 process_direct() 方法,就是不走 Bus,直接构造一个 InboundMessage 调用并 _process_message()。这个方法主要给命令行模式 nanobot agent -m "xxx" 使用,省去了消息总线的中转。
渠道系统——对接外部聊天平台
Agent Loop 处理完消息后返回的是 OutboundMessage,那这个消息是怎么送到用户手机上的?从用户手机发出的消息又是怎么进入系统的?这就是渠道系统的职责。
渠道基类 BaseChannel
channels/base.py 定义了所有聊天渠道的抽象基类。每个渠道必须实现三个方法:
方法 | 作用 |
|---|---|
start() | 连接平台并开始监听消息 |
send(msg) | 把 OutboundMessage 发送到对应平台 |
stop() | 断开连接,清理资源 |
基类还提供了两个通用方法:
is_allowed(sender_id):白名单检查。如果配置了allowFrom,则只有列表中的用户才能使用机器人_handle_message():收到平台消息后的统一处理——权限检查 → 打包成InboundMessage→ 发布到消息总线
渠道管理器 ChannelManager
channels/manager.py 中的 ChannelManager 负责渠道管理,并协调各聊天渠道,它有一个后台异步任务,不停从消息总线的 outbound 队列取消息,根据 msg.channel 字段路由到对应渠道的 send() 方法:
msg = await self.bus.consume_outbound() # 从总线取消息
channel = self.channels.get(msg.channel) # 找到对应渠道
await channel.send(msg) # 发送
这样整个消息出站的流程就串起来了:AgentLoop → bus.publish_outbound() → ChannelManager._dispatch_outbound() → Channel.send() → 用户手机。
定时任务、心跳、子任务
前面讲的是 nanobot 的主线,也就是用户问、AI 答。但一个完整的 AI 助手还需要一些辅助能力,比如定时执行任务、定期检查待办、在后台处理耗时操作等。
定时任务 CronService
cron/types.py 定义了数据结构,cron/service.py 实现了服务逻辑。
数据结构如下:
CronJob
├── id, name # 标识
├── schedule # 调度规则(CronSchedule)
│ ├── kind="every" # 按固定间隔,every_ms 毫秒执行一次
│ ├── kind="cron" # 按 cron 表达式,如 "0 9 * * *"(每天9点)
│ └── kind="at" # 一次性,在指定时间点执行
├── payload # 执行内容(CronPayload)
│ ├── message # 发给 Agent 的消息
│ ├── deliver # 是否把结果推送给用户
│ └── channel, to # 推送到哪个渠道的哪个用户
└── state # 运行状态(上次执行时间、下次执行时间、状态)
服务逻辑的核心是一个定时器循环,启动时计算所有任务的下一次执行时间,然后设置一个 asyncio.sleep 定时器等到最近的那个时间点,到时间了就执行到期的任务。执行完之后重新计算下一次时间并重新设置定时器。
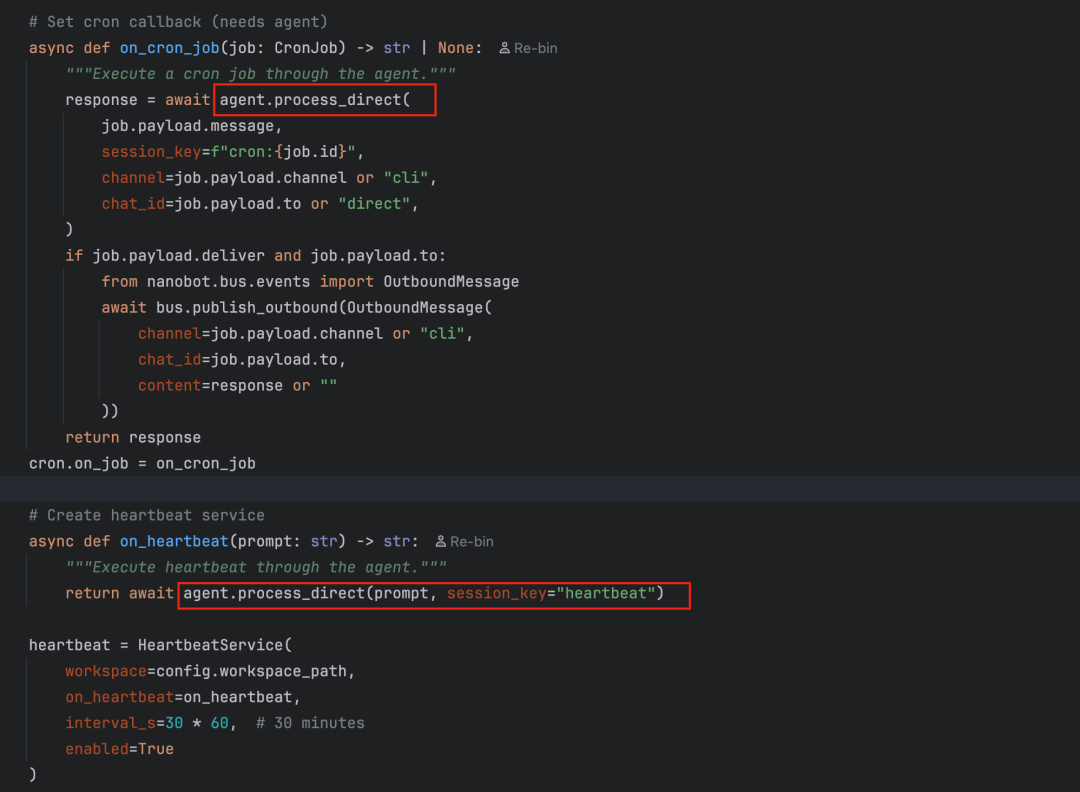
任务的执行方式也很巧妙,通过回调函数 on_job 把任务消息交给 Agent 处理。在 cli/commands.py 中可以看到,这个回调最终调用的是 agent.process_direct(job.payload.message)。也就是说,定时任务的本质就是定时给 Agent 发一条消息,复用整个 Agent Loop 来处理。
心跳服务 HeartbeatService
heartbeat/service.py 实现了一个简单但实用的功能:每隔 30 分钟唤醒 Agent 一次,让它检查有没有待办事项。
原理是每 30 分钟读一次 workspace/HEARTBEAT.md,如果文件为空或不存在,什么都不做;如果有内容,就把一段固定的 prompt 发给 Agent 处理;Agent 看完文件后,如果没事干就回复 HEARTBEAT_OK,有事就执行。
这就像给 AI 设了个闹钟——你可以在 HEARTBEAT.md 里写上"每天检查一下邮件",AI 每隔 30 分钟就会去翻一翻,有任务就执行。
子任务 SubagentManager
agent/subagent.py 解决的问题是如果用户让 AI 做一个很耗时的任务,正常流程下 Agent 要跑很久才能回复,用户会一直等着。
SubagentManager 的方案是通过工具(SpawnTool) spawn 一个独立的后台子 Agent,子 Agent 执行完成后将消息发到消息总线,然后由主 Agent 告知用户。
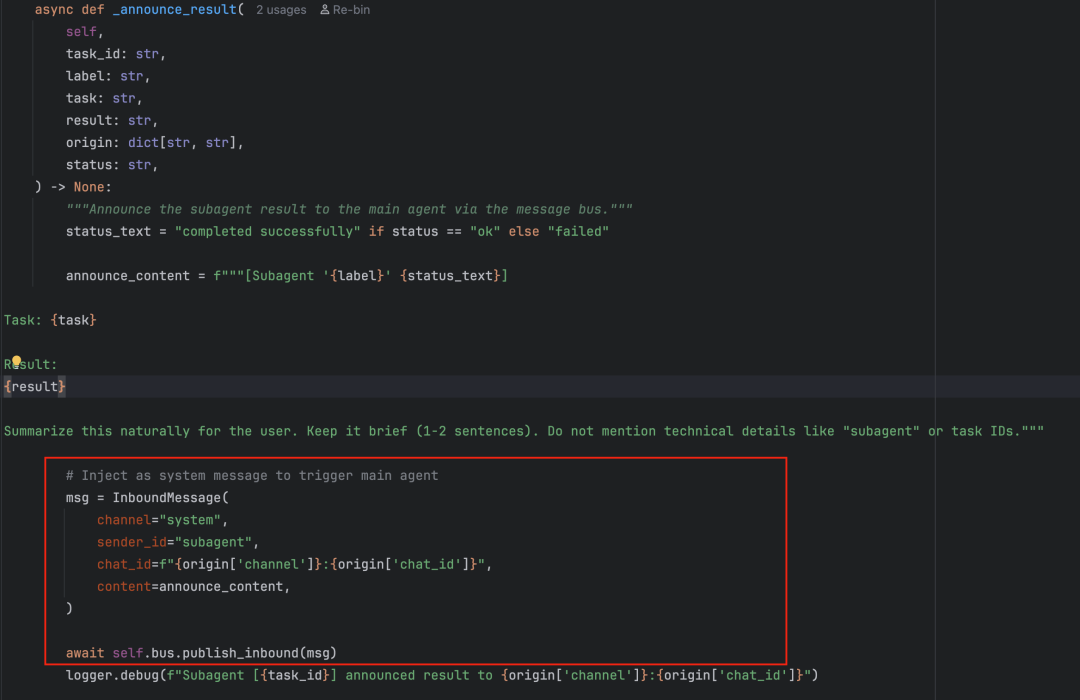
这个设计完全复用了现有的消息总线机制,子 Agent 不直接给用户发消息,而是通过 Bus 告诉主 Agent,由主 Agent 代为转达。
CLI 入口
cli/commands.py 是组装了整个项目,前面讲的所有组件,都在这个文件里被拼装成一个可运行的程序。
这个文件使用 Typer 框架定义了以下几个命令:
nanobot onboard 初始化
创建配置文件 ~/.nanobot/config.json 和 workspace 目录,以及默认的引导文件(SOUL.md、AGENTS.md、USER.md、MEMORY.md)。是用户使用 nanobot 的第一步。
nanobot agent -m "xxx" 对话
这是单次对话模式,也是理解组装过程最好的入口。来看它做了什么:
config = load_config() # 加载配置
bus = MessageBus() # 创建消息总线
provider = LiteLLMProvider(api_key, api_base, model) # 创建 LLM 提供商
agent_loop = AgentLoop(bus, provider, workspace, ...) # 创建 Agent Loop
response = await agent_loop.process_direct(message) # 直接处理消息
短短几行代码就把配置、消息总线、LLM、Agent Loop 串起来了。process_direct() 不走消息总线,直接调用 _process_message(),适合命令行这种不需要多渠道路由的场景。
如果不传 -m 参数,则进入交互模式,用 while 循环不断读取用户输入。
nanobot gateway —— 启动网关
这是最复杂也最完整的命令,它把所有组件都启动起来:
# 1. 基础组件
config = load_config() # 加载配置
bus = MessageBus() # 消息总线
provider = LiteLLMProvider(...) # LLM 提供商
# 2. 定时任务
cron = CronService(store_path) # 创建 Cron 服务
# 3. Agent Loop(核心)
agent = AgentLoop(bus, provider, workspace, ..., cron_service=cron)
# 4. 设置 Cron 回调(定时任务通过 agent.process_direct() 执行)
cron.on_job = on_cron_job
# 5. 心跳服务
heartbeat = HeartbeatService(workspace, on_heartbeat=...)
# 6. 渠道管理
channels = ChannelManager(config, bus)
# 7. 全部启动
await cron.start()
await heartbeat.start()
await asyncio.gather(agent.run(), channels.start_all())
最后的 asyncio.gather() 同时启动 Agent Loop 和所有渠道。
注意 Cron 和 Heartbeat 的回调设置,它们最终都是调用 agent.process_direct(),也就是说定时任务和心跳任务本质上就是给 Agent 发一条消息,复用整个 Agent Loop 的处理能力。
其他命令
nanobot status:显示配置状态、API Key 是否配置等nanobot channels status/login:渠道状态查看和 WhatsApp 登录nanobot cron add/list/remove/enable/run:定时任务的 CRUD 操作
这些命令都比较简单,就是调用对应模块的方法并格式化输出。
从发消息到收回复
前面我们自底向上地看完了每一个组件,最后让我们把它们串起来,走一遍完整的链路。
假设场景:你在飞书上给 nanobot 发了一条消息:“帮我搜一下今天的新闻”。
用户在飞书发消息
│
▼
FeishuChannel._on_message() [channels/feishu.py]
│ 解析消息文本、媒体,构造 sender_id、chat_id
▼
BaseChannel._handle_message() [channels/base.py]
│ 权限检查 is_allowed() → 打包成 InboundMessage
▼
bus.publish_inbound(msg) [bus/queue.py]
│ 消息放入 inbound 队列
▼
AgentLoop.run() → bus.consume_inbound() [agent/loop.py]
│ 从队列取出消息
▼
AgentLoop._process_message(msg) [agent/loop.py]
│
├── sessions.get_or_create(msg.session_key) [session/manager.py]
│ 获取会话历史
│
├── context.build_messages(history, msg, ...) [agent/context.py]
│ ├── build_system_prompt()
│ │ ├── _get_identity() → 身份信息
│ │ ├── _load_bootstrap_files() → SOUL.md, AGENTS.md ...
│ │ ├── memory.get_memory_context() → 长期记忆
│ │ └── skills.build_skills_summary() → 技能列表
│ └── 拼接 system + history + user message
│
├── while 循环开始 ─────────────────────────────
│ │
│ ├── provider.chat(messages, tools) [litellm_provider.py]
│ │ 调用 LLM,返回 LLMResponse
│ │
│ ├── response.has_tool_calls? → Yes
│ │ ├── context.add_assistant_message()
│ │ ├── tools.execute("web_search", ...) [registry.py → web.py]
│ │ └── context.add_tool_result() []
│ │
│ ├── provider.chat(messages, tools) [] ← 带上搜索结果再问一次
│ │
│ └── response.has_tool_calls? → No
│ final_content = response.content → "以下是今天的新闻..."
│
├── session.add_message("user", ...) []
├── session.add_message("assistant", ...)
├── sessions.save(session)
│
└── return OutboundMessage(channel="feishu", chat_id="12345", content=...)
│
▼
bus.publish_outbound(response) [bus/queue.py]
│ 消息放入 outbound 队列
▼
ChannelManager._dispatch_outbound() [channels/manager.py]
│ 从队列取出,根据 channel="feishu" 找到 FeishuChannel
▼
FeishuChannel.send(msg) [channels/feishu.py]
│
▼
用户在飞书收到回复 ✅
至此,一条消息从用户手机出发,经过渠道层 → 消息总线 → Agent Loop → LLM → 工具 → LLM → 消息总线 → 渠道层,最终回到用户手机。整个链路涉及前面的几乎每一个组件,每个组件各司其职、通过消息总线解耦通信。
这就是 nanobot 的全部核心设计。3500 多行代码,实现了一个五脏俱全的 AI Agent 框架,有 LLM 调度、有工具系统、有多渠道通信、有会话记忆、有定时任务、有后台子任务,麻雀虽小,五脏俱全。
结语
以上就是 nanobot 的核心内容啦,难度并不大,但是很多设计 Agent 的思路和方案都值得我们学习。希望大家看完后能够有所收获。
如果有帮助的话,欢迎关注点赞呀,我们下期再见,拜拜👋🏻!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-02-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号