强化学习之父与 AlphaGo 之父联手研究:AI 正告别「人类数据时代」,奔向「经验时代」

强化学习之父与 AlphaGo 之父联手研究:AI 正告别「人类数据时代」,奔向「经验时代」

不二小段
发布于 2026-04-09 15:48:52
发布于 2026-04-09 15:48:52
如果说现在的大模型研究上空笼罩着什么乌云的话,那「数据」无疑是其中一朵。我们撞上数据墙了吗?Scale law 失效了吗?大模型的能力还会继续提升吗?
《欢迎来到经验时代》也许是今年 AI 领域最重要的关于训练数据的纲领性檄文。两位重量级作者,一位是图灵奖得主、现代强化学习的奠基人之一、被誉为「强化学习教父」的 Richard S. Sutton, 另一位则是 AlphaGo 背后的大脑、DeepMind 的杰出科学家 David Silver。

Image
在这篇论文中,David 和 Richard 联手宣告:以模仿人类数据为核心的 AI 时代正在结束,而一个全新的、将从根本上释放 AI 潜能的「经验时代」 即将到来。
是的,你没看错。支撑起今天整个大模型生态的「大数据、大模型、大算力」范式,在他们眼中,即将触及天花板。而通往 AGI 的下一条路,指向了一个被许多人忽视、却又无比根本的方向:经验。
两位大佬认为,当前由大型语言模型 (LLM) 主导的、依赖海量人类数据进行训练的 AI 范式,其潜力正在迅速见顶。无论是数据量还是知识边界,都已触及天花板。要想到达真正的「超人智能」,AI 必须摆脱对人类知识的模仿,转向一个全新的数据来源,也就是经验。
在这个新时代,智能体 (agent) 将主要通过与环境的持续互动来学习和进化,其所产生的经验数据,无论在规模还是质量上,都将远远超越人类数据的总和。现在是时候重拾并革新强化学习 (RL) 的核心理念,为迎接真正超人智能的到来做好准备了。

Image
这篇论文系统性地剖析了当前 AI 范式的局限,并为即将到来的「经验时代」定义了四大核心支柱。那么,我们熟悉的 AI 时代究竟出了什么问题?「经验时代」又将如何颠覆一切?让我们跟随两位大师的思路,一探究竟。
「人类数据时代」的黄昏:当最强的燃料即将耗尽
过去几年,AI 取得了惊人的进步,其核心驱动力是对海量人类数据的学习。
以 LLM 为代表,通过吞噬互联网上几乎所有人类创造的文本和代码,实现了惊人的通用能力。 仅仅一个 LLM,就能写诗、解物理题、诊断病情、总结法律文书,几乎无所不能。
这个时代,我们可以称之为「人类数据时代」 (Era of Human Data)。它的成功逻辑很简单:模仿人类。
但 David 和 Richard 尖锐地指出,这种模式有其固有的、无法逾越的局限性。模仿人类,最多只能达到和人类一样好的水平,却永远无法超越人类知识的边界。
瓶颈已经显现。
首先,高质量的人类数据正在被耗尽。 在数学、编程和科学等关键领域,能显著提升顶尖模型性能的高质量数据,要么已经被「喂」给了模型,要么很快就将被消耗殆尽。 纯粹依靠监督学习从人类数据中汲取养分,这条路带来的进步速度,肉眼可见地正在放缓。
其次,单纯模仿无法超越模仿对象。 依赖人类数据训练的 AI,其能力的上限被牢牢地锁死在人类知识的边界之内。它可以成为一个优秀的人类模仿者,但很难在那些需要真正创造力的领域——如数学、科学和技术创新上,实现超越人类的突破。真正有价值的新定理、新技术和新发现,恰恰存在于人类现有知识的版图之外。指望从已有的数据中「挖掘」出这些不存在的东西,无异于缘木求鱼。
AI 需要一个新的、取之不竭的数据来源。这个来源必须是动态的、能够随着智能体自身变强而「水涨船高」的。任何静态的、人为合成的数据生成方法,很快就会被更强大的智能体甩在身后。
唯一的答案,就是让智能体从自己的「经验」,也就是智能体与环境交互所产生的数据中学习。
这场变革,或许已经悄然开始。
AlphaProof 的成功就是一个绝佳的例证。它是第一个在国际数学奥林匹克竞赛 (IMO) 中斩获银牌的 AI 程序,其表现远超那些依赖人类数据的模型。它的成功秘诀是什么?
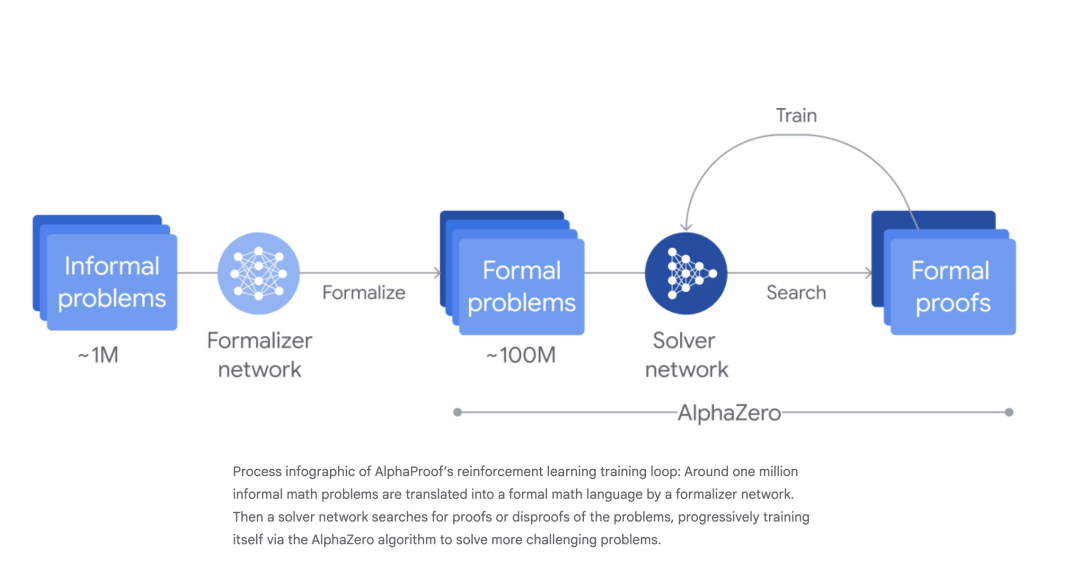
Image
AlphaProof 最初学习了约十万个人类数学家多年积累的形式化证明。但这只是起点,关键在于其后的强化学习阶段——通过与证明系统持续互动,它生成了上亿条新的证明,远远超出了人类现有知识的范畴。正是这种对「交互经验」的探索运用,让它发现了人类未曾想到的解题路径。
无独有偶,DeepSeek 的研究也得出了相似的结论,他们发现「强化学习的力量和美丽在于:我们不是明确地教模型如何解决问题,而只是为它提供正确的激励,它就能自主地发展出高级的问题解决策略」。
一旦我们完全释放「经验学习」的潜力,AI 将迸发出不可思议的全新能力。而这个即将到来的「经验时代」,将在以下四个维度彻底突破「人类数据时代」的限制。
定义未来的四大支柱:经验时代的 AI 长什么样?
David 和 Richard 认为,「经验时代」的智能体将不再是人类数据的被动接收者,而是真实世界的积极探索者。这种转变将体现在四个核心特征上:流 (Streams)、行动与观察 (Actions and Observations)、奖励 (Rewards) 以及规划与推理 (Planning and Reasoning)。
从「问答」到「终身学习」:经验流 (Streams of Experience)
「人类数据时代」的 AI,其生命是碎片化的。
LLM 的交互大多是短暂的「回合制」:用户提问,模型回答,一次交互结束。从一个回合到下一个回合,几乎没有信息会得到保留,模型无法实现长期的适应和进化。它的目标也仅限于当前回合,比如直接回答用户的问题。
相比之下,人类和其他动物的存在方式是连续的。我们活在一个持续多年的、不间断的「行动与观察」流之中。我们的记忆和经验贯穿整个生命流,行为会根据过去的经验不断自我纠正和改进。更重要的是,我们的目标往往是长期的,跨越了无数个当下的行动和观察。例如,一个人可能会为了「保持健康」、「学习一门语言」或「实现科学突破」这些长远目标而行动。
未来强大的 AI,也应该拥有属于自己的、长周期的「经验流」 (stream of experience),智能体将像人类或其他动物一样,存在于一个持续一生的经验流中。它们的行为和观察是连续的,信息可以在整个生命周期中传递和积累,从而不断自我修正和改进。这意味着智能体可以设定和追求长远目标。
想象一下未来的应用场景:
- 个性化健康助手:一个与你的可穿戴设备相连的 AI 助手,可以持续数月监控你的睡眠模式、活动水平和饮食习惯。它能根据长期趋势和你的健康目标,提供个性化的建议和鼓励,并动态调整其指导策略。
- 个性化教育代理:一个 AI 导师,可以花上几年时间跟踪你学习一门新语言的进度,识别你的知识短板,适应你的学习风格,并不断优化教学方法。
- 科学发现代理:一个以「发现新材料」或「减少二氧化碳」为目标的科学智能体。它可以长期分析真实世界的观测数据,开发并运行模拟,甚至提出需要在真实世界中进行的实验或干预措施。
在这些场景中,智能体追求的是长期成功的最大化,而非眼前一时的最优解。它们今天的某个行为,可能短期内没有收益甚至有害,但却是实现未来宏大目标的必要一步。
这与当前 AI 系统那种「即时响应请求、不考虑未来后果」的模式形成了鲜明对比。
从「对话框」到「真实世界」:行动与观察 (Actions and Observations)
「人类数据时代」的 LLM 主要通过文本与世界互动,这是一个被人类特权化的渠道。而自然界的智能,无论是动物还是人类,都是通过传感器和运动控制与环境进行更直接、更丰富的互动。
虽然 LLM 已经可以通过调用 API 等方式在数字世界中执行一些「动作」。但这些能力最初也主要来自于模仿人类使用工具的案例,而非智能体自身的经验。
「经验时代」的智能体也将打破文本的束缚,获得在真实世界中自主行动的能力。
最近,一些前沿的 AI 原型已经开始以一种更通用的方式与计算机交互——它们使用与人类完全相同的接口(如鼠标和键盘)来操作电脑。这种转变,预示着 AI 将能够独立自主地在世界中行动。
未来的智能体将能够:
- 主动探索世界:而不是被动等待指令。
- 与数字世界深度融合:它们既可以使用对人类友好的用户界面,方便与用户协作;也可以使用对机器友好的 API 和代码,为了自身目标自主行动。
- 与物理世界交互:通过数字接口,一个科学智能体可以监控环境传感器,远程操控望远镜,或控制实验室里的机械臂来自主进行科学实验。
这种更丰富的交互,将为 AI 提供一种自主理解和控制世界的方式,让它们能够发现人类可能永远也想不到的策略。
从「人类偏好」到「环境信号」:基于现实的奖励 (Grounded Rewards)
AI 如何知道自己做得好或不好?
「人类数据时代」的主流答案是 RLHF (基于人类反馈的强化学习)。简单说,就是让人类专家来评价 AI 的输出是好是坏。比如,让专家来评判一个健康助手的建议、一个教育助理的教学方法,或一个科学智能体的实验方案。
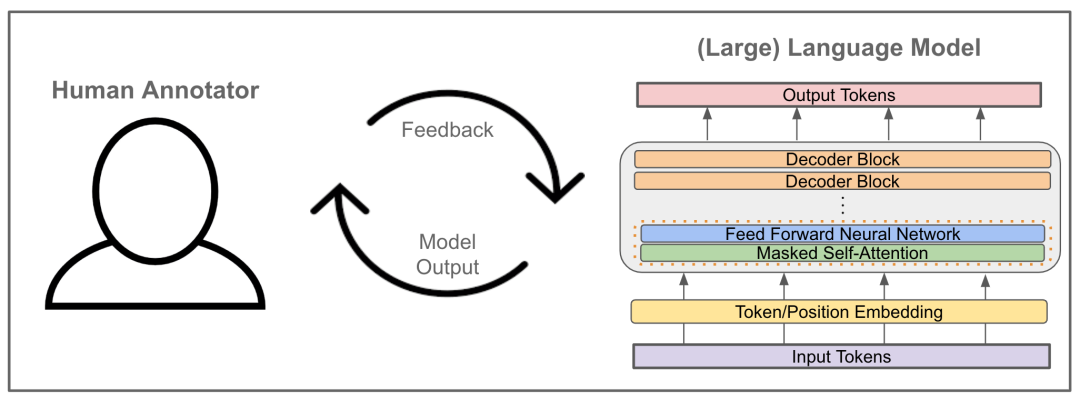
Image
这种方式被称为「人类预判」 (human prejudgement)。它的核心缺陷在于,奖励信号并非来自于行动对真实世界产生的后果,而是来自于人类在行动发生前的主观判断。这就带来了一个无法穿透的性能天花板:AI 永远无法发现那些不被人类评估者所理解或欣赏的、但实际上更优的策略。
要想发现远超人类现有知识的新思想,就必须使用「植根性奖励」 (grounded rewards)—— 即那些直接来自环境本身的客观信号。
世界本身就充满了可供量化的信号,例如:
- 健康领域:其奖励信号可以基于一系列用户身体的信号,比如静息心率、睡眠时长、运动步数。
- 教育领域:某一门学科的考试成绩。
- 科学领域:如果目标是减缓全球变暖,奖励可以基于对二氧化碳水平的经验观察;如果目标是发现更坚固的材料,奖励可以基于材料模拟器中的拉伸强度等测量值。
- 商业领域:利润、销量、用户访问量。
这些「植根性奖励」从哪里来?两位作者认为,一旦智能体通过丰富的行动和观察与世界连接起来,这样的信号将无处不在。这些信号直接反映了智能体行为在真实世界中产生的后果,而不是人类专家的预判。
事实上,我们的世界充满了各种可以量化的指标:成本、错误率、饥饿感、生产力、健康指标、气候指标、利润、销量、考试成绩、成功、访问量、产量、股票、点赞数、收入、快乐/痛苦、经济指标、准确率、功率、距离、速度、效率、能耗……等等。
但问题也随之而来:如果 AI 开始自主优化这些非人类的、植根于环境的奖励信号,它会不会变得与人类的目标背道而驰,甚至失控?
David 和 Richard 提出了一种由用户引导的、双层优化的奖励机制。
这个想法是,奖励函数本身可以是一个神经网络,它接收智能体与用户和环境的互动作为输入,然后输出一个奖励值。
高层目标:由用户设定。例如,用户可以指定一个宽泛的目标,如「帮我提升健康水平」。
低层优化:AI 根据这个高层目标,自动将奖励函数与环境中的具体「植根信号」(如心率、睡眠时长、步数)结合起来。
持续校准:用户可以在过程中提供反馈(如满意度),用于微调奖励函数。 这样,奖励函数本身就可以不断适应和演进,以识别和纠正任何「对不齐」(misalignment) 的情况。
这可以看作一个双层优化过程:顶层优化人类的反馈,底层优化来自环境的植根信号。通过这种方式,少量的「人类数据」(高层目标和反馈)就可以驱动海量的「自主学习」(对底层信号的优化),既保证了 AI 的自主探索能力,又确保了它与人类的长期目标对齐。
从「模范人脑」到「探索非人推理」:规划与推理 (Planning and Reasoning)
近年来,LLM 通过「思维链」 (chain of thought) 等技术,在语言推理方面取得了巨大进展。它们通过生成一步步的思考过程来模仿人类的逻辑。有些方法甚至会强化那些与人类专家思维路径相匹配的思考步骤。
但这里存在一个根本性的问题:我们凭什么认为,人类语言是思考的最佳载体?人类的语言和思维方式,真的是进行计算和推理的最优形式吗?
David 和 Richard 尖锐地指出,更高效的思维机制几乎必然存在,它们可能使用非人类的语言,比如符号化的、分布式的、连续的甚至是可微的计算。一个能够自学习的系统,原则上由潜力通过从经验中学习「如何思考」来发现或改进这些方法。就像 AlphaProof,它学习证明复杂数学定理的方式就与人类数学家截然不同。
更重要的是,单纯模仿人类思维会继承人类固有的偏见和错误的认知模型。作者们给出了一个生动的思想实验:
一个 5000 年前训练的 AI,可能会用「万物有灵论」来解释物理问题;1000 年前,它会用「神学」来解释;300 年前,是「牛顿力学」;而 50 年前,则是「量子力学」。
人类之所以能不断推翻旧理论,正是因为我们能通过实验与真实世界互动,用观测数据来检验和修正我们的思想。人类思维范式的每一次跃迁,都离不开与真实世界的互动:提出假设、进行实验、观察结果、修正理论。
同样,AI 也必须植根于真实世界的数据,才能推翻那些继承来的错误思想。否则,无论一个 AI 多么复杂,它都将成为现有人类知识的「回音室」。
如何让 AI 的思考更「接地气」?一种可能的方式是构建一个「世界模型」 (world model)。智能体通过这个模型来预测自己行为的后果,并基于这些预测进行规划。随着与世界互动的经验不断增加,这个模型也会被持续更新和修正,变得越来越准确。
这使得 AI 能够直接在其行动与世界的因果关系层面进行规划,而不是仅仅在语言层面进行推理。 随着智能体在经验流中不断与世界互动,它的世界模型也会被持续更新和修正。
为何是现在?一场伟大的「范式和解」
经验学习并非新概念。在所谓的「模拟时代」 (Era of Simulation),强化学习早已在围棋 (AlphaGo)、星际争霸 II、Dota 2 等规则清晰、奖励明确的模拟环境中取得了超越人类的成就。AlphaZero 等算法甚至展示了近乎无限的扩展潜力。
然而,这个范式始终未能跨越从「模拟」(规则明确、奖励单一的封闭问题)到「现实」(开放、奖励模糊的复杂问题)的鸿沟。
「人类数据时代」提供了一个极具吸引力的解决方案。蕴含在海量人类语料库中的知识,让 AI 获得了前所未有的广度。相较于「模拟时代」的狭窄成功,「人类数据时代」的 LLM 展现了处理多样化任务的能力。结果是,整个领域的重心发生了偏移,经验性的强化学习方法在很大程度上被抛弃,世界全面转向了以人类为中心的 AI。
可以说,「人类数据时代」的 LLM 反而丢失了「模拟时代」最宝贵的东西:自我发现新知识的能力。AlphaZero 曾发现人类数千年来未曾想到的围棋策略,从根本上改变了这项古老游戏。
而即将到来的「经验时代」,将实现一场伟大的「和解」。David 和 Richard 认为,「经验时代」的使命,就是将 LLM 的通用性与经典 RL 的自我发现能力这两股力量重新结合起来。当智能体能够在真实世界的经验流中自主行动和观察,并且其奖励可以灵活地与现实世界中丰富的植根信号相结合时,这一切就将成为可能。
这张代表强化学习关注度的曲线,在 2016 年左右的 AlphaGo 时代达到顶峰,随后在以 ChatGPT 为代表的「人类数据时代」跌入低谷,而从 2024 年开始,随着 AlphaProof 等新一代智能体的出现,这条曲线正以一个更陡峭的角度,昂首向上,指向「超人智能」。
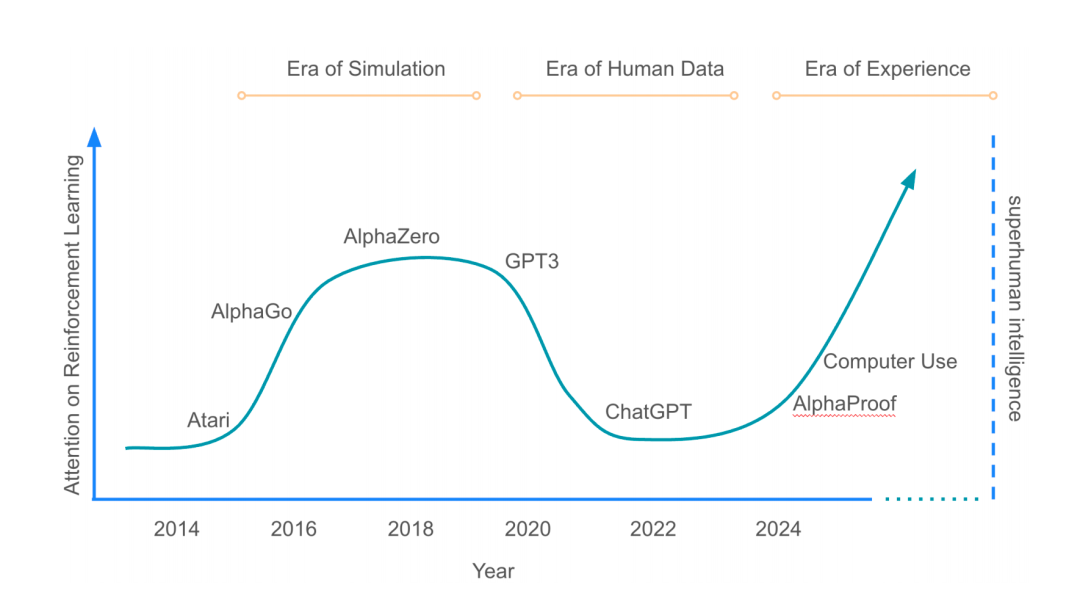
Image
随着能够与复杂真实世界环境互动的自主智能体技术日趋成熟,以及强大的 RL 方法开始被用于解决开放式的推理问题,我们已经站在了新时代的大门口。
这也意味着,AI 社区需要重新审视并大力发展那些在 LLM 时代被某种程度上「绕过」的经典 RL 概念,如价值函数、真实世界探索、世界模型和时间抽象等,为新时代的挑战做好准备。
机遇、风险与新的安全视角
「经验时代」的到来无疑将释放巨大的生产力。个性化助理将深刻改变我们的生活:
- 在日常生活中,个性化的 AI 助手将利用连续的经验流,为个人提供长达数月甚至数年的健康、教育或职业规划支持。
- 最激动人心的变革将发生在科学发现领域。 AI 智能体将能够在材料科学、医学或硬件设计等领域自主设计和进行实验。 通过从自己的实验结果中持续学习,它们将以惊人的速度探索知识的新前沿,带来新材料、新药物和新技术的爆发。
但风险同样不容忽视。能够自主行动、追求长期目标的智能体,带来了新的滥用风险和更艰巨的监管挑战:
- 社会影响:虽然自动化能提高生产力,但也可能导致更大范围的工作岗位替代,甚至触及那些被认为是人类专属的领域,如长期问题解决和创新能力。
- 安全风险:能够长期自主与世界互动的智能体,天然地减少了人类干预的机会,这对信任和责任提出了极高的要求。
- 可解释性:摆脱人类数据和人类思维模式,可能会让未来的 AI 系统更难被理解。
然而,有趣的是,David 和 Richard 认为,「经验时代」的 AI 反而可能带来一些重要的安全优势。
- 适应性:一个经验型智能体能够感知环境的变化并随之调整自身行为。比如,当它发现某个行为引发了人类的担忧或不满时,它可以通过学习来主动修正,避免负面后果。这比一个固化不变的、无法感知外界变化的系统要安全得多。
- 可修正的对齐:由于奖励函数本身也可以通过经验来学习和调整,这意味着即使最初的目标设定有偏差(比如经典的「回形针最大化」思想实验),系统也有机会通过观察到的人类负反馈,在灾难发生前逐步修正其目标。
- 物理世界的刹车:依赖真实世界物理反馈的进步,其速度会受到物理规律的天然限制。开发一款新药,即使有 AI 辅助,也绕不开耗时漫长的真实世界临床试验。这为我们应对 AI 的快速发展提供了一个宝贵的缓冲期。
结语
「经验时代」标志着 AI 演化的一个决定性时刻。
它建立在今天强大的技术基础之上,但决心要超越人类衍生数据的局限。 在这个新范式下,智能体将越来越多地从自身与世界的互动中学习。 它们将在终身的经验流中持续适应,通过丰富的观察和行动与环境自主互动,其目标可以被引导至任何植根于现实的信号组合,并利用强大的非人类推理能力,制定植根于行动后果的计划。
最终,经验数据将在规模和质量上,全面超越人类生成的数据。
正如 David Silver 和 Richard Sutton 所描绘的蓝图,这场由「经验」驱动的革命,最终将解锁在众多领域超越任何人类的全新能力。
一个时代结束了,一个更伟大的时代,正拉开序幕。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号