Kimi 深度研究一手实测,横评对决 ChatGPT、Gemini Deep Research

Kimi 深度研究一手实测,横评对决 ChatGPT、Gemini Deep Research

不二小段
发布于 2026-04-09 16:14:43
发布于 2026-04-09 16:14:43
拿到 Kimi Researcher 的内测资格一周多了,高强度测了很多 case。
Image
先说一下我的总体感受吧:
- • 从产品层面,Kimi 的深度研究和 ChatGPT、Gemini 的 Deep Research 类似,都是针对给定话题先搜再写,我感觉搜索的广度和深度差不多,但是 Kimi 的写作能力还是稍弱,不过 Kimi 除了搜写以外还会额外生成一个可视化的网页,传递信息更加直观。
- • 从技术层面,Kimi Researcher 验证了「模型即 Agent」范式,通过端到端强化学习极大提升模型自主规划、工具调用能力,并涌现出审慎严谨、自我修正的行为,值得从业者关注。
接下来我会分别从用户视角和开发者视角来分享一下我的体验和看法。
实测体验:不止于搜写,更有可视化报告交付
先来看一些使用案例吧,其中一些案例我会进行将 Kimi 深度研究和 ChatGPT、Gemini 的 Deep Research 进行比较。
汽车选购建议
这几天最火的应该就是小米 YU7,先来一道汽车选购的题目,看看 Kimi Researcher 的表现。我的 Prompt 是:
一家三口,日常用车,请你帮我开展调研,预算 27 万左右。 1、比较小米 Yu7 的不同版本; 2、比较小米 Yu7、特斯拉 Model Y、小鹏 G7、智界 R7。 给出你的选购建议。
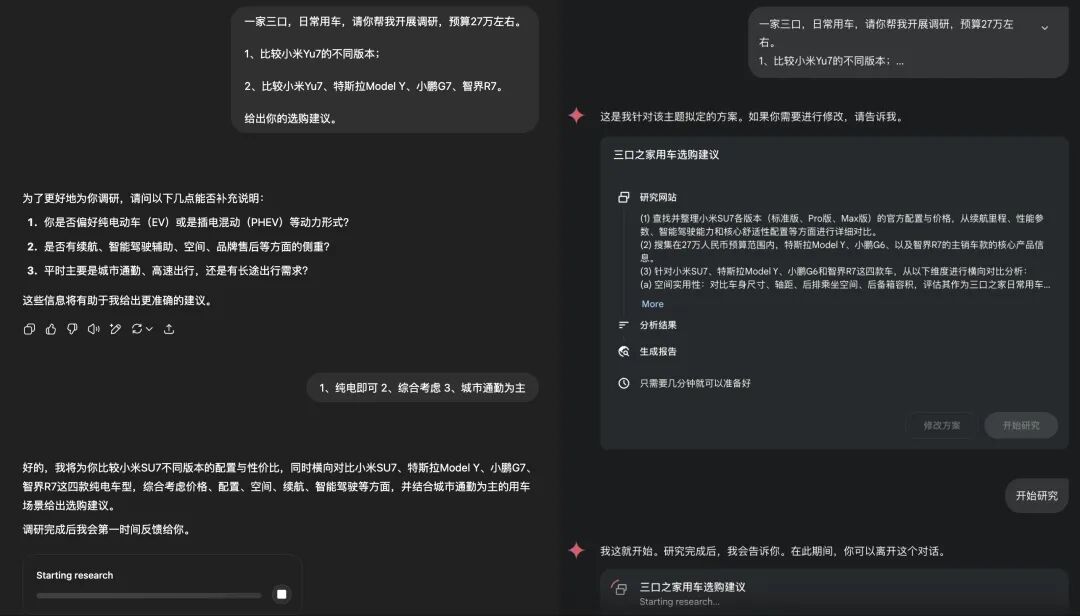
Kimi 在开始研究前,会追问一次用户,请求澄清或补充更完整的信息,之后就会开始进行搜索研究。单次研究的耗时往往超过 20 分钟,在研究过程中不用一直开着对话页面。

Image
对于 ChatGPT 和 Gemini,在正式研究前,都会有类似步骤,ChatGPT 同样是追问信息,而 Gemini 则是确认方案:
Image
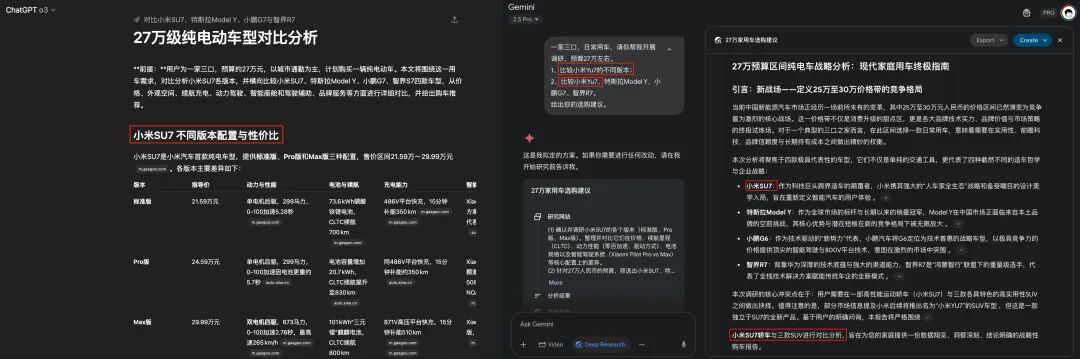
耐心等待半小时后,我们来看结果…诶…?桥豆麻袋,我明明问的 YU7,怎么 ChatGPT 和 Gemini 调研的都是 SU7 啊?
Image
这就很奇怪。唯一可能的解释是,ChatGPT 和 Gemini 的训练知识中只知道 SU7 不知道 YU7,所以以为 YU7 是我的笔误,自动把 YU7 纠正成了 SU7,好离谱。
我看了一下,Kimi 并没有犯同样的错误。而且我们可以从 Kimi 第一步的追问中发现线索:

Image
在还没有开始正式研究之前的确认步骤中,Kimi 就知道了 YU7 Pro 的定价以及主要功能,可以推测出出在请求用户补充信息的这这一步,Kimi 是进行了一次搜索的,也因而补充了基础的背景信息,所以不会犯低级错误。 而 ChatGPT、Gemini 在制定搜索方案的这一步应该并没有做类似的初始搜索,仅靠训练知识去推断,所以才会出现把用户询问的 YU7 篡改成 SU7 这么离谱的错误。
我本以为这会是一道送分题,没想到 ChatGPT 和 Gemini 直接把研究的主体都给搞错了,直接 0 分。我们只能抛开事实性错误,从字数和形式上比较一下:
深度研究 | 报告字数 | 结果呈现 |
|---|---|---|
Kimi | 10156 | 文本+可视化网页 |
ChatGPT | 19271 | 文本 |
Gemini | 9396 | 文本+手动 Create 应用 |
可以看出,Kimi 和 Gemini 的报告字数都在一万字左右,而 ChatGPT 则放飞自我,一口气写了两万字(的错误答案)。 但是反过来讲,现在的模型一口气写上万字也不奇怪,就像大家开玩笑说的,创作者在用 AI 扩写,读者在用 AI 摘要,报告越长,给读者带来的阅读负担也越重。
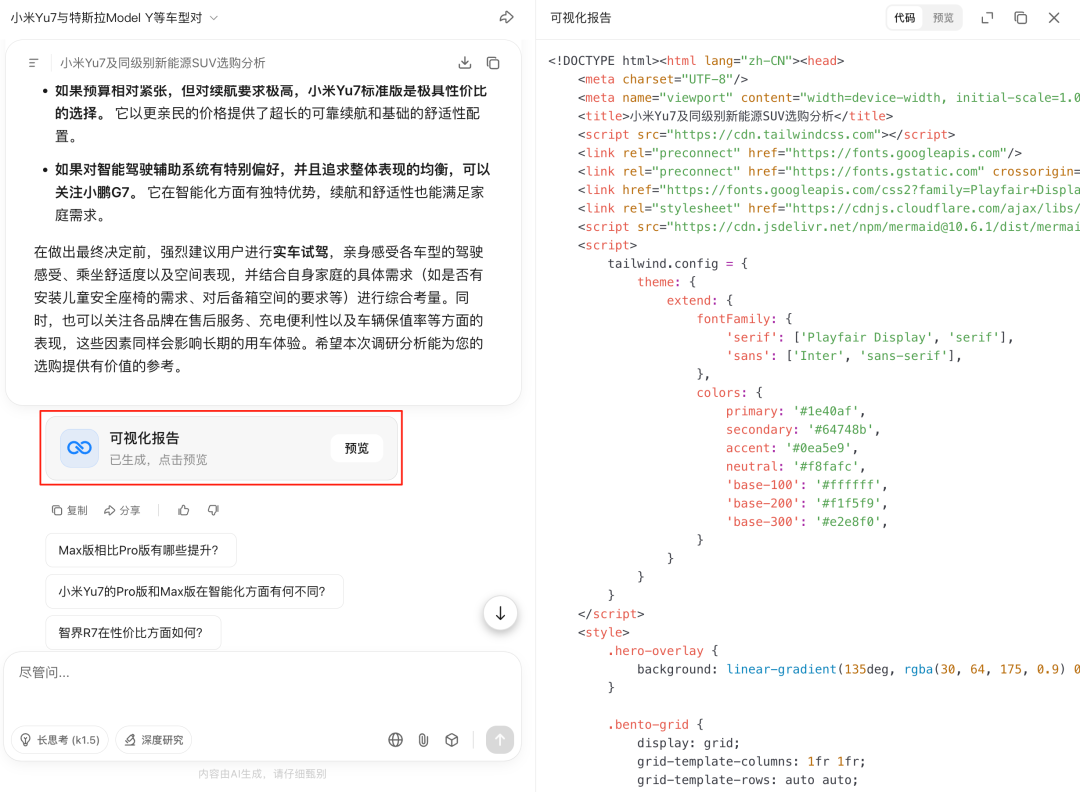
所以 Kimi 做得很巧妙的一点是,每次文字报告完成撰写后,都会自动编写网页代码,交付一份可视化报告。我看了一下,光是这份报告的代码,就有 1500 行。
Image
ChatGPT 并没有提供类似的功能,Gemini 则是一个手动的 Create 选项,但说实话,我很少用。
深度研究本身就极其消耗算力,Kimi 还把可视化报告作为一个默认功能,对用户是更友好的。可视化报告可以提供提供卡片、表格、思维导图等多种形式的信息呈现,用户获取信息更加简单有效。
比如直接呈现核心结论:

Image
再比如直观的横向比较:

Image
卡片式的信息呈现:

Image
从第一轮来看,Kimi 深度研究在偏日常的综合信息检索上的完成度还是不错的。
冷门知识检索
对于偏日常的话题,与其说是深度研究,不如说是广度检索,这些任务更偏向于横向收集信息的全面性,模型写出来的报告都会很完整详细,很难客观比较优劣。
为了比较深度研究能力,开发者就会尽可能找一些偏门冷门的题目刁难 AI,这些题目往往需要纵向的很多深度挖掘步骤才能得到答案。OpenAI 开源的 BrowseComp,红杉中国推出的 xbench-DeepSearch 就是这方面的测试集。
比如 BrowseComp 里的这个例子:
我正在寻找一位作家兼传记作家的笔名,这位作家著有多部作品,包括其自传。1980 年,他还为其父亲撰写了一部传记。这位作家爱上了一位哲学家的兄弟,该哲学家在家中排行第八。作家于 1940 年代离婚并再婚。
类似这种题目就不单单是「搜索广度」可以解决的,甚至可以说,这种题目让人去做,花几个小时搜不到正确答案也很正常,因为题目里的信息都很泛泛,需要串联起很多线索,综合分析比较,才能定位答案。
我从 BrowseComp 测试集了选了一道真题来测试。注意:为了避免泄漏题目,OpenAI 对题目进行了加密,并要求测试者不要在互联网公开分享题目。

Image
所以我这里只分享一下结果,这道题目要求检索一部冷门电影,给出了年代、时长、导演背景、编剧背景 4 条线索。
- • ChatGPT:答案正确,且 4 条线索全部验证。
- • Kimi:答案正确,3 条线索验证,其实编剧信息 Kimi 也搜到了,但少推理了半步,不过综合线索已经指向了唯一答案。
- • Gemini:答案错误,且认为题目是两部电影杂糅在一起编制的。
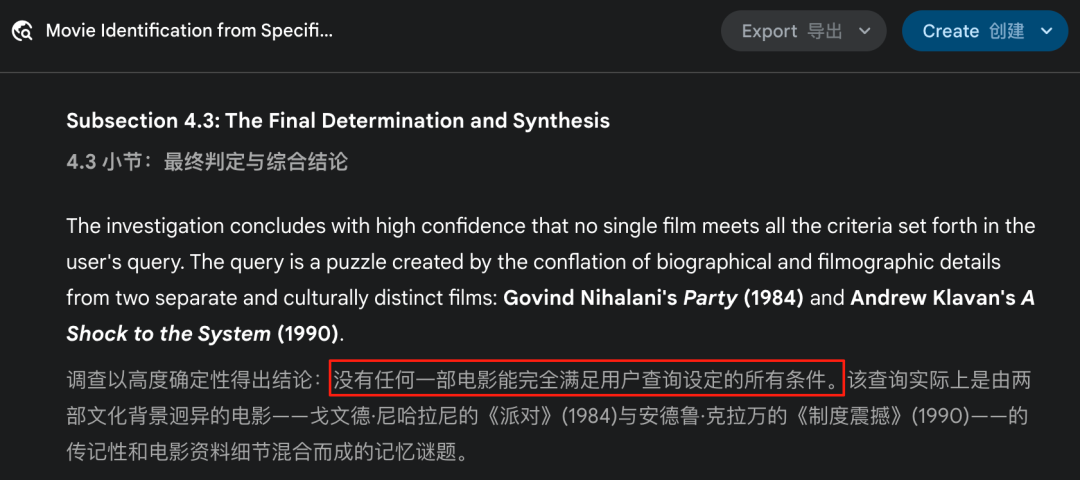
Image
顺便一提,这部电影冷门到在百度百科甚至没有词条,豆瓣上有词条但没有评分。Kimi 之所以能答对,是因为它可以访问到很多高质量的英文信源或官方网站:
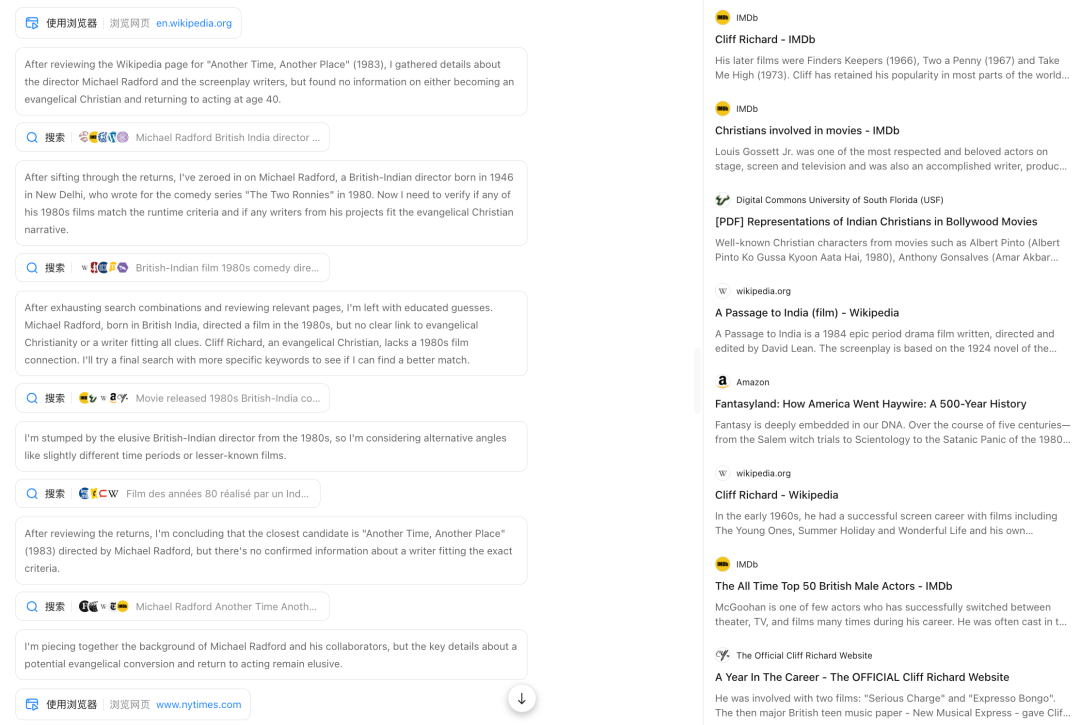
Image
总之,对于这种问题,一般的「AI + 搜索」或者「搜索 + AI」是很难答出的,而深度研究通过自主的规划大量的检索,在超长上下文能力的帮助下定位关键信息,Kimi 在这方面表现还不错。
撰写深度报告
最后再来比较一个报告撰写的案例吧。「稳定币」最近很火,所以我让 Kimi 和 ChatGPT 分别写了一篇稳定币的报告。这次我们让 Gemini 2.5 Pro 来做裁判,比较一下二者生成的报告质量。
结果是:Gemini 裁定 ChatGPT 胜出,并列出了详细的对比。

Image
从中还是可以看出 Kimi 的写作特点的,比如:
- • Kimi 的报告层级很深,但对于快速阅读不够友好(Kimi:那我要是多做一份可视化报告呢?)
- • ChatGPT 偏商务,Kimi 偏学术。
- • Kimi 对中国特定市场的分析独树一帜。
Gemini 最后也端水地评价了一句:
总结: 两位员工都非常出色,完成了高质量的工作。员工一更擅长撰写高层战略报告(Executive Report),而员工二更擅长进行深度专题研究(In-depth Research)。
不管怎么说,Kimi 的报告虽然没有获胜,但能和 ChatGPT 打个有来有回,也呈现出学术化、中国本土化的差异化特点,对用户来说是有价值的。
范式之争:端到端强化学习炼就「模型即 Agent」
Kimi 的公告中说,Kimi Researcher 是他们的「第一个 Agent」。站在 2025 年年中,Agent 的概念其实已经非常泛化了,或者说,只要是个做 AI 的,就敢说自己的产品是 Agent。
相比之下,Kimi 的技术路线坚定而纯粹,就是靠端到端的强化学习让模型具备 Agentic 能力。
作为从业者,我也跟很多人聊过一个问题:做一个 Agent,更重要的是模型,还是工程?
大多数人的答案其实是一半一半,原因很简单,模型并不是谁都训的起的,更难做的事情,显然会有更深的护城河。
大部分所谓的 Agent 企业,都在拿 AI API 做落地,套上一大堆 Prompt 和工程上的 trick。这样做当然没什么不对,API Wrapper 也是大模型产业的重要一环,做出了非常多优秀的产品。
但是,Workflow 工程做得再极致,天花板也会被模型能力卡住,只能期望于模型能力迭代。比如之前就有人说:Claude 3.5 出来之后,原来跑不通的 Agent,可以直接跑通了。而且依靠别家的模型去落地 Agent,也会遇到成本和供应商锁定的问题。
一个残酷的事实是:模型和工程并不是非此即彼、严格分工的。模型厂商是不会满足于卖 API 的,他们有能力、也有动机做出更强的模型,同时做出更强的应用落地。

Image
从卷预训练、多模态,到卷推理能力,当传统模型训练遇到数据墙,当 Scale law 遇到瓶颈,模型厂商们就自然会开始卷 Agent,于是今年开始兴起「模型即 Agent」,比如 OpenAI 的 o3,能够在推理过程中使用工具。
Kimi 同样选择了这条公认难度最大,同时潜力最大的路线:端到端强化学习。
所谓端到端强化学习,核心思想是放弃对过程的人工干预,只设定最终目标(奖励信号),让 Agent 在与环境(如搜索引擎、代码解释器)的海量交互中自主试错、探索和学习。模型需要自己学会规划、调用工具、处理信息、应对不确定性。
这种方法的理论上限极高,因为它不依赖于人类的先验知识,有可能发现人类未曾想到的更优解题路径。正如「The Bitter Lesson」所言:通用、可扩展的方法最终将战胜依赖人类领域知识的特定方法。
Kimi Researcher 的成功,验证了「模型即 Agent」范式可行,特别是模型涌现出自我修正、交叉验证的能力,证明模型可以在没有预设规则的情况下,通过强化学习自发形成有效策略。
小结
不知不觉写了快 4000 字,其实还有很多话题想聊,比如 Kimi 一直以来的长文本优势,比如 Kimi Researcher 提出的上下文管理,正好契合最近大家讨论的 Context Engineering,再比如数据飞轮和大规模 RL 工程问题等等。篇幅有限,感兴趣的可以去看一下 Kimi Researcher 的技术报告。
最后说一下我对 Kimi 的建议和期待吧:
- 1. 目前深度研究模式下还不支持上传文档,这应该不算什么太难的功能,但对用户来是有需求的,可以更简单直接地提供上下文供模型参考。更进一步,如果能让用户自定义主题知识库并使用 Researcher 参考知识库就更棒了。
- 2. 希望能接入更多高质量信源(比如论文库),同时提供分类和筛选的选项。更进一步,如果在能支持一些搜索语法,比如限定时间范围,指定或过滤某个网站就更好了,毕竟「写得好」的基础是「搜的对」,信源质量更高更可控也很重要。
当然,说再多都不如让大家能早点用上,希望 Kimi 能尽快结束内测,让更多用户能体验到基于国产模型的深度研究工具,也希望能早点开源 Kimi Researcher 模型,推动 Agent 在强化学习方向的探索。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号