先猜后验:四个Agent协作理解长视频,VideoMME三基准SOTA
原创
先猜后验:四个Agent协作理解长视频,VideoMME三基准SOTA
原创
CoovallyAIHub
发布于 2026-04-09 17:04:20
发布于 2026-04-09 17:04:20
导读
长视频理解一直面临一个核心矛盾:视频越长,冗余信息越多,模型越容易在海量帧中"迷路"。现有的Agent方法大多采用反应式检索——先搜索相关片段,再根据搜到的内容重新规划——这种试错循环不仅耗时,还容易让推理偏离正轨。
浙江工业大学、UC Berkeley和华东师范大学的研究团队提出了一个反直觉的思路:不急着去视频里找答案,而是先针对每个候选答案提出假设,再用视频证据逐一验证。VideoHV-Agent将这一"先猜后验"的思路落地为四Agent协作框架,在EgoSchema上达到81.0%、NextQA验证集80.7%、IntentQA 75.6%、VideoMME-L 60.6%,均为零样本SOTA,且推理速度快于同类Agent方法。
本文将拆解这套假设-验证框架的设计逻辑、四个Agent的分工协作机制、多基准实验表现以及消融实验揭示的关键组件。
论文信息
- 标题:Think, Then Verify: A Hypothesis-Verification Multi-Agent Framework for Long Video Understanding
- 作者:Zheng Wang, Haoran Chen, Haoxuan Qin, Zhipeng Wei, Tianwen Qian, Cong Bai
- 机构:浙江工业大学、UC Berkeley、华东师范大学
- 代码:https://github.com/Haorane/VideoHV-Agent
一、长视频理解为什么需要"先猜后验"?
长视频问答(VideoQA)的难度不只来自视频本身的长度和冗余,更来自问题的复杂性。论文指出,现有Agent框架存在两个根本问题:
第一,相关性驱动(correlation-driven)的规划方式。大多数方法将精力花在分解视频的复杂性——帧数、冗余度、细粒度信息——却忽略了问题本身的复杂性:多实体的组合约束、时序顺序、因果前提条件等。这意味着Agent可能找到了"相关"的片段,却没有真正回答问题。
第二,反应式检索(reactive retrieval)的推理模式。Agent反复搜索与当前计划相关的片段,根据找到的内容重新规划,形成昂贵的试错循环。更关键的是,这种模式不会明确检查所收集的证据是否真正支持或反驳候选答案。
VideoHV-Agent的核心思路是将推理顺序颠倒过来:不是先去视频里找答案,而是先思考"如果某个答案正确,视频中应该看到什么",然后有针对性地去验证。这就是论文所称的"thinking before finding"(先思考再查找)原则。
具体而言,框架将VideoQA重新构建为结构化的假设-验证过程(hypothesis-verification process),包含三个阶段:上下文摘要(Context Summarization)、两步推理(假设生成 + 假设验证),以及证据整合(Evidence Integration)。
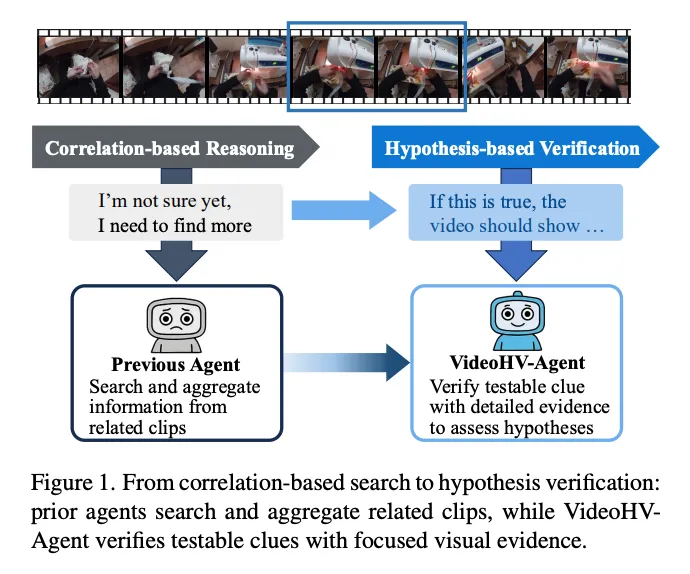
图片来源于原论文
二、四个Agent各司其职:Thinker → Judge → Verifier → Answer
VideoHV-Agent的核心架构由四个专职Agent组成,每个Agent只负责一个环节,形成清晰的流水线。
Thinker(思考者):将选项改写为可测试假设
Thinker接收问题、候选答案选项和视频摘要,将每个候选答案改写为一个可测试的假设(testable hypothesis)。假设需要明确指定:视频中什么必须为真,该选项才能成立——包括关键实体/对象、主要动作/事件、时间/因果关系。
Thinker还承担一个预过滤步骤:在生成假设之前,先排除明显不合理的选项,减少下游验证的噪声。
Judge(判断者):生成判别线索并评估区分度
Judge比较假设之间的核心差异(实体、动作、事件、因果/时序关系、视觉证据类型),提炼出一个判别线索(discriminative clue)κ——它精确指定需要在视频中检查什么证据。
Judge同时为线索分配一个0-1的区分度评分:0.7-1.0表示假设之间存在明确可测试的差异;0.4-0.6表示中等区分度;低于0.5则需要重新生成假设。这一机制确保验证阶段有明确的"靶心"可瞄准。
Verifier(验证者):定位、描述、判定
Verifier的工作分三步:
- 时间定位(Temporal Localization):利用帧级字幕定位线索最可能出现的时间窗口,将搜索范围从整段视频缩小到决定性片段。
- 细粒度描述(Detailed Captioning):对定位到的时间窗口内的原始帧调用GPT-4o提取详细描述(每次最多处理5帧),获取具体的视觉证据。
- 线索验证(Clue Verification):输出结构化验证状态——VERIFIED(线索被证实)、PARTIAL(部分证实,需补充证据)或NOT_VERIFIED(线索不成立,需重新生成假设)。
Answer(回答者):整合证据输出答案
Answer Agent整合所有验证结果,重新评估每个候选选项与证据的匹配度。如果多个假设被部分验证,它会推理哪个与整体上下文更一致;如果所有线索都未验证,则明确标注不确定性。最终输出附带完整推理链的答案。
双层自精炼循环
四个Agent之间并非单次流水线执行,而是通过两层循环实现自我修正:
- 大循环(Hypothesis-verification循环):当Verifier输出NOT_VERIFIED时触发,回到Thinker重新生成假设和线索。
- 小循环(Verification-only循环):当Verifier输出PARTIAL时触发,仅补充收集更多证据,不重走全流程。
重生成时有两种策略:特异性增强(Specificity Enhancement)使假设更具体可测试;判别力增强(Discriminability Enhancement)增加假设之间的语义对比度。
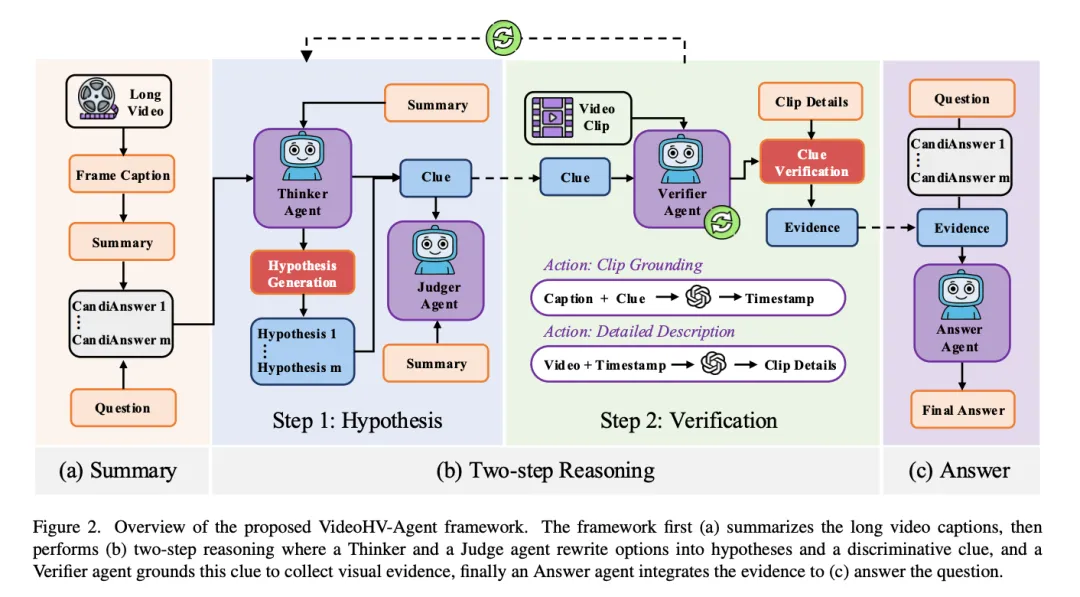
图片来源于原论文
三、实验:多个基准零样本SOTA
论文在四个基准数据集上进行了评估,所有Agent统一使用GPT-4o作为LLM backbone,帧采样率为1 fps。
EgoSchema:第一人称长视频推理
EgoSchema包含5,000道基于Ego4D的多选题,视频时长均超过3分钟。在500道公开验证集上:
方法 | 准确率(%) |
|---|---|
VideoAgent | 60.2 |
VideoTree | 66.2 |
LVNet | 68.2 |
LifelongMemory | 72.0 |
VideoMultiAgents | 75.4 |
VideoAgent2 | 80.6 |
VideoHV-Agent | 81.0 |
VideoHV-Agent以81.0%的准确率超越此前最优的VideoAgent2(80.6%),提升0.4个百分点。
NextQA:因果与时序推理
NextQA侧重日常视频中的因果和时序推理,验证集包含570视频、5,000个问题。
方法 | 验证集(%) | ATP-hard子集(%) |
|---|---|---|
SeViLA | 63.6 | 50.8 |
VideoAgent | 71.3 | 58.4 |
VideoMultiAgents | 79.6 | - |
VideoAgent2 | 80.5 | 68.2 |
VideoHV-Agent | 80.7 | 71.2 |
在ATP-hard子集上,VideoHV-Agent达到71.2%,比VideoAgent2的68.2%提升3.0个百分点——这一困难子集的提升幅度尤为显著,说明假设-验证范式在复杂因果推理场景下优势更大。
IntentQA:行为意图理解
IntentQA评估模型对视频角色行为意图的理解能力:
方法 | 准确率(%) |
|---|---|
IG-VLM | 65.3 |
VideoTree | 66.9 |
ENTER | 71.5 |
VideoINSTA | 72.8 |
VideoAgent2 | 73.9 |
VideoHV-Agent | 75.6 |
VideoHV-Agent以75.6%超越VideoAgent2(73.9%),提升1.7个百分点。
VideoMME-L:超长视频理解
VideoMME-L的平均视频时长达到2466.7秒(约41分钟),在同一LLM backbone(GPT-4o)下:
方法 | 准确率(%) |
|---|---|
CoT | 46.7 |
VideoTree | 54.2 |
VCA | 56.3 |
VideoHV-Agent | 60.6 |
相比CoT基线提升13.9个百分点,相比VCA提升4.3个百分点。
效率优势
在EgoSchema上,与其他Agent方法的推理时间对比:
方法 | 推理时间(s) | 准确率(%) |
|---|---|---|
VideoHV-Agent | 123.66 | 81.0 |
VideoAgent | 129.46 | 60.2 |
VideoMultiAgents | 134.90 | 75.4 |
VideoTree | 160.21 | 66.2 |
VideoHV-Agent在准确率最高的同时,推理时间也是最短的(123.66秒)。更值得关注的是框架的可扩展性:视频时长从NextQA的39.5秒增长到VideoMME-L的2466.7秒(增长62倍),推理时间仅从74.48秒增长到181.82秒(增长2.4倍)。这得益于摘要阶段将帧字幕压缩为紧凑摘要,避免了随帧数线性增长的开销。
四、消融实验:验证状态移除降幅最大(-7%)
消融实验在EgoSchema上进行,逐一移除框架的关键组件:
消融条件 | 准确率(%) | 相对完整框架下降 |
|---|---|---|
去掉假设生成(w/o hypothesis) | 76.0 | -5.0 |
去掉线索生成(w/o clue) | 78.6 | -2.4 |
去掉验证状态(w/o verification status) | 74.0 | -7.0 |
完整框架 | 81.0 | 基准 |
验证状态机制的移除导致了最大降幅(-7.0个百分点)。验证状态(VERIFIED / PARTIAL / NOT_VERIFIED)是触发自精炼循环的开关——没有它,框架无法判断何时需要重新生成假设、何时需要补充证据,自适应能力被完全剥夺。这证明验证状态是框架中功能性必需的组件,而非装饰性设计。
假设生成的移除造成第二大降幅(-5.0个百分点)。去掉假设后,系统直接从原始选项差异导出线索,丢失了将选项结构化为"关键事件 + 实体 + 因果关系"的能力,下游推理缺少了清晰的锚点。
线索生成的移除影响相对较小(-2.4个百分点),但仍可观。线索将高层假设转化为具体的视觉检查指令,去掉它会削弱验证阶段的聚焦性。
循环次数的影响
论文还分析了自精炼循环次数的影响。实际运行数据显示,73.28%的样本仅需1轮大循环即可得到正确答案,仅13.81%需要2轮,12.91%需要3轮。小循环中,87.19%的样本只需1轮。这说明框架在大多数情况下能一次命中关键信息,额外循环只在确有需要时才被触发。
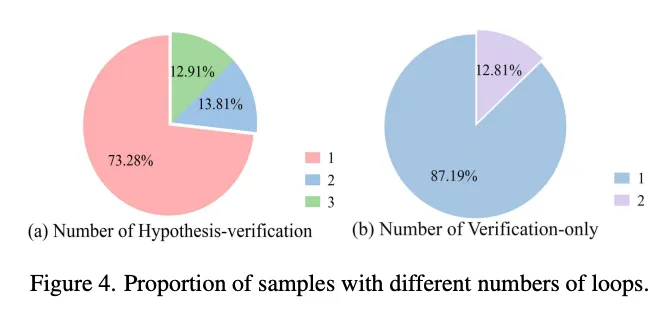
图片来源于原论文
五、总结与思考
VideoHV-Agent将长视频问答从"在视频中搜索答案"转变为"先为每个候选答案建立假设,再用视频证据验证"。四个Agent分工明确——Thinker构建假设、Judge提炼线索、Verifier定位验证、Answer整合推理——配合双层自精炼循环,在EgoSchema、NextQA、IntentQA和VideoMME-L四个基准上均达到零样本SOTA,同时推理效率优于同类Agent方法。
在此基础上,有几点值得进一步思考。首先,框架目前仅在多选题场景下验证,开放式问答中假设的构造方式需要重新设计。其次,四个Agent均依赖GPT-4o,论文附录的控制实验显示GPT-3.5 backbone下增益达+15.8%,说明架构贡献大于模型能力,但更轻量的开源LLM能否支撑同样的流程仍待验证。此外,验证状态的三级判定(VERIFIED / PARTIAL / NOT_VERIFIED)是否可以进一步细化,以减少不必要的大循环触发,也是一个可优化的方向。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号