palantir深度解析(五)
原创

Foundry 分支核心考点·一页速记
- 主分支:生产环境用
master - 个人分支:一人一个,防止覆盖、冲突
- Commit(提交):每一次代码/数据改动的存档记录
- 提审流程:改完 → 发起 PR(拉取请求) → 审核 → 合并
- 数据集分支特点
- 本质是指向最近一次事务的指针
- 支持回溯历史,不支持合并(和 Git 最大区别)
6.分支删除规则- 删中间分支,子分支会自动挂靠到它的父分支
7.读写安全- 构建只写当前分支,不会修改 master
8.查找机制(回退链 fallback chain)- 先读自己分支 → 找不到 → 往上找父分支/master
9.设计目的- 安全开发测试,不污染、不破坏主分支数据
Palantir Foundry 分支体系
这份文档是Foundry企业级数据开发多人协作、版本控制、生产环境稳定性保障的核心规则手册。它将软件开发领域Git的成熟分支管理思想,完整适配到数据开发领域,彻底解决了企业级数据开发的核心痛点:多人同时修改同一条数据流水线、同一个数据集时,如何实现互不干扰的安全协作,同时严格保障生产环境的稳定性。
它和你之前学习的「数据集事务」「Code Repositories」「Pipeline Builder」「构建应用」完全打通,是Foundry数据DevOps流程、团队协作的核心基础设施。
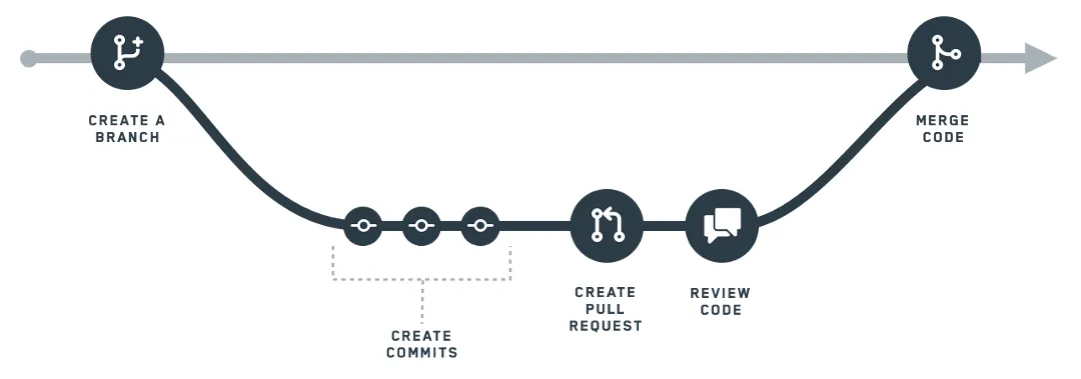
一、分支的核心定位与设计思想
Foundry分支的核心设计逻辑:用软件开发人员管理代码的方式管理数据。
- 传统软件开发中,Git分支解决了「多人同时修改同一份代码,互不干扰、安全合并」的问题;
- 在Foundry中,分支把这套能力完整复制到了数据开发领域,让多人可以同时对同一条数据流水线、同一个数据集做修改、实验、测试,全程不会影响生产环境的稳定运行。
从高层视角看,分支的核心逻辑非常简单:
- 你在自己的独立分支上完成数据变换、流水线修改,全程和生产环境隔离;
- 测试验证通过后,通过审核流程,把你的改动安全合并回生产主分支。
二、分支标准工作流
1. CREATE A BRANCH(创建分支)
核心定义
master分支是生产环境主分支,对应线上稳定运行的流水线、对外提供服务的数据集,是整个团队的唯一数据真值来源。
创建分支,就是从master分支拉取一个完全独立的「副本沙箱环境」,你在这个分支里的所有修改,都只会作用于当前分支,绝对不会影响master主分支,也不会和其他同事的修改冲突。
核心价值
给你一个无风险的实验环境,你可以随意修改流水线、调整数据逻辑、测试新功能,完全不用担心搞崩生产环境,也不会打断其他同事的开发工作。
平台对应操作
在Pipeline Builder/Code Repositories的分支下拉框中,点击「创建新分支」,输入分支名(规范命名如feature/年报分析流水线、fix/用户数据去重逻辑)即可完成创建。
2. CREATE COMMITS(创建提交)
核心定义
在你的分支中,对流水线、数据变换做的每一次有效修改(比如新增一个清洗算子、修改一行SQL代码、调整数据集Schema),都可以打包成一个提交(Commit)。 每个提交都有唯一标识、修改人、修改时间、完整的修改内容记录,会形成线性的、可追溯的版本历史。
核心价值
你的每一步改动都有完整记录,出了问题可以随时回滚到之前的稳定版本,同时团队可以清晰看到你对流水线做的所有改动,方便后续审核。
平台对应操作
Pipeline Builder中点击Save保存修改、Code Repositories中点击Commit提交代码,都会生成对应的提交记录。
3. CREATE PULL REQUEST(创建拉取请求,简称PR)
核心定义
当你在分支中完成了开发、测试,确认修改逻辑无误、数据结果符合预期,想要把改动合并到master主分支时,就需要创建一个PR。
它本质是给团队发送的「合并申请」,告知团队:我对流水线做了这些修改,已经完成测试验证,请大家审核,没问题的话可以合并到生产环境。
核心价值
把「开发测试」和「生产上线」完全拆分开,强制增加审核环节,避免未经验证的改动直接上线,从流程上保障生产环境的稳定性。
4. REVIEW CODE(代码/流水线审核)
核心定义
PR创建后,团队负责人、资深工程师会对你的提交做交叉审核:检查修改逻辑是否合理、有没有数据质量风险、会不会影响下游依赖、是否符合合规要求。不同企业有不同的审核规范,通常需要1-2个审批人通过,才能进入合并环节。
核心价值
通过多人交叉验证,提前发现潜在问题,保障生产流水线的质量,同时实现团队的知识共享与规范落地。
5. MERGE CODE(合并代码)
核心定义
审核通过后,将你的分支中的修改,正式合并到master主分支中。合并完成后,你的改动会在生产环境生效,master分支的流水线逻辑、数据集会更新为你修改后的版本。
核心价值
完成整个开发-测试-审核-上线的闭环,把经过验证的改动,安全地同步到生产环境。
【官方最佳实践·避坑提醒】
文档中特别强调:强烈建议每个人使用独立的分支,禁止多人在同一个personal分支上协作开发。 Foundry的分支实现了行业标准的类Git版本控制模式,设计为「每个文件的单个分支,同一时间只有一个活跃开发者」。如果多人在同一个分支上修改,彼此的改动会被覆盖,导致代码丢失、逻辑冲突。
三、分支的底层技术实现
文档中明确了Foundry的分支能力,是通过两个层级的功能共同实现的,二者是递进关系:
- 数据集分支:底层基础,实现数据层面的版本隔离与控制;
- 构建中的分支:上层应用,实现「流水线逻辑+数据版本」的联动隔离,也是你日常开发中直接使用的能力。
(一)数据集分支(Dataset Branching)
这是Foundry分支能力的底层基础,完全基于你之前学习的数据集事务实现。
1. 核心定义(与Git类比,快速理解)
Git概念 | Foundry数据集对应概念 | 核心本质 |
|---|---|---|
Git仓库(Repository) | 数据集(Dataset) | 版本管理的主体 |
Git分支(Branch) | 数据集分支 | 指向最新提交/事务的指针 |
Git提交(Commit) | 数据集事务(Transaction) | 单次修改的原子性记录 |
核心本质:数据集分支,只是一个指向该分支上最新事务的指针。它不是把整个数据集完整复制了一份,只是一个轻量的指针,因此创建分支的成本极低,不会占用额外存储。
举个直观的例子:
master分支的指针,指向生产环境最新的事务;- 你从
master创建feature分支,初始时feature的指针和master指向同一个事务; - 你在
feature分支提交新事务,feature的指针会向前移动,而master的指针原地不动,两个分支完全独立、互不影响。
2. 与Git的核心差异(极易混淆,重点注意)
特性 | Git分支 | Foundry数据集分支 |
|---|---|---|
分支合并 | 支持两个分支的代码合并,可解决冲突 | 不支持数据集分支的合并 |
核心用途 | 代码的协作合并 | 数据的版本隔离与历史追溯 |
这里必须澄清一个关键误区:你在PR里合并的是流水线的代码/逻辑,不是数据集分支本身。
合并逻辑后,系统会在master分支上运行构建,生成新的事务,而不是把两个数据集分支直接合并。这个设计是为了保证数据的一致性,避免数据集合并带来的冲突、数据错乱问题。
3. 父分支与根分支
- 根分支:没有父分支的分支,绝大多数场景下,
master分支就是唯一的根分支,是所有子分支的源头; - 父分支:创建子分支时基于的分支,就是父分支。比如从
master创建feature分支,master就是feature的父分支; - 分支重挂靠规则:如果删除了一个有子分支的「中间分支」,子分支不会被删除,会自动把父分支修改为原来的祖父分支。比如
feature的父分支是develop,develop的父分支是master,删除develop后,feature的父分支会自动变为master,整个过程不会改动任何事务,仅修改分支的祖先记录。
4. 数据集分支支持的核心操作
文档中列出了数据集分支的4个底层原子操作,上层应用均基于这些能力封装:
- 创建根分支:创建无父分支、无初始事务的空分支;
- 创建子分支:从已有分支/已有事务创建新分支,新分支初始指针与父分支一致;
- 在分支上开启新事务:启动事务,并将分支指针移动到这个新事务上;
- 删除分支:仅删除分支的指针,不会删除分支上的任何事务,保证历史版本永远可追溯,不会因删除分支丢失数据。
5. 数据集分支的核心保证(底层强制硬规则)
这是Foundry保障数据一致性、避免冲突的底层铁律:
- 单分支单开放事务:每个分支同时最多只能有1个开放(未提交/中止)的事务,且这个事务一定是分支上的最新事务。避免同一分支同时有多个修改,导致冲突;
- 单分支事务严格有序:同一个分支内的事务,严格按开启/提交时间线性排序,保证版本历史清晰可追溯;但不同分支之间的事务,没有时间顺序的保证;
- 非根分支必有父分支:所有子分支都有明确的父分支,删除中间分支时会自动重挂靠,不会出现无主分支,保证分支树的完整性。
(二)构建中的分支(Branching in Builds)
这是Foundry分支能力的核心价值所在,它解决了传统数据开发的致命痛点:代码(流水线逻辑)与数据版本脱节。 传统场景中,经常出现「代码改了,但用的还是旧版本数据」「代码回滚了,数据没回滚」的不一致问题。而Foundry的构建分支,把「Git中的代码逻辑分支」和「数据集的数据分支」完全绑定,实现了逻辑与数据的版本联动、全环境隔离。
1. 核心定义
你在Code Repositories中编写的流水线代码,存储在Git分支中;流水线生成的数据集,存储在数据集分支中。Foundry的构建系统,将这两个分支1:1绑定: 每一次构建,都只会在你指定的分支上运行,构建内的所有任务,只会修改该分支上的数据集,绝对不会触碰其他分支的任何数据。
简单说:你在feature分支运行构建,所有计算、数据写入,都只在feature分支的数据集里生效,master分支的数据集、流水线完全不受影响,实现了100%的环境隔离。
2. 构建分支的两个核心核心流程
文档中拆解了构建运行时,分支处理的两个核心步骤,这是构建系统的底层逻辑:
① 任务图编译(Task Graph Compilation)
- 核心逻辑:当你在分支中提交代码时,系统会把你的流水线逻辑打包成JobSpecs(任务规范),发布到对应分支的构建系统中。当你在该分支运行构建时,系统会遍历分支上的所有JobSpecs及其依赖关系,生成完整的任务执行DAG图(也就是你在构建应用中看到的任务流水线)。
- 关键能力:分支回退链(Branch Fallback)
你可以为构建配置回退链,比如
feature → master。它的含义是:如果当前构建分支上没有某个数据集的JobSpec(也就是你没修改这个数据集的生成逻辑),系统会自动从回退链的下一个分支(master)读取该JobSpec,使用生产环境的逻辑处理该数据集。 举个例子:你的流水线是A→B→C,你只修改了B和C的逻辑,没改A。在feature分支运行构建时,A的逻辑会从master分支读取,直接使用master分支的A数据集作为输入,只重新计算B和C并写入feature分支。既保证了环境隔离,又避免了全量重新计算,大幅节省计算资源。 - 补充细节:数据集图标的颜色由JobSpec决定——蓝色=master分支上有该数据集的JobSpec(有生产逻辑);灰色=master分支上没有该数据集的JobSpec。
② 输入和输出解析(Input & Output Resolution)
这是构建分支保障隔离性的核心规则,文档中做了明确的强制约定:
- 输出规则:构建中所有任务要输出的数据集,都会在构建分支上开启事务。如果该数据集在构建分支中不存在,会从回退链的第一个分支创建,或创建为根分支。所有输出只会写入构建分支,绝对不会写入其他分支。
- 输入规则:任务的输入数据,优先从构建分支读取;如果构建分支中没有该输入数据集,会从回退链中第一个存在该数据集的分支读取。
- 核心隔离保证:构建绝对不会修改除「构建分支」以外的任何数据集分支,也不会为输入数据集创建新分支,彻底保证生产环境数据的稳定性和安全性。
3. 官方示例拆解(直观理解分支构建全流程)
文档中的示例是最经典的分支开发场景,我们做分步拆解,让你清晰理解整个过程:
前提:master分支上已有完整流水线 数据集A → 数据集B → 数据集C,有对应的JobSpec和全量生产数据。
- 数据工程师在Code Repositories中创建名为
feature的分支,底层Git仓库同步创建对应分支,初始状态与master完全一致。 - 工程师修改了生成数据集B和C的代码,提交代码后,系统将B和C的新JobSpec发布到
feature分支,A的JobSpec在feature分支上无修改,仍沿用master分支的版本。 - 工程师在
feature分支启动构建,配置的回退链为feature → master。 - 构建系统编译任务图:读取feature分支上B和C的JobSpec,A的JobSpec从master分支读取,生成执行任务:先计算B,再计算C。
- 任务串行执行:
- 任务1(生成B):输入数据集A,优先找feature分支的A,不存在,自动读取master分支的A数据集;计算完成后,将结果写入feature分支的B数据集,提交事务。master分支的B数据集完全无变化。
- 任务2(生成C):输入数据集B,优先找feature分支的B,已存在,使用刚计算完成的feature分支的B;计算完成后,将结果写入feature分支的C数据集,提交事务。master分支的C数据集完全无变化。
- 所有任务执行成功,构建完成。
最终结果:feature分支上生成了新的B、C数据集,工程师可在分支内验证结果;master分支的A、B、C完全不受影响,生产环境稳定运行。
4. 构建分支的核心保证(底层强制硬规则)
- 只有当分支回退链,与涉及的数据集的分支祖先兼容时,构建才能解析成功,避免逻辑与数据版本不匹配的问题;
- 构建绝对不会修改除「构建分支」以外的任何数据集分支,也不会为输入数据集创建分支,彻底保障生产环境的隔离性与安全性。
四、分支体系与之前学习内容的联动
Foundry的分支能力,和你之前学习的所有核心组件完全打通,形成了完整的开发闭环:
- Code Repositories:基于Git分支管理流水线代码,提交代码时发布JobSpec到对应分支;
- Pipeline Builder:可视化操作分支,保存修改生成提交,运行构建在对应分支生成数据;
- 构建应用:执行分支上的构建任务,处理JobSpec,生成对应分支的数据集;
- 数据集预览:切换分支,查看不同分支的数据集视图、事务历史、元数据;
- 数据健康:监控不同分支的数据集健康状态、同步情况;
- 数据沿袭:查看不同分支上,数据集的上下游依赖与血缘关系。
五、核心价值总结
Foundry的分支体系,真正实现了数据开发的DevOps化,为企业级数据开发提供了三大核心能力:
- 安全隔离:开发测试与生产环境完全隔离,未经审核的改动绝对不会影响生产稳定;
- 多人协作:多人可同时在独立分支开发,互不干扰,解决了数据开发的协作冲突问题;
- 全链路可追溯:从代码提交、数据修改、审核合并到生产上线,全流程有完整的版本记录,可追溯、可回滚,满足企业合规与审计要求。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
原创声明:本文系作者授权腾讯云开发者社区发表,未经许可,不得转载。
如有侵权,请联系 cloudcommunity@tencent.com 删除。
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号