Jason Wei 最新演讲:关于 AI,你需要理解三个核心思想


上周,斯坦福大学 AI 俱乐部邀请了一位重量级嘉宾——Jason Wei。
如果你关注 AI 领域,这个名字一定不陌生。Jason Wei 目前在 Meta Superintelligence labs 担任研究科学家。此前,他在 OpenAI 参与了 o1 模型和 Deep Research 产品的创建,更早之前,他在 Google Brain 工作期间,他的研究推动了「思维链」(Chain of Thought) 和「指令微调」等关键技术的发展。他的论文引用次数超过 9 万次,是当今 AI 领域最具影响力的研究者之一。
在这次演讲中,Jason 提出了他认为在 2025 年理解和驾驭 AI 发展的三个核心思想。这些思想非常深刻,但又足够简单,可以作为我们普通人思考 AI 未来走向的思维框架。
Jason Wei at Stanford AI Club
今天,我想结合 Jason 的演讲内容,详细解读这三个思想。它们分别是:

- 1. 智能正在成为一种商品 (Intelligence as a Commodity)
- 2. 验证者法则 (Verifier’s Law)
- 3. 智能的锯齿状前沿 (The Jagged Edge of Intelligence)
一、智能的商品化:成本趋近于零
我们常常讨论 AI 会如何改变世界,但不同的人给出的答案天差地别。Jason 的一位量化交易员朋友认为,ChatGPT 虽然很酷,但在他的实际工作中几乎派不上用场。而另一位顶级 AI 实验室的研究员则悲观地表示,他们可能只剩下两三年的工作时间,之后就会被 AI 取代。

这种巨大的分歧,根源在于对 AI 能力发展速度和成本变化的理解不同。Jason 的第一个观点是:智能,或者说获取知识和进行推理的能力,正在迅速商品化,其成本和获取门槛正趋向于零。
AI 进展的两个阶段
Jason 认为,AI 的发展可以分为两个阶段。
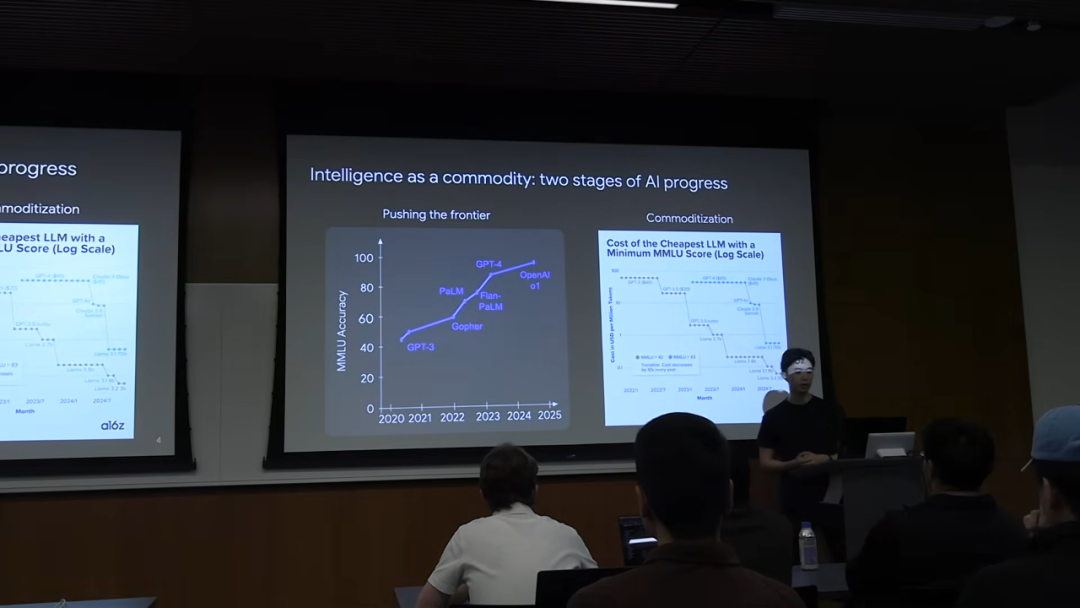
- • 第一阶段:前沿突破。 在这个阶段,AI 还无法很好地完成某项任务,研究人员的目标是「解锁」这项新能力。比如,我们可以看到过去五年,各大模型在
MMLU(大规模多任务语言理解) 这个通用基准测试上的性能是逐步提升的。 - • 第二阶段:能力商品化。 一旦某项能力被解锁,它的成本就会开始急剧下降。Jason 展示了一张图表,纵坐标是时间,横坐标是达到特定
MMLU分数所需的计算成本(美元)。趋势非常明显:每过一年,获得同等智能水平的模型的成本都在大幅降低。
这个趋势会持续下去吗?Jason 的答案是肯定的,而背后的核心驱动力,是一种在深度学习历史上第一次真正奏效的技术:自适应计算 (Adaptive Compute)。
自适应计算:成本下降的核心驱动力
在去年之前,深度学习领域的主流范式是「固定计算」。无论问题是简单(例如「加州的首府是哪里?」)还是复杂(例如一道高难度的数学竞赛题),模型在推理时消耗的计算资源基本是固定的。
但现在,我们进入了「自适应计算」的时代。模型可以根据任务的难度,动态地调整计算资源的使用量。
这个概念的首次大规模展示,是 OpenAI 一年多前发布的 o1 模型。研究表明,在解决数学问题时,如果在测试阶段投入更多的计算量,模型的性能就会相应提高。
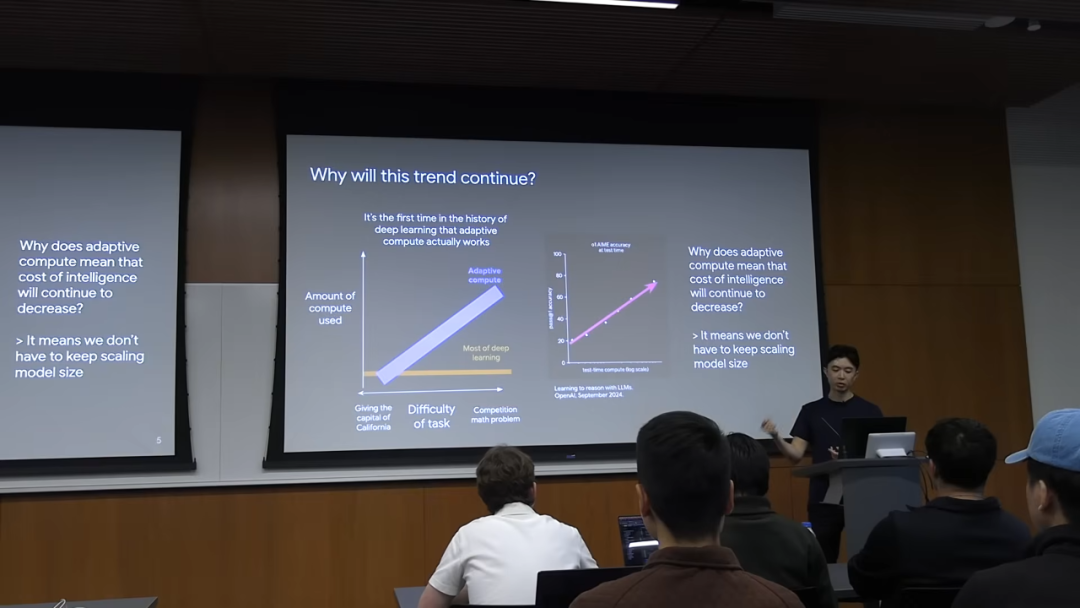
自适应计算的意义在于,它打破了「模型规模决定智能上限」的僵局。对于简单任务,我们可以用极小的计算资源来完成,从而将成本推向极限。你不必为了回答一个简单问题而去运行一个万亿参数的庞然大物。这使得智能的「单位成本」可以持续下降。
知识获取的「零时差」时代
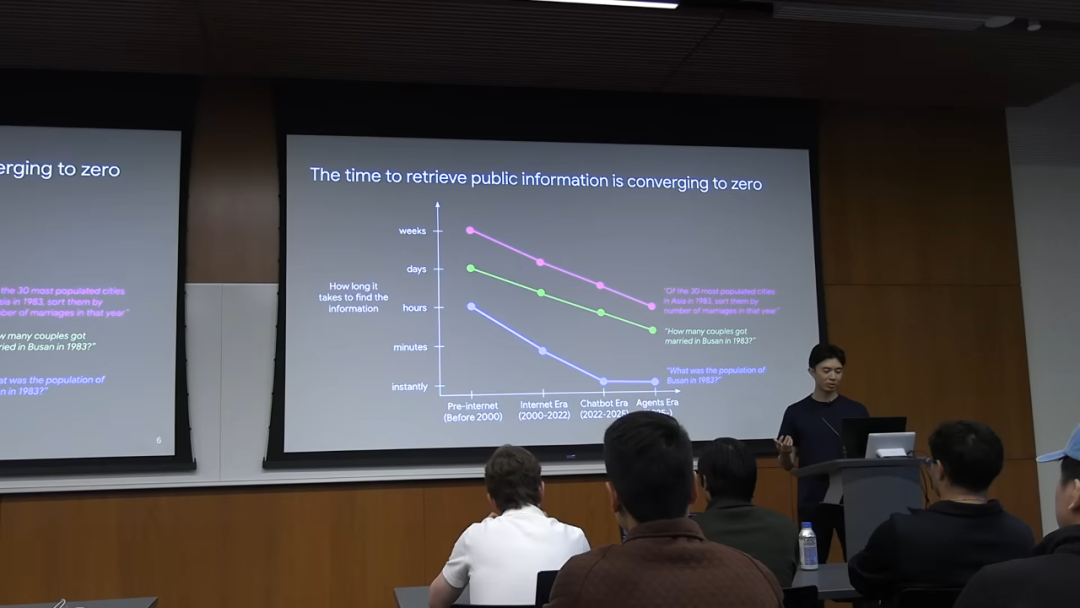
智能商品化的另一个体现是获取公共信息的时间成本急剧下降。Jason 用一个例子说明了这一点:
假设你想知道「1983 年韩国釜山的人口是多少?」
- • 前互联网时代:你可能需要开车去图书馆,翻阅大量的百科全书或年鉴,花费数小时。
- • 互联网时代:你可以用搜索引擎,浏览几个网页,找到答案,可能需要几分钟。
- • 聊天机器人时代:你直接提问,答案几乎是瞬时的。
现在,我们把问题变得更难一些:
「1983 年在釜山有多少对新人结婚?」
这个问题的信息更加隐蔽。在前互联网时代,你可能需要飞到韩国,去政府档案馆查阅几十本卷宗,这可能需要几天甚至几周。在互联网时代,你可能需要懂韩语,在特定的政府数据库网站上进行复杂的查询。
但在今天的「AI 智能体」(Agents) 时代,这个问题可以在几分钟内解决。Jason 提到,GPT-3 无法回答这个问题,但 OpenAI 的内部研究工具 Operator 可以。它能够自动访问韩国统计信息服务 (KOSIS) 数据库,通过多次点击和尝试,构建正确的查询语句,最终找到答案。
为了衡量这种能力,OpenAI 内部创建了一个名为 BrowseComp 的基准测试。这些问题通常答案一旦找到就很容易验证,但寻找过程却非常耗时。例如,根据一系列复杂的约束条件,找到一场特定的足球比赛。测试结果显示,人类解决这些问题平均需要超过两个小时,而且很多问题人类在两小时内根本无法完成。而 OpenAI 的 Deep Research 模型已经能解决其中近一半的问题。

启示与影响
智能商品化将带来深远的影响:

- 1. 领域的民主化:过去因知识壁垒而门槛很高的领域,将被大大拉平。编程是一个典型例子,现在人人都可以借助 AI 成为开发者。个人健康也是如此,你可以通过 AI 获取专业医生水平的建议,进行个性化的健康实验。
- 2. 私有信息价值提升:当所有公共信息的获取成本都降为零时,那些未公开的、内部的、私有的信息(比如市场上未挂牌的房源信息)的相对价值将急剧上升。
- 3. 个性化信息流:未来我们访问的可能不再是千人一面的公共互联网,而是为每个人量身定制的「个性化互联网」。你关心的一切信息,都会以最适合你的方式呈现。
二、验证者法则:AI 的能力边界由可验证性决定
Jason 提出的第二个核心思想,是一个他称之为「验证者法则」(Verifier’s Law) 的规律。这个法则可以帮助我们预测哪些任务会最先被 AI 攻克。
不对称的验证成本
在计算机科学中,有一个著名的概念叫「验证与求解的不对称性」(类似 P vs NP 问题),即验证一个解是否正确,通常比找到这个解要容易得多。
Jason 列举了一些例子,来帮助我们理解这种不对称性在现实世界中的体现:

第一类情况:易于验证,难于求解,比如:
数独:求解一个复杂的数独可能需要很长时间,但验证一个填好的数独是否正确,只需几秒钟。
编写或测试代码:构建并运行整个 Twitter 的后端系统需要数千名工程师,但验证这个网站是否正常工作,只需要打开浏览器点几下。
第二类情况:验证与求解难度相当,比如:
数学竞赛题:对于某些证明题,验证答案的过程几乎等同于重新推演一遍解题过程。
第二类情况:难以验证,易于求解 (生成),比如:
- • 编写数据处理脚本:自己写一个脚本来处理数据可能很快,但要去验证别人写的混乱脚本是否完全正确,可能比自己重写一遍还要花时间。
- • 撰写一篇事实性文章:AI 可以轻易地生成一篇看起来很有道理、充满事实陈述的文章。但要逐一核实其中每一个信息的准确性,却是一项极其繁琐和耗时的工作。
- • 提出一种新的饮食理论:一个人只花 10 秒钟就能随意宣称「只吃野牛是最好的饮食方式」。但要科学地验证这个说法的真伪,需要大规模的样本、长期的跟踪观察,并且结果还可能充满噪音。
我们可以将不同的任务放置在一个坐标系中,X 轴是「生成难度」,Y 轴是「验证难度」。数独和网页代码位于「难生成,易验证」的象限,而饮食理论则位于「易生成,难验证」的象限。
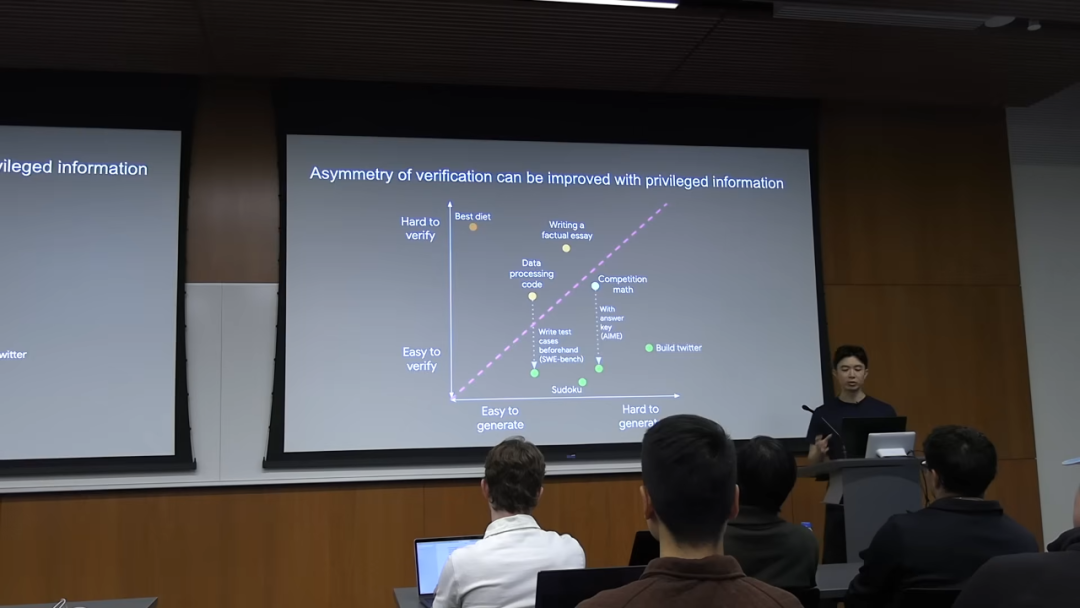
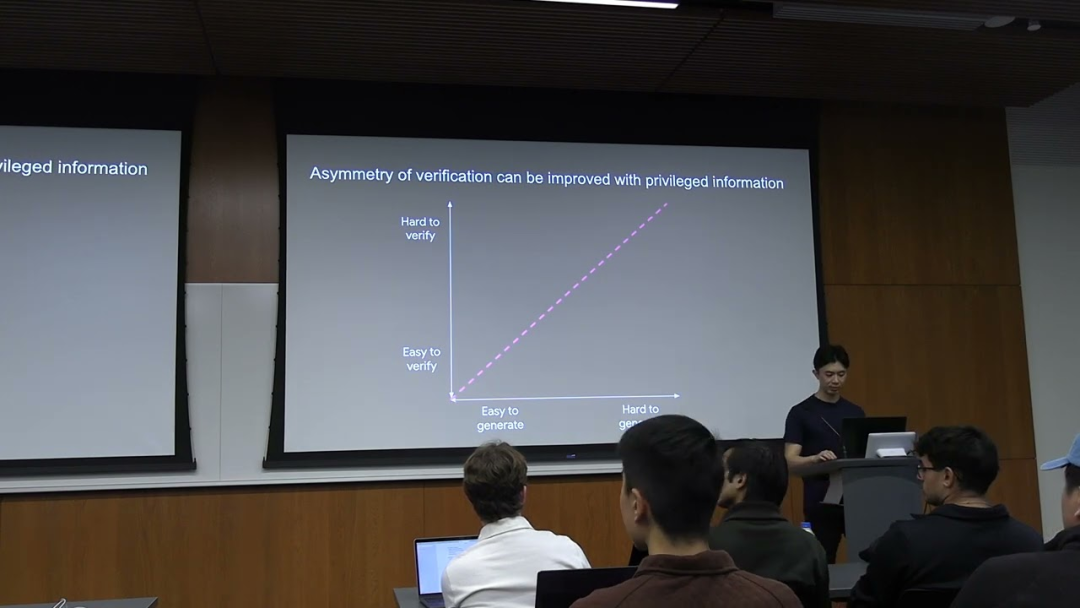
一个有趣的点是,我们可以通过提供「特权信息」(privileged information) 来改变一个任务的验证难度。比如,对于数学题,如果提供了答案和解题步骤,验证就变得非常容易。对于代码,如果提供了完整的测试用例,验证也变得轻而易举。
验证者法则:可验证性决定了 AI 的能力边界
基于上述观察,Jason 提出了他的核心论断,即验证者法则:
训练 AI 解决某个任务的能力,与该任务的可验证性成正比。任何可解的、且易于验证的任务,最终都将被 AI 攻克。
一个任务的「可验证性」高低,取决于五个因素:
- 1. 客观性 (Objective Truth):是否存在一个明确的、客观的正确答案?
- 2. 速度 (Fast):验证一个答案需要多长时间?
- 3. 可扩展性 (Scalable):能否同时快速验证数百万个不同的提议解?
- 4. 低噪音 (Low Noise):每次验证得到的结果是否一致?
- 5. 连续奖励 (Continuous Reward):评价体系是二元的(通过/不通过),还是能提供一个连续的分数来衡量解的优劣?

我们日常见到的大多数 AI 基准测试,其本质就是高度可验证的任务。这也就解释了为什么 AI 在这些 benchmark 上的表现突飞猛进。
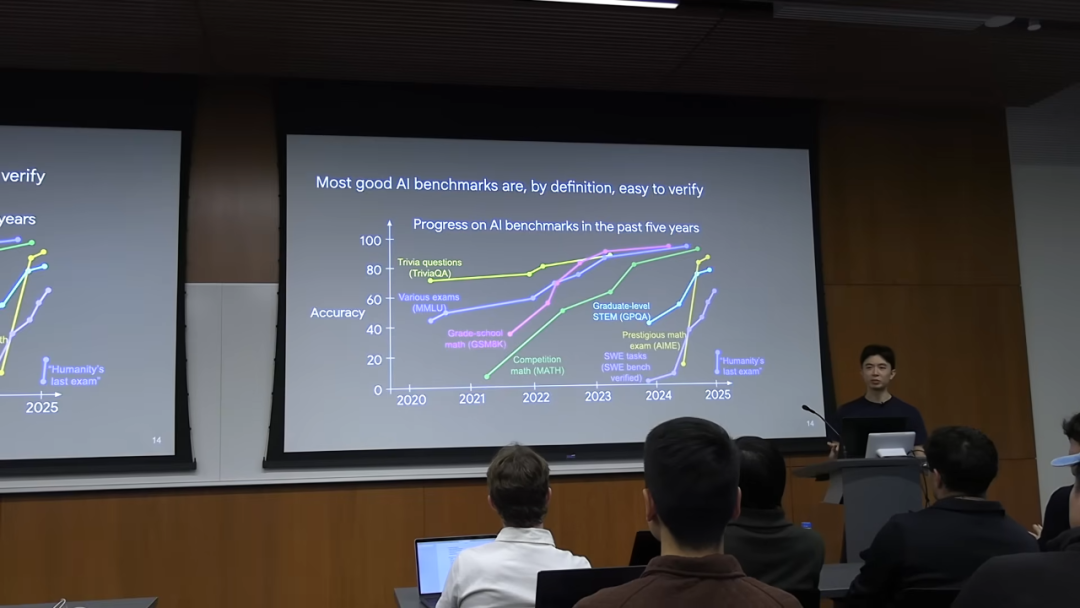
案例研究:DeepMind 的 AlphaDev
利用这种「不对称验证性」最经典的例子,是 DeepMind 的 AlphaDev 项目。他们选择了一些极难解决、但解法易于验证的计算问题,比如找到一种算法对某些序列进行更快的排序,或者用最少的指令实现某个功能。

他们的做法非常巧妙,可以概括为一种进化式搜索算法:
- 1. 生成 (Sample):让大语言模型生成大量候选的解决方案(代码)。
- 2. 评估 (Grade):因为任务是高度可验证的(例如,可以通过运行测试来评估代码的正确性和效率),所以可以自动、快速地给每个方案打分。
- 3. 迭代 (Iterate):将得分最高的方案作为「灵感」,反馈给大语言模型,让它在下一轮生成更高质量的方案。
通过投入海量的计算资源进行这种循环,AlphaDev 能够发现比人类专家设计的算法更优的解。Jason 举了一个例子:找到 11 个六边形的最佳摆放方式,使其能被一个最小的外部六边形包围。这个问题完美符合高可验证性的所有标准:结果客观、计算验证快、可扩展、无噪音,并且外部六边形的大小提供了一个连续的奖励信号。
启示与影响
验证者法则告诉我们:

- 1. 最先被自动化的领域,将是那些工作成果极易验证的领域。比如,某些类型的软件测试、代码优化、金融市场的套利策略发现等。
- 2. 测量即优化:创造衡量和验证标准本身,将变得极具价值。如果你能为某个原本难以衡量的领域(比如创造力、用户体验)设计出一套快速、客观、可扩展的评估体系,那么接下来就可以利用 AI 来大规模地优化它。
三、智能的锯齿状前沿:为什么不会有「快速起飞」
Jason 的第三个观点,是关于 AI 能力发展的形态。很多人对 AI 的未来有一种二元对立的看法,要么觉得它无所不能,要么觉得它漏洞百出。
「快速起飞」的幻象
在 AI 安全领域,有一个流传已久的假说叫「快速起飞」(Fast Takeoff)。它认为,一旦 AI 的智能达到某个临界点(比如能够自主进行 AI 研究),它的能力将在极短的时间内发生爆炸性增长,远超人类,形成所谓的「超级智能」。

Jason 认为,这种情况大概率不会发生。
他的理由是,AI 的自我提升能力更可能是一个渐进的、连续谱式的过程,而不是一个「0 或 1」的二进制开关。与其想象「某一天 AI 突然就能训练下一代 AI 了」,更现实的场景是:
- • 第一年:AI 连研究代码库都跑不起来。
- • 第二年:AI 可以勉强训练一个模型,但效果很差。
- • 第三年:AI 可以自主训练了,但效果不如顶尖的人类研究团队。
- • 第四年:AI 训练得很好,但偶尔还需要人类介入来解决一些疑难杂症。
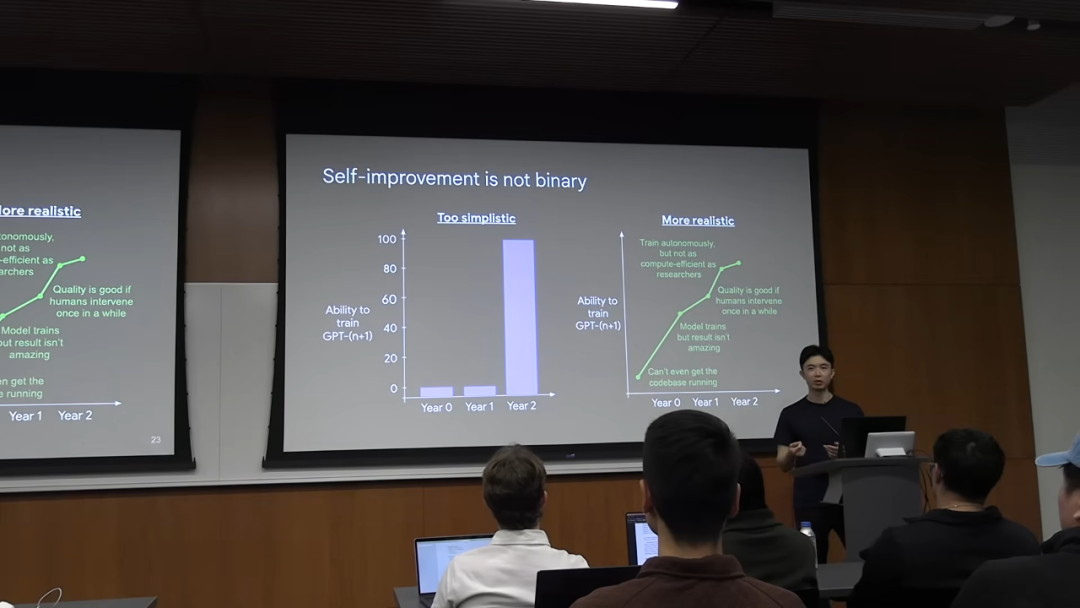
此外,AI 的能力发展并不是一个平滑的、齐头并进的战线,而是一个「锯齿状」的前沿。
能力图谱:高峰与深谷
想象一下 AI 的能力图谱,它不是一条平滑的上升曲线,而是一条布满了高峰和深谷的崎岖山脉线。
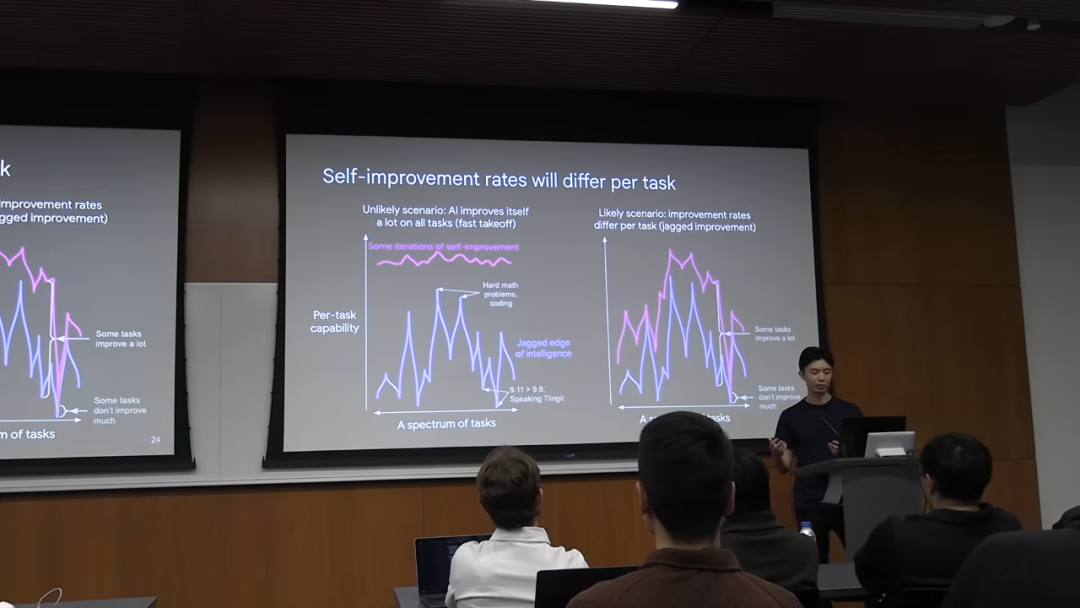
- • 高峰:是 AI 目前表现出超人能力的领域,例如解决复杂的数学问题、编写某些类型的竞赛代码。
- • 深谷:是 AI 表现得非常糟糕的领域。比如,很长一段时间里,
ChatGPT会认为 9.11 比 9.9 大。另一个例子是说特林吉特语 (Tlingit),这是一种只有几百名北美原住民会说的语言,由于数据极度稀缺,AI 几乎不可能学会。
更重要的是,不同任务的提升速度也是不同的。那些位于「高峰」的任务,可能会因为其高度可验证性而得到算法的快速优化,变得越来越强。而那些位于「深谷」的任务,其瓶颈可能在于物理世界交互或数据采集,提升速度会非常缓慢。AI 不会因为在数学上取得了突破,就突然学会了如何说一口流利的特林吉т语。
预测 AI 进展的三大启发式法则
那么,我们如何预测一个特定任务被 AI 攻克的速度呢?Jason 提供了三个简单但非常有效的启发式法则:
- 1. 数字任务 vs. 物理任务:AI 在纯数字领域的进展速度远快于物理世界。原因很简单:迭代速度。在数字世界里,你可以用海量的计算资源进行百万次的模拟和实验。但在物理世界,一个机器人做一个动作,收集一次数据,速度是受物理定律限制的。Jason 引用了一幅 1981 年的漫画,画的是一个能帮你做作业的「家庭作业机」,这在今天几乎已成为现实。但像
iRobot那样的家用机器人,离我们还很遥远。 - 2. 对人类的难度:总的来说,对人类越容易的任务,对 AI 也越容易。当然也有例外,比如 AI 可以在海量数据中发现人类无法察觉的模式(例如从数百万张医学影像中预测乳腺癌),实现超人表现。
- 3. 数据丰富度:数据量是决定 AI 性能的关键因素。一个清晰的例子是语言模型在不同语言上的数学能力。模型的数学表现与该语言在训练语料库中出现的频率(数据量)呈现出非常强的正相关关系。
这个规则同样有一个例外:如果一个任务有明确、单一的评价指标,我们就可以像 AlphaZero 或 AlphaEvolve 那样,通过强化学习生成几乎无限的合成数据来训练模型。
基于这三个启发式规则,Jason 给出了一个关于 AI 能力发展时间线的预测表格,其中不乏一些有趣的思考:

「锯齿状前沿」的启示:

- 1. 非对称的行业冲击:AI 的影响将极不均衡。某些领域,如软件开发,将被 AI 彻底改变和加速。而另一些领域,如理发、传统手工艺,短期内可能几乎不受影响。
- 2. 理性的预期管理:理解 AI 能力的「锯齿状」特性,可以帮助我们避免陷入「AI 无所不能」或「AI 一无是处」的极端思维,从而对 AI 的发展有一个更理性和现实的预期。
结语
总结一下,Jason Wei 分享的三个核心思想,共同构成了一个理解和思考 AI 未来的框架:
- 1. 智能商品化:计算和知识的成本正在趋近于零。这是一个不可逆转的宏观趋势,它将重塑知识型工作的价值。
- 2. 验证者法则:一个任务的可验证性,决定了它被 AI 征服的速度。重点关注那些易于衡量和评估的领域,它们将是 AI 最先突破的地方。
- 3. 锯齿状前沿:AI 的发展是不均衡的,能力图谱上既有高峰也有深谷。我们需要具体问题具体分析,而不是笼统地谈论「AI 能做什么」。
基于这个框架,我们就可以思考:哪些工作会被自动化?哪些新机会正在涌现?我们应该学习什么样的新技能?
如果能找到这些问题的答案,就能找到自己在这个新时代中的位置。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号