超越 RAG:知识图谱如何构建 AI 的记忆与推理


大模型虽好,但开发者们都明白,看似强大能力的背后隐藏着致命缺陷:大模型缺乏真正可靠的上下文理解和记忆能力。
一个常见的误区是认为只要不断扩大模型的上下文就能解决问题。但现实是,当上下文窗口变得过大时,LLM 会出现「注意力迷失」的现象。当重要信息被淹没在输入的「噪音」之中,模型依然会误解信息、遗忘细节、进而得出不可靠的结论。
如何让大模型给出更可靠的回复?图数据库 Neo4j 的开发者关系副总裁 Stephen Chin 给出的答案是「基于 GraphRAG 的上下文工程」。

他在一场题为「Context Engineering: Connecting the Dots with Graphs」的演讲中系统阐释了自己的观点,简单来说:我们应该从「提示工程」转变为「上下文工程」,并使用知识图谱来增强 RAG 的能力和可靠性。

一、什么是上下文工程?
上下文工程是一门旨在系统性地塑造 AI 如何感知、记忆和推理信息的学科。它远不止于编写提示词,而是涵盖了为 AI 提供高质量、结构化信息的整个流程。
上下文工程分为四个主要部分:
- 1. 提示工程 (Prompt Engineering):Prompt 依然是基础。我们需要设计清晰的指令、提供必要的背景信息,为 AI 的任务执行设定好「初始框架」。
- 2. 检索增强生成 (Retrieval Augmented Generation, RAG):从外部数据源(如企业文档、数据库)检索相关信息,并将其作为附加上下文提供给 LLM,以增强其回答的准确性和时效性。
- 3. 状态与历史 (State and History):即 AI 的记忆。这不仅包括短期记忆,用于处理当前的多轮对话和任务;还包括长期记忆,用于记录和学习跨越多次交互的知识和经验。
- 4. 结构化输出 (Structured Output):确保 AI 的输出结果是可预测、可解析的格式(如 JSON),以便于下游应用或其他 AI Agent 的调用和集成。
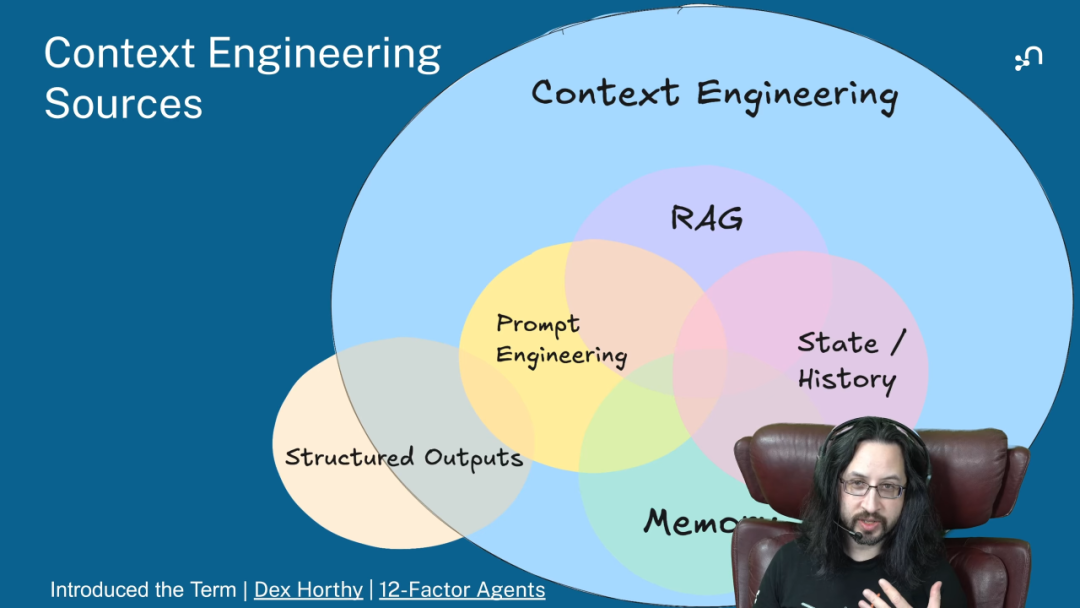
这四个部分共同构成了一个动态的、目标驱动的上下文管道。其核心目标是提升输入给 LLM 的「信噪比」,让模型能够专注于最相关的信息,从而做出更可靠、更具可解释性的判断。
上下文工程的兴起,标志着我们从与 AI 的「对话」,进化到了对 AI 整个工作环境的「设计」。
二、AI 的记忆难题
在上下文工程的版图中,「记忆」是核心难题。一个没有可靠记忆的 AI,就像一个只能处理瞬时信息的计算器,无法进行真正复杂的、需要长期规划的任务。
Stephen 将 AI 的记忆分为两类:
- • 短期记忆:专注于当前任务。它的挑战在于如何将尽可能多的相关信息(包括用户输入、工具返回结果等)高效地压缩到有限的上下文窗口中,并确保最关键的信息排在最前面,以对抗模型的注意力衰减。同时,还需要过滤掉来自过去工具调用中冗余的、干扰性的输出。
- • 长期记忆:跨越多次对话和任务的持久化知识。它需要从过去的交互中提取出具有「情节性」(Episodic)、「语义性」(Semantic) 和「结构性」(Structural) 的信息,并将其转化为可供未来任务使用的指令、流程或规划依据。

构建这样一个双层记忆系统,目的是为了将最相关、最核心的上下文「置顶」到模型的注意力焦点区域,填补信息空白,同时清除那些导致幻觉和错误答案的噪音。这正是知识图谱大放异彩的领域。
三、知识图谱:结构化知识的回归
在 LLM 的浪潮之前,知识图谱就作为一种强大的知识表示技术而存在。它用一种直观且强大的方式来组织和连接信息,非常适合解决 AI 的上下文和记忆问题。

知识图谱的基本构成非常简单:
- • 节点 (Nodes):代表实体,如人、地点、事件或概念。例如,「张三」、「北京」、「产品 A」。
- • 关系 (Relationships / Edges):代表实体之间的联系。例如,「张三」-「居住在」->「北京」。
- • 属性 (Properties):附着在节点或关系上的键值对信息。例如,「张三」节点可以有属性
{age: 30},「居住在」关系可以有属性{since: "2010"}。
Stephen 举了一个例子:一个表示 Ann 和 Dan 两人关系的知识图谱。
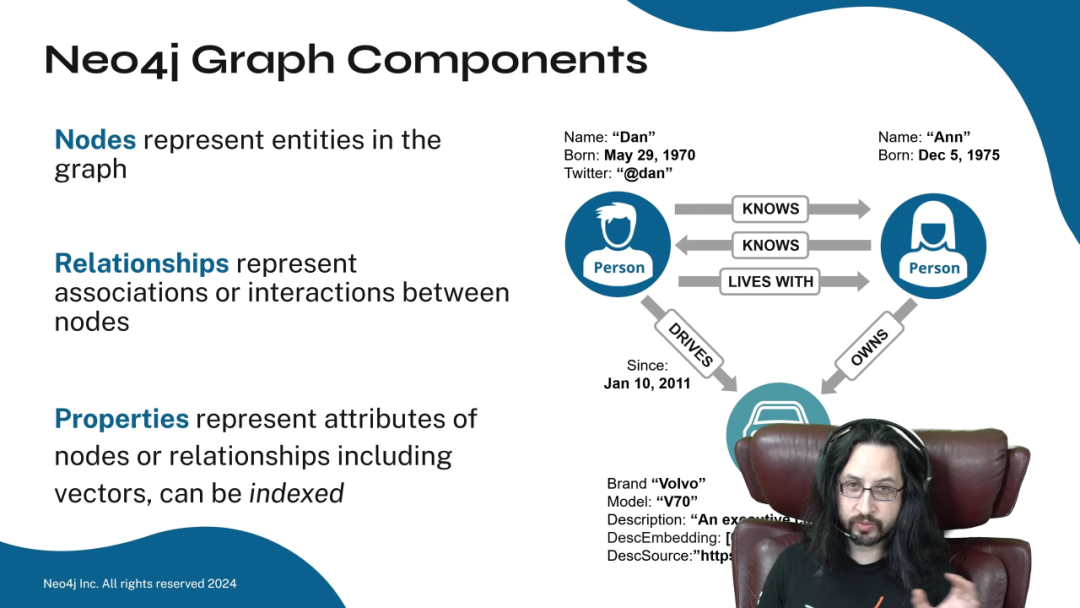
在这个图中,「Ann」和「Dan」是节点,「Car」也是节点。他们之间通过「KNOWS」、「LIVES_WITH」、「DRIVES」等关系连接。每个节点和关系都可以有自己的属性,比如汽车的型号是「Volvo V70」。更关键的是,节点上还可以存储「嵌入向量」(Embeddings),这为后续的向量检索提供了基础。
LLM 的优势在于语言、推理和创造力,而知识图谱的优势在于结构化的事实、上下文和可解释性。当这两者结合时,便能产生强大的协同效应。

知识图谱就像一个为 LLM 定制的外置大脑,一个代表了你的组织、业务或特定领域的「数字孪生」。
四、GraphRAG:下一代检索增强
传统的 RAG 主要依赖于向量数据库进行语义相似度搜索。它将文档切分成块 (Chunks),计算嵌入向量,然后检索与用户问题最相似的文本块。这种方法虽然有效,但它忽略了信息之间固有的、丰富的关系。
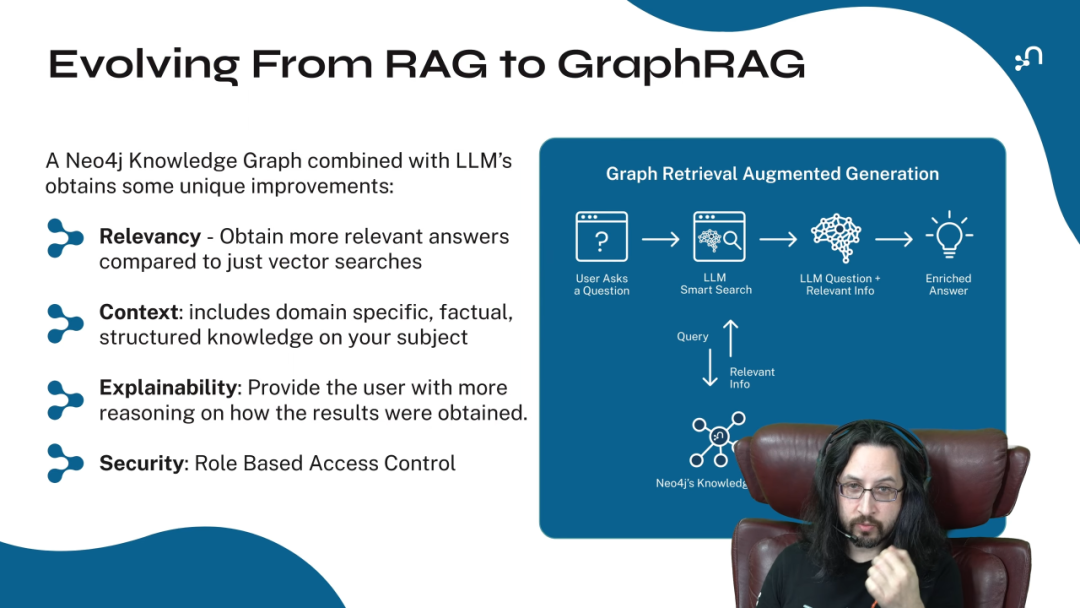
GraphRAG 则是将知识图谱整合进 RAG 流程的下一代技术。其工作流程如下:
- 1. 用户提出问题。
- 2. LLM 将问题初步处理后,向知识图谱发起一个查询。
- 3. 知识图谱返回一个与问题相关的子图 (Subgraph),这个子图不仅包含相关节点,还包含了这些节点之间的关系。
- 4. 这个子图作为丰富的、结构化的附加上下文,与原始问题一起提交给 LLM。
- 5. LLM 基于这个高质量的上下文,生成一个更准确、更深入、更具可解释性的答案。
相比于传统的向量 RAG,GraphRAG 带来了几个优势:
- • 更高的相关性:它不仅仅是找到相似的文本,而是找到相关的「事实网络」。例如,查询某个软件漏洞,GraphRAG 不仅能找到描述该漏洞的节点,还能通过关系找到受影响的组件、修复它的 commit、发现者以及相关的安全公告,提供一个完整的上下文图景。
- • 强大的可解释性:我们可以清晰地看到 LLM 的回答是基于知识图谱中的哪一部分子图。这为构建可信、可审计的 AI 系统提供了坚实的基础,当 AI 出错时,我们能够追溯其「思考过程」。
- • 动态演进:知识图谱是一个「活的」数据库。我们可以随着时间的推移不断地更新、修正和丰富它,从而持续提升 AI 系统的性能。
- • 精细的访问控制:可以在图的层面实现复杂的权限管理。比如,在一个医疗系统中,可以设定只有医生角色的用户才能查询到「诊断」信息,而行政人员只能查询到患者的联系方式等个人信息。这种基于图结构的角色访问控制 (Role-based Access Control) 远比基于文档的控制更为灵活和强大。
实战演示:漏洞查询
在 Stephen 的第一个演示中,他使用了一个开源的知识图谱构建工具,将一份关于供应链安全的 VEX (Vulnerability Exploitability eXchange) 文档导入 Neo4j 数据库,自动构建了一个知识图谱。这份文档详细描述了 Jackson 库中的一个漏洞。
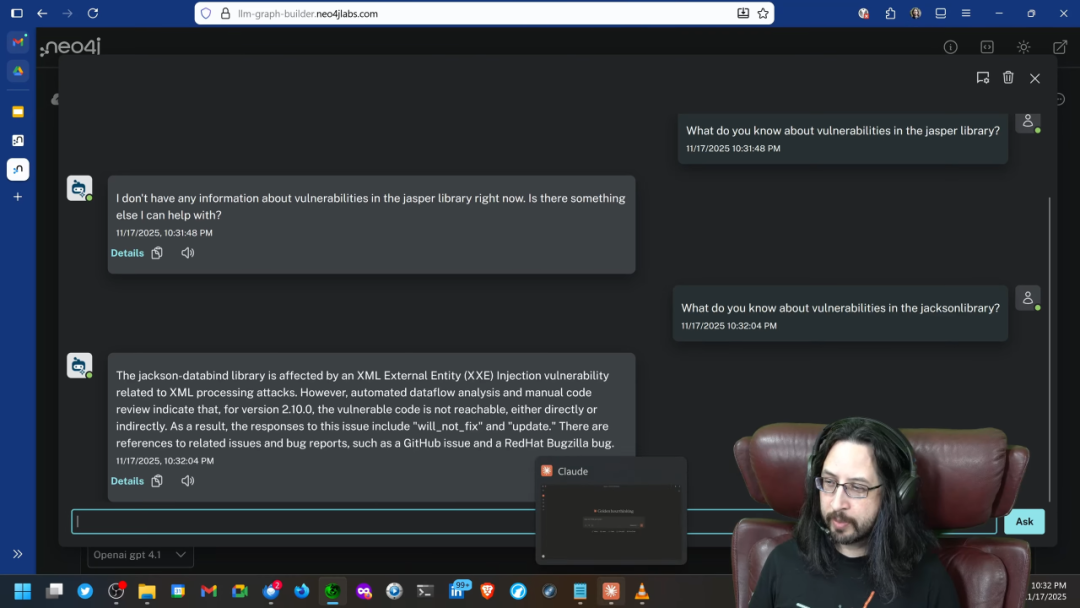
当向配置了 GraphRAG 的 LLM 提问「Jasper 库有什么漏洞?」时,系统明确回答「知识库中没有相关信息」,因为它在图中找不到关于 Jasper 的节点。这完美地展示了知识图谱的「闭合世界假设」,有效防止了幻觉。
而当提问「Jackson 库有什么漏洞?」时(即使有拼写错误),系统执行了一个两阶段的 GraphRAG 流程:
- 1. 第一阶段:进行向量搜索,在图谱中定位到与
Jackson漏洞最相关的初始节点。 - 2. 第二阶段:从这些初始节点出发,沿着关系进行图遍历,抓取所有与之相连的邻近节点(如受影响版本、修复方案等),形成一个包含丰富上下文的子图。
最终,LLM 基于这个子图,给出了一个极为详尽和准确的回答,包括漏洞的 CVE 编号、攻击类型、受影响版本以及修复建议。
五、赋能 Agent:图谱驱动的记忆与推理
随着 AI Agent 技术的兴起,对 AI 记忆和自主规划能力的要求越来越高。Agent 需要在多步任务中持续追踪状态、调用工具并做出决策。知识图谱为此提供了一个理想的记忆和推理框架。
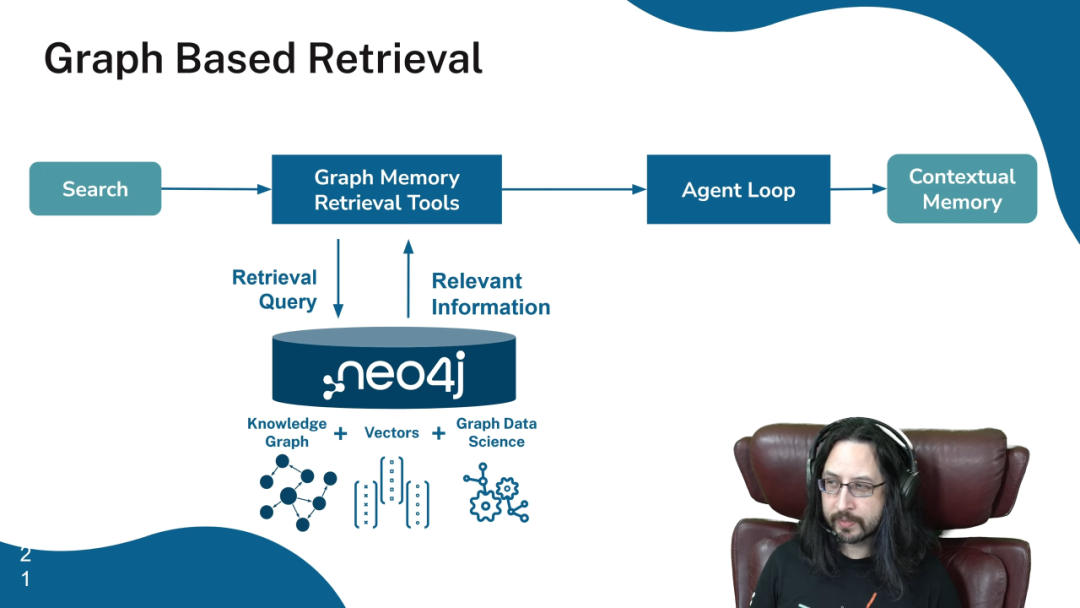
Stephen 阐述了如何使用图谱作为 Agent 的记忆核心:
- • 记忆存储:Agent 的每一次交互、观察、工具调用结果,都可以被结构化地存储为图谱中的节点和关系,并附加上时间、地点等元数据。
- • 记忆检索:当 Agent 需要决策时,它可以在这个记忆图谱中进行复杂的查询。这种查询可以是混合式的:
- • 向量检索:通过嵌入向量进行语义搜索,找到相关的记忆片段。
- • 图算法:运行图数据科学算法,如社区发现来找到相关的记忆簇,或使用 PageRank 算法来识别最重要的记忆节点。
案例:更新演示文稿
假设用户需要对 LLM 说,「请根据我和 Sid 上次在 GIDS 大会演讲的内容,更新一下这个演示文稿。」
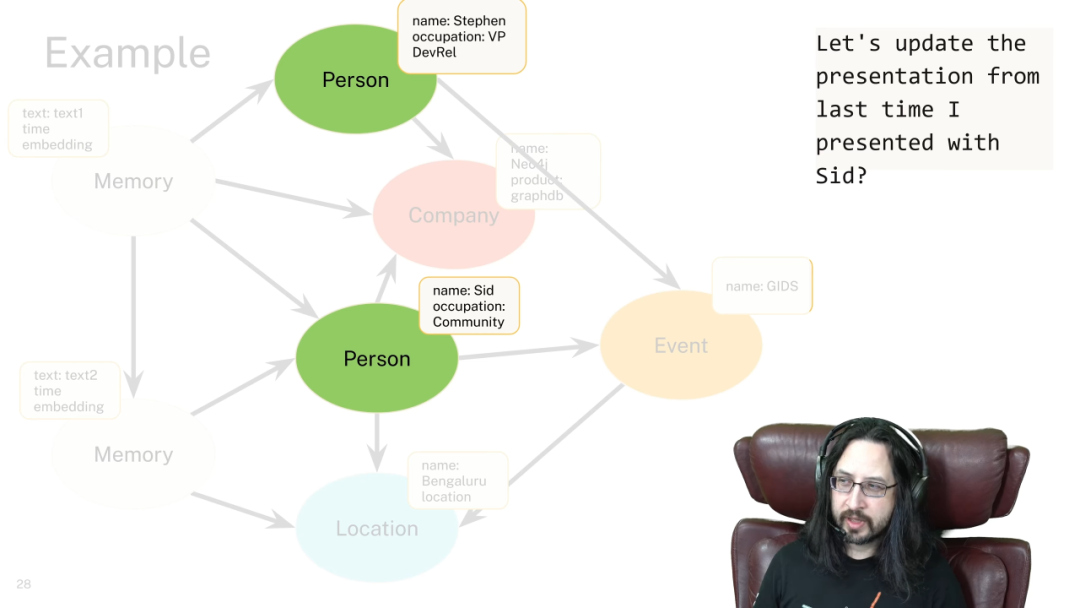
传统的 RAG 可能会陷入困境。它可能会找到关于 Stephen 的文档、关于 Sid 的文档、以及关于 GIDS 大会的文档,但很难将这三者精确地关联到「那一次特定的演讲」。
而基于图谱的记忆系统则可以轻松处理:
- 1. 它通过实体识别,在图谱中定位到「Stephen Chin」、「Sid」和「GIDS」这三个节点。
- 2. 它在图谱中寻找一个同时与这三个节点相连的「事件」节点,即那次「演讲」事件。
- 3. 该「演讲」节点上还关联着时间、地点以及演讲内容等属性。
- 4. 系统将这个包含所有相关实体和关系的完整子图作为上下文提供给 LLM。
LLM 获得了关于「谁、和谁、在哪里、什么时候、做了什么」的完整、无歧义的上下文,从而可以高质量地完成「更新演示文稿」的任务。
这种处理多跳 (Multi-hop)、多约束复杂查询的能力,是知识图谱相较于简单向量检索的根本性优势。
六、Agentic Traversal:AI Agent 的自主图谱探索
在演讲的最后,Stephen 展示了更前沿的技术:Agentic Traversal,即让 AI Agent 具备自主遍历和探索知识图谱的能力。
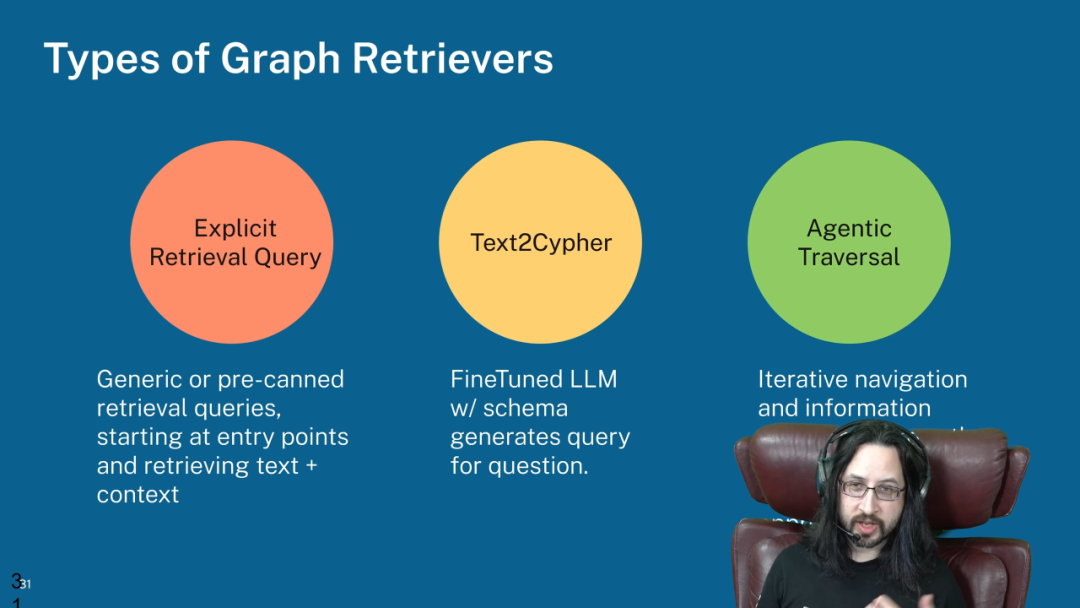
实战演示:Agentic Claude 查询
在这个演示中,他将一个 Claude Agent 与 Neo4j 数据库通过一个开源的 Cypher 工具连接起来。当向这个 Agent 提出关于 Jackson 漏洞的同一个问题时,Agent 展现了自主规划和执行能力:
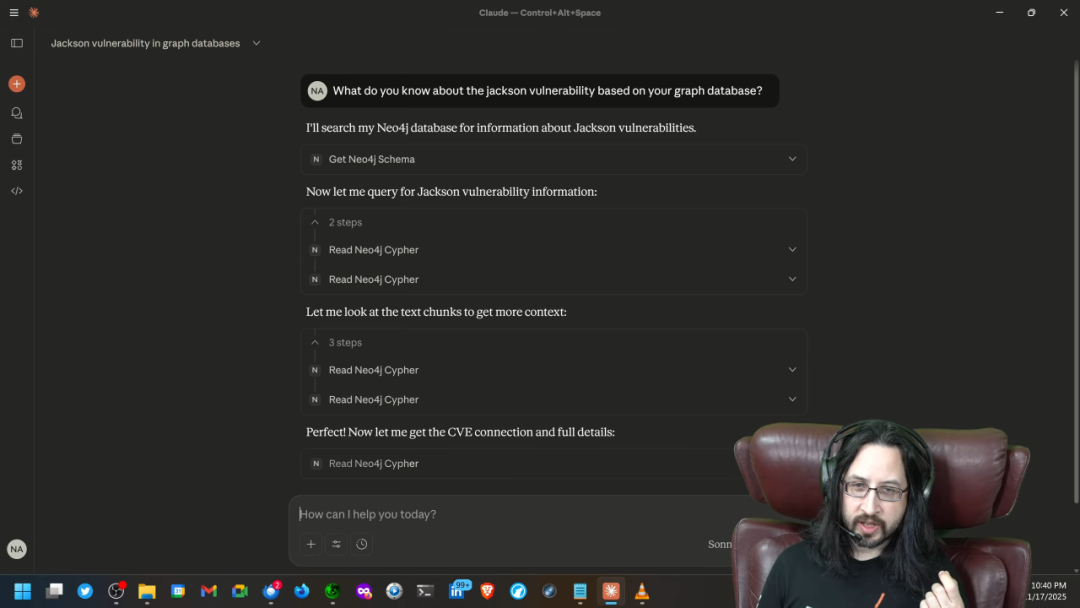
- 1. 理解模式 (Schema Inspection):Agent 做的第一件事,是向数据库查询图谱的模式 (Schema),即有哪些类型的节点、哪些类型的关系以及它们是如何连接的。这是 Agent 理解其可用知识结构的关键一步。
- 2. 迭代查询 (Iterative Querying):在理解了模式之后,Agent 自主地生成并执行了一系列 Cypher 查询(一种用于图数据库的查询语言)。它首先找到漏洞的核心节点,然后查询其属性,接着沿着关系探索与之相连的其他信息节点,一步步地收集所有相关的细节。
- 3. 综合回答 (Synthesized Answer):Agent 将多次查询得到的信息碎片进行汇总和推理,最终生成了一份比第一个演示中更为详尽、结构更为清晰的漏洞分析报告。报告不仅包含了所有技术细节,甚至还给出了组织应如何应对该漏洞的建议。
这种 Agentic 方法虽然执行时间更长,但它通过自主探索,最大化地利用了知识图谱中的信息,最终得到了质量极高的结果。
这代表了未来 AI 应用的一种重要模式:我们不再是为 AI 准备好一切,而是为 AI 提供一个高质量的知识环境和一个工具集,让它自己去探索、发现和解决问题。
结语:从提示工程师到信息架构师
Stephen Chin 的分享指明了后 RAG 时代的方向:构建真正强大、可靠和可信的 AI 系统,其核心挑战在于上下文。而解决这个挑战,需要我们从「提示工程师」的战术思维,升级到「信息架构师」的战略思维。
我们未来的工作,将不再是与单个 LLM 的反复博弈,而是设计、构建和维护一个高效的信息生态系统,让 AI 在其中可靠地运行。在这个生态系统中,知识图谱将扮演数据基石的角色,为 AI 提供结构化的事实、长期的记忆和可解释的推理路径。
从 RAG 到 GraphRAG,再到 Agentic Traversal,这条技术演进路线的核心,是让 AI 从一个单纯的「语言生成器」,进化为一个拥有记忆、能够利用结构化知识进行复杂推理的「认知引擎」。
如果你希望继续深入了解这一领域,Stephen 推荐了以下资源:
- • Graph Academy:Neo4j 官方的免费学习平台,提供了从 Cypher 查询到 GraphRAG 的实践课程。
- • Nodes AI:一个专注于 AI 和图技术的免费线上会议。
- • GraphRAG.com:一个社区驱动的网站,汇集了关于 GraphRAG 的最新研究、指南和前沿信息。
LLM 的浪潮仍在继续,但构建护城河的不再是模型本身,而是高质量的数据以及将数据转化为智能的能力。当 RAG 不足以精细支撑上下文工程时,也许是时候拾起知识图谱这项经典的技术了。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-28,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号