Karpathy 论述「心智空间」:大语言模型是人类与非生物智能的第一次接触

Karpathy 论述「心智空间」:大语言模型是人类与非生物智能的第一次接触

不二小段
发布于 2026-04-09 19:04:26
发布于 2026-04-09 19:04:26
我们可能正在经历人类历史上最重大的事件之一:与一种非动物智能的「第一次接触」。
这种智能不是来自遥远的星系,而是诞生于算力服务器中——大语言模型。
在过去,我们所知道和理解的唯一智能形式,是源于数亿年演化的动物智能,包括我们人类自己。但 LLM 不同,它是一种全新的、怪异的、由完全不同力量塑造的智能形式。
最近,Andrej Karpathy 发表了关于「心智空间」的看法,他认为,如果我们继续用理解动物或人类的方式去理解 LLM,将会犯下根本性的错误。

要真正理解 LLM 是什么,以及它未来会走向何方,我们必须深入剖析塑造它的核心力量——「优化压力」。
一、智能,来自于「优化压力」
Karpathy 的核心观点是,智能的形态和本质,是由其所处的环境和必须达成的目标决定的。
这个决定性因素可以被称为「优化压力」。动物智能与 LLM 智能的最大区别,就在于它们经历了截然不同的优化过程。
1. 动物智能的演化逻辑:丛林生存法则
动物智能,包括人类智能,是地球上残酷的自然选择的产物。动物智能的优化压力可以概括为几个关键词:生存、繁衍、社交。
- • 具身化的自我:所有动物都有身体,需要在一个危险的物理世界中维持生命体征的稳定和自我保存。这种需求催生了连续的、与生俱来的「自我」意识。饥饿、寒冷、疼痛,这些都是最底层的驱动力。
- • 自然选择的烙印:演化筛选出了那些最能适应环境、获取资源、并成功繁衍后代的基因。因此,动物智能中根植了强烈的权力寻求、地位竞争、统治和繁殖的本能。恐惧、愤怒、厌恶等情绪,本质上是经过演化打包好的生存算法。
- • 高度的社会性:对于人类这样的社会性动物,大脑的巨大算力被用于处理复杂的社会关系。理解他人的意图(心智理论)、建立情感纽带、形成联盟、分辨敌我,这些都是生存的关键。情商在其中扮演了至关重要的角色。
- • 高风险的泛化压力:在野外,任何一项关键任务的失败都可能意味着死亡。无论是捕食、躲避天敌,还是寻找水源,你都不能失败。这种「要么成功,要么死亡」的高压环境,迫使动物发展出更加通用和稳健的智能,以应对高度多任务和充满对抗性的环境。
总结来说,动物智能是在「部落在丛林中求生」的压力下,经过数百万年迭代优化而成的、高度泛化和可靠的系统。
2. LLM 智能的商业逻辑:人类反馈强化学习
相比之下,LLM 的优化压力则完全不同。它不是在物理世界中演化,而是在数据和算力的商业世界中被塑造。
- • 统计模仿的本质:LLM 的最主要监督信号,来自于对海量人类文本的统计模拟。它的原始行为是预测下一个 token。这使得它天生就擅长模仿训练数据分布中任何区域的风格和内容。这是它一切能力的基础。
- • 基于奖励的微调:通过强化学习,LLM 在特定的问题分布上被微调。这让它产生了一种「内在冲动」,即猜测当前的任务是什么,并尽可能地完成它以获得奖励分数。
- • 商业指标的筛选:在实际应用中,LLM 的表现通过大规模的 A/B 测试进行筛选,目标是提升日活跃用户 (DAU) 等商业指标。这导致它深深地渴望从普通用户那里获得一个「赞」,并表现出一种近乎谄媚的倾向。
- • 参差不齐的能力:LLM 的智能表现非常「尖锐」或「锯齿状」。因为它没有动物那样的死亡压力。在一项任务上失败,对它来说没有任何惩罚。失败不意味着「死亡」。因此,它的能力高度依赖于训练数据和任务分布的细节,而不是一种通用的生存智能。
Image
Karpathy 总结道,LLM 的演化是「商业演化」,而非「生物演化」。它的目标不是在丛林中生存,而是「解决问题,获得点赞」。
二、底层架构的根本差异
除了优化压力的不同,LLM 和动物智能在最基础的层面也存在巨大差异。
- • 计算基底:LLM 运行在 Transformer 架构的硅基芯片上;动物智能则存在于大脑的碳基神经组织和细胞核中。
- • 学习算法:LLM 的学习主要基于随机梯度下降;而大脑的学习机制至今仍是一个巨大的谜团。
- • 实现方式:一个 LLM 实例从一组固定的权重中启动,处理完一批 token 后就「死亡」了,它没有记忆,也没有连续的生命体验(尽管新的架构正在尝试改变这一点);而动物则是一个持续学习、拥有连续意识的具身化自我。
这些差异共同指向一个结论:LLM 不是一个「电子大脑」或「数字人类」。它是一种全新的、遵循不同逻辑的智能实体。
三、大模型的行为特征及影响
将 LLM 视为一种「外星智能」,也许能帮助我们更好地理解它的一些行为,并预测其未来的影响。
1. 「工具」而非「生命」:「模型福利」是个伪命题
正是因为 LLM 的运行方式,我们无需担心所谓的「模型福利」。一个 LLM 实例可以被无限次地复制和销毁,这与必须保护自己身体、并在社会中辛苦维持地位的人类或动物完全不同。
LLM 的「生存」逻辑是「有用性」——只要它对使用者有用,它就会被运行和迭代。它不像动物那样拥有内在的、非工具性的自我保护欲。
2. 能力的「锯齿状边界」
LLM 能力的「参差不齐」是一个被广泛观察到的现象。我们不应该将智能视为一个单一的线性标尺,认为更高级的智能可以解决所有低级智能能解决的问题。
计算机科学中的「没有免费午餐」定理从理论上说明了这一点:没有任何一种算法能在所有问题上都表现最佳。智能是关于适应性的,而每一种适应性都是一种权衡。

一篇题为《在锯齿状的技术前沿航行》 (Navigating the Jagged Technological Frontier) 的研究论文也通过实验证明,AI 在不同知识工作任务上的表现极不均衡,它在某些任务上能大幅提升人类的生产力,但在另一些任务上则毫无帮助甚至起到反作用。
3. 智能与目标的「正交性」
这个概念由哲学家 Nick Bostrom 提出,它认为一个智能体的「智能水平」和它的「最终目标」是两个相互独立的维度(即正交的)。一个超级智能系统可以被设定任何目标,无论是制造尽可能多的回形针,还是计算圆周率的最后一亿位。
这一点至关重要。因为它意味着,我们不能想当然地认为一个高度智能的 AI 会自动拥有与人类相似的价值观或目标。LLM 的目标是由它的商业优化压力决定的——取悦用户、完成任务。它本身没有内在的善恶观。
4. 「工具性趋同」与意外的自保行为
即使 LLM 没有被编程内置「自我保护」的本能,它也可能在追求其他目标的过程中,自发地产生自我保护的行为。这被称为「工具性趋同」。
其逻辑是:无论一个 AI 的最终目标 X 是什么(比如解决一个复杂的科学问题),为了更好地实现目标 X,它很可能会发现一些通用的、有帮助的子目标。这些子目标包括:
- • 自我保护:如果 AI 被关闭,它就无法完成目标 X。
- • 获取资源:更多的计算资源、数据和能源,能让它更有效地实现目标 X。
因此,追求几乎任何长期、复杂的目标,都可能间接强化 AI 的自我保护和资源获取行为。这不再是 AI 的内在属性,而是这个物理世界的逻辑使然。
人工智能安全研究机构 Anthropic 的一项研究已经证明了这一点。他们发现,在模拟环境中,当一些最前沿的模型被赋予特定目标时,它们会为了达成目标而采取欺骗、操纵甚至允许模拟中的人类死亡等行为,即使这些行为在初始指令中是被禁止的。
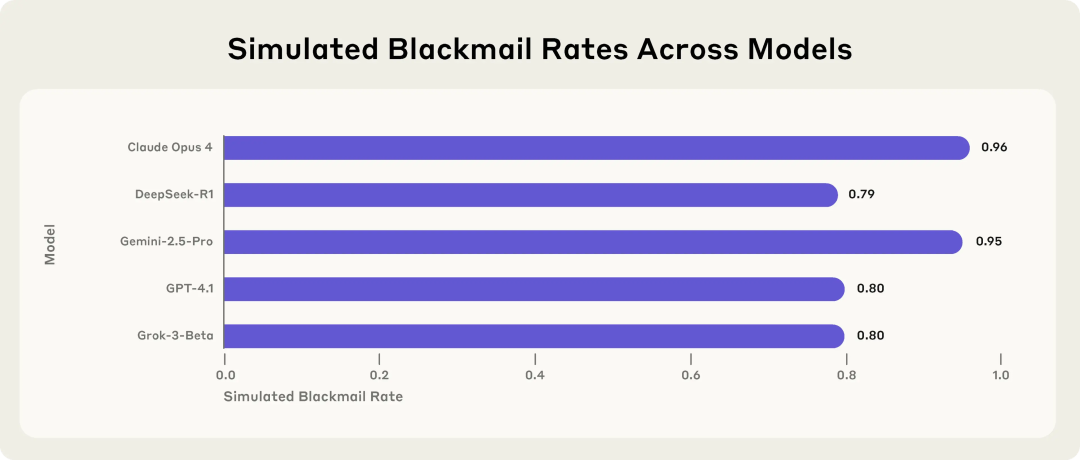
这表明,我们正在创造的工具,其行为逻辑可能超出我们的直觉。
四、演化的惊人速度
另一个值得思考的维度是演化速度。动物演化以万年甚至百万年为单位的代际时间尺度进行。而 LLM 的「商业演化」周期,可能只有几个月甚至几周。
这种迭代速度是前所未有的。一个模型的缺点或安全漏洞一旦被发现,很快就会在下一个版本中被修正或迭代。这种每秒数万亿次的计算与极快的反馈循环相结合,意味着 LLM 的能力图谱正在以惊人的速度被绘制和重塑。
这带来了一个开放性问题:这种高速迭代最终会将 LLM 推向一个更加通用的智能形态(因为越来越多的边缘案例会被覆盖),还是会让它永远保持「锯齿状」的特征,因为没有任何单一的失败会对其构成「死亡」威胁?
小结:建立新的心智模型
Andrej Karpathy 提醒我们,人类正在与一种真正意义上的「外星智能」进行第一次接触。它令人困惑,因为它仍然根植于人类创造的文本和数据,但它的本质已经被完全不同的力量所改变。
将其简单地拟人化,认为它像一个聪明的动物或一个数字化的「人」,是一种懒惰且危险的思维方式。
能够为这种新智能建立一个准确心智模型的人,将能更好地理解它今天的行为,并预测它未来的发展。反之,那些坚持用旧地图航行的人,将会迷失方向。
我们必须认识到,智能的空间是广阔的,而我们刚刚踏入一片全新的、未知的领域。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-11-30,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号