腾讯云ES AI搜索最佳实践:基于ES与Dify的企业级RAG应用方案

腾讯云ES AI搜索最佳实践:基于ES与Dify的企业级RAG应用方案

腾讯QQ大数据
发布于 2026-04-09 19:48:06
发布于 2026-04-09 19:48:06


点击蓝字,关注我们
本文共计5255字 预计阅读时长16分钟
一、引言
众所周知,RAG 已不再是早期的 Native RAG,而是作为 Agent 中的核心组件,作为企业级应用的决策大脑,是 Agent 获取知识、执行复杂任务的底层支持。当然,检索也不再是静态的一次性动作,而是根据任务需求,主动、多次、精准的调用内外部知识。
于企业而言,如何在保证数据绝对安全的前提下,构建一套高精度又可以适配业务的生产级 RAG 系统,支撑到上游各个业务部门稳定调用,是所有企业AI落地的核心命题。
企业 RAG 的三大痛点:
- 数据安全:数据是核心资产,必须在受控的环境下流转。
- 检索准确度:私域数据搜不到或搜不准,模型再强也是徒劳。
- 业务适配灵活性:不同的数据权限,不同业务场景,链路与参数都有不同的诉求。
本文将介绍一套在私有化环境下,兼顾极致搜索准确度与数据安全的黄金组合。
二、架构设计
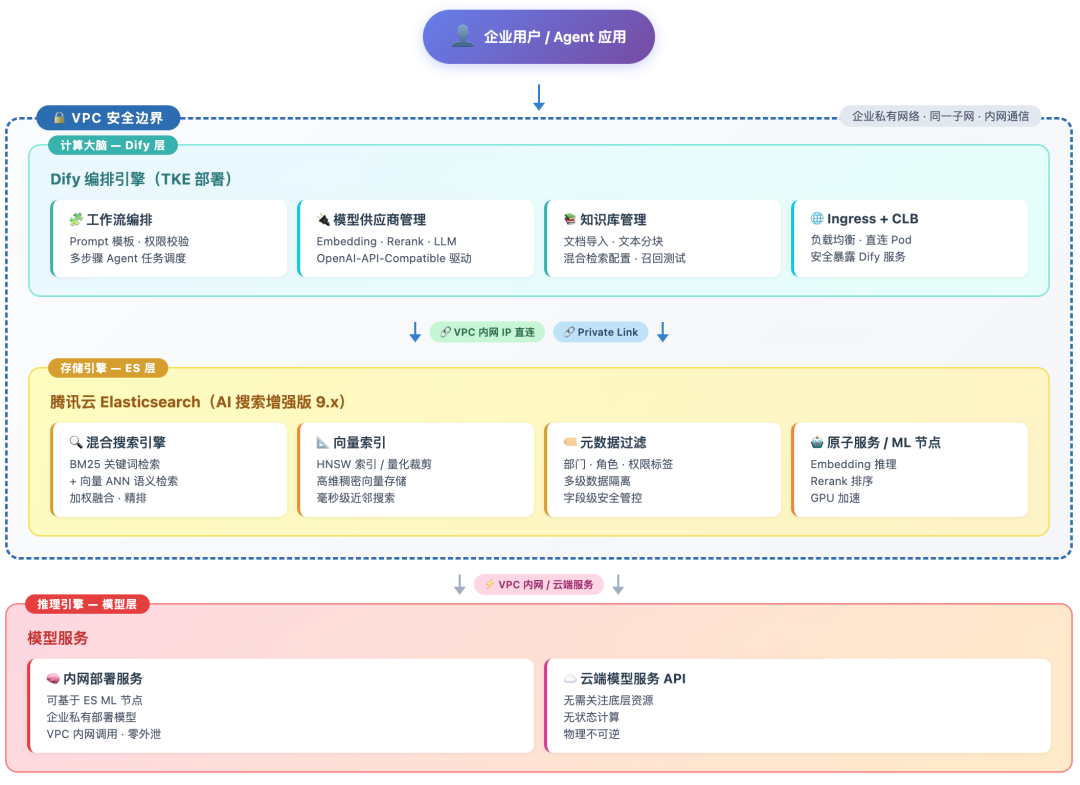
为了彻底解决前文提到的数据安全、检索准确度与业务适配灵活性这三大痛点,我们设计了基于 VPC(虚拟私有网络) 为安全底座,腾讯云 ES 为检索核心,Dify 为逻辑编排引擎的闭环架构。
架构组件概览:
- 安全边界(VPC层): 整个系统部署在企业私有网络内。Dify 应用服务器与 ES 集群处于同一子网(Subnet),通过内网 IP 直接通信,数据不出域。
- 计算大脑(Dify层): 负责与 LLM(可采用私有化部署模型或通过专线接入的 API)对接,处理工作流编排、Prompt 模板及权限校验逻辑。
- 存储引擎(ES层): 存储企业全量知识库。利用其强大的分词、向量索引及元数据过滤能力,承担高精度的混合搜索任务。
- 推理引擎(模型层):主要包含 Embedding、Rerank 及 LLM 服务,在数据预处理与 RAG 各链路进行调用,可基于 ES 机器学习节点,也可以调用云端 API 服务。
接下来,笔者将基于腾讯云 ES 以及相关服务,实操搭建一套企业级 RAG 框架。
三、场景实践
1.创建 ES 集群,获取 ES 访问地址
ES 作为整个框架的核心底层引擎,用于文本、向量的存储和检索,是整个 RAG 框架的前置条件。
我们首先需要购买一个 ES 集群,具体操作参考官网文档:
https://cloud.tencent.com/document/product/845/19536
具体配置参考:
- 用于测试验证计费模式可选按量计费。
- 产品版本选择 AI 搜索增强版,专用于对搜索能力、查询性能和稳定性有极高要求的搜索和 RAG 场景。
- Elasticsearch 版本选择 9.1.3,向量能力主要集中在 8.x 以上版本。
- 其余配置选择默认即可,注意保存集群访问密码。
集群创建成功后,进入对应集群的访问控制(https://console.cloud.tencent.com/es/cluster/detail?instanceId=es-71szkmx7®ion=ap-guangzhou&searchQuery=%3FpageIndex%3D1%26pageSize%3D10%26region%3Dap-guangzhou&tab=access-control)下可获取相关信息,用户名为 elastic,密码在创建集群时所设置,如已忘记可以重置。

2.购买 TKE 集群,部署 Dify
相比自建部署 Dify,我们推荐腾讯云 TKE 和轻应用服务提供的一键部署 Dify 方案,具备高可用、灵活弹性等特点,可以满足企业的生产部署需求,本次实践以 TKE 为例。
具体操作如下:
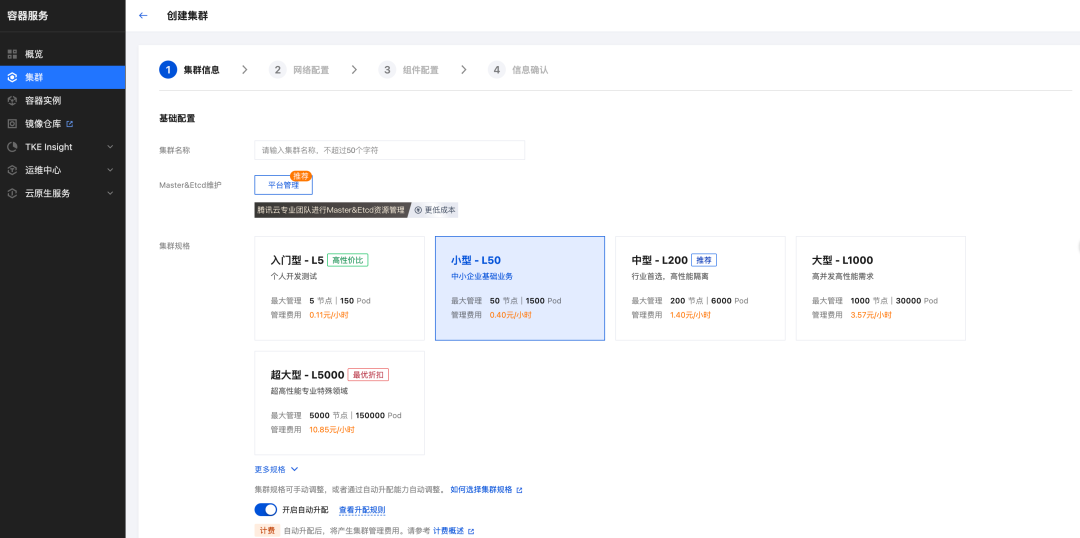
1.创建 TKE 集群
- 集群规格根据实际业务情况进行选择
- 所在地域与 ES 集群保持一致
- VPC 及子网与 ES 集群保持一致
- 勾选安装 CFS 存储组件,Dify 的关键组件 API 和 Work 需要共享存储,推荐在 TKE 集群中使用腾讯云 CFS 文件存储
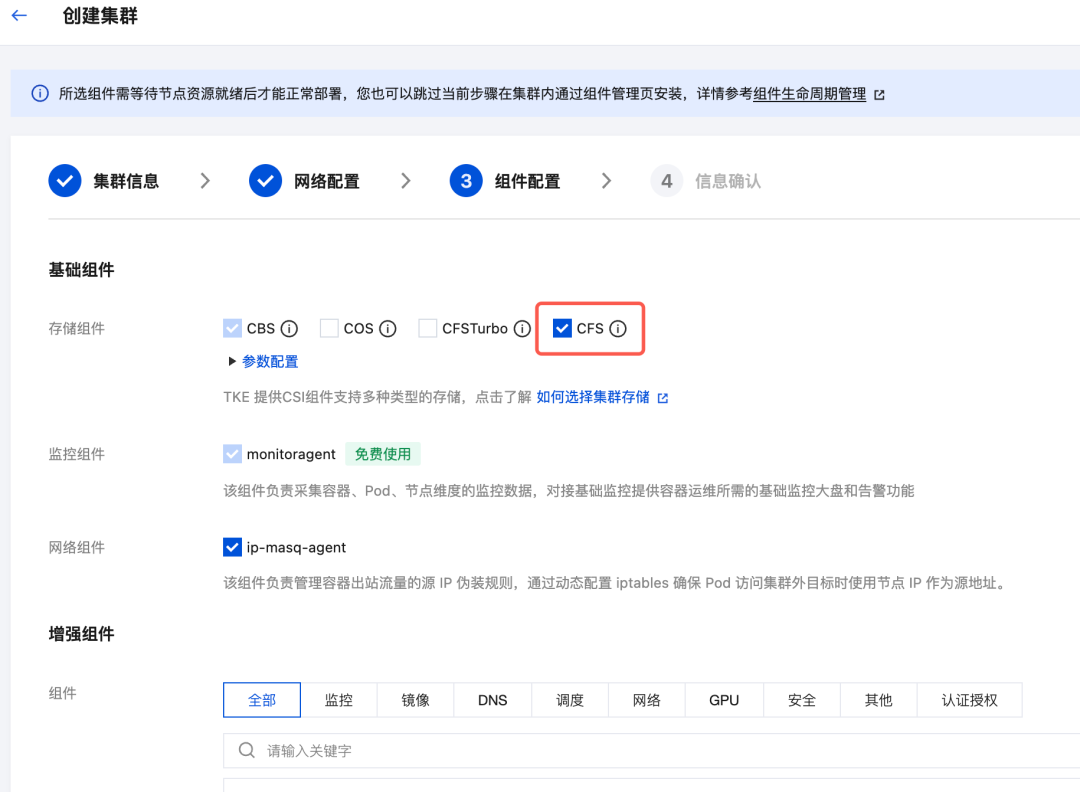
- 其余按默认配置即可。
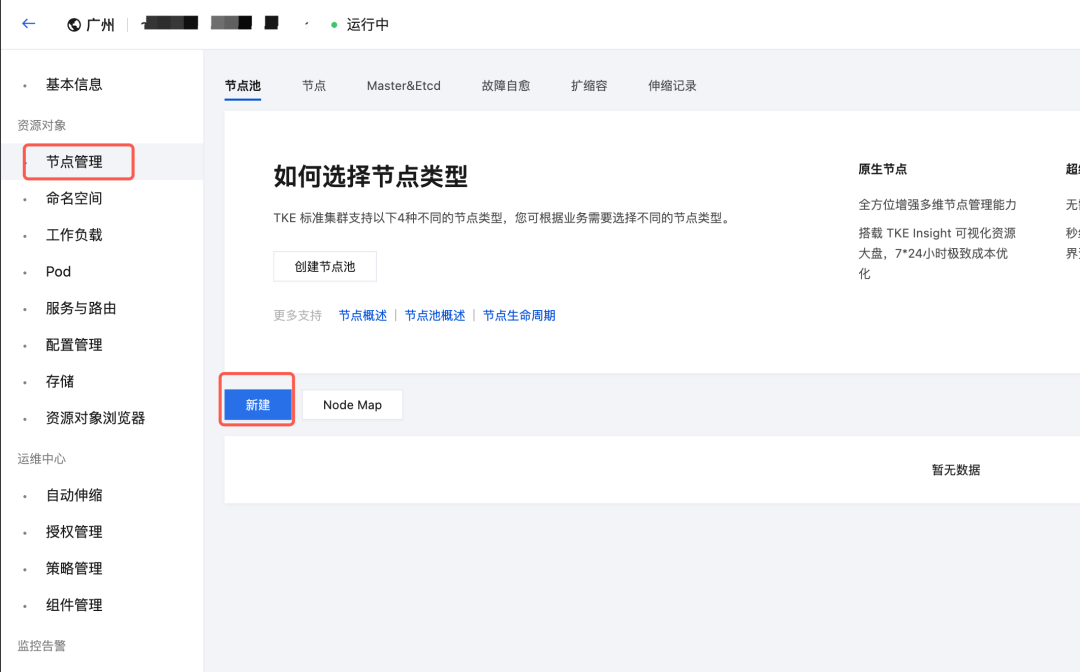
2.进入创建的 TKE 集群
- 在节点管理中新建节点
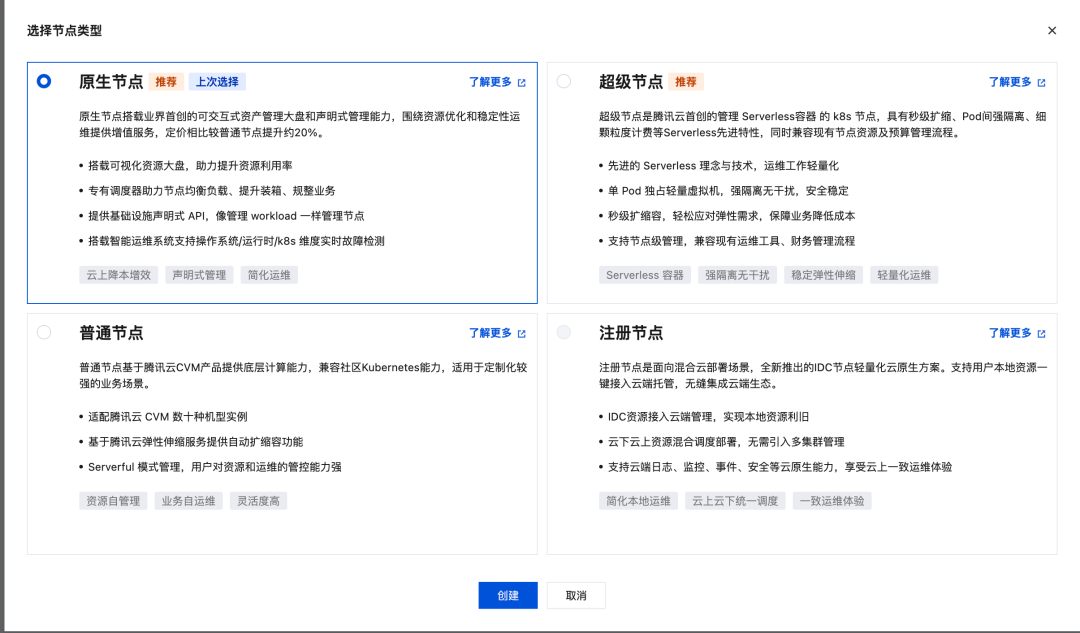
- 可选用原生节点
- 因为 Dify 组件较多,推荐至少 3*4核8G,如果你需要用到 Dify 的官方插件市场,公网宽带记得勾选「创建弹性公务 IP」,这里后续要使用 Embedding 等云端服务,推荐勾选上。
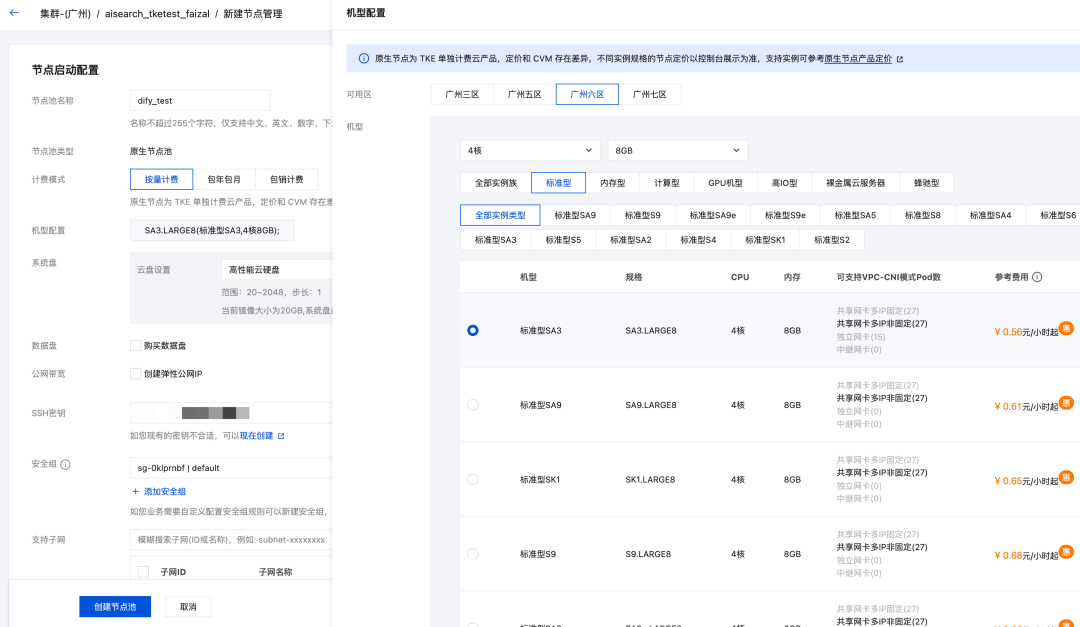
- 勾选子网
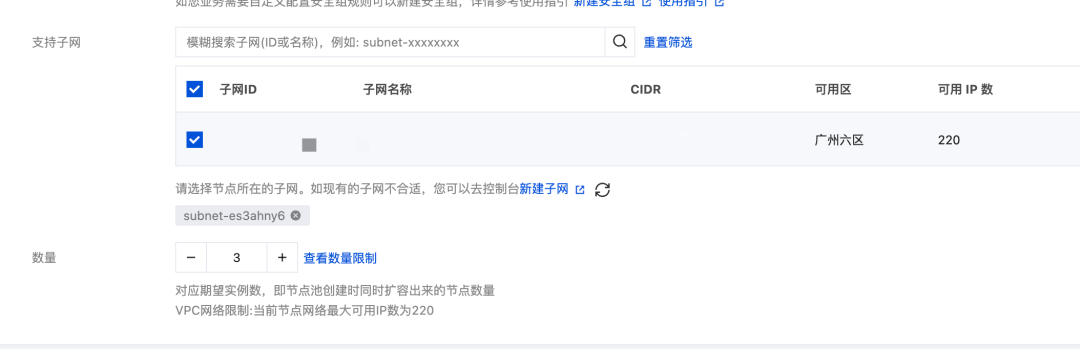
- 其余按默认配置即可。
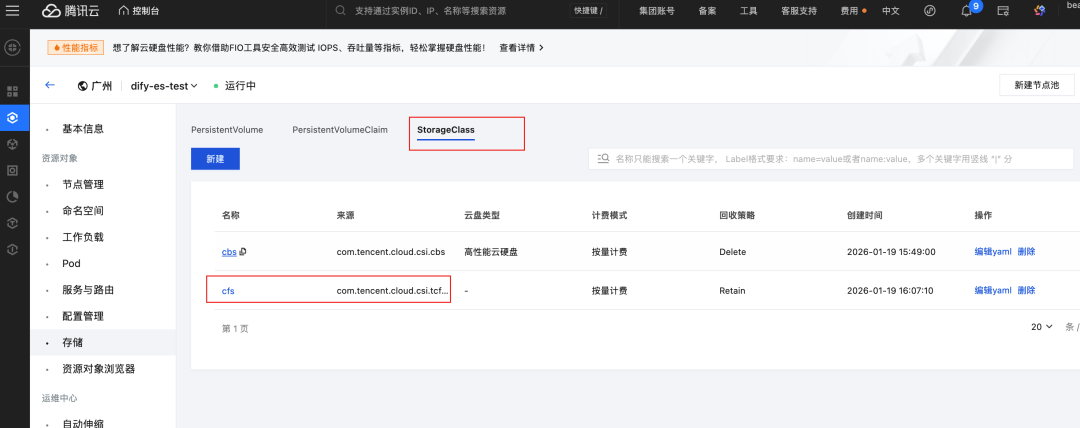
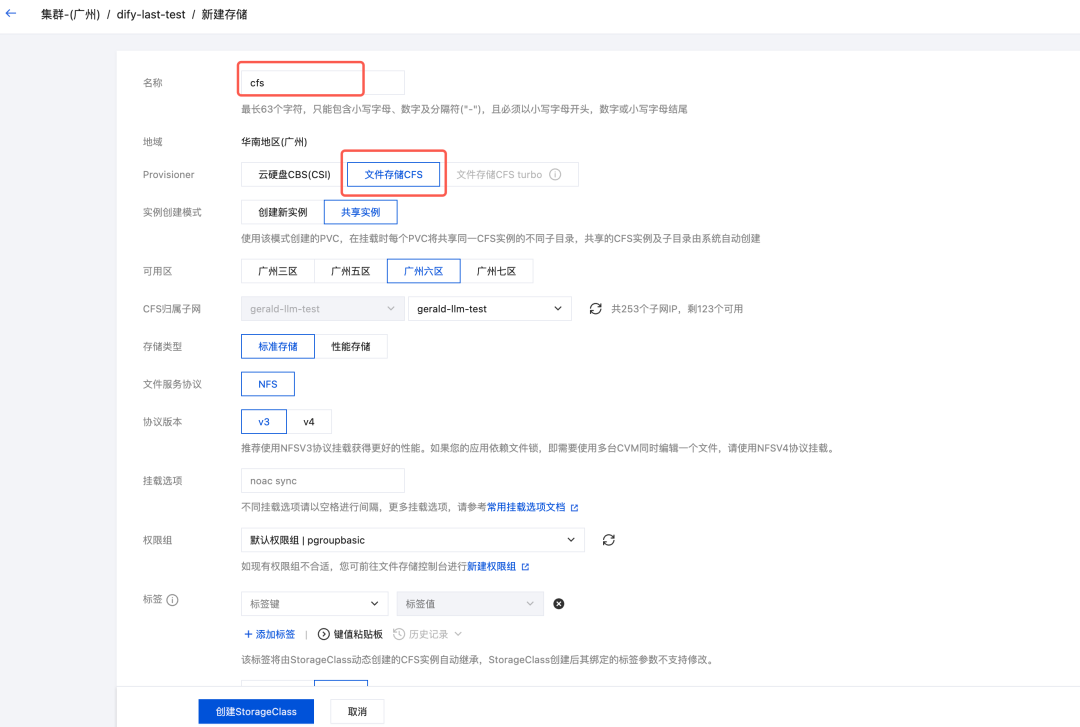
3.在存储中的 StorageClass 页签中创建命名为 cfs 的 Storageclass 对象,Provisioner选择文件存储cfs,保持子网一致。
4.部署 Dify
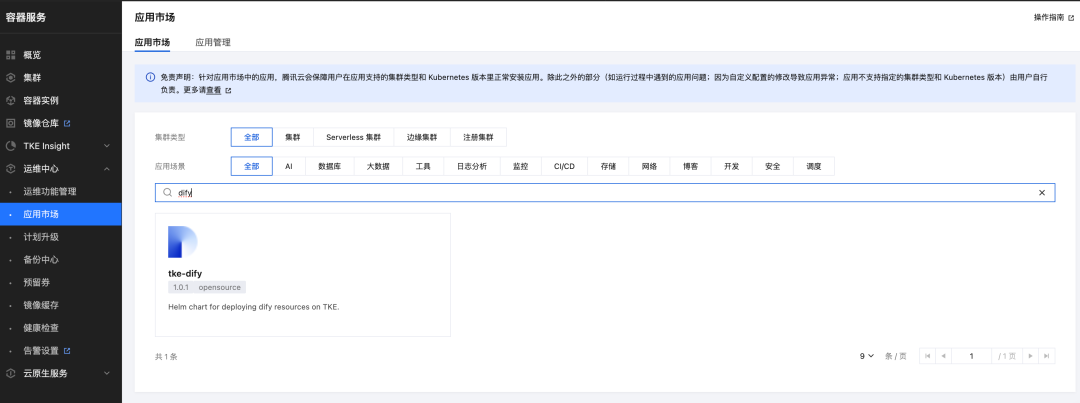
- 在应用市场中搜索 Dify 组件
- 在创建的 TKE 集群下,创建 Dify 应用,注意确认地域与集群信息
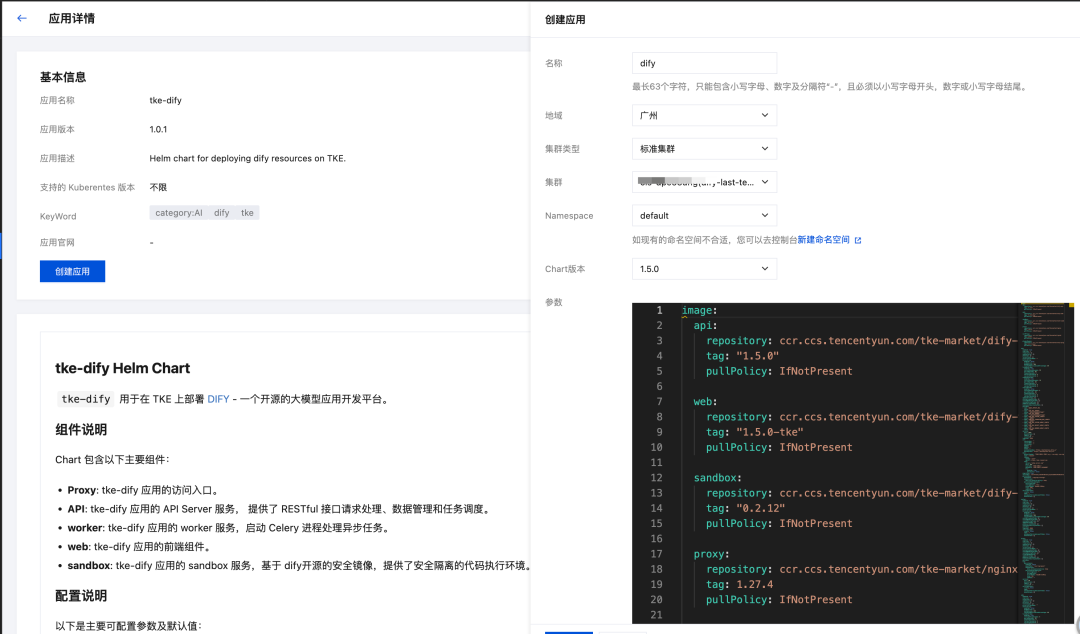
- 创建成功后,在应用管理中可查看已经部署的Dify。
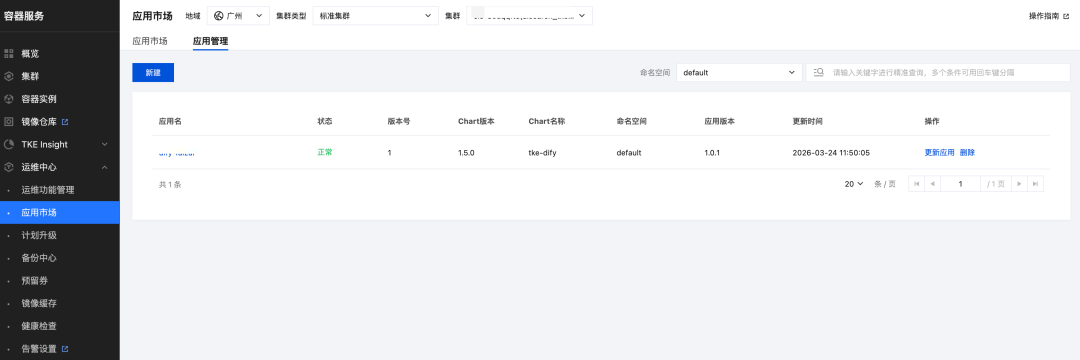
Dify 部署详情方案
- TKE 方案:https://cloud.tencent.com/document/product/457/118720
- 轻量应用服务方案: https://cloud.tencent.com/document/product/1207/123479 (轻量应用服务默认内网不互通,注意手动开启 https://cloud.tencent.com/document/product/1207/56847)
3.将向量库设置为 ES
Dify 默认的向量数据库为 Weaviate,默认随 Dify 部署,仅适合 Demo 或较小数据量使用。我们要利用 ES 强大的混合搜索能力,去提升整个 RAG 系统的精准度,所以在这一步,我们需要将默认的向量库配置变更为 ES。
以 TKE 为例(轻应用服务需要登录到机器中,在docker 目录,编辑 .env 配置文件)
1.进入 TKE 集群,在配置管理页面,修改 Dify 的 API 和 Work 两个配置,操作一致,可以在界面上修改,也可直接编辑YAML,以在页面上更新为例。
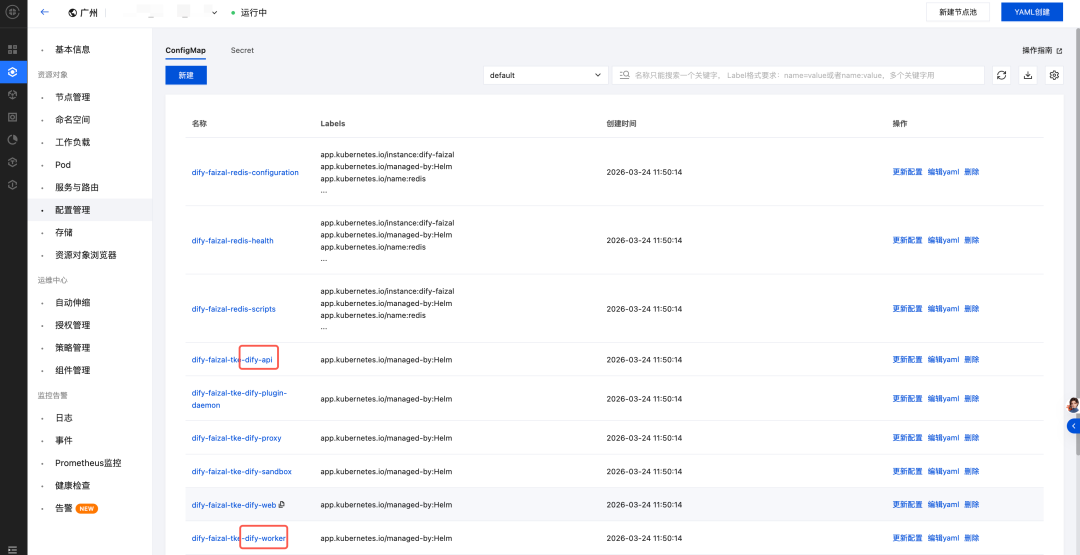
2.点击更新配置,更改如下配置项
- 将向量库原有 weaviate 改为 elasticsearch。
- 手动添加es相关配置,包括 Host、Port、Username、Password以及Kibana_Port(dify和es部署在同一vpc,HOST填写内网域名即可)
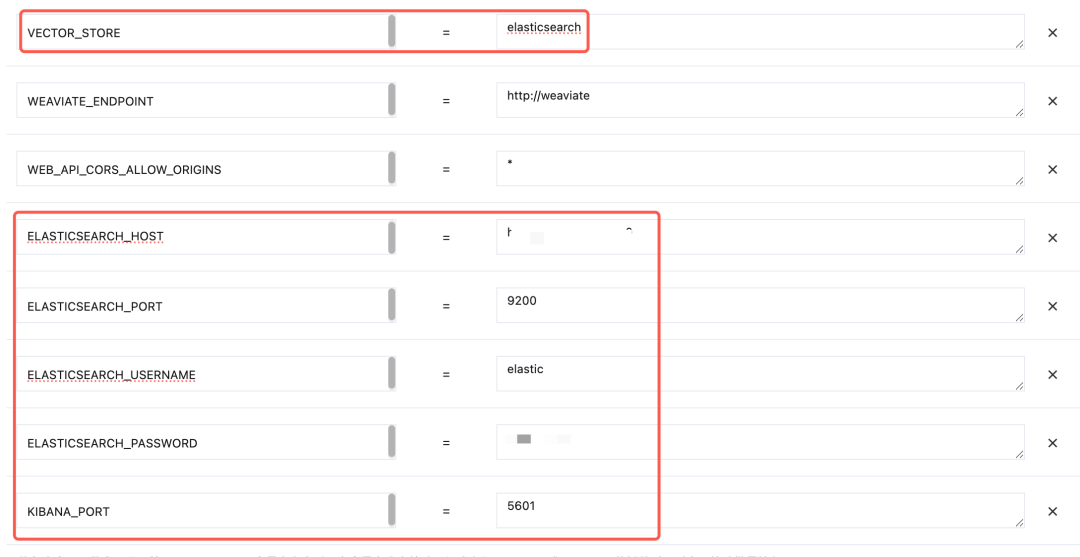
具体信息如下:
# VECTOR_STORE 修改为 elasticsearch
VECTOR_STORE=elasticsearch
# ES相关配置
ELASTICSEARCH_HOST=https://xxxxxxx # 注意这里的9200不要重复写
ELASTICSEARCH_PORT=9200
ELASTICSEARCH_USERNAME=elastic
ELASTICSEARCH_PASSWORD=PASSWORD
KIBANA_PORT=5601
3.重启工作负载
因为已经调整了 API 和 Worker 组件,需要重新部署更新,具体操作如下:
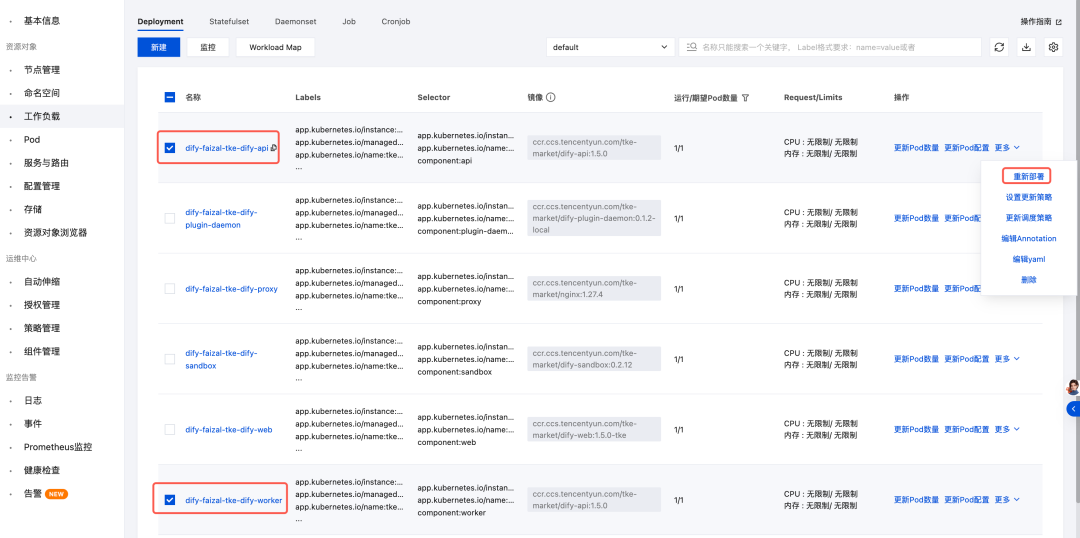
此时 Dify 使用的向量库就被修改成了 ES,我们还缺一个 Dify 服务入口。
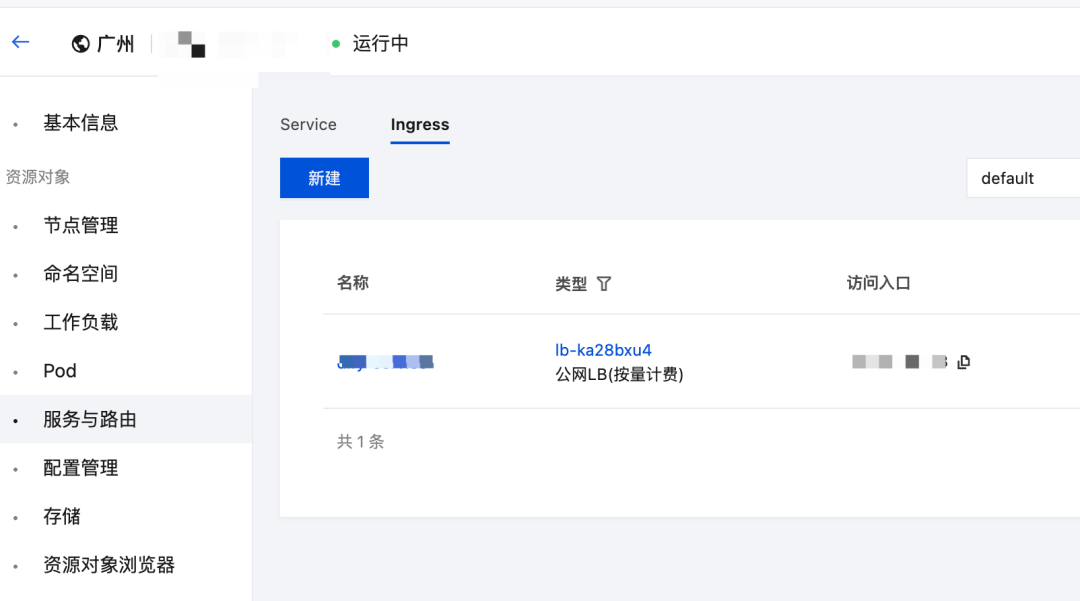
4.新建 Ingress
通过 Ingress 和 CLB 负载均衡将 Dify 服务暴露出来,并提供安全的访问方式。
具体操作如下:
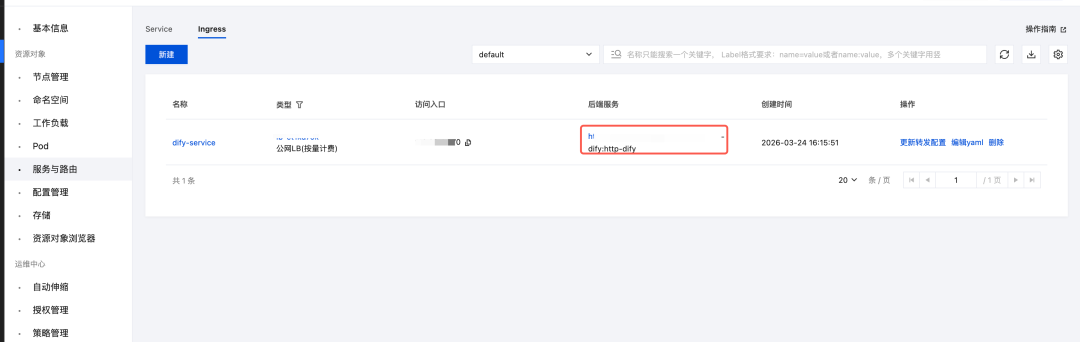
- 在【服务与路由】页面,切到 Ingress 页签,点击新建
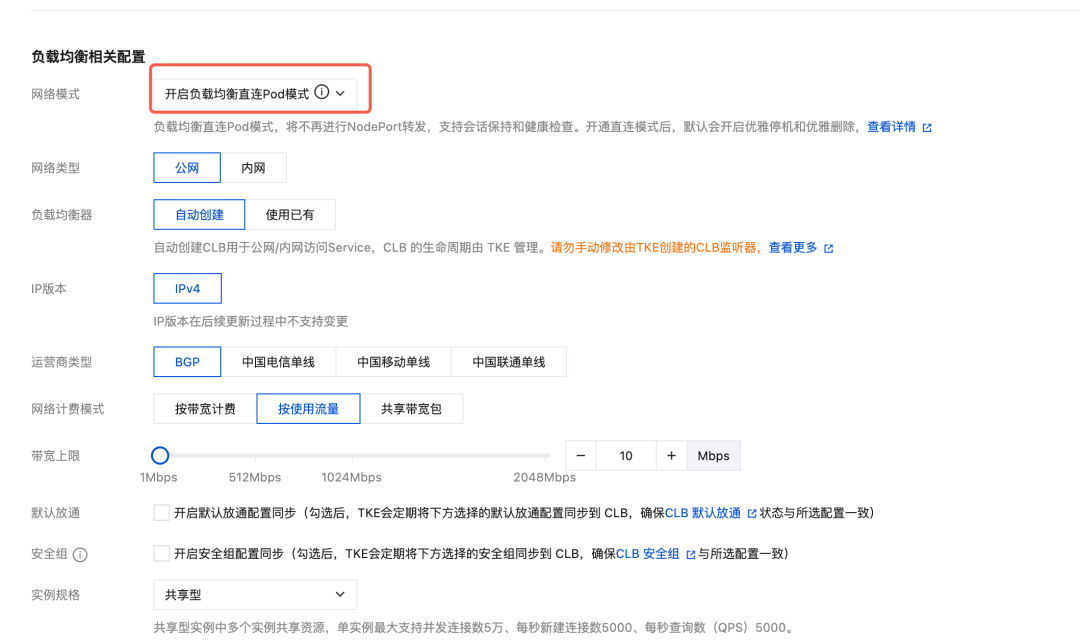
- 注意在网络模式要开启负载均衡直连Pod模式
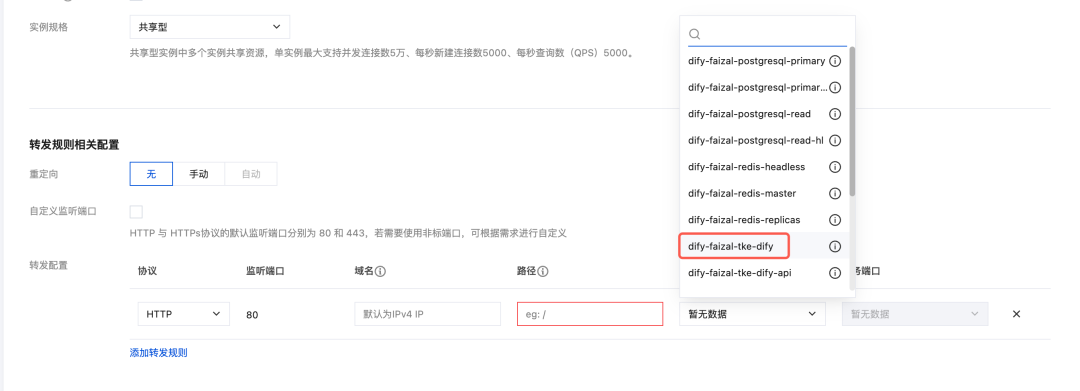
- 后端服务选择后缀为 tke-dify 的服务,路径直接斜杠就好,服务端口选择80
- 创建成功后,获得登录 Dify 地址
4.登录 Dify,配置模型服务
首次访问 Dify 需要先配置管理员账号,设置界面如下,然后根据设置的邮箱和密码进行登录,注意保存好管理员账号信息。
在搭建 RAG 过程中,除了本身需要文本和向量存储的 ES,还涉及 Embedding、Rerank 以及 LLM 等服务,在 Dify 上支持自定义和编排。
同时腾讯云 ES 提供两种模式的解决方案,进行上述服务的调用。
方案一:原子服务模式(推荐)
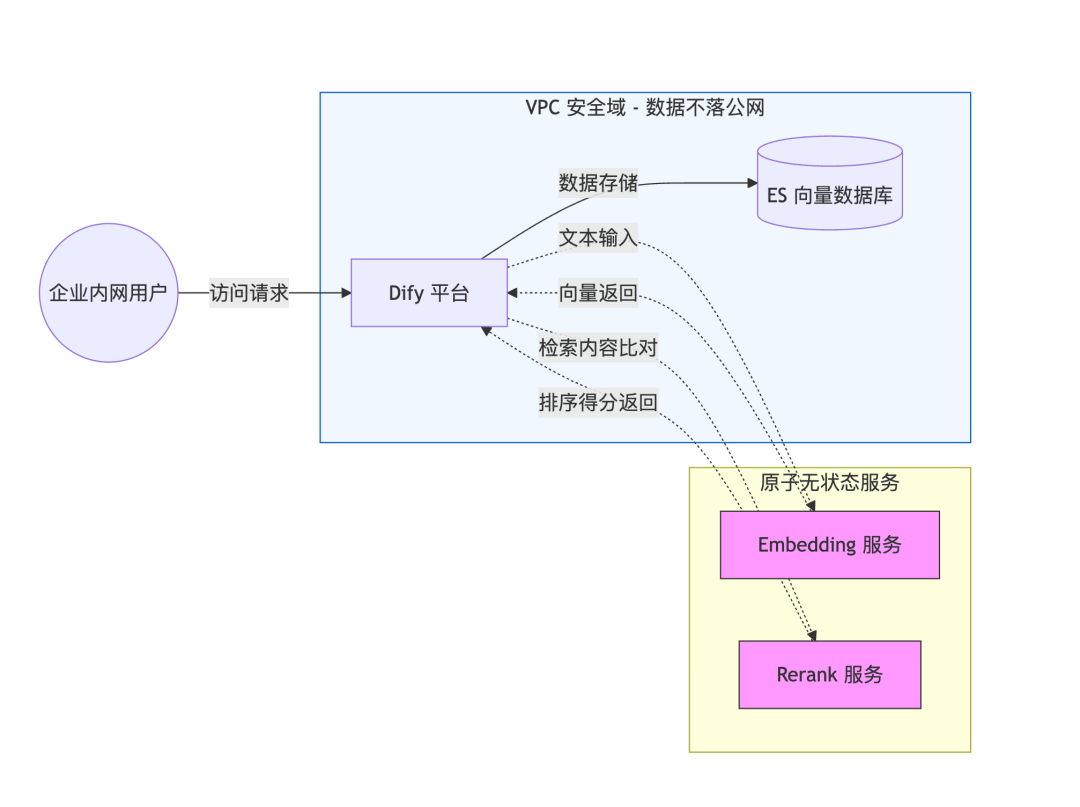
网络说明:
- 企业用户通过 VPC 内网来访问 Dify, Dify 通过 private link 访问 ES。
- 原子无状态服务位于腾讯云内网服务,Dify 所在的 VPC 默认开启腾讯云内网单向访问。
重点说明原子服务接口:
- 物理无存储:该服务被定义为“无状态计算单元”,其架构中不包含任何数据库或文件系统,文本流进入内存后,经由模型计算立即转化为向量或分值,原始文本在内存中停留时间以“毫秒”计,计算完成即释放,不留任何痕迹。
- 逻辑无留存:数据像自来水经过滤水器一样,只做加工,不做留存,系统日志仅记录 Request ID、User ID 和 Latency,明确禁止记录 Request Body,从源头上规避了日志泄露风险。
- 结果不可逆:Embedding 返回的是高维浮点数向量(如 1024 维数组)。本质上是有损压缩,在数学上也是多对一的映射,再加上模型内部的权重是复杂的非线性组合,导致这种转化是物理不可逆的。即使向量数据泄露,也无法反推出原始的文档信息。
具体操作:
1.进入Dify的插件页面
2.选择插件市场(注意在购买节点时要开公网,如因业务需要不能开公网,则需本地上传或直接拉取 Github 仓库:
https://github.com/langgenius/dify-plugins/tree/main/TencentCloud/ES
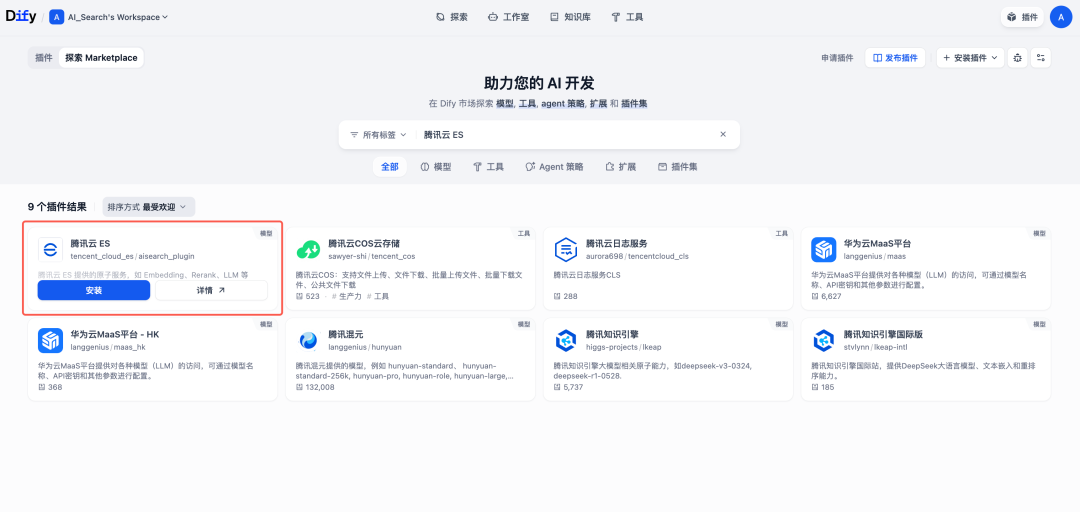
3.搜索腾讯云 ES,进行插件安装
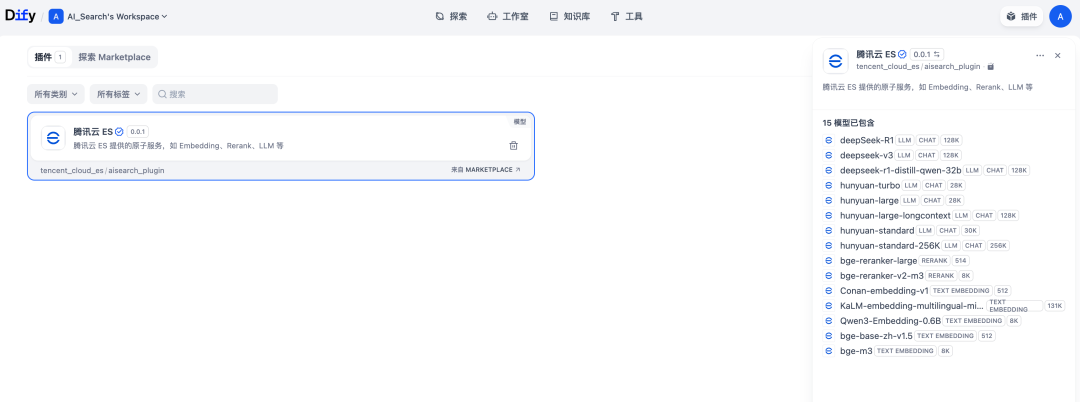
4. 插件安装成功后,可直接在入库和检索环节调用相关模型服务
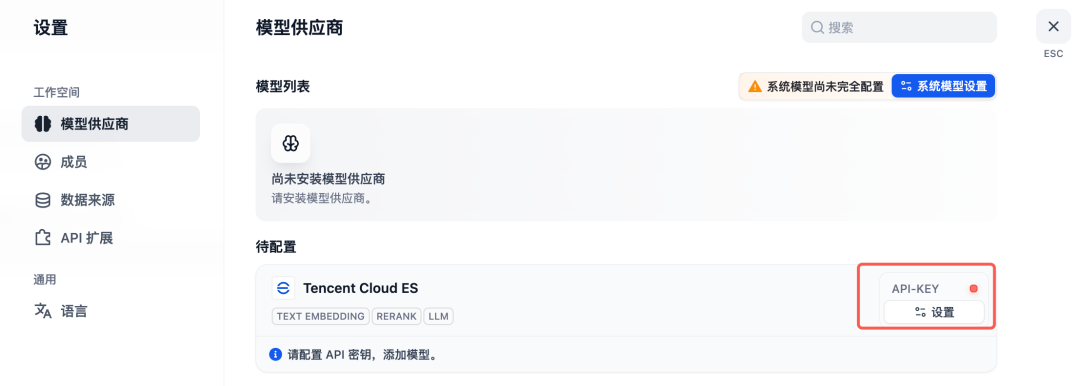
5.在进入设置页面设置模型的秘钥信息
6.选择模型供应商,配置腾讯云 ES 的原子服务接口调用信息, ID 和 Key 请从云API 获取。
方案二:机器学习节点模式
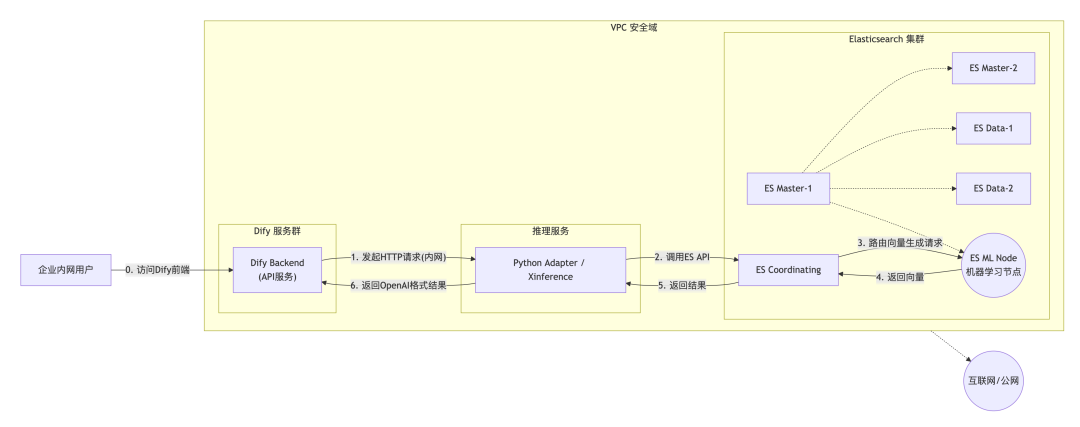
腾讯云 ES 机器学习节点目前仅支持 Embedding、Rerank 模型的部署。
方案安全说明:
- 企业用户通过 Private link 来访问 Dify。
- 所有的机器部署于腾讯云私有 VPC 网络中(Dify、服务节点、ES节点),不与公网交互。
- 腾讯云 VPC 可以开通单向出站访问公网能力(可选)
方案链路说明:
1.因为 Dify 不知道如何直接调用 ES 的 _infer API,因此需要写一个极简的 Python Web 服务(Adapter),将 ES 的私有推理接口转换成 OpenAI 兼容接口。
2.架构: Dify -> Python Adapter (VPC内) -> ES ML Node (_infer API)
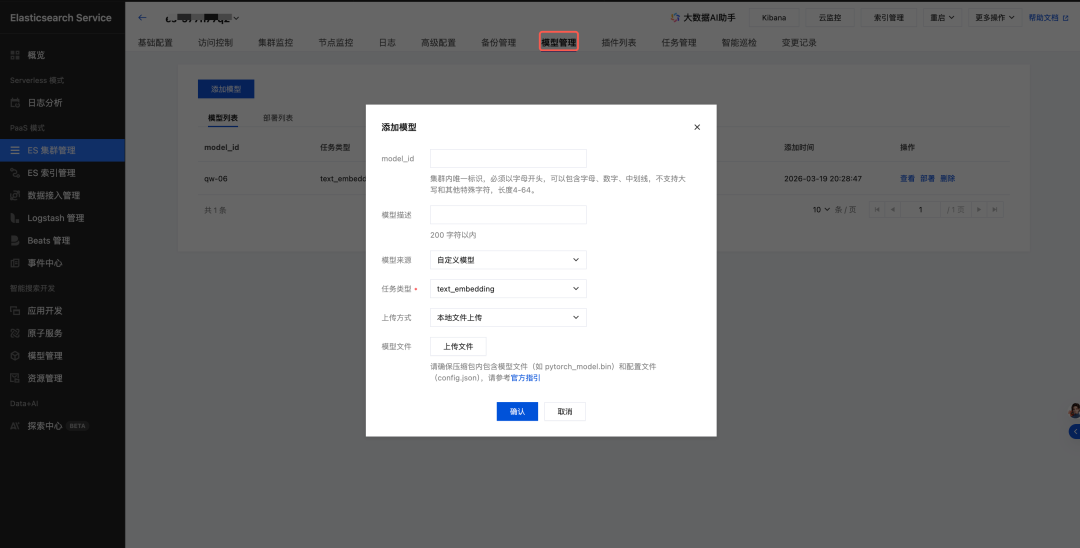
实施路径:
1.在 ES 中部署模型: 在 ES 控制台上传模型,注意如要部署模型,需提前购买 ES机器学习节点
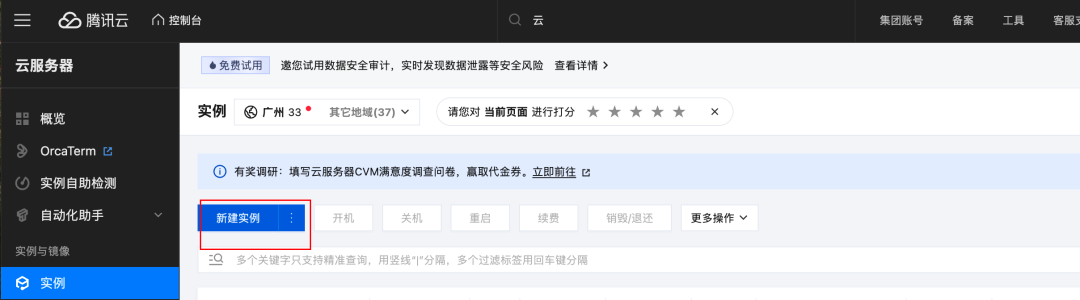
2.部署 Adapter,创建一个简单的 Flask/FastAPI 服务,部署在CVM 上
这里以embedding为例,在 CVM 部署一个简单的协议转换服务。
- 登录云服务器控制台,进入登录-腾讯云(https://console.cloud.tencent.com/cvm/instance)页面,单击新建实例,购买 CVM,注意网络配置选择和 ES 集群同 VPC 下
- 登录 CVM,安装Python3
sudo yum update -ysudo yum install -y python3 git - 上传 main.py 文件和 requirements.txt 文件到服务器(可控制台上传),修改ES_URL,ES_USER,ES_PASS,ES_MODEL_ID 为你的 ES 集群的配置
importosimportasyncioimportloggingfromtypingimportUnion,ListfromfastapiimportFastAPI,HTTPExceptionfrompydanticimportBaseModelfromelasticsearchimportElasticsearch# 配置日志logging.basicConfig(level=logging.INFO,format='%(asctime)s- %(name)s- %(levelname)s- %(message)s',handlers=[logging.FileHandler('embedding_service.log'), # 输出到文件logging.StreamHandler() # 同时输出到控制台])logger=logging.getLogger(__name__)ES_URL=os.getenv("ES_URL","http://you_es_internal_ip:9200") # ES内网ipES_USER=os.getenv("ES_USER","username") # ES用户名ES_PASS=os.getenv("ES_PASS","password") # ES密码ES_MODEL_ID=os.getenv("ES_MODEL_ID","es_model_id") # ES部署的模型idapp=FastAPI()# 全局变量存储ES连接,初始化为Nonees=NoneclassEmbeddingRequest(BaseModel):input:Union[str,List[str]]model:str@app.on_event("startup")asyncdefstartup_event():"""应用启动时创建ES连接"""globales# 添加证书验证配置,提高连接稳定性es=Elasticsearch(ES_URL,basic_auth=(ES_USER,ES_PASS),verify_certs=False # 如果是自签名证书或测试环境,关闭证书验证)logger.info("Elasticsearch连接已建立")@app.on_event("shutdown")asyncdefshutdown_event():"""应用关闭时关闭ES连接"""globalesifes:es.close()logger.info("Elasticsearch连接已关闭")@app.post("/v1/embeddings")asyncdefcreate_embeddings(request:EmbeddingRequest):texts= [request.input] ifisinstance(request.input,str)elserequest.inputifnottexts:raiseHTTPException(status_code=400,detail="input empty")# 构造 ESdocs(字段名需与模型训练时一致,使用text_field字段)docs= [{"text_field":t} fortintexts]loop=asyncio.get_event_loop()try:# 使用requests库直接调用ESAPI,避免transport的限制importrequestsimportjsonurl=f"{ES_URL}/_ml/trained_models/{ES_MODEL_ID}/_infer"body= {"docs":docs}# 构建认证头auth=(ES_USER,ES_PASS)headers= {"Content-Type":"application/json"}resp=awaitloop.run_in_executor(None,lambda:requests.post(url,auth=auth,headers=headers,json=body,verify=False, # 关闭证书验证timeout=30))# 检查响应状态ifresp.status_code !=200:raiseException(f"ES API返回错误状态: {resp.status_code}, 响应: {resp.text}")resp_data=resp.json()logger.info(f"ES推理响应状态: {resp.status_code}")exceptExceptionase:logger.error(f"ES推理错误详情: {e}")raiseHTTPException(status_code=502,detail=f"ES infer error: {e}")# 根据ES返回结构解析predicted_valueinference_results=resp_data.get("inference_results", [])embeddings= []fori,resultinenumerate(inference_results):predicted_value=result.get("predicted_value")ifpredicted_value:embeddings.append(predicted_value)logger.info(f"成功获取第{i}个文本的嵌入向量,长度: {len(predicted_value)}")else:logger.error(f"第{i}个结果中未找到predicted_value,结果结构: {result}")raiseHTTPException(status_code=500,detail=f"No predicted_value found in result {i}")ifnotembeddings:logger.error(f"未找到任何嵌入向量,完整响应: {resp_data}")raiseHTTPException(status_code=500,detail="No embeddings generated from ES")return {"object":"list","data": [{"object":"embedding","embedding":emb,"index":i} fori,embinenumerate(embeddings)],"model":request.model,"usage": {"prompt_tokens":sum(len(text)fortextintexts),"total_tokens":sum(len(text)fortextintexts)}}requirement.txtfastapi==0.83.0uvicorn[standard]==0.16.0elasticsearch==8.11.0pydantic==1.9.0requests==2.25.1 - 创建虚拟环境并安装依赖
python3 -m venv venvsource venv/bin/activatepip install --upgrade pippip install -r requirement.txtdeactivate - 启动服务
nohup uvicorn main:app --host 0.0.0.0 --port 8000> service.log 2>&1 & - 测试服务(ES集群模型部署好再测)
curl -X POST "http://localhost:8000/v1/embeddings" -H "Content-Type: application/json" -d '{ "input": "这是一个测试文本", "model": "bge-base-zh-v1.5"}'
3.Dify 配置模型服务,与原子服务类似,Dify 提供了 OpenAI-API-Compatible 插件,我们需要安装这个插件,将我们的模型服务转发进来
- 登录 Dify,搜索并安装 OpenAI-API-compatible 插件
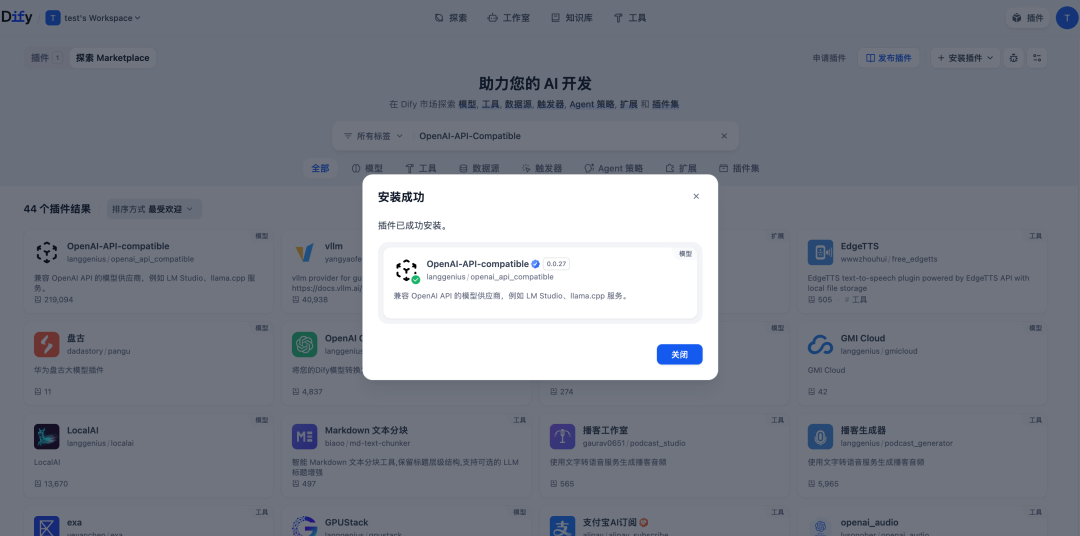
- 设置模型供应商:单击右上角选择设置,选择 OpenAI-API-compatible 插件,点击添加模型,API URL配置为上述CVM中部署的自定义中转服务,我这里没有设置 API key,可随便填即可
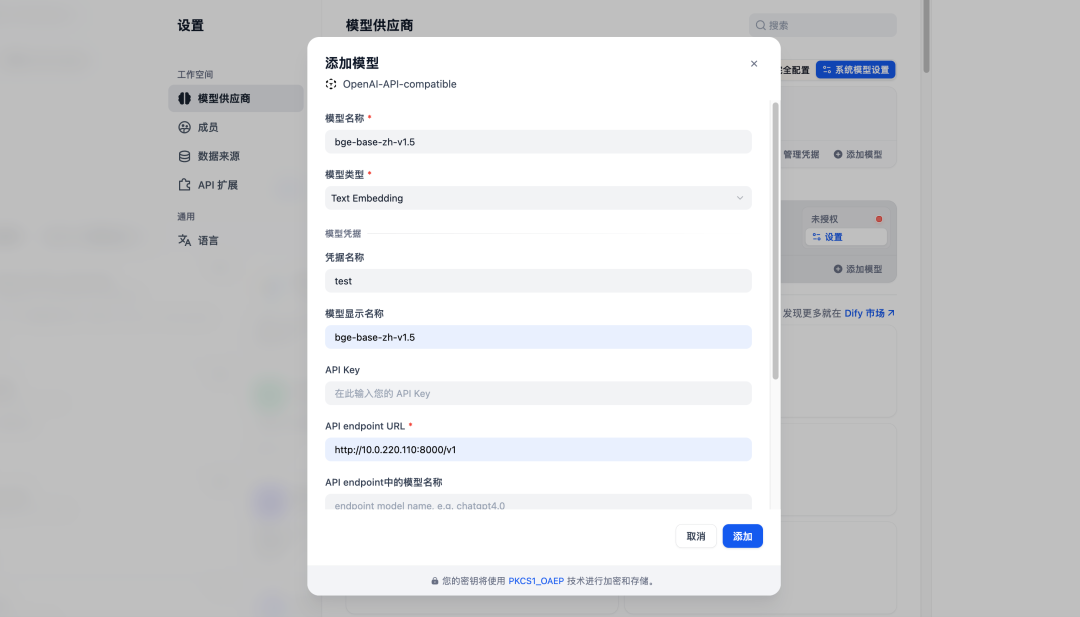
OpenAI-API-Compatible 并非一个需要独立下载的大型插件或运行时环境,它只是 Dify 内部的一个驱动程序或模型协议解析器,所以它也是在 VPC 下的,不涉及出域。
5.测试验证
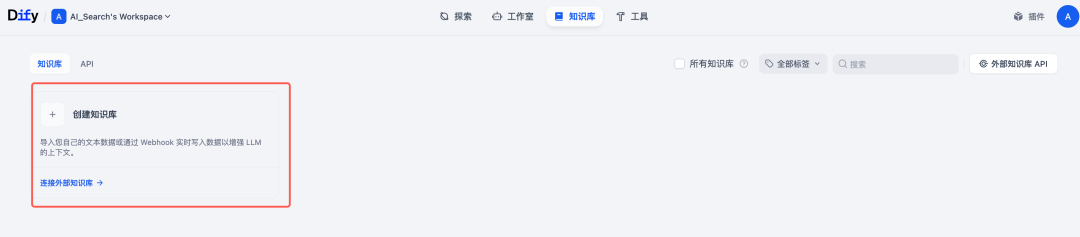
1.创建知识库,并导入文档
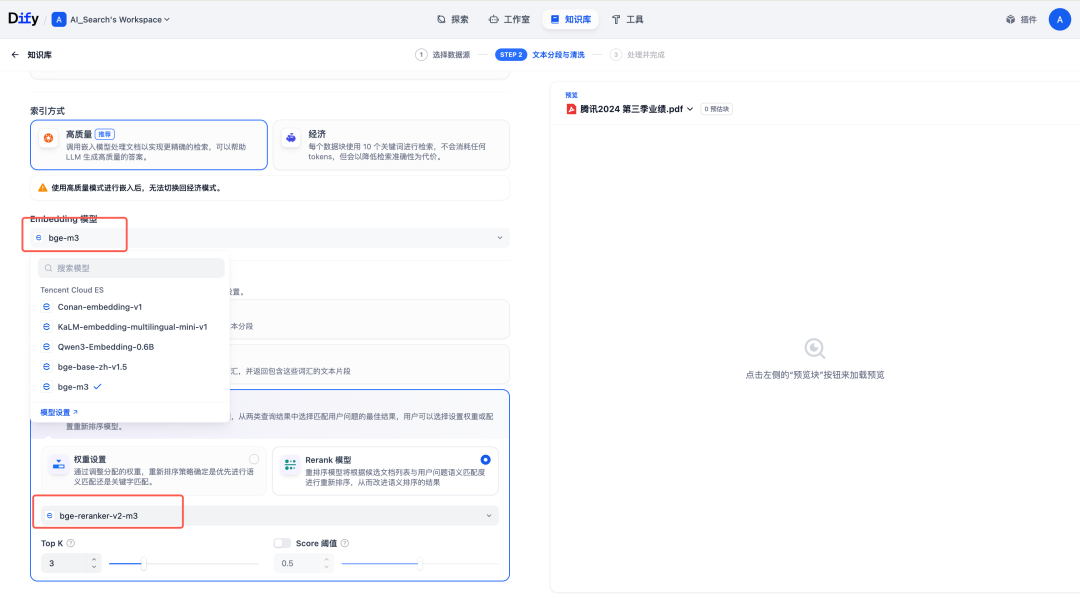
2.配置 Embedding 和混合检索
3.完成文档导入和向量化
4.在 ES 中查看数据是否写入成功,进入 ES 控制台查看对应集群的索引
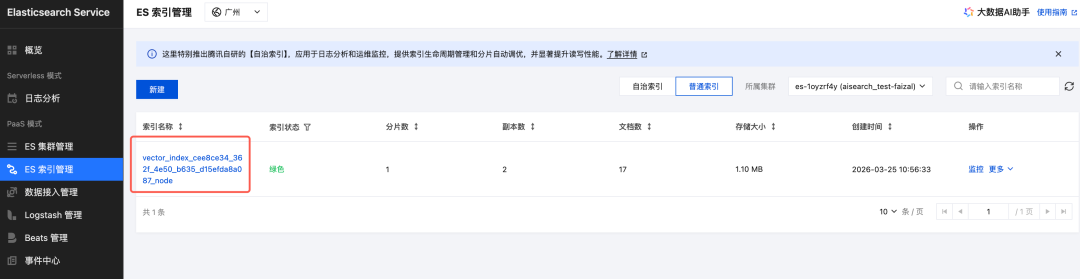
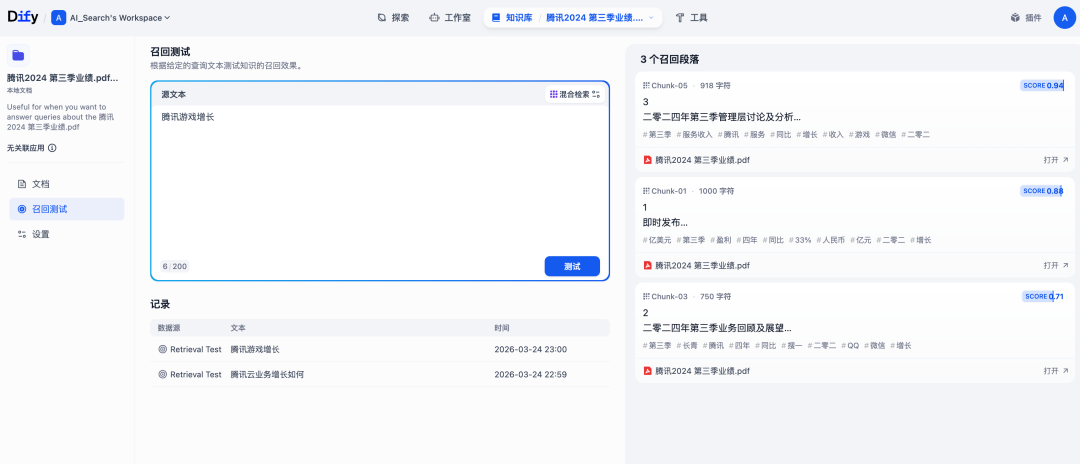
5.在知识库中召回测试,召回成功如下
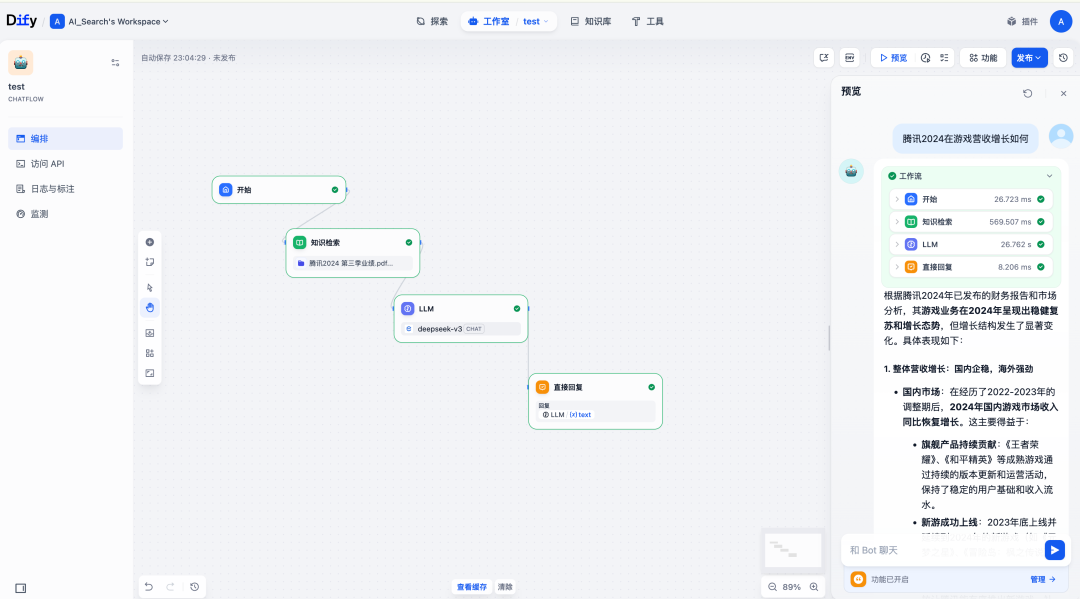
6.应用编排测试,可进行知识库检索以及LLM调用
四、结语
在 AI 原生应用的浪潮中,RAG 已经完成了从实验项目到生产工具的蜕变,它正在成为企业决策的核心知识系统。在那些充斥着专业术语、复杂逻辑、且对数据安全有极高要求的企业核心场景里,腾讯云 ES 以其多年的技术积淀,证明了在混合检索、大规模并发及索引管理上的统治力。
构建一套生产级的 RAG 系统并非终点,而是一个持续进化的起点。随着 Agentic RAG 的深入,腾讯云 ES 将在索引构建、查询理解、检索排序到结果生成全链路 AI 化,成为 AI 时代最具竞争力的搜索基础设施,不仅仅服务人类用户,更要成为面向千万级 Agent 的核心检索层。
END

清明节兼具自然与人文两大内涵,既是自然节气点,也是传统节日。扫墓祭祖与踏青郊游是清明节的两大礼俗主题,这两大传统礼俗在中国自古传承,至今不辍。

关注腾讯云大数据╳探索数据的无限可能
往期精彩



求点赞

求分享

求喜欢

本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号