【译】混合专家(Mixture of Experts, MoE)

【译】混合专家(Mixture of Experts, MoE)

AlphaHinex
发布于 2026-04-09 21:00:17
发布于 2026-04-09 21:00:17
- 原文地址:Mixture of Experts (MoE)[1]
- 原文作者:Sebastian Raschka[2]
混合专家(Mixture of Experts, MoE)是近年来开源大模型能够拥有极高的总参数量,又不会使每次推理的代价同等昂贵的主要原因之一。
其基本思想是,用多个专家型前馈块(FeedForward blocks)替换单一的稠密前馈块,然后通过路由让每个 token 只激活其中的一小部分。
- 架构画廊[3]
- 《从零构建大模型》章节[4]
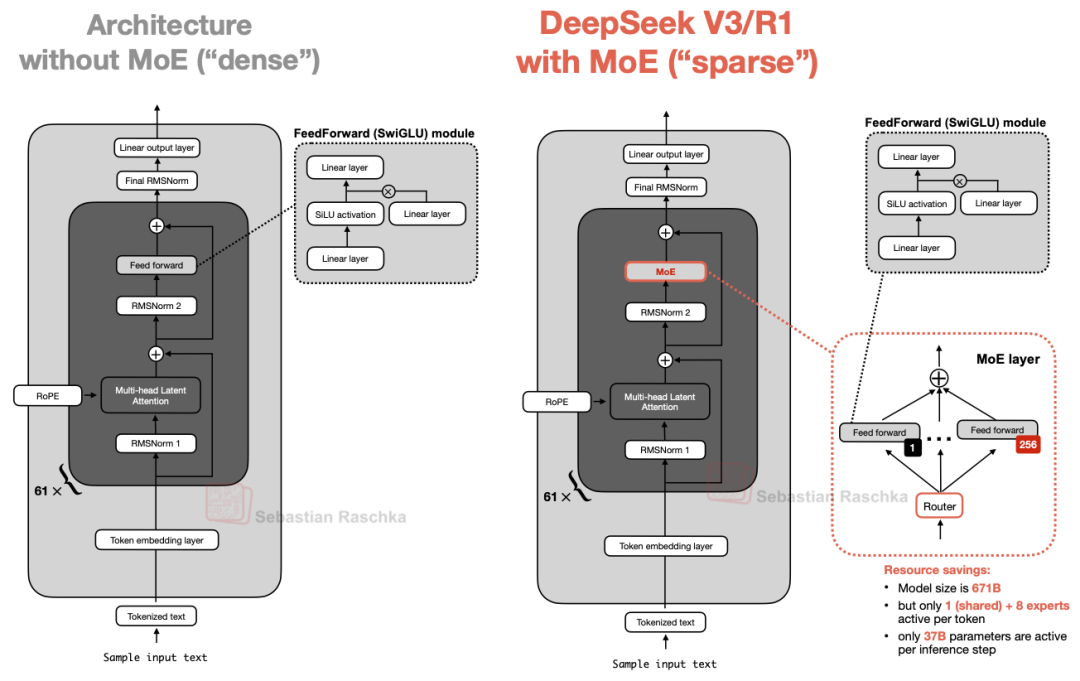
DeepSeek V3 和 R1 中的混合专家模块与标准前馈块的对比
DeepSeek V3 和 R1 中的混合专家模块与标准前馈块的对比
引自 大语言模型架构对比[5]:主要结构的变化非常直接。一个单一的稠密前馈块被一个带有多个专家的路由 MoE 模块所取代。
- 改变了什么:一个稠密前馈路径变成了多个专家前馈路径,外加一个路由
- 实际好处:模型可以拥有更高的总容量,同时每个 token 只激活较小的路径
- 示例架构:DeepSeek V3[6]、Qwen3 235B-A22B[7]、GPT-OSS 120B[8]、Mistral Large 3[9]、GLM-5 744B[10] 和 MiniMax M2 230B[11]
为什么重要
前馈块已占据了 transformer 层中很大一部分参数。因此,当我们用多个专家块替换一个前馈块时,模型的总参数量可以显著增加。
关键点是,路由不会为每个 token 激活所有专家。它只选择一个小的子集。这就是为什么 MoE 模型可以在总容量上非常大,同时在每次推理步骤中只使用较少的活跃参数。
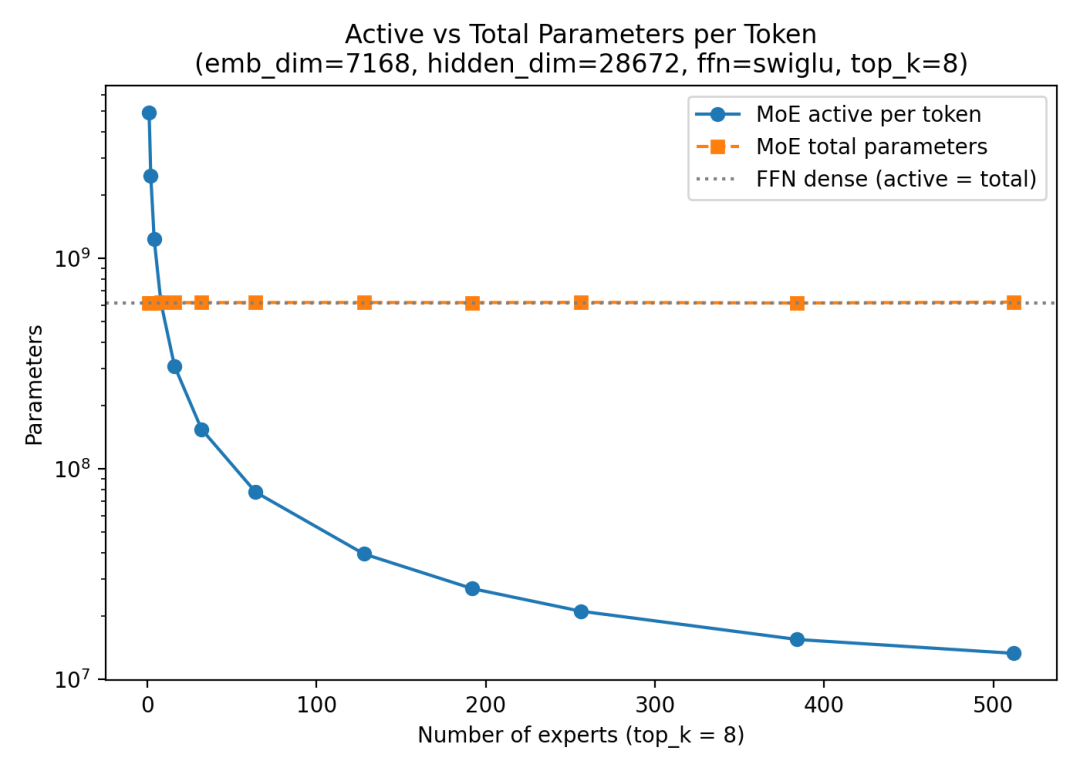
混合专家层中总参数与活跃参数的差异
混合专家层中总参数与活跃参数的差异
引自《从零构建大模型》中 MoE 材料:随着专家数量的增加,总参数的增长速度远快于每个 token 的活跃参数。
这里的“稀疏”是什么意思
MoE 层通常被描述为稀疏的,因为并非每个 token 都使用所有专家。模型很大,但每个 token 的计算是有选择性的。
这也是为什么 MoE 模型经常同时列出总参数和活跃参数的原因。DeepSeek V3 就是一个典型的例子:总参数量非常大,但每个步骤只激活了一个更小的子集。
共享专家及其变体
随着 MoE 的基本思想被广泛采用,各团队开始对细节进行不同的调整。例如,“共享专家”就是除了路由选择的专家外,始终保持激活的专家;还有“潜在 MoE”(latent MoE[12]),如 Nemotron 3 Super,将专家计算迁移到更小的潜在空间中。
所以,虽然许多模型被称为 MoE 模型,但它们在专家数量、每个 token 的路由专家数、是否使用共享专家以及专家子网络的大小方面仍然可能有很大差异。
示例架构
- DeepSeek V3[13]:画廊中最清晰的 MoE 参考点
- Qwen3 235B-A22B[14]:一个当前的大规模开放 MoE 模型,具有 GQA
- GPT-OSS 120B[15]:一个稀疏的 MoE 堆栈,具有交替的局部和全局注意力
- Mistral Large 3[16]:另一个 DeepSeek 风格的 MoE 架构
参考来源
- 大语言模型架构对比[17]
- 《从零构建大模型》MoE 章节[18]
参考资料
[1]
Mixture of Experts (MoE): https://sebastianraschka.com/llm-architecture-gallery/moe/
[2]
Sebastian Raschka: https://sebastianraschka.com/
[3]
架构画廊: https://sebastianraschka.com/llm-architecture-gallery/
[4]
《从零构建大模型》章节: https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04/07_moe
[5]
大语言模型架构对比: https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
[6]
DeepSeek V3: https://sebastianraschka.com/llm-architecture-gallery/#card-deepseek-v3
[7]
Qwen3 235B-A22B: https://sebastianraschka.com/llm-architecture-gallery/#card-qwen3-235b-a22b
[8]
GPT-OSS 120B: https://sebastianraschka.com/llm-architecture-gallery/#card-gpt-oss-120b
[9]
Mistral Large 3: https://sebastianraschka.com/llm-architecture-gallery/#card-mistral-large-3
[10]
GLM-5 744B: https://sebastianraschka.com/llm-architecture-gallery/#card-glm-5-744b
[11]
MiniMax M2 230B: https://sebastianraschka.com/llm-architecture-gallery/#card-minimax-m2-230b
[12]
latent MoE: https://sebastianraschka.com/llm-architecture-gallery/latent-moe/
[13]
DeepSeek V3: https://sebastianraschka.com/llm-architecture-gallery/#card-deepseek-v3
[14]
Qwen3 235B-A22B: https://sebastianraschka.com/llm-architecture-gallery/#card-qwen3-235b-a22b
[15]
GPT-OSS 120B: https://sebastianraschka.com/llm-architecture-gallery/#card-gpt-oss-120b
[16]
Mistral Large 3: https://sebastianraschka.com/llm-architecture-gallery/#card-mistral-large-3
[17]
大语言模型架构对比: https://magazine.sebastianraschka.com/p/the-big-llm-architecture-comparison
[18]
《从零构建大模型》MoE 章节: https://github.com/rasbt/LLMs-from-scratch/tree/main/ch04/07_moe
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号