别再用云API了!手把手教你把大模型“装进自己电脑”


文章前言
在深入学习大模型的过程中"如何本地部署一个可用的大模"是每个学习者都会遇到的关键环节。相较于直接调用云端服务,本地部署大模型(Local LLM Deployment)不仅是理解模型工作原理的重要途径,更是实现自主研发与个性化应用的必经之路。通过本地部署我们可以在完全掌控数据与环境的前提下深入体验模型加载、推理、优化、微调等全过程,真正做到"从使用到理解,从理解到创造"。同时本地部署具备免费、隐私、安全、灵活、高效等多重优势,让学习者能在离线或局域环境中自由探索AI的潜力
基本介绍
大模型(Large Model,LM)是指参数规模达到亿级甚至千亿级的深度学习模型,它主要基于深度学习(Deep Learning)、Transformer架构实现高效并行化训练,其核心特征包括海量数据处理能力、多任务泛化性以及通过预训练和微调适应不同场景,从而具备理解、生成、推理和创造等多种智能能力,目前被广泛应用于自然语言生成、多模态交互、科学计算等领域
运行框架
框架介绍
Ollama是一个开源的本地大语言模型运行框架,它旨在让普通用户和开发者能够以极低的门槛在本地电脑(macOS、Windows、Linux)上直接下载、运行和管理各种开源大语言模型(LLM)及多模态模型,它本质上其实是提供了一个统一的运行时环境 + 模型包管理器 + OpenAI风格的本地API服务。Ollama解决了云端大模型带来的三大痛点:数据隐私泄露风险(所有推理完全本地)、网络依赖与延迟问题(断网也能用)、高昂的API调用费用,让个人开发者、小团队、隐私敏感场景、企业内网、离线环境都能低成本、高控制力地使用目前最强的开源智能能力
框架安装
Step 1:访问ollama的官网地址并选择对应系统版本,下载安装包
https://ollama.com/download
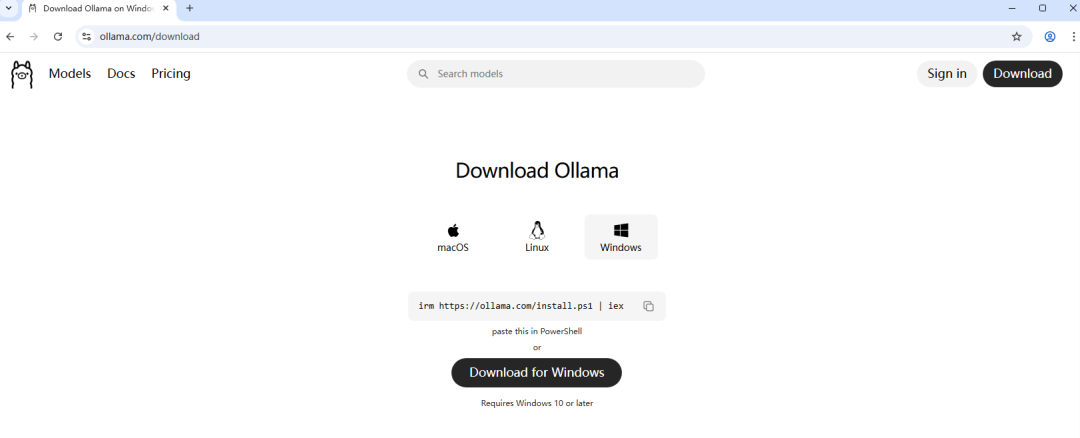
这里从官网下载有点慢,我们可以直接访问GIthub选择对应的下载软件包版本并复制链接
https://github.com/ollama/ollama/releases
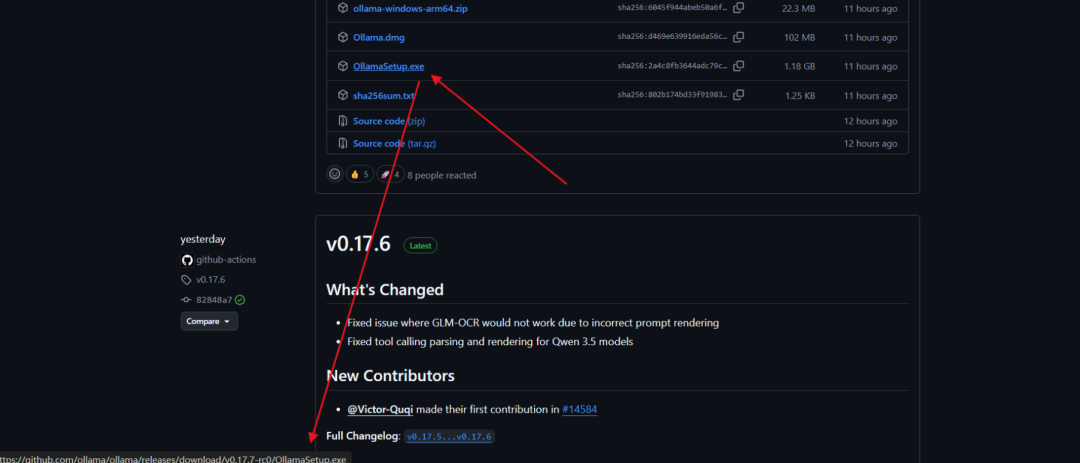
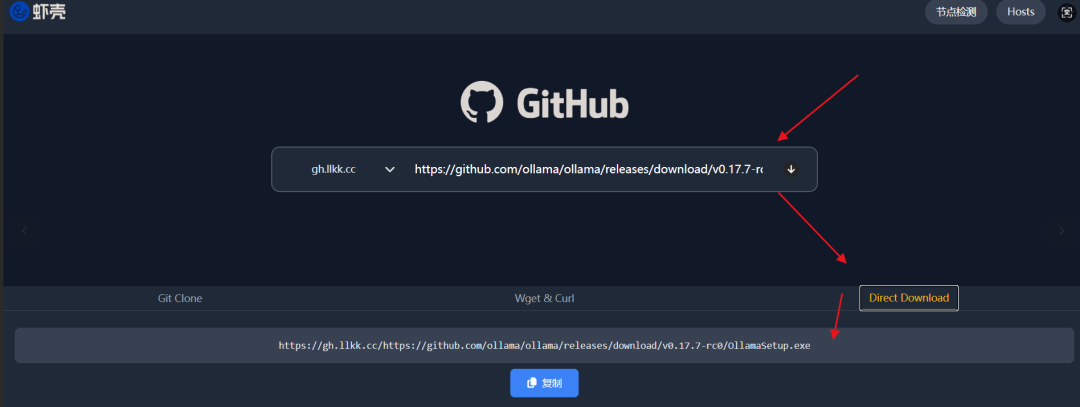
随后使用虾壳来生成加速下载链接:
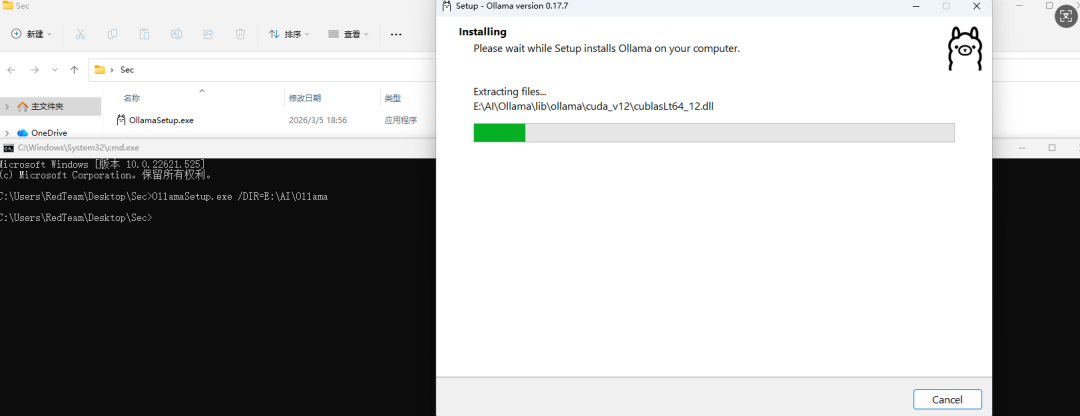
Step 2:运行安装包并按照提示完成安装
Ollama默认装位置一般会在"C:\Users\xxx\AppData\Local\Programs\Ollama"进行存储,对于下载的模型(models及其配置文件)位置一般会在"C:\Users\xxx\.ollama"存储,我们可以直接通过以下方式来将Ollama安装到指定的目录下
OllamaSetup.exe /DIR=E:\AI\Ollama #DIR= 后面是你想把ollma安装到的文件的目录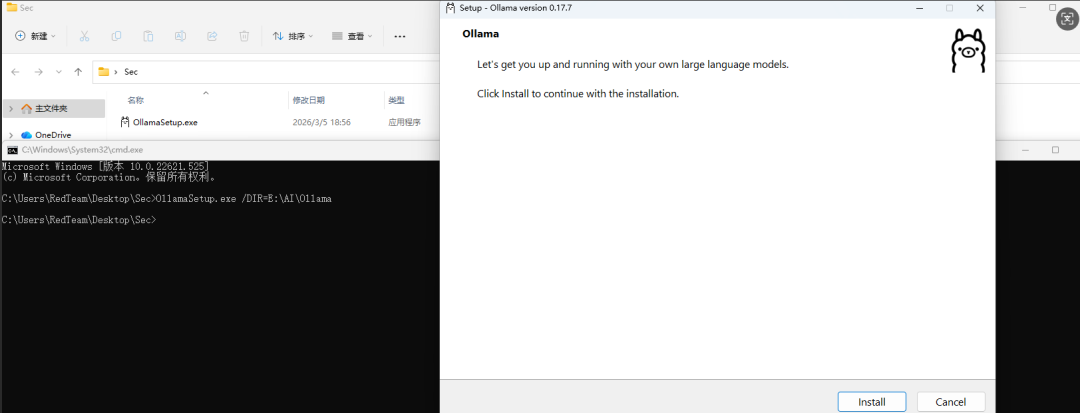
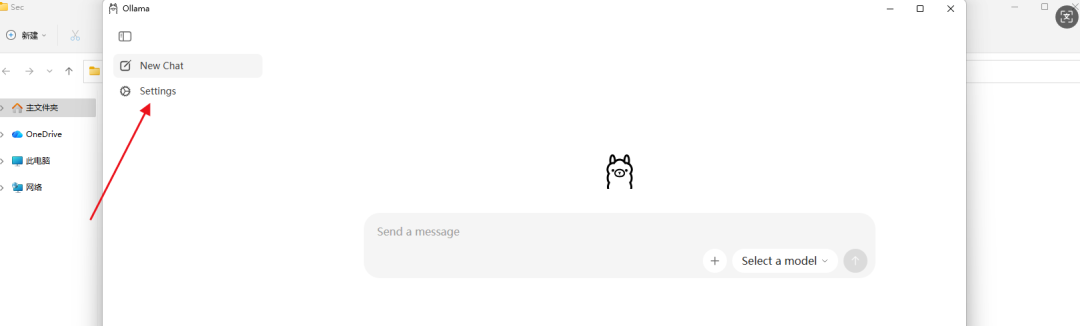
Step 3:模型下载位置更改
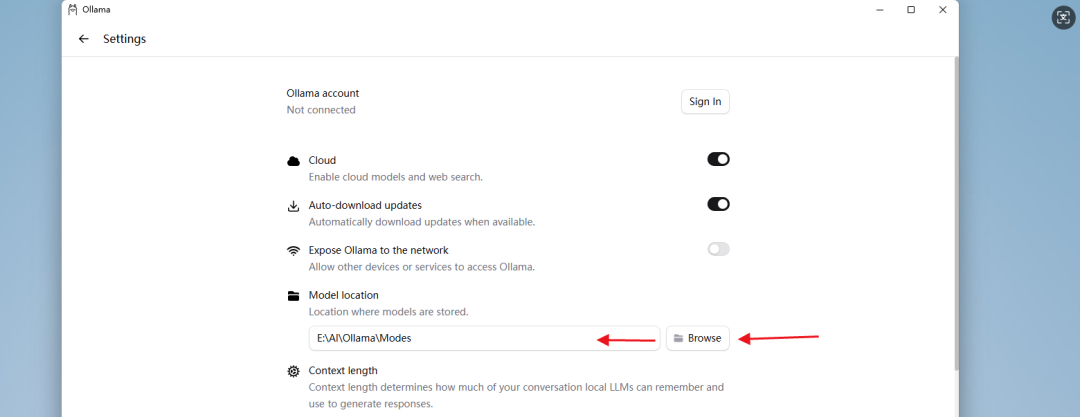
Step 4:系统环境变量配置
PATH变量:E:\AI\Ollama
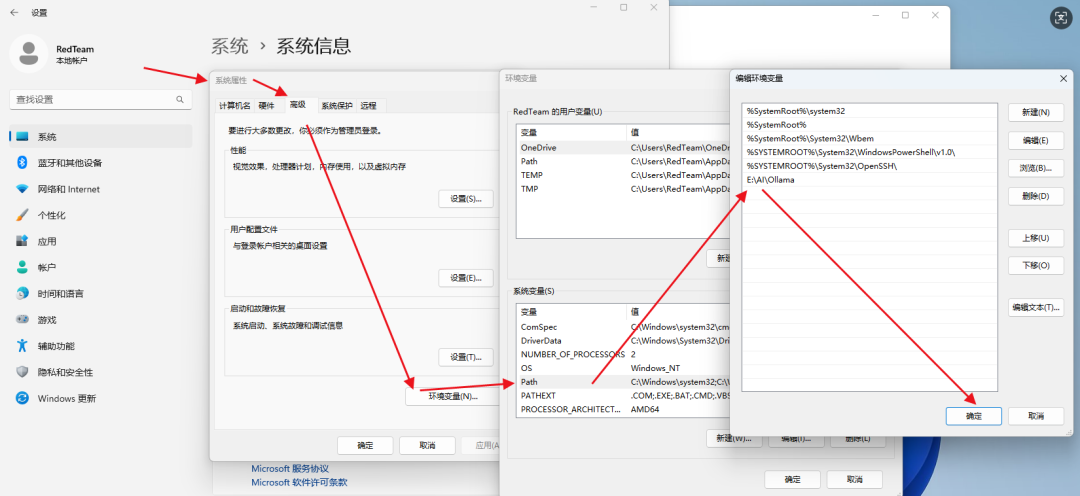
新建环境变量:
OLLAMA_MODELS:E:\AI\Ollama\Modes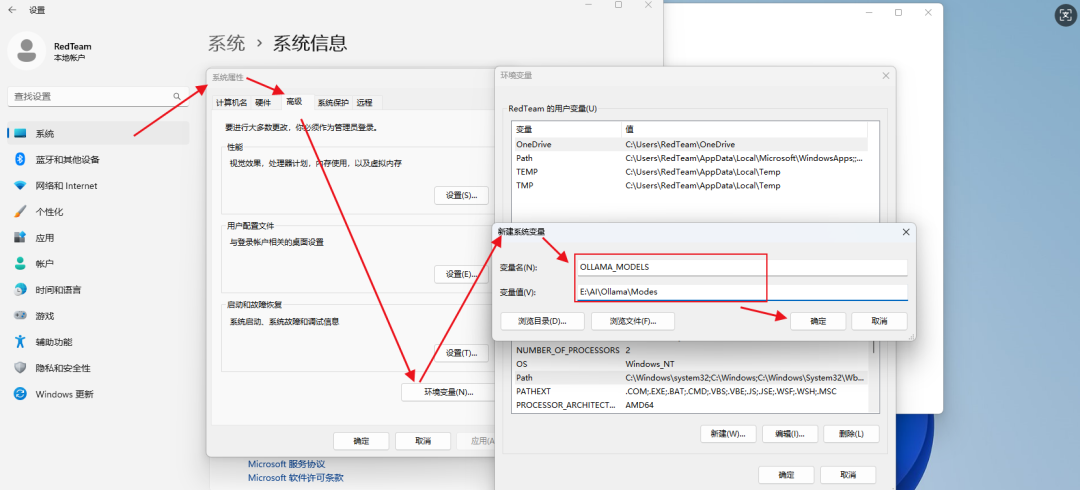
Step :5:测试模型是否安装成功
ollama --version
命令参数
帮助信息
ollama help
命令汇总:
命令 | 说明 | 常用参数 / 示例 | 备注 |
|---|---|---|---|
ollama run | 运行指定模型(例如:未下载则自动pull) | ollama run llama3:8b | 启动后进入交互模式,可直接输入prompt交互 |
ollama pull | 下载/更新模型到本地存储 | ollama pull deepseek-r1:8b | 可指定tag/版本 |
ollama list | 列出本地可用模型 | ollama list | 包含模型名、大小等信息 |
ollama ps | 显示当前正在运行的模型(加载到内存中) | ollama ps | 类似容器工具的进程查看 |
ollama stop | 停止正在运行的模型 | ollama stop llama3:8b | 停止模型会释放内存 |
ollama rm | 删除本地某个模型 | ollama rm llama3:8b | 删除后可释放磁盘空间 |
ollama cp | 复制本地模型到新名称(用于修改或自定义) | ollama cp llama3 my-llama3-copy | 可用于建立自定义版本 |
ollama create | 使用 Modelfile 创建自定义模型 | ollama create mymodel -f ./Modelfile | Modelfile定义模型配置(系统提示、参数) |
ollama show | 显示模型详细信息 | ollama show llama3:8b | 可展示配置、参数信息等 |
ollama serve | 启动Ollama本地服务(无界面) | ollama serve | 常用于API或Web访问场景 |
ollama help | 显示帮助或某命令的用法 | ollama help run | 查看各命令参数说明 |
模型拉取
首先我们查看Ollama支持的模型有那些:
https://ollama.com/search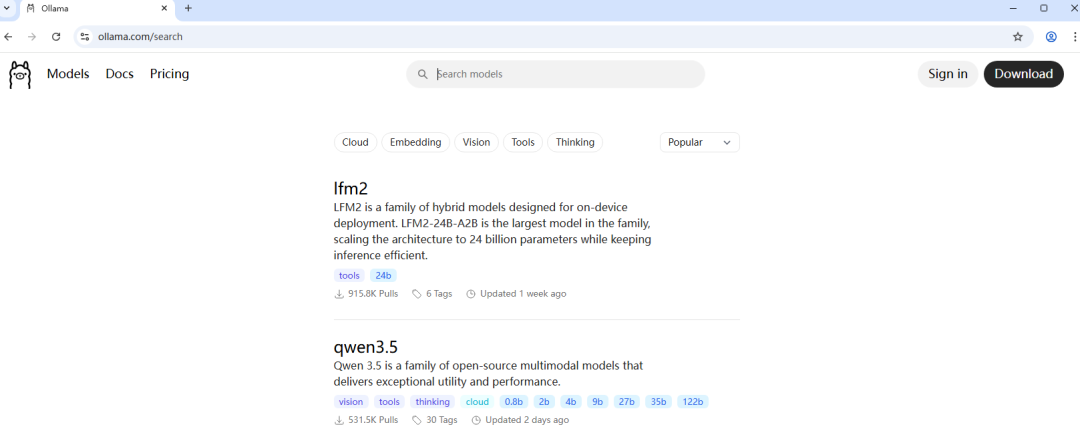
目前Ollama支持的模型主要包括以下几种:
模型名称 | 参数规模(大致) | 功能定位 / 简介 |
|---|---|---|
Llama 3.1 | 8B / 70B / 405B | Meta最新一代通用大语言模型,适合高质量对话、文本生成与推理任务 |
Llama 3.2 | 1B / 3B | Llama 3的轻量级版本,适合资源有限设备的对话与基础生成任务 |
Llama 3.3 | 70 B | Llama 3的更先进版本,增强语言理解与推理能力(需要大内存) |
Llama 3.2‑Vision | 11B / 90B | Llama 3的多模态视觉语言模型,可以处理图像理解与文本生成任务 |
Gemma 2 / Gemma 3 | 2B / 9B / 12B / 27B | Google提供的高性能通用模型,平衡质量与效率,支持语言、推理等任务 |
Mistral / Mistral‑Nemo | 7 B / 12B | 轻量且推理效率高的模型,适合对话、写作与开发辅助,Nemo版本有更长上下文能力 |
DeepSeek‑R1 | 1.5 B–70 B/671B | 基于Llama/Qwen精炼的通用推理模型,在某些任务上与商业级模型接近 |
Phi‑4 / Phi‑4‑mini | 14 B/ ~3.8 B | 微软推出的开放模型,在语言理解和推理方面表现良好 |
Qwen2.5 /QwQ | 0.5B–72 B | 支持多语种、大上下文窗口的模型,可用于通用生成和推理应用 |
CodeLlama | 7 B/13 B/34 B/70 B | 针对代码生成与编程辅助优化的LLM,适合IDE集成或代码任务 |
StarCoder2 | 3B / 7B / 15B | 专注代码生成的开源模型,适合代码补全与解释 |
Falcon2 / Falcon3 | 7B–10B | 用于高效自然语言生成与推理的通用模型 |
各个模型规模对内存需求、硬件配置需求如下:
模型规模 | 典型内存需求(RAM + GPU 显存) | 适合硬件 | 说明 |
|---|---|---|---|
小模型(1B~ 3B) | 8~16 GB RAM 或 4~6 GB GPU | 轻量笔记本/桌面 | 可在CPU上运行,但GPU会快很多,适合快速测试、学习、轻量文本生成 |
中型模型(7B~13B) | 16~32 GB RAM 或 8~12 GB GPU | 中高端笔记本/单GPU桌面 | 可在CPU上运行,但推理速度慢,GPU推荐用于流畅交互 |
大模型(30B~ 70B) | 32~128 GB RAM 或 24 GB 以上 GPU | 高端工作站/专业GPU服务器 | CPU几乎不可用,必须GPU或分布式方案 |
超大模型(100B+) | 128+ GB RAM 或 多GPU | 专业服务器 / 数据中心 | 个人电脑几乎无法直接运行,需要切分模型或使用云GPU |
在这里我们选择拉取DeepSeek-R1的1.5b模型作为演示
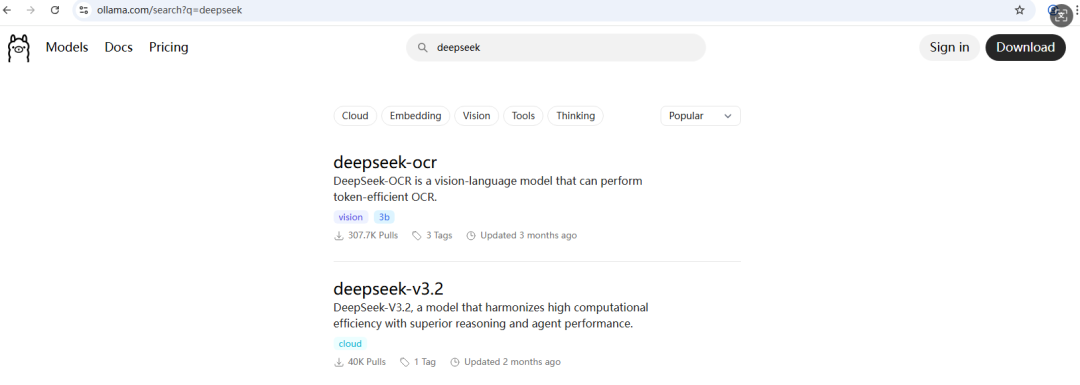
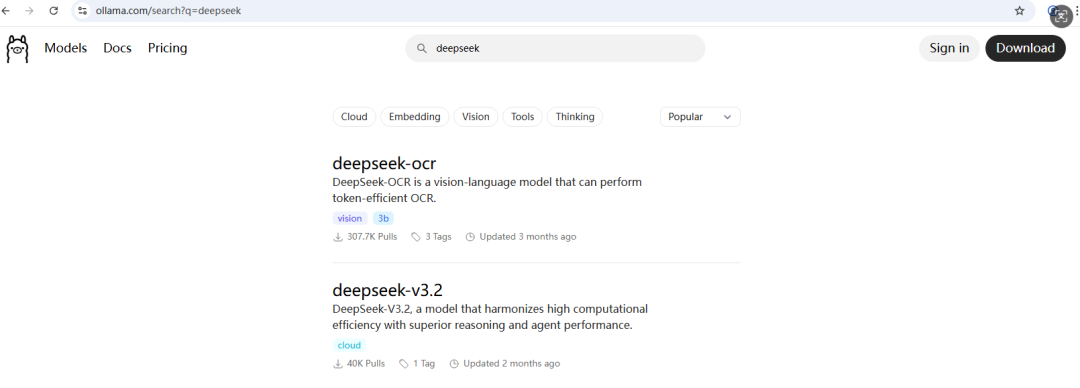
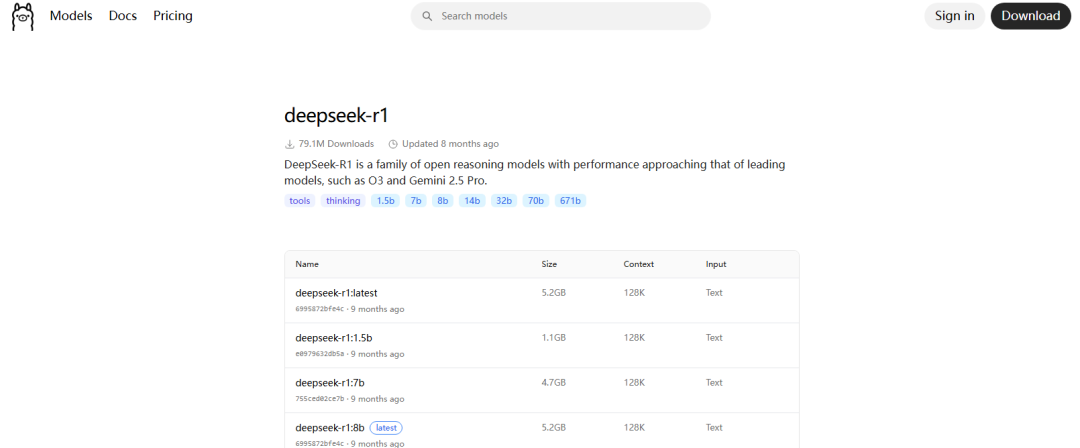
随后拉取模型:
ollama pull deepseek-r1:1.5b

模型运行
我们可以通过以下命令来查看当前本地的模型:
ollama list
随后我们可以通过以下命令来运行执行的模型:
#格式:
ollama run <模型NAME>
#示例
ollama run deepseek-r1:1.5b
随后我们可以通过交互式输入对应的问题来提问:
你是谁?
简单介绍一下什么是SQL注入,如何防御SQL注入问题?
Chatbox
基本介绍
Chatbox AI(通常简称:ChatBox)是一款开源的AI大模型桌面客户端,主要用于在本地或通过API与各种大语言模型进行交互,它的核心作用是为用户提供一个统一、易用的图形界面来使用AI模型,无论模型来自本地部署还是云端服务,ChatBox就像是大模型的"聊天界面工具",类似于浏览器访问AI,但它专门为AI应用设计,支持接入多种模型,例如:
- Claude
- Gemini
- DeepSeek
- OpenAI API
- Ollama(本地模型环境)
项目地址
官网地址:https://chatboxai.app/
Githhub地址:https://github.com/chatboxai/chatbox
部署安装
Step 1::访问官网直接下载对应的系统版本安装包
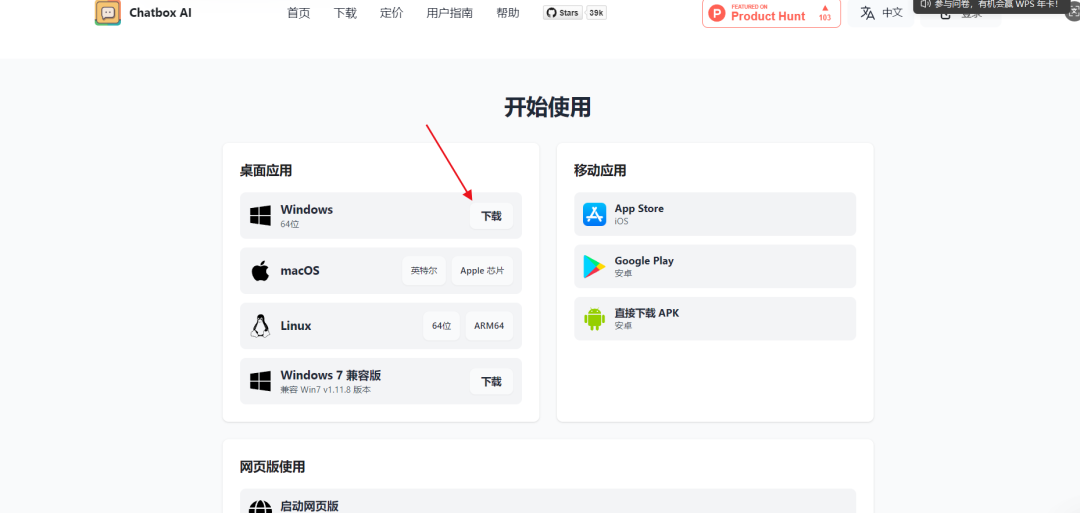
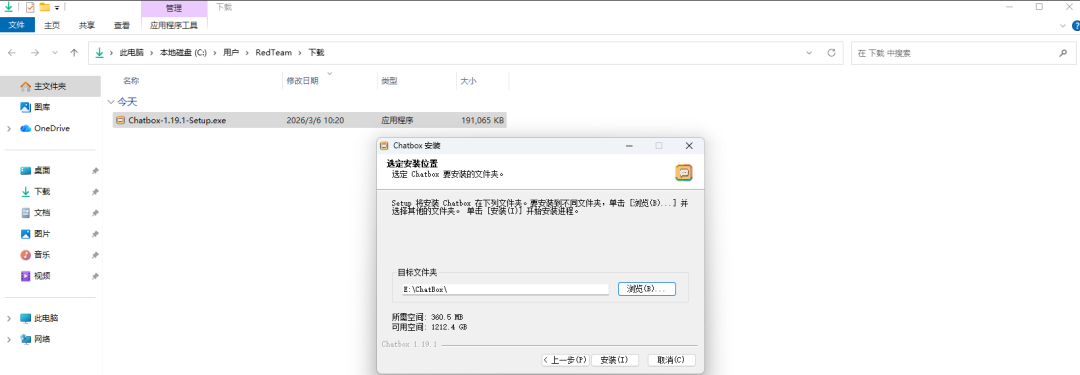
Step 2:双击对应的安装包进行安装部署
运行界面如下所示
Step 3:随后进行本地模型配置
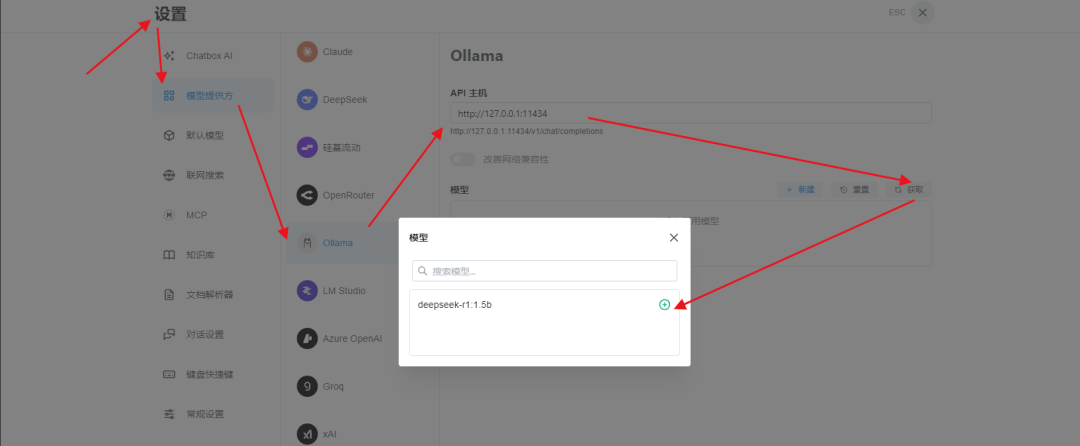
我们也可以在Chatbox中使用外部大模型,使用时只需要填写对应的OPENAPI KEY凭证信息即可
Step 4:模型选择适配
随后我们在本地Chat中选择对应的本地模型即可开始对话沟通
文末小结
本篇文章我们通过借助Ollama在本地完成了DeepSeek大模型的部署,同时通过ChatBox为大模型交互提供了图形化交互界面,通过ChatBox我们可以与大模型进行友好沟通会话~
推 荐 阅 读
图片

图片
图片
图片
图片
横向移动之RDP&Desktop Session Hija
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号