vLLM 硬核四连发!


大家好,我是 Ai 学习的老章
关于 vLLM,我之前写过不少:
- 吃瓜,大模型推理引擎,vLLM和SGLang 杠起来了
- 大模型本地部署,vLLM 睡眠模式来了
- vLLM 最新版来了,Docker Model Runner 集成vLLM
- 全模态大模型部署,vLLM-Omni 来了,100%开源
- vLLM 重磅项目
今天再来聊聊 vLLM 在 2026 年 3 月密集发布的四个重大更新——Semantic Router v0.2 Athena、NVIDIA Nemotron 3 Super 上线、P-EAGLE 并行推测解码、以及Model Runner V2 架构大重构。这一波更新可以说是从底层引擎到上层编排全面开花,让 vLLM 在 2026 年站稳了大模型推理基座的位置。
一、Semantic Router v0.2 Athena:从路由器到系统大脑
第一个登场的是 vLLM Semantic Router v0.2 Athena(雅典娜)。
如果你对 Semantic Router 还不熟悉,简单说就是——它不是一个模型,它是帮你决定"这个请求该交给哪个模型处理"的智能路由层。
从 v0.1 Iris 到 v0.2 Athena,这次升级幅度相当大。
下图是 Athena 的整体架构概览,可以看到从信号提取到决策路由再到模型选择的完整流程:
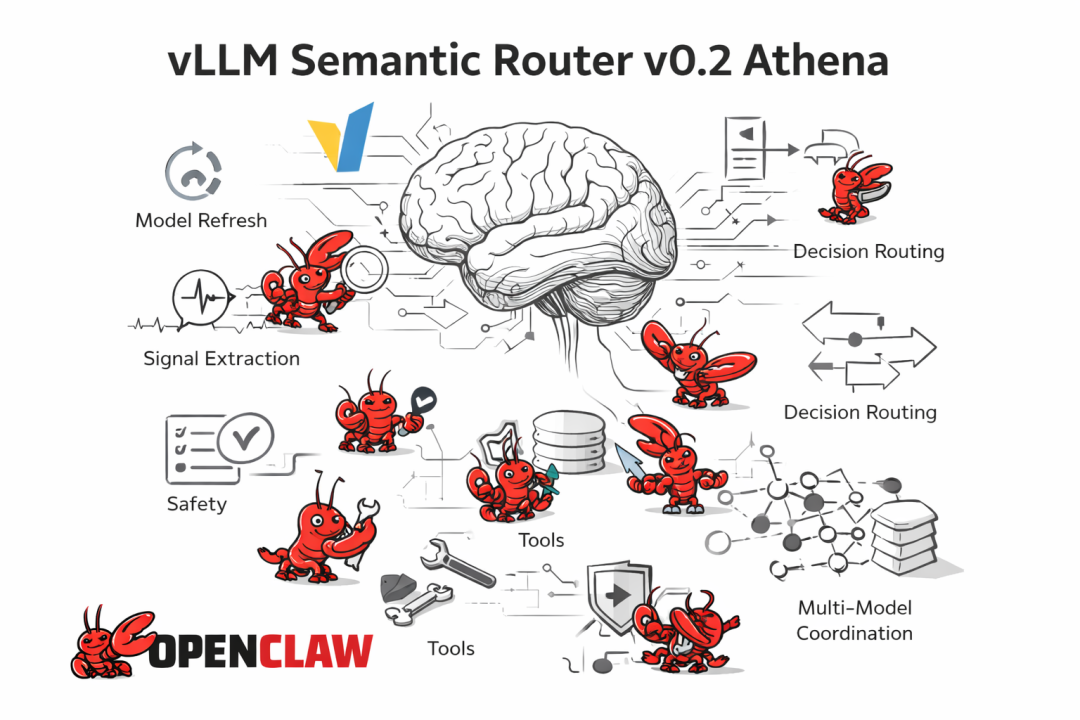
Athena 整体架构
Athena 整体架构
1. 模型栈全面换血
Athena 把底层基座换成了新的多语言长上下文模型 mmbert-embed-32k-2d-matryoshka,支持 1800 多种语言、32K 上下文。在它之上构建了一整套分类器家族 mom-multilingual-class,覆盖意图分类、越狱检测、PII 检测、事实核查和反馈检测。
下图展示了新的跨模态嵌入模型 multi-modal-embed-small,能把文本、图片、音频统一映射到同一个 384 维语义空间:
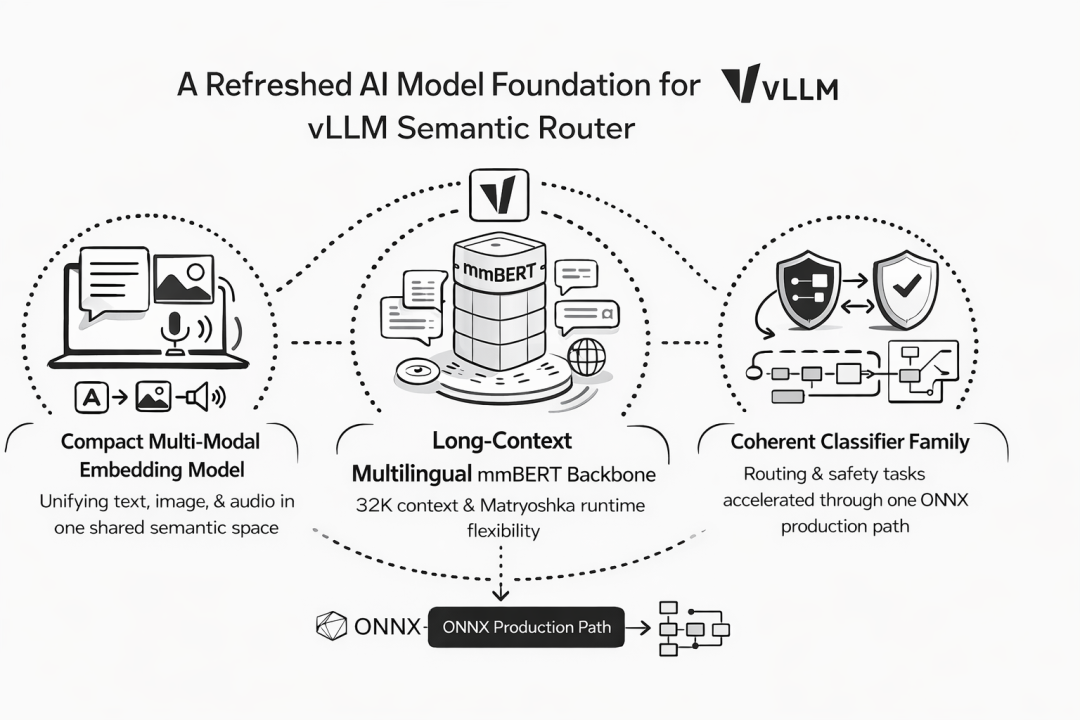
跨模态嵌入模型
跨模态嵌入模型
性能提升立竿见影——在 AMD MI300X 上做了一组端到端测试:
请求大小 | ONNX+GPU 平均延迟 | ONNX+CPU 平均延迟 | Candle+CPU 平均延迟 |
|---|---|---|---|
~500 tokens | 22 ms | 853 ms | 1053 ms |
~2000 tokens | 31 ms | 1814 ms | 1805 ms |
~8000 tokens | 128 ms | 4796 ms | 1830 ms |
ONNX+GPU 比 CPU 方案快了 40 倍,这不是理论测试,是走完 Envoy→ext_proc→SR 的真实路由链路。
下图是 Athena v0.2 的模型栈全景,可以直观看到新旧基座的替换:
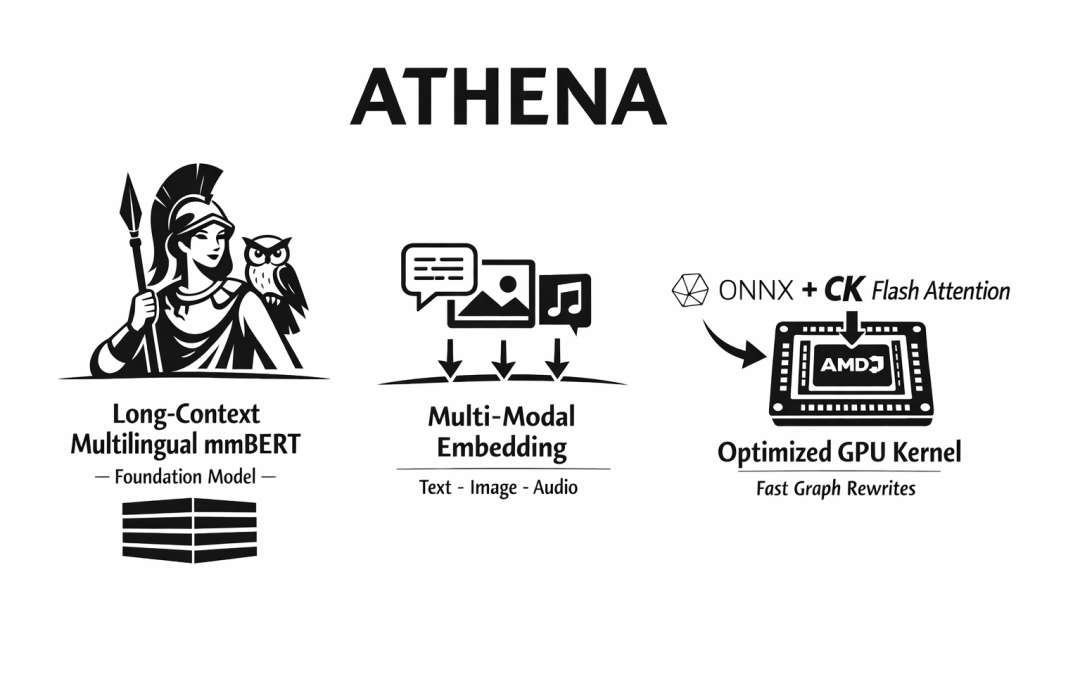
Athena 模型栈全景
Athena 模型栈全景
2. ClawOS:让路由器变成 AI 操作系统
这是 Athena 最大胆的尝试。ClawOS 把 Semantic Router 变成了一个可以编排多个 OpenClaw 智能体团队的操作层。你可以通过自然语言对话来创建团队、分配 Worker、实时协调——有点像给 AI 智能体搞了个"操作系统"。
下图是 ClawOS Dashboard 的多智能体编排界面——可以看到团队管理、Worker 分配和实时聊天协作的完整界面:
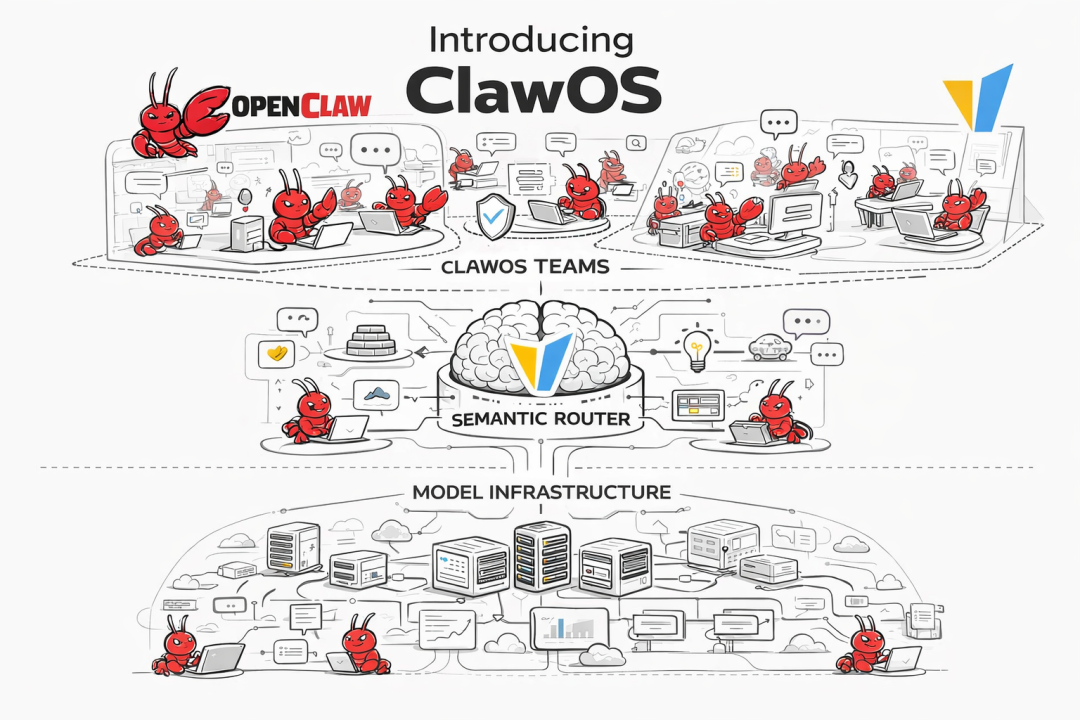
ClawOS 多智能体编排界面
ClawOS 多智能体编排界面
虽然还是实验性质,但方向很清晰:**未来的 AI 推理不只是"选模型",而是"管团队"**。
3. 零配置上手 + Dashboard 驱动
以前搞 Semantic Router 得先写一堆 YAML 配置。现在一行命令搞定:
curl -fsSL https://vllm-semantic-router.com/install.sh | bash
装完自动启动 Dashboard,进去配一下模型就能用。下图是全新的 Dashboard 首次启动引导界面:
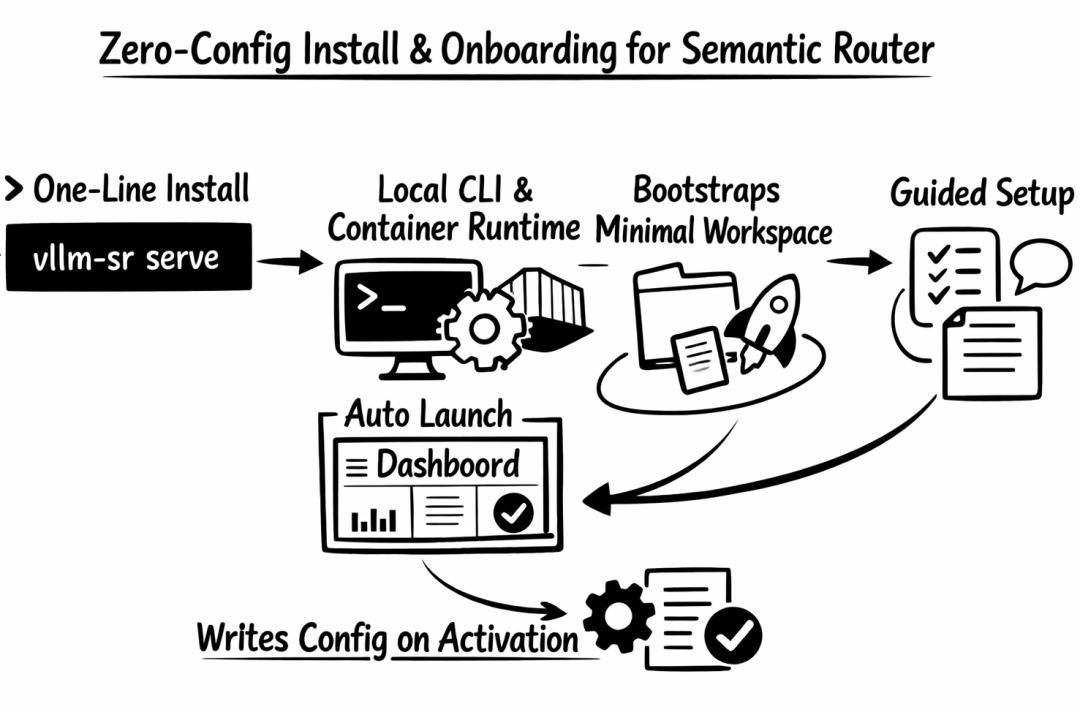
Dashboard 首次启动引导
Dashboard 首次启动引导
Dashboard 现在不光能配置路由,还能可视化拓扑、回放路由决策、做评估测试。真正成了"系统大脑":
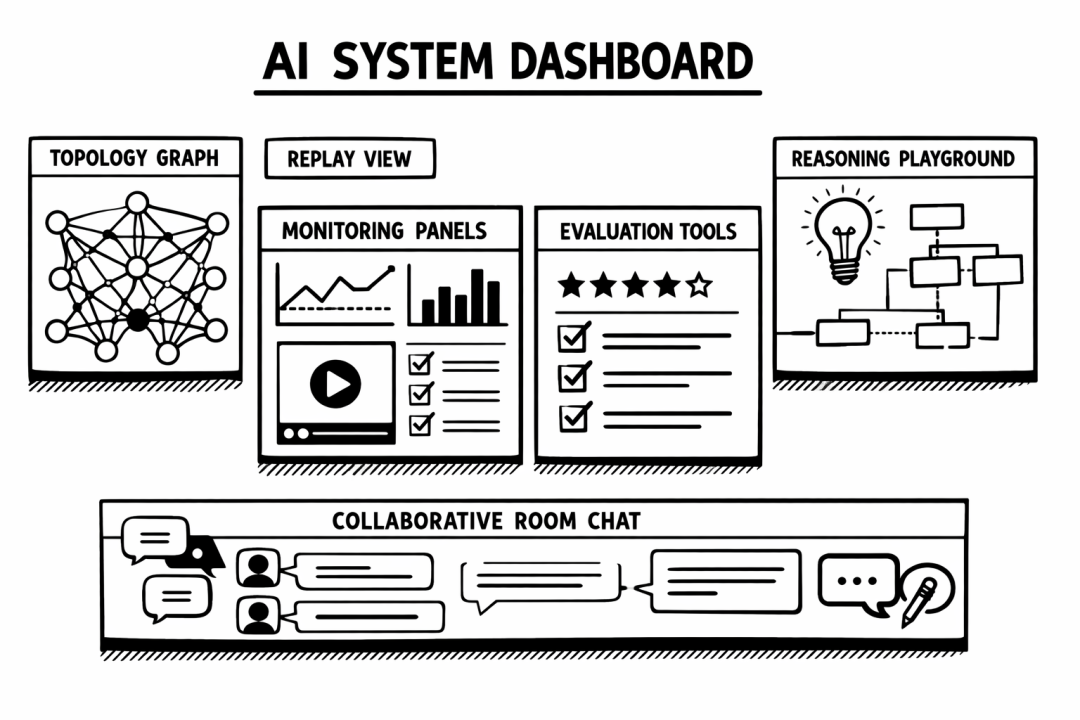
Dashboard 系统大脑
Dashboard 系统大脑
4. AMD ROCm Yes!
AMD 用户终于不是二等角色了
Athena 把 ROCm 做成了正式支持的部署路径:
vllm-sr serve --platform amd
下图展示了 AMD ROCm 端到端部署路径,包括 GPU 直通、ONNX 加速和 CK Flash Attention 支持:
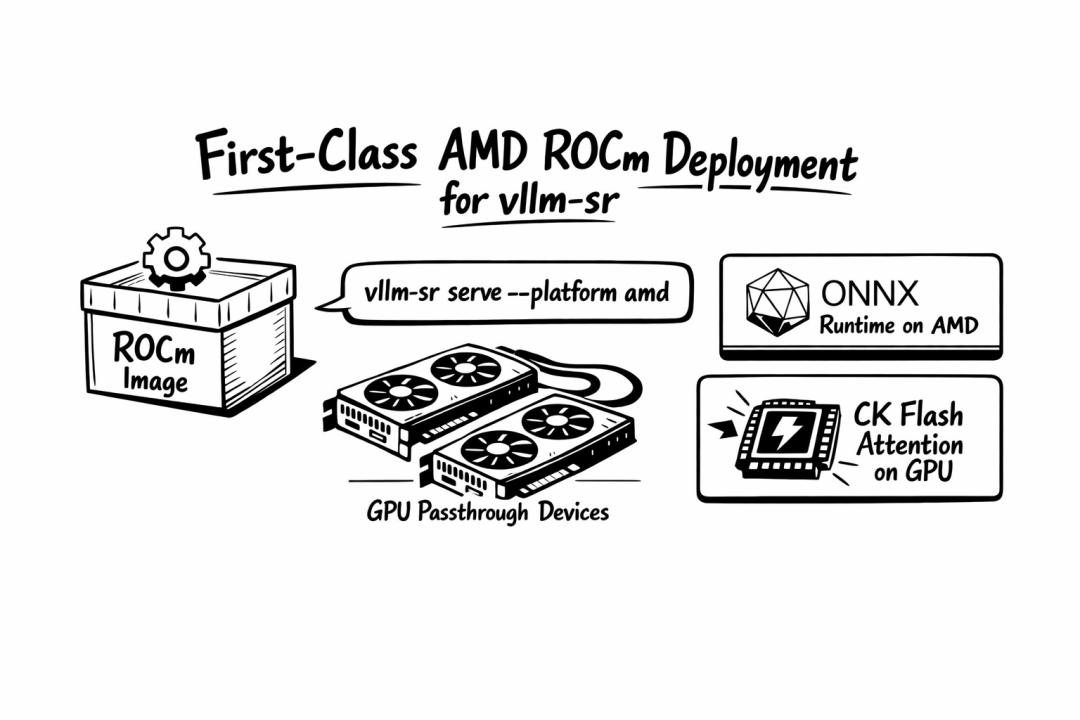
AMD ROCm 部署架构
AMD ROCm 部署架构
老章说:Semantic Router 的野心越来越大了。从 v0.1 的"请求路由"到 v0.2 的"系统大脑",vLLM 开始不只做推理引擎,而是做上层编排。对于需要跑多个模型的生产环境来说,这东西值得关注。
二、NVIDIA Nemotron 3 Super:为多智能体而生的 MoE 模型
英伟达发力了,新模型在 OpenClaw 成功率排行榜杀进前五,目前免费用
NVIDIA 和 vLLM 联手推出了 Nemotron 3 Super 的官方支持。先来看一组惊人的数字:
- 总参数:1200 亿
- 激活参数:仅 120 亿(MoE 架构,Latent MoE 让 4 个专家的推理成本等于 1 个)
- 上下文窗口:100 万 token
- 支持 GPU:B200、H100、DGX Spark、RTX 6000
下图是 Artificial Analysis 的评测对比,Nemotron 3 Super 在同级别开源模型中智能水平和开放度都领先:
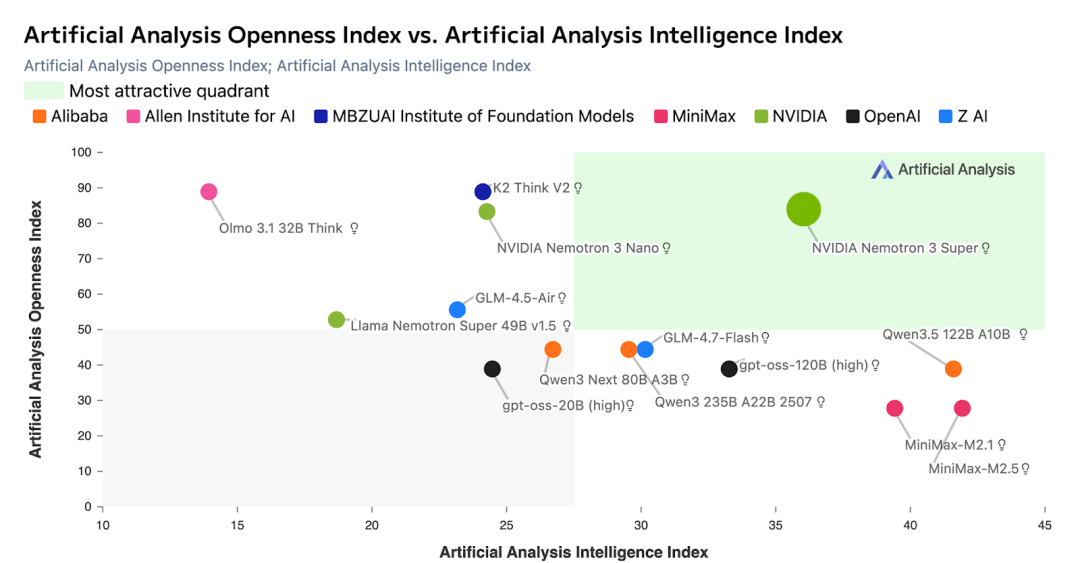
Nemotron 3 Super Artificial Analysis 对比
Nemotron 3 Super Artificial Analysis 对比
为什么说它是"为多智能体而生"?
多智能体系统有两个老大难问题:
- 上下文爆炸:多个智能体之间不停传递历史记录、工具输出和推理步骤,token 越滚越大。Nemotron 3 Super 用 100 万 token 上下文窗口直接暴力解决——历史全装得下,目标漂移大幅减少。
- 推理税:每个子任务都用大模型会又慢又贵。MoE 架构只激活 120 亿参数,吞吐量比前代提升最高 5 倍,NVFP4 精度在 Blackwell 上比 H100 的 FP8 还快 4 倍,且精度几乎无损。
下图展示了 Nemotron 3 Super 在效率和精度两个维度上的领先位置:
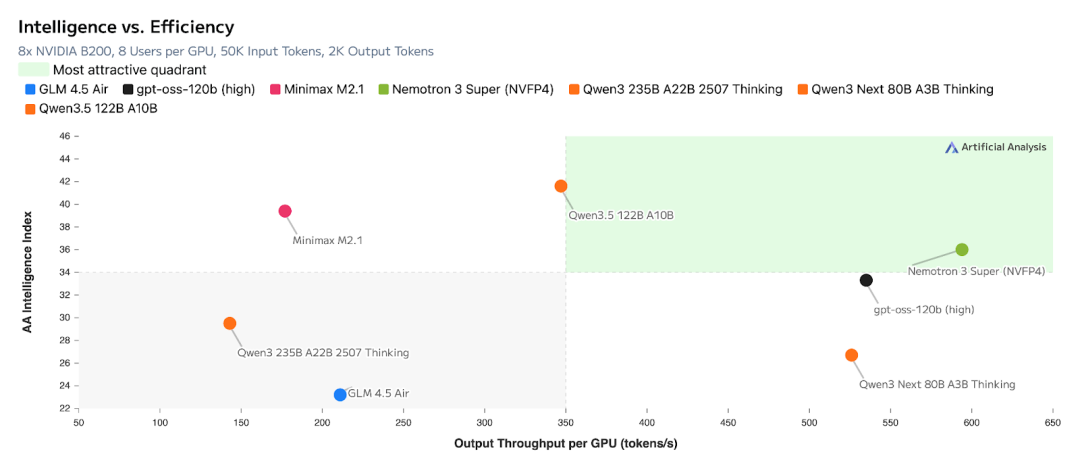
Nemotron 3 Super 效率 vs 精度
Nemotron 3 Super 效率 vs 精度
快速上手
安装 vLLM 后一条命令就能部署:
pip install vllm==0.17.1
# BF16 精度,4 卡 H100 配置
vllm serve nvidia/NVIDIA-Nemotron-3-Super-120B-A12B-BF16 \
--kv-cache-dtype fp8 \
--tensor-parallel-size 4 \
--trust-remote-code \
--served-model-name nemotron \
--enable-auto-tool-choice \
--tool-call-parser qwen3_coder \
--reasoning-parser nemotron_v3
然后用标准 OpenAI SDK 就能调用:
from openai import OpenAI
client = OpenAI(base_url="http://127.0.0.1:5000/v1", api_key="null")
resp = client.chat.completions.create(
model="nemotron",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Give me 3 bullet points about vLLM"}
],
temperature=0.7,
max_tokens=256,
)
print("Reasoning:", resp.choices[0].message.reasoning_content,
"\nContent:", resp.choices[0].message.content)
值得注意的是,Nemotron 3 Super 还支持 Thinking Budget,可以精细控制推理时的 token 开销——不是所有任务都需要深度思考,简单任务省着点用。
老章说:Nemotron 3 Super 的定位很精准——不追求最强单点能力,而是在"效率×精度"的帕累托前沿找到最优解。120B 总参数只激活 12B,配合百万 token 上下文,就是为多智能体工作流量身定制的。如果你在搞 Agent 编排、Tool-Calling Pipeline,这个模型值得认真评估。
三、P-EAGLE:推测解码再提速,一次前向搞定所有草稿 token
推测解码(Speculative Decoding)是目前加速大模型推理最有效的技术方向之一。EAGLE 系列是这个领域的 SOTA 方法,vLLM 也一直在深度集成。但 EAGLE 有一个绕不开的瓶颈——草稿生成是自回归的。你想预测 K 个 token,就得跑 K 次前向传播。当你想预测得更多的时候,草稿模型本身的延迟反而成了新的瓶颈。
先看效果——下图是 P-EAGLE 在 NVIDIA B200 上 SPEED-BENCH 的性能对比,一眼就能看出差距:
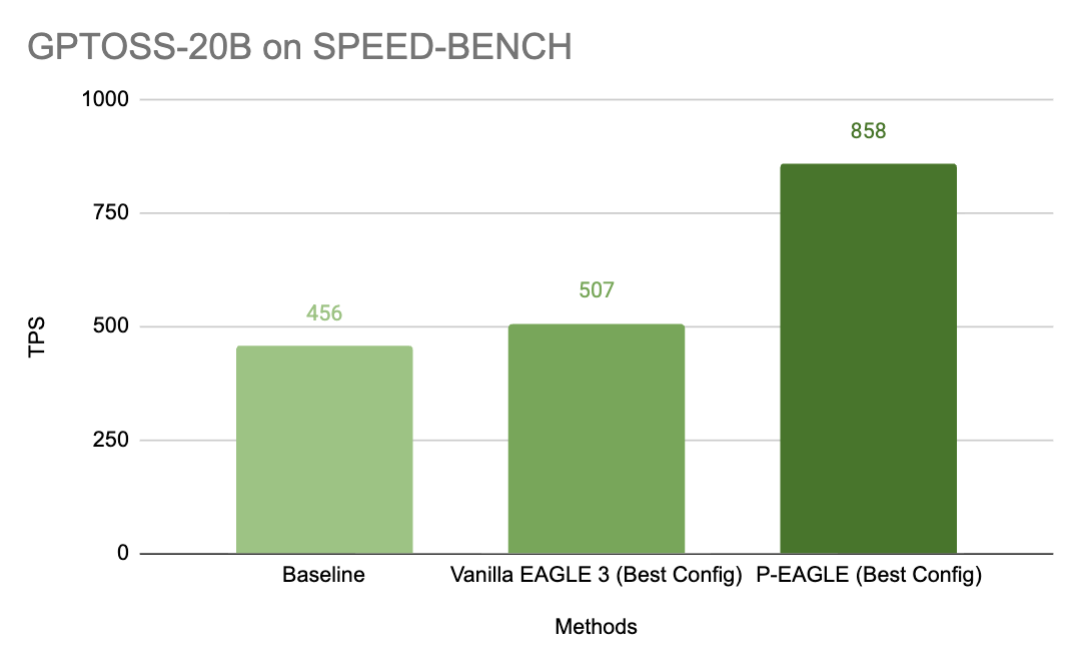
P-EAGLE SPEED-BENCH 性能对比
P-EAGLE SPEED-BENCH 性能对比
P-EAGLE 的解决方案非常直接:把自回归草稿生成改成并行生成——一次前向传播,输出全部 K 个草稿 token。
怎么做到的?
下图是 P-EAGLE 的架构原理图,左侧是传统 EAGLE 的自回归方式,右侧是 P-EAGLE 的并行方式:
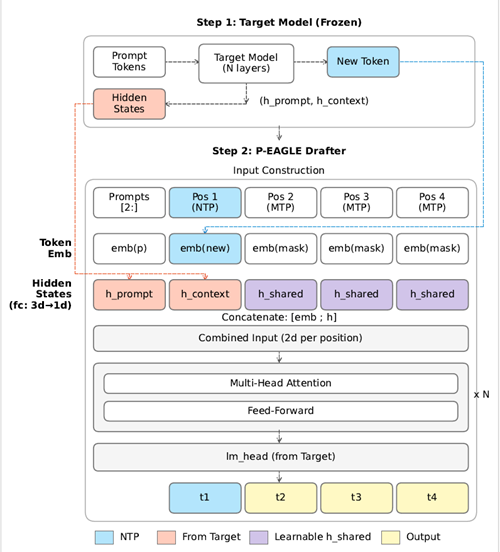
P-EAGLE 架构原理
P-EAGLE 架构原理
P-EAGLE 在预填充阶段和普通 EAGLE 一样,捕获目标模型的隐藏状态。关键在第二步——草稿生成阶段:
- 对于下一个 token(NTP),输入和标准 EAGLE 完全一样
- 对于第 2 到第 K 个位置(MTP),输入的 token embedding 和隐藏状态还不存在,怎么办?P-EAGLE 引入了两个可学习参数:共享的 mask token embedding 和共享的隐藏状态
h_shared,作为占位符
所有位置一起通过 N 层 Transformer,一次性输出所有草稿 token。
长序列训练的挑战
训练 P-EAGLE 面临的最大挑战是内存。下图展示了 GPT-OSS 120B 在 UltraChat 数据集上的序列长度分布——中位数 3891 token,P90 达到 10800 token:
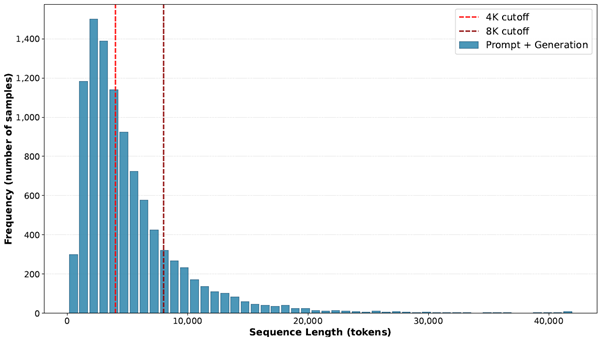
序列长度分布
序列长度分布
训练 K 个并行组在长度为 N 的序列上,会产生 N×K 个位置。N=8192、K=8 时,一个训练样本就有 65536 个位置,注意力矩阵要 8GB。P-EAGLE 通过序列分区算法解决了这个问题。
实测效果
三组基准测试的详细结果如下:
MT-Bench 上不同并发下的吞吐量对比,P-EAGLE 在所有并发度上都领先:
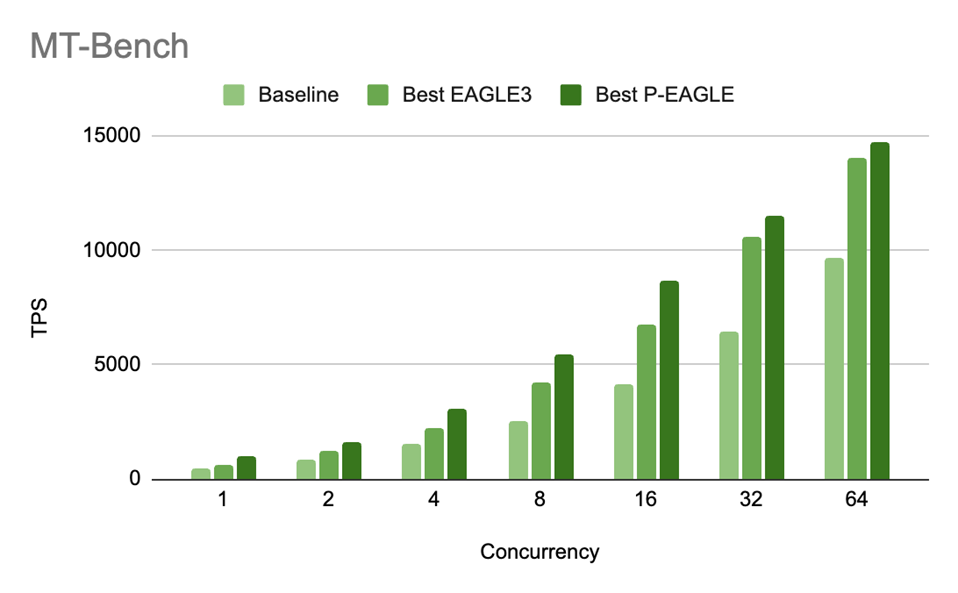
MT-Bench 吞吐量对比
MT-Bench 吞吐量对比
HumanEval 代码合成任务,P-EAGLE 的优势在高并发时依然明显:
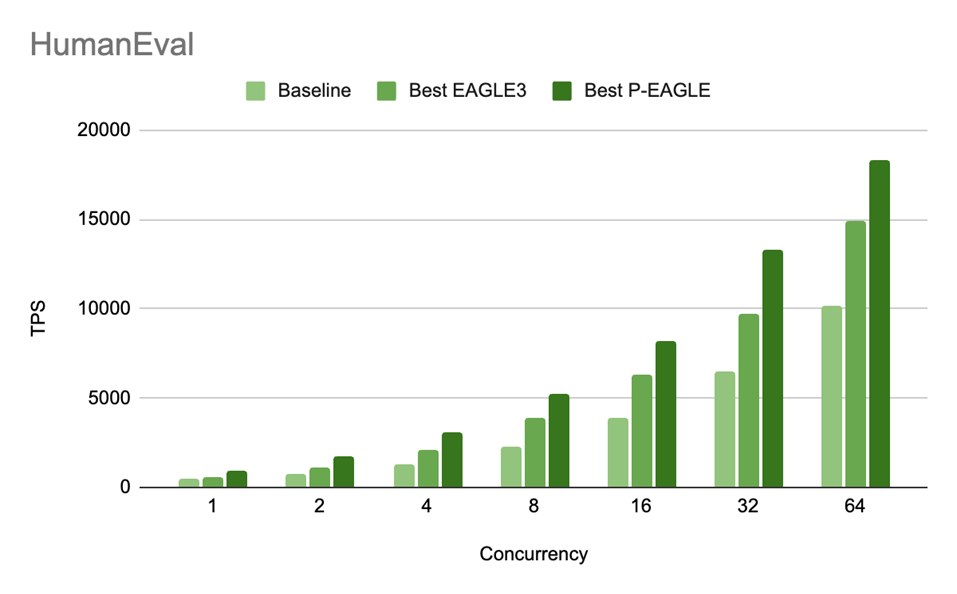
HumanEval 吞吐量对比
HumanEval 吞吐量对比
SPEED-Bench 长文本代码生成任务,P-EAGLE 在 c=1 时加速比高达 1.69x:
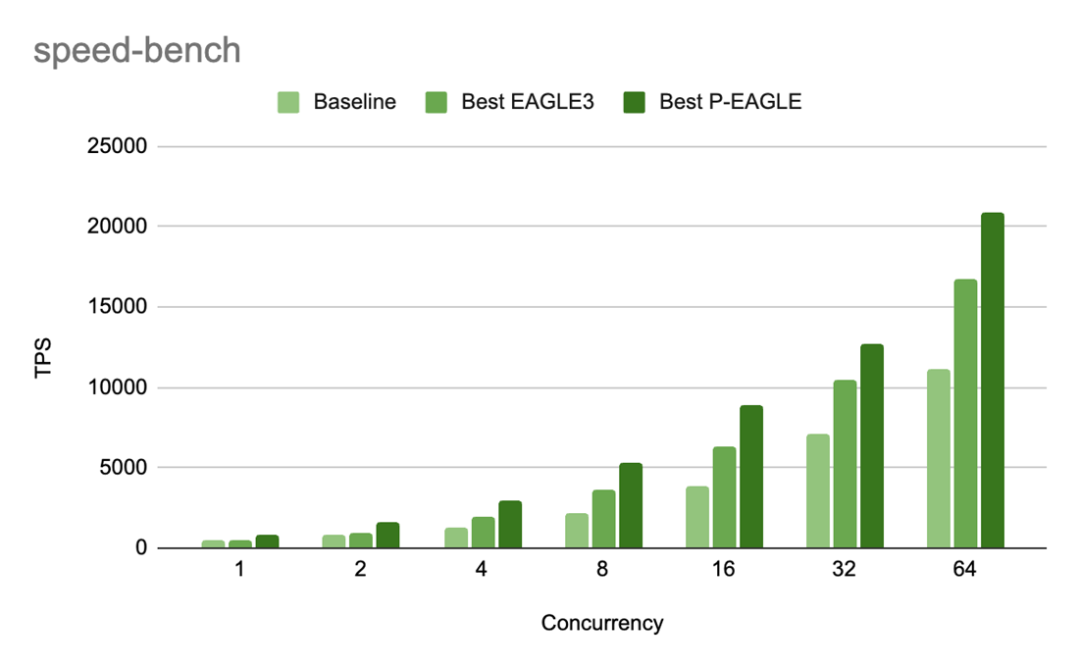
Speed-Bench 吞吐量对比
Speed-Bench 吞吐量对比
一个很有意思的发现:P-EAGLE 在 K=7 时达到峰值性能,而 EAGLE-3 在 K=3 时就封顶了。因为并行生成不管 K 多大,前向传播次数都是 1 次——越深的推测,P-EAGLE 的优势越大。
接受长度(AL)的对比更能说明问题。在 K=7 时:
- HumanEval:P-EAGLE 3.94 vs EAGLE-3 3.03(高 30%)
- SPEED-Bench:3.38 vs 2.59(高 31%)
- MT-Bench:3.70 vs 3.27(高 13%)
使用方法
只需要两步:
- 下载(或训练)并行版草稿头,HuggingFace 上已有 GPT-OSS 120B、GPT-OSS 20B、Qwen3-Coder 30B 的预训练版本
- 加一个配置参数:
vllm serve openai/gpt-oss-20b \
--speculative-config '{"method": "eagle3", "model": "amazon/gpt-oss-20b-p-eagle", "num_speculative_tokens": 5, "parallel_drafting": true}'
就这么简单,"parallel_drafting": true 一行搞定。
老章说:P-EAGLE 的思路很优雅——既然草稿模型的序列生成是瓶颈,那就不序列生成了。用可学习占位符+并行 Transformer 一次搞定。代价是需要重新训练草稿头,但 Amazon 已经放出了多个预训练版本。对于生产环境中追求极致延迟的场景,这个升级非常值得尝试。
四、Model Runner V2:vLLM 核心引擎的彻底重构
如果前面三个更新是"在 vLLM 之上做加法",那 Model Runner V2(MRV2)就是对 vLLM 核心引擎的彻底重写。
这是自去年 vLLM V1 发布以来最大的架构升级。官方毫不客气地说:V1 的 model runner 积累了大量技术债,持久化状态和模型输入耦合、异步调度是后来打的补丁、CPU 端做了太多本该 GPU 干的活、代码变得越来越难维护。
MRV2 围绕三个核心原则重建:模块化、GPU 原生、异步优先。
1. 更好的持久化批处理 + GPU 原生输入准备
V1 直接把持久化状态当作模型输入,导致布局约束和复杂的状态管理。下图展示了 V1 中请求顺序与 Block Table 布局紧耦合的问题:
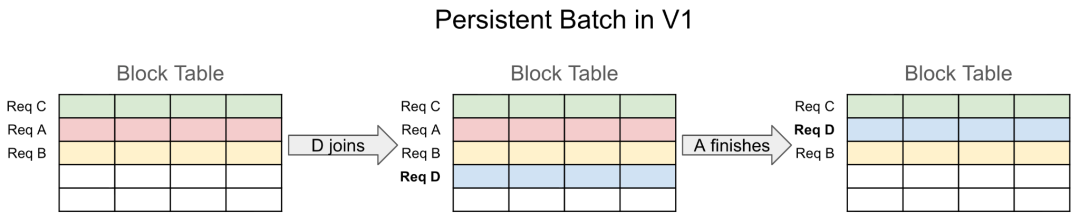
V1 持久化批处理设计
V1 持久化批处理设计
MRV2 解耦了持久化请求状态和每步输入张量——每个活跃请求在固定大小的状态表中有稳定的行,每步按当前顺序从中提取输入。下图可以清晰看到新设计如何通过 gather 操作生成正确排序的输入:
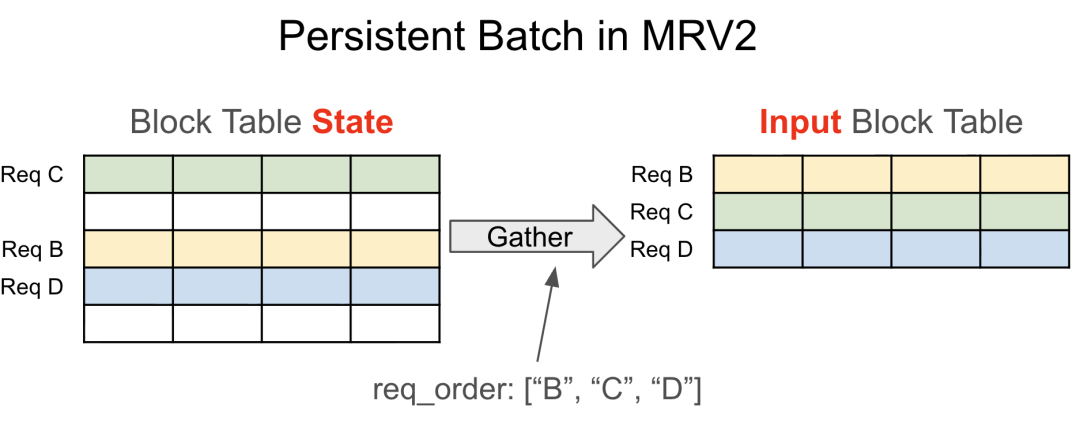
MRV2 持久化批处理设计
MRV2 持久化批处理设计
更关键的是,输入准备移到了 GPU 上,用 Triton Kernel 完成。input_ids、positions、query_start_loc、seq_lens 这些张量现在直接在 GPU 上构建,不再走 CPU。
2. 异步优先设计
V1 的异步调度是"后来加上去的",MRV2 把它作为核心设计约束——目标是 CPU 和 GPU 之间零同步。
下图是标准的异步调度时序,CPU 在 step N+1 做准备的同时 GPU 执行 step N:
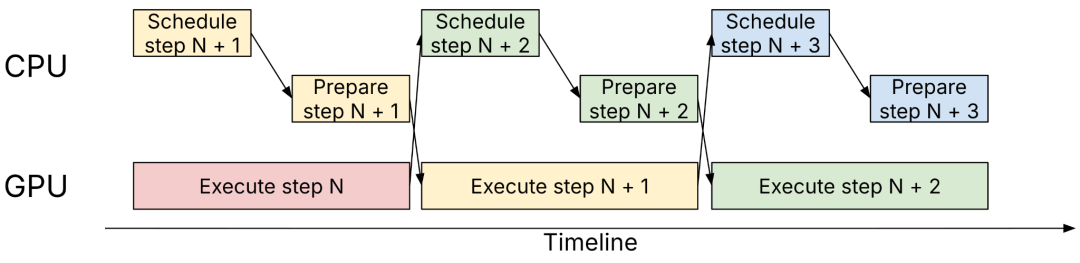
异步调度时序
异步调度时序
最直接的好处:异步调度和推测解码终于可以干净地共存了。下图展示了 MRV2 如何通过 GPU 端输入准备直接消费拒绝采样结果,消除所有同步点:
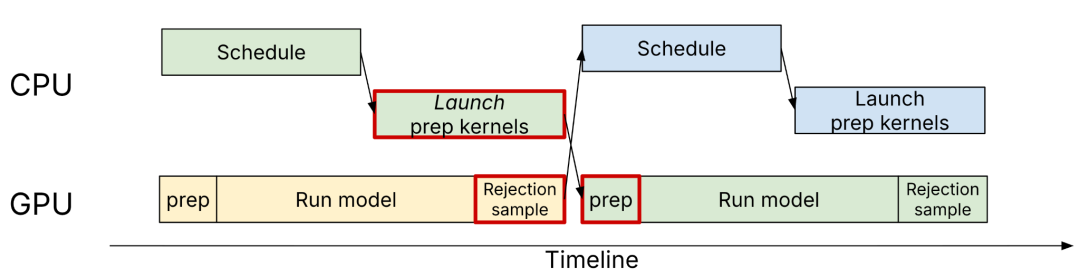
MRV2 推测解码异步优化
MRV2 推测解码异步优化
3. Triton 原生采样器
MRV2 重写了采样逻辑:
- Gumbel-Max 采样核,避免显式 softmax 计算
- 更高效的 top-k logprobs,先找 top-k logits 再算 logprobs
- 更节省内存的 prompt logprobs,支持单个 prompt 内的分块处理
- 更好的推测解码兼容性
4. 更强的模块化
V1 的 gpu_model_runner.py 已经膨胀到 6700 行。MRV2 引入了 ModelState 抽象接口:
class ModelState(ABC):
def add_request(self, ...):
def remove_request(self, ...):
def get_mm_embeddings(self, ...):
def prepare_inputs(self, ...):
def prepare_attn(self, ...):
def prepare_dummy_inputs(self, ...):
...
把模型特定逻辑(多模态嵌入、额外输入、注意力元数据)和通用执行路径分离。最大的文件现在控制在 1300 行以内。
这对 DeepSeek、Qwen、Kimi 等不同模型系列的开发者来说太重要了——你只需要关心自己模型的 ModelState,不用读几千行无关代码。
性能实测
用小模型 Qwen3-0.6B 在 GB200 上跑(故意用小模型放大 CPU 开销的影响),吞吐量直接从 16K 飙到 25K:
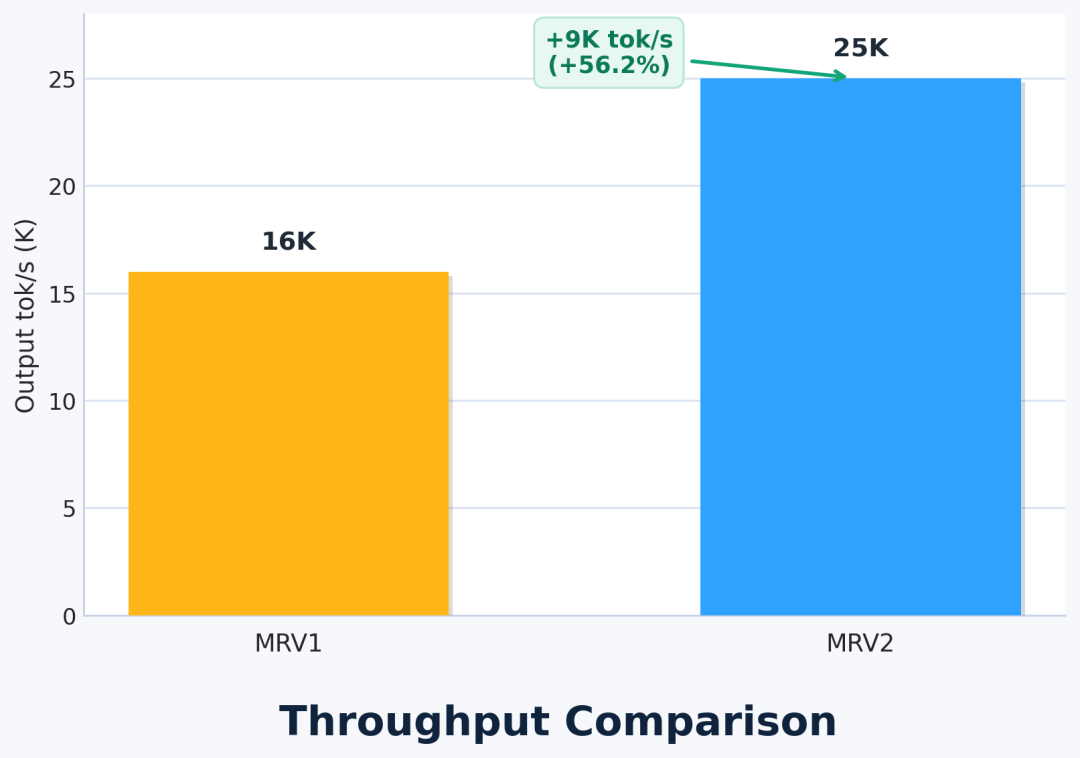
MRV2 吞吐量提升 56.2%
MRV2 吞吐量提升 56.2%
推测解码场景:4 卡 GB200 + GLM-4.7-FP8 + MTP=1,TPOT 降低 6.3%:
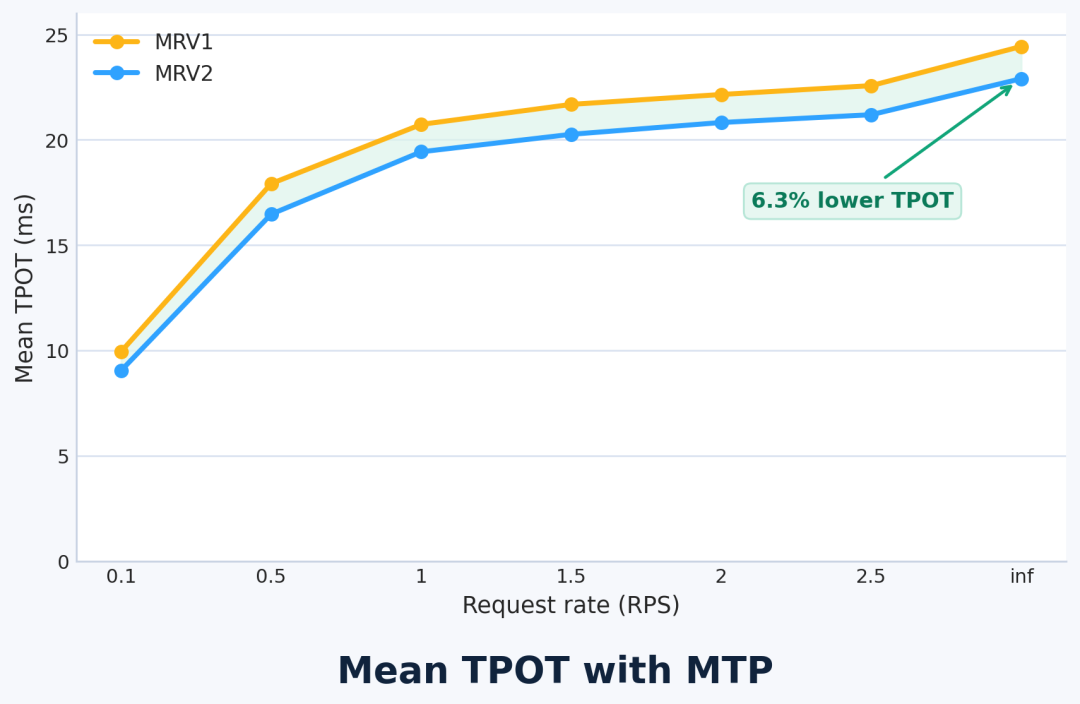
MRV2 TPOT 对比
MRV2 TPOT 对比
提升来自零同步设计——推测解码启用后 CPU-GPU 同步点完全消除。
现在就能试
export VLLM_USE_V2_MODEL_RUNNER=1
# 然后正常使用 vLLM,无需改任何代码
不过需要注意,MRV2 目前还是实验性质,v0.18.0 中有几项功能暂不支持:线性注意力模型(Qwen3.5、Nemotron 3 Super)、Eagle/Eagle3/MTP 之外的推测解码方法、LoRA 等。
老章说:MRV2 是一次"伤筋动骨"的重构,但方向完全正确。把输入准备搬到 GPU、实现零同步异步调度、引入 ModelState 解耦——这些改进不是"锦上添花",而是为未来异构模型+推测解码+多模态并存的复杂场景打地基。56% 的吞吐提升只是开始,随着更多特性迁移到 MRV2,收益还会继续释放。
总结:vLLM 2026 年 3 月全景
更新 | 发布日期 | 一句话概括 |
|---|---|---|
Semantic Router v0.2 Athena | 3月10日 | 从路由器进化成多模型编排的系统大脑 |
Nemotron 3 Super | 3月11日 | 120B 总参/12B 激活,为多智能体量身打造的 MoE 模型 |
P-EAGLE | 3月13日 | 一次前向搞定所有草稿 token,推测解码不再有序列瓶颈 |
Model Runner V2 | 3月24日 | vLLM 核心引擎彻底重构,GPU 原生+零同步+强模块化 |
这四连发放在一起看,vLLM 的战略意图非常清晰:
- 底层——MRV2 重建引擎地基,为更复杂的推理需求做准备
- 加速——P-EAGLE 在推测解码这个关键优化方向上再突破天花板
- 模型——Nemotron 3 Super 补全高效 MoE 模型的生态位
- 上层——Semantic Router Athena 开始做多模型编排和智能体调度
从"推理引擎"到"推理平台",vLLM 正在完成一次从工具到生态的跃迁。
相关链接:
- Semantic Router v0.2 Athena:https://vllm.ai/blog/v0.2-vllm-sr-athena-release
- Nemotron 3 Super:https://vllm.ai/blog/nemotron-3-super
- P-EAGLE:https://vllm.ai/blog/p-eagle
- Model Runner V2:https://vllm.ai/blog/mrv2
- vLLM 官网:https://vllm.ai
- Semantic Router GitHub:https://github.com/vllm-project/semantic-router
#vLLM #大模型推理 #推测解码 #Nemotron #SemanticRouter
制作不易,如果这篇文章觉得对你有用,可否点个关注。给我个三连击:点赞、转发和在看。若可以再给我加个🌟,谢谢你看我的文章,我们下篇再见!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号