AI时代高质量数据集的四个关键本质

AI时代高质量数据集的四个关键本质

人月聊IT
发布于 2026-04-13 12:45:29
发布于 2026-04-13 12:45:29
大家好,我是人月聊IT。今天准备和大家聊一个最近频繁出现在我视野里的概念——高质量数据集。
上个月,我去参加中国电子线下的一场技术沙龙,本来主题是聊本体论的,结果大家聊着聊着,话题就转到了高质量数据集上。无独有偶,上周我和一位做数据治理的朋友聊天,他也提到,最近在给甲方做数据架构规划的时候,客户同样在反复强调“高质量数据集”的重要性。
这个词,一下子就成了大家关注的焦点。但问题也来了:高质量数据集,难道不就是传统数据治理里一直在做的数据质量管理吗?
如果只是解决数据的准确性、一致性,消除重复和冗余,再制定一套标准规范,那为什么还要单独发明一个新概念?这听起来不就是在“新瓶装旧酒”吗?
说实话,高质量数据集在业界确实还没有一个统一的、标准的定义。但一个新概念的兴起,背后一定是因为出现了新的需求和场景。因此今天就详细展开来聊下高质量数据集的核心本质究竟在哪里?
01 为什么突然需要“高质量数据集”?
这个背景其实很简单,也很直接——因为AI大模型来了。
为了让大模型真正为组织、为企业所用,我们需要给它喂“数据语料”。但传统企业里沉淀下来的数据集,往往并不能直接满足大模型的需求。这就好比你要教一个聪明的学生学会一门专业技能,光给他一堆零散的、没有标注的课本是远远不够的,你需要一套结构清晰、逻辑严谨、带有注解的教材。
于是,“高质量数据集”这个概念应运而生。
不过,很多人对这个概念的理解还是过于简单化了。他们认为,所谓高质量数据集,就是在传统数据的基础上,再增加一些人工清洗和标注的工作。这听起来像是一个“加量版”的数据治理。
但这个理解,依然是片面的。
在我看来,高质量数据集的核心,不在于“量”的堆积,而在于“质”的飞跃。它有三个本质上的定义,我想重点展开讲一讲。
02 高质量数据集的三个本质特征
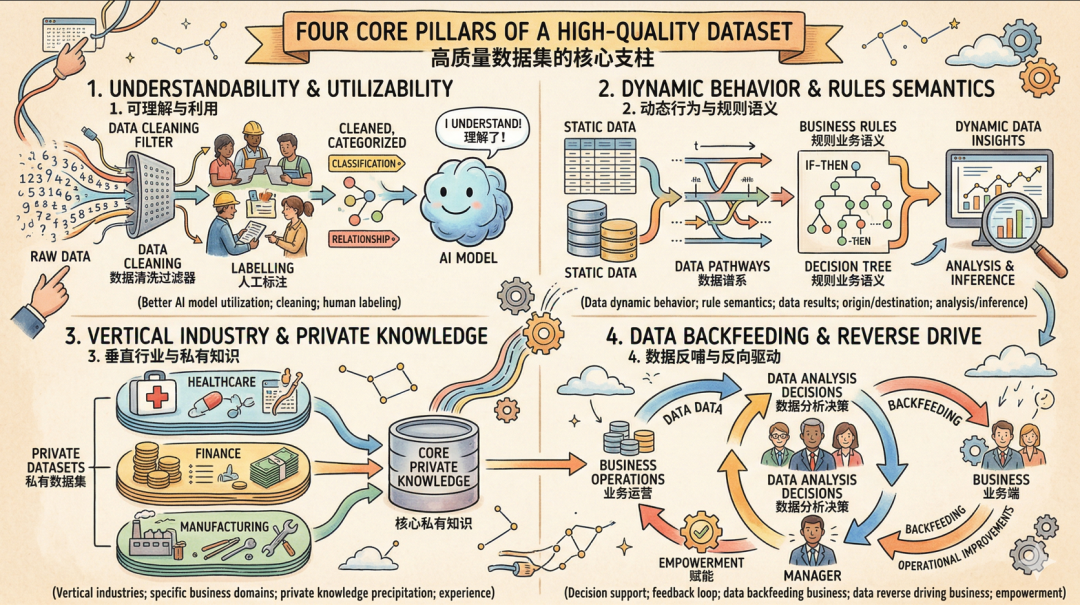
第一,它一定是补充了业务语义的数据集
传统的数据集,更像是静态的数据模型和关系表。它记录了“是什么”,比如“商品A的单价是100元”,但它不记录“为什么”和“怎么样”。
而高质量数据集,必须在这个基础上,补充大量的业务语义。
这是什么意思?我举个例子你就明白了。
假设你经营一家连锁超市,传统数据集会告诉你“某款薯片在过去一周卖了500包”,这是一个事实。但高质量数据集会进一步告诉你:
- 数据来龙去脉:这500包销量,有多少来自线上APP,多少来自线下门店?是哪个区域的门店卖得最好?
- 数据的行为规则:这款薯片的销量是不是随着周末或节假日而波动?它和哪款饮料经常被一起购买?
- 相关的业务语义:这款薯片属于“休闲零食”品类,主要面向年轻消费群体,近期还参与了“满99减20”的促销活动。
只有当数据集包含了这些“来龙去脉”、“行为规则”和“业务语义”后,它就不再是冰冷的数字,而是一个有血有肉、能被理解和推理的知识体系。这就是高质量数据集的第一个关键特征。
第二,它一定是面向特定领域、沉淀了私有经验的数据集
很多人一提到数据,就希望数据越多越好、越全越好。但在AI时代,“泛”不如“专”。
高质量数据集,一定不是包罗万象的通用数据,而是面向企业某一个特定业务领域,或者某一个特定行业,深度融入了行业属性、领域属性以及企业自身私有知识和经验的数据集。
比如,一家银行想要训练一个智能风控模型。如果它用的只是一些通用的、公开的金融数据,那么模型学到的只是“银行是怎么做风控的”这个通用知识。
但如果它使用的是高质量数据集,里面应该包含该银行独有的客户特征、特有的审批规则、历史积累的违约案例和风控策略,甚至包括一线信贷员的实操经验和判断逻辑。
这样的数据集,才是别人拿不走、学不来的核心竞争力。它让AI模型真正具备了企业“私有化”的智慧,而不是一个到处都能下载的通用模型。
第三,它一定是能够反哺业务、驱动推理的数据集
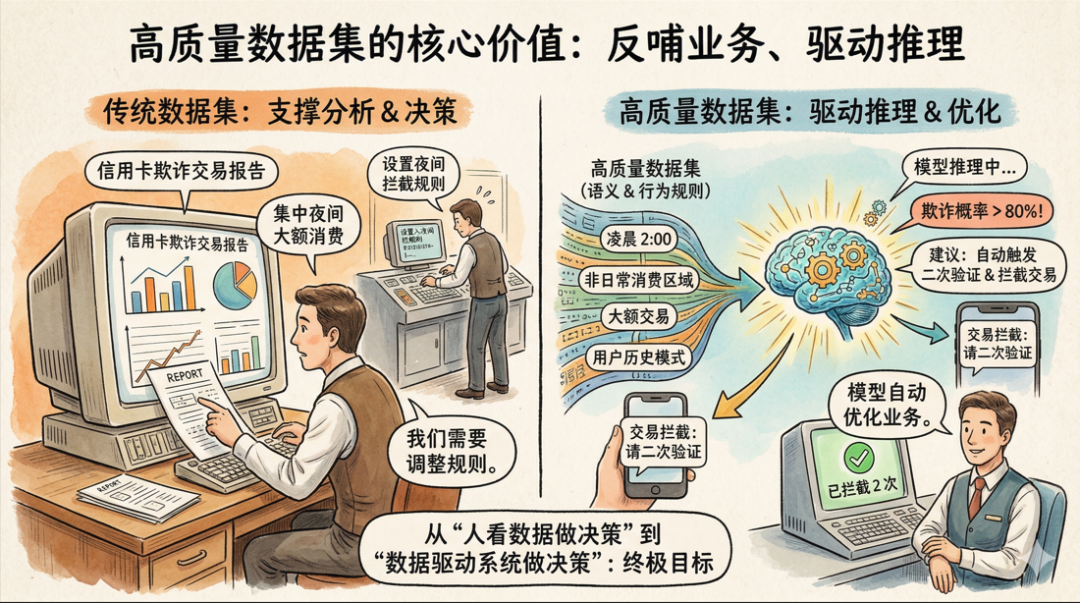
传统数据集的主要价值,是支撑数据分析和决策。我们通过报表、大屏看数据,然后由人来做出判断。
但高质量数据集的价值,远不止于此。它应该是数据能够反哺业务、反向驱动业务的。也就是说,数据不仅仅是给人看的,更是给机器用的,机器可以利用这些数据进行进一步的分析和推理,从而主动地去优化业务。
我们再用一个场景来说明。
还是上面那个银行的例子。一个传统数据集可能会告诉你:“过去一个月,信用卡欺诈交易主要集中在夜间大额消费上。”然后,银行工作人员根据这个结论,去调整风控规则。
而一个高质量数据集,因为它包含了更丰富的业务语义和行为规则,AI模型可以直接利用它进行推理。模型可能会主动发现:“凌晨两点,在非日常消费区域进行的大额交易,结合用户历史行为模式,欺诈概率超过80%。建议自动触发二次验证,并拦截交易。”
这就是“数据驱动业务”的升级版——从“人看数据做决策”到“数据驱动系统做决策”。这才是高质量数据集真正要实现的终极目标。
当然,这三个核心特征,最终都指向一个目的:经过整理的数据集,能够被AI大模型充分使用和利用。
如果数据集不能被大模型理解和调用,那它再“高”,也是束之高阁。
03 如何构建高质量数据集?
好了,既然高质量数据集这么重要,那我们应该怎么去构建它呢?
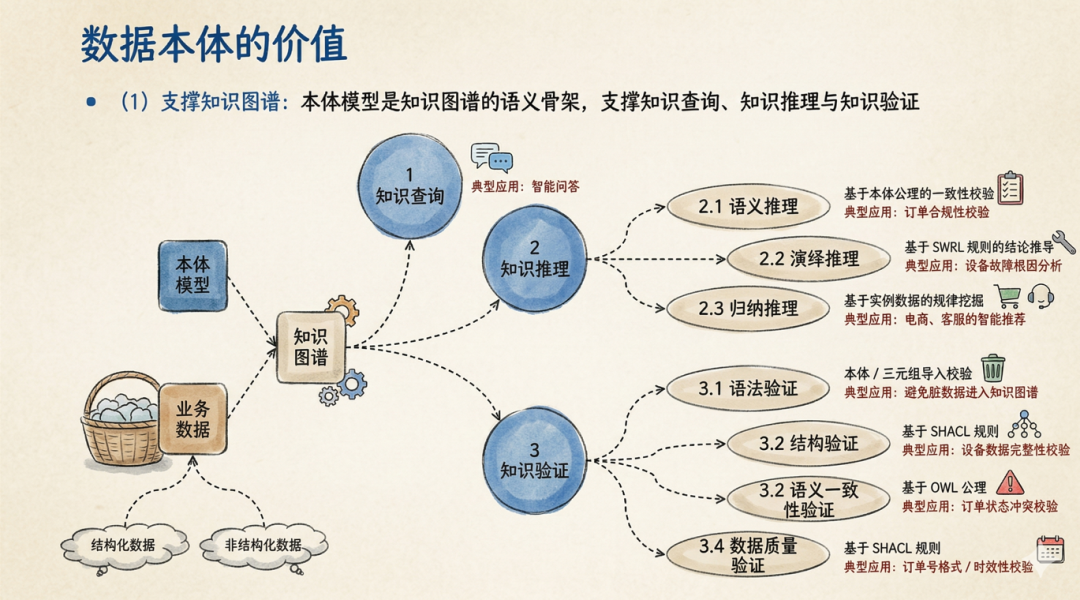
我前面提到过,有人可能会想到用知识图谱。但光有知识图谱就够了吗?也不完全是。
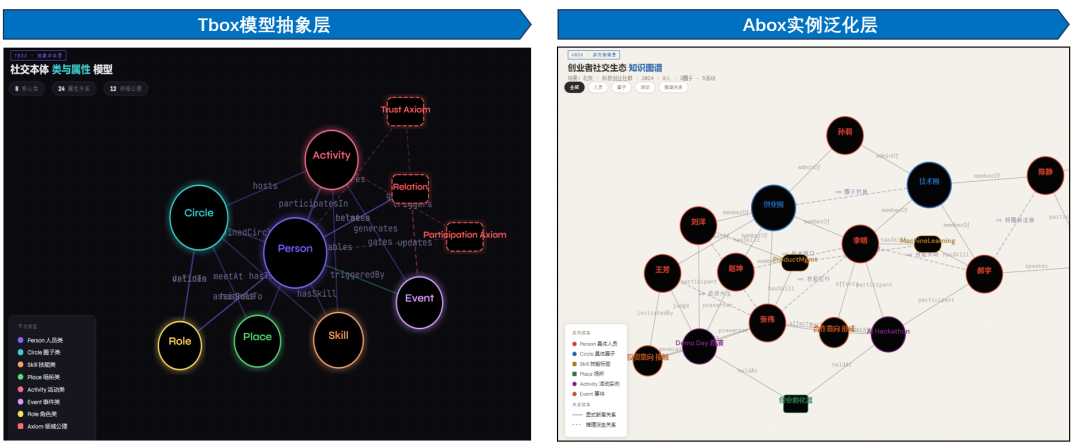
这里就不得不提到一个概念——本体模型。我在之前的文章里多次聊过本体模型和知识图谱的区别。简单来说,本体模型相当于强化了知识图谱里的“Schema”(模式)这一层。
打个比方,知识图谱就像一张已经画好的地图,上面标注了各种地点和路线。而本体模型,则相当于这张地图的“制图标准”——它定义了什么是“城市”、什么是“道路”、什么是“河流”,它们之间是什么关系。先有模型的抽象,然后才有数据的泛化实例。
所以,当我们去构建高质量数据集时,一定要明确这个逻辑:首先,我们要抽象出一个核心的、类似本体的数据模型(或者叫对象模型),把业务领域的核心概念、关系和规则定义清楚。然后,再去考虑如何往这个模型里填充具体的内容。
只有实现这种“模型层+数据层”的两层结构,数据集才能真正称得上“高质量”。这样的数据集,才能更好地服务于后面的数据分析、决策,以及支撑业务行为和业务活动的分析与推理。
04 什么样的数据格式最适合AI大模型
接下来,我们再聊一个更落地的问题:高质量数据集,应该长什么样?
也就是说,什么样的数据格式,才是真正容易被AI大模型理解和学习的?
如果你给AI大模型还是一堆Word文档、PDF文件,那对不起,你建的只是一个“智能知识库”,还经常会出现“幻觉”,答非所问。
AI大模型真正需要的,是更清晰、更结构化的定义。
比如,Markdown格式,它用简洁的语法定义了标题、列表、引用、代码块,层次分明,AI很容易解析。再比如,YAML文件,它是一种以数据为中心的语言,用来定义配置、模型结构非常清晰,AI能够精准地理解其中的字段和关系。
这种带有清晰模型定义和语义定义的数据集,才是AI大模型最“爱吃”的“营养餐”。
当然,除了用Markdown和YAML文件来定义,我们还可以引入图数据库。通过图数据库来存储本体模型或知识图谱中的对象和对象之间的关系,可以充分发挥图数据库强大的分析和推理能力。
数据在清洗和处理完后,底层的存储方式也很关键。一个好的图数据库,能让数据集更好地与AI大模型结合,进行深度的分析和推理。
05 回归本质:模型是工具,经验才是核心
说到这里,你可能会觉得,高质量数据集离不开本体模型,离不开知识图谱,离不开图数据库,听起来有点技术门槛。
但我想说的是,这些技术手段——无论是本体模型、知识图谱,还是图数据库——它们都是“器”,是工具,是手段。
真正的核心,永远是你业务知识与经验的沉淀。
技术可以帮你把数据组织得更清晰,但技术没法帮你凭空创造经验。高质量数据集里最宝贵的部分,是去补充那些静态数据模型里丢失的动态业务语义,是去注入你在这个行业摸爬滚打几十年积累下来的“门道”和“直觉”。
只有当你把这些核心的东西沉淀下来,融入到数据集中,你才能真正构建起一个能够被AI大模型充分利用的、有价值的数据资产。
今天的分享就到这里。希望对大家有所启发。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-27,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号