Palantir 平台深度解析:从数据操作系统到AI操作系统,如何实现深度推理?

Palantir 平台深度解析:从数据操作系统到AI操作系统,如何实现深度推理?

人月聊IT
发布于 2026-04-13 12:47:33
发布于 2026-04-13 12:47:33
大家好,我是人月聊IT。
今天继续跟着我学习和理解Palantir在传统的Foundry平台基础上增加了AIP平台后究竟在哪些地方实现了能力增强和AI赋能?包括AIP平台是如何更好的实现不提前预算规则情况下动态推理的?
具体参考AI对话问题如下:
问题1:对于palantir,早期就是一家做数据集成和数据分析的公司。核心产品是本体驱动的Foundry平台,那么后期增加了AIP平台后究竟解决了传统Foundry平台哪些没有解决的问题?整个AI赋能究竟体现在哪些关键地方?
问题2:也就是说不基于预设规则的AI大模型智能推理能力,包括动态回写能力,都是在AIP平台出来后才真正增强的核心能力?
问题3:AIP的动态推理是基于本体模型构建的知识图谱采用传统的DL语言推理,还是知识图谱存储到图数据库采用图数据库的图算法推理?还是直接采用AI大模型自身内部的动态推理能力?
问题4:帮我构建一个架构图或集成关系图来说明下foundry平台和aip平台里面各个组件之间的联动关系,包括一个动态推理过程是如何完成的。就用你上面谈到的我们的A供应商上周交货情况如何这个业务场景。至少需要体现模型层,数据层,推理过程,数据流动流向等关键信息。
本文系统梳理 Palantir 的产品体系、技术架构、核心子系统及其集成关系,重点剖析 Foundry 与 AIP 两代平台的能力演进逻辑,以及 AI 赋能究竟体现在哪些关键环节。
一、Palantir 是一家什么公司
Palantir Technologies 成立于 2003 年,由 Peter Thiel、Alex Karp 等人联合创办。公司名称来自《魔戒》中的"真知晶球"(Palantír),寓意"看见一切"。它最初以服务美国情报机构起家,逐步扩展到军事、执法、医疗、金融、制造等多个领域。
从定位上看,Palantir 不是一家传统的数据库公司,也不是 BI 工具厂商,而是一家以数据语义化和决策智能化为核心的平台型企业。它解决的根本问题是:企业和政府机构积累了海量数据,但这些数据分散在不同系统、格式各异、互相隔离,导致"数据有了,但决策还是靠人拍脑袋"。
Palantir 的整体产品战略经历了两个明显阶段:早期以 Foundry 为核心,构建数据操作系统;2023 年推出 AIP 后,向 AI 操作系统演进。这两个阶段不是替代关系,而是叠加关系——Foundry 是地基,AIP 是在地基之上运行的"大脑"。
二、核心产品体系总览
Palantir 的产品体系由四个主要产品构成,各有明确的定位和用户群体。
Gotham(政府与军事端)
Gotham 是 Palantir 最早的旗舰产品,主要服务于情报机构、军队和执法部门。它的核心能力是多源异构数据整合与关系网络分析——把来自不同渠道的情报数据(通讯记录、地理位置、金融流水、人员关系)整合在一起,帮助分析师发现隐藏的关联和模式。典型场景包括反恐情报分析、战场态势感知和犯罪网络溯源。
Foundry(企业端)
Foundry 是面向商业企业的数据操作平台,是 Palantir 商业化扩张的核心产品。它的定位是"数据的操作系统"——把企业内部分散在 ERP、CRM、IoT 传感器、数据库、文档中的数据,统一接入、清洗、建模,形成一个企业可以在其上进行分析和决策的共同数据层。典型客户包括空客、BP、英国国民健康服务(NHS)等。
AIP(AI 平台)
AIP 于 2023 年推出,是目前 Palantir 最重要的增长引擎。它的定位是在 Foundry 的数据资产上,安全地引入大语言模型(LLM)推理能力,让 AI 真正能够"读懂"企业数据并采取行动。AIP 的核心卖点是:企业数据不出企业,在私有环境中部署 AI 推理能力。
Apollo(部署运维平台)
Apollo 是贯穿所有产品的底层运维平台,负责跨环境的软件持续交付和版本管理。它支持在公有云、私有云、边缘计算节点乃至完全断网的机密网络(Air-gapped)环境中统一部署和运行 Gotham、Foundry、AIP。Apollo 对上层产品完全透明,是 Palantir 能够服务军事和高安全场景的关键基础设施。
(注:本体模型层在哪里?本体模型层也在Foundry里面,但是注意本体模型实际是构建了Foundry和AIP之间交互协同的桥梁。首先问题场景触发AIP识别分析用户意图,基于本体模型确认需要触发哪些Action,查询调用哪些数据,然后再动态链接到Foundry获取数据,将数据转换为AIP用于后续推理的上下文。)
三、Foundry 平台:数据操作系统的架构逻辑
理解 AIP 之前,必须先理解 Foundry 解决了什么问题,以及它的边界在哪里。
Foundry 做到的事
Foundry 的核心价值在于把企业内部的"数据孤岛"打通,形成一个统一的数据操作层。它的架构自下而上分为三个关键层次:
数据接入与管道层(Pipeline / Transforms)是 Foundry 的入口。它负责从各类数据源(SAP、Salesforce、Kafka 数据流、SQL 数据库、文件系统等)接入数据,进行清洗、去重、格式转换,并组织成标准化的数据集(Dataset)。数据工程师在这一层构建数据管道,是 Foundry 的主要使用者之一。
本体建模层(Ontology)是 Foundry 最具差异化的设计,也是整个 Palantir 平台的核心枢纽。Ontology 把清洗后的数据"升维"为业务对象模型:不再是一张表格里的一行数据,而是一个有属性、有关系、有动作的业务实体。例如,"供应商 A"是一个对象,它有评级、地理位置等属性,与"采购订单"对象存在"suppliedBy"关系,并且可以执行"createOrder"这个动作。这种建模方式让数据从技术层面上升到了业务语义层面。
分析与应用层(Workshop / Slate)是业务用户的操作界面。基于 Ontology 中的业务对象,Foundry 支持构建仪表盘、报表和定制化的业务操作应用。
Foundry 的能力边界
Foundry 做得很好的是数据的"存、通、看"——存储、打通和可视化。但它有一个根本性的局限:所有分析和决策逻辑,都需要人预先定义好规则。系统是被动的、静态的。具体表现在三个方面:
第一,分析师在 Foundry 上看到异常信号之后,需要写报告、开会讨论、人工决策,再回到系统执行。从"发现问题"到"采取行动",中间有一条很厚的人工翻译层,链路极慢。
第二,非技术用户很难直接使用 Foundry。要从 Foundry 中提取洞察,需要懂 Pipeline 构建、懂 Ontology 建模,或者依赖数据工程师。业务人员和 Foundry 之间有一道技术墙,导致大量数据资产被束之高阁。
第三,Foundry 的工作流自动化基于预设规则。规则覆盖的场景可以自动执行,但边界情况和规则未定义的场景,系统就停下来等人处理。这在复杂多变的实际业务中是巨大的瓶颈。
四、AIP 平台:从规则驱动到推理驱动
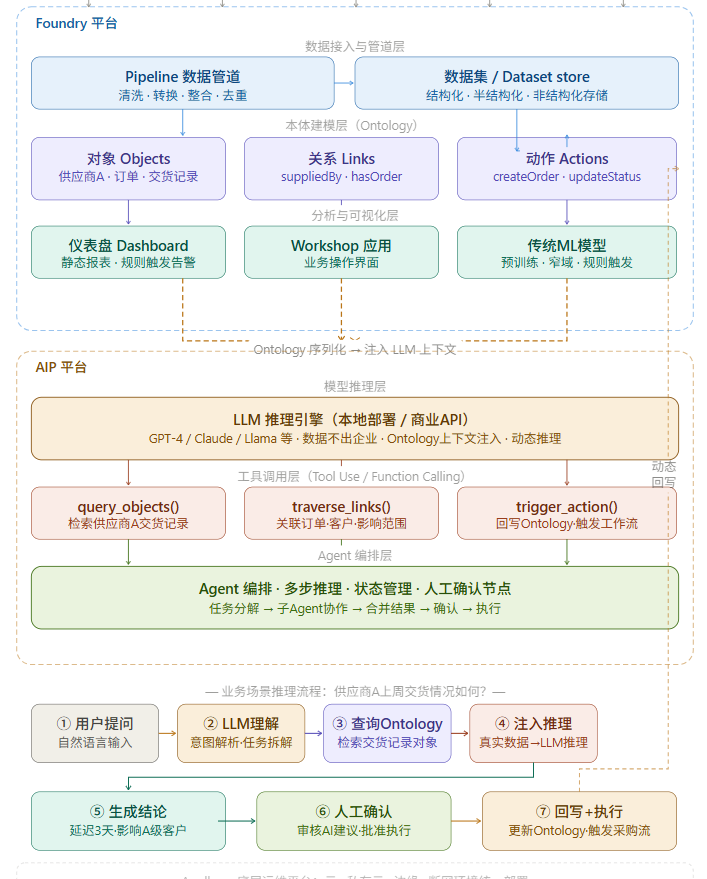
AIP 的出现,本质上是用大语言模型的动态推理能力,补上了 Foundry 留下的那三个缺口。
核心突破一:消除分析与执行之间的人工翻译层
Foundry 时代,数据分析和业务执行是两个独立的环节,中间靠人工连接。AIP 之后,LLM 可以直接读取 Ontology 中的业务对象,用自然语言推理出行动建议,并直接触发工作流执行。决策链路从"数据 → 人 → 动作"压缩为"数据 → AI 推理 → 动作(人确认)"。
核心突破二:自然语言成为操作界面,打破技术墙
AIP 让非技术用户可以直接用自然语言与企业数据交互。一个供应链经理可以直接问:"上周哪些供应商的交货延迟超过了三天,并且影响了我们的 A 级客户?"——AIP 理解意图,查询 Ontology,返回结构化结果,并给出处理建议。这打开了一个巨大的用户群体,让 Foundry 里沉淀的数据资产真正被业务侧消费。
核心突破三:从规则触发到 Agent 自主编排
AIP 引入了 Agent 框架,支持多步骤任务的动态编排。Agent 可以自主分解复杂任务为子步骤,动态选择调用哪个工具(查数据库、调 API、触发工作流),处理规则未覆盖的边界情况,并在必要时请求人工确认。
以一个军事后勤场景为例:"评估东部地区的后勤保障能力"——Agent 会自动拆解为:查库存数据、分析运输路线、评估人员状态、汇总生成报告、标记风险点。整个过程不需要预先编写这条具体的逻辑,LLM 依靠自身的通用推理能力完成任务拆解和执行路径规划。
核心突破四:动态回写,推理结果真正影响业务系统
这是 AIP 最重要的架构突破,也是最容易被忽视的。Foundry 时代,Ontology 是"读多写少"的——数据流进来供分析使用,写回操作笨重且需要预设触发条件。AIP 之后,Ontology 变成了一个"活的操作层":
AI 推理结果 → 直接回写到 Ontology 对象 → 触发下游工作流 → 影响真实业务系统(ERP / CRM / 调度系统)
以供应链场景为例:AI 发现某零件库存将在 72 小时内耗尽,它不只是发出预警,而是直接更新 Ontology 里采购订单对象的状态,触发采购审批工作流,同时通知相关供应商系统。人只需要在关键节点确认。"AI 推理 → 回写 → 触发执行"的闭环,才是 AIP 真正的核心价值。
五、AIP 的推理机制:三层架构的精确分工
理解了 AIP 做什么之后,需要进一步理解它是"怎么做到的"。AIP 的推理机制是三层架构的协同:LLM 负责推理,Ontology 负责接地,工具层负责执行。
LLM 是推理的主体
AIP 选择 LLM 作为推理引擎,而不是传统的描述逻辑(DL)推理或图数据库的图算法,原因是实际业务场景对灵活性的要求远高于对形式化完备性的要求。传统规则引擎只能处理被明确建模的逻辑,遇到边界情况就失败;LLM 可以处理模糊的、开放性的问题,给出近似最优解。
具体实现上,Palantir 支持在私有环境中部署多种 LLM(GPT-4、Claude、开源 Llama 系列等),通过 Model Gateway 统一路由和管理。模型可以是本地部署的开源模型,也可以对接商业 API,Palantir 扮演的是AI 的安全编排层,而不是模型本身。
Ontology 是推理的接地层
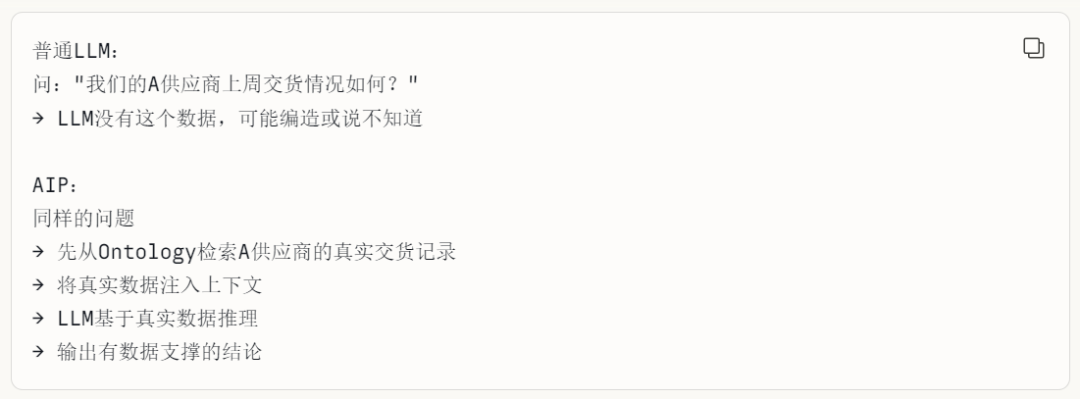
这是 AIP 区别于直接调用公共 LLM API 的核心差异。LLM 有一个致命的企业应用问题:幻觉(Hallucination)——当模型没有相关知识时,可能会编造看似合理的答案。
AIP 的解法是:在 LLM 推理之前,先从 Ontology 中检索与当前问题相关的真实业务对象,将其序列化为 LLM 可读的结构化文本,注入到 LLM 的上下文窗口。LLM 基于真实数据推理,而不是凭空生成。Ontology 保证了推理的事实基础,LLM 提供了推理的智能能力。
以"供应商 A 上周交货情况如何"为例,AIP 的推理过程是:
- 用户自然语言提问
- LLM 解析意图,识别需要查询供应商 A 的交货记录
- 调用
query_objects()工具,从 Ontology 中检索供应商 A 的交货对象 - 检索到真实数据(3 批次、延迟 2 次、平均延迟 3.2 天)注入 LLM 上下文
- LLM 基于真实数据推理,生成情境化结论(延迟影响了哪些 A 级客户)
- 人工确认后,回写 Ontology 并触发采购流程
工具层是推理的执行臂
LLM 通过 Function Calling / Tool Use 机制按需调用各类工具。主要分三类:
query_objects() 负责从 Ontology 中检索特定类型的业务对象,支持过滤条件;traverse_links() 负责在对象之间进行关系遍历,找出关联实体(如供应商关联的订单、订单关联的客户);trigger_action() 负责将推理结果回写到 Ontology 并触发预定义的业务动作(如创建采购单、发送通知)。
LLM 在推理过程中动态决定何时调用哪个工具、传入什么参数,工具执行结果再返回 LLM 继续下一步推理。这个"推理 → 调用 → 观察 → 继续推理"的循环,就是 Agent 的工作模式。
六、关于图数据库的架构辨析
在理解 AIP 的推理机制时,一个常见的疑问是:既然 Ontology 本质上是图结构(对象是节点,关系是边),是否应该把数据注入图数据库,利用图数据库的查询和推理能力?
答案是:没有必要,而且会引入不必要的复杂性。原因有三:
第一,Ontology 本身已经是图模型,并内置了关系遍历能力(traverse_links())。把数据再导入独立图数据库,等于为已有的图结构套一层图结构,造成数据冗余和同步复杂性。
第二,LLM 需要的是"语义化文本",不是"图查询的原始结构化结果"。图数据库返回的是节点 ID、边类型、路径列表——结构化但语义贫乏,LLM 还需要二次理解。Ontology 序列化的输出是直接语义化的业务描述,LLM 可以立即推理。
第三,图数据库的图算法(PageRank、最短路径、社区发现等)适用于大规模、需要全局拓扑计算的场景(百万级节点、多跳关系分析)。在 AIP 的典型推理场景中,通常只需要 2-3 跳的局部关系遍历,Ontology 完全胜任,根本不需要图算法。
如果业务场景确实需要大规模图分析(如金融风控的资金链路追踪、多级供应链风险传导),正确的架构是:图数据库在 LLM 上游做预处理,将图算法结果序列化为语义文本后再注入 LLM 上下文。图数据库应该在推理链路的上游,而不是下游。
七、整体平台架构:六层结构与横向集成
Palantir 的完整平台架构可以从纵向和横向两个维度理解。
纵向六层结构
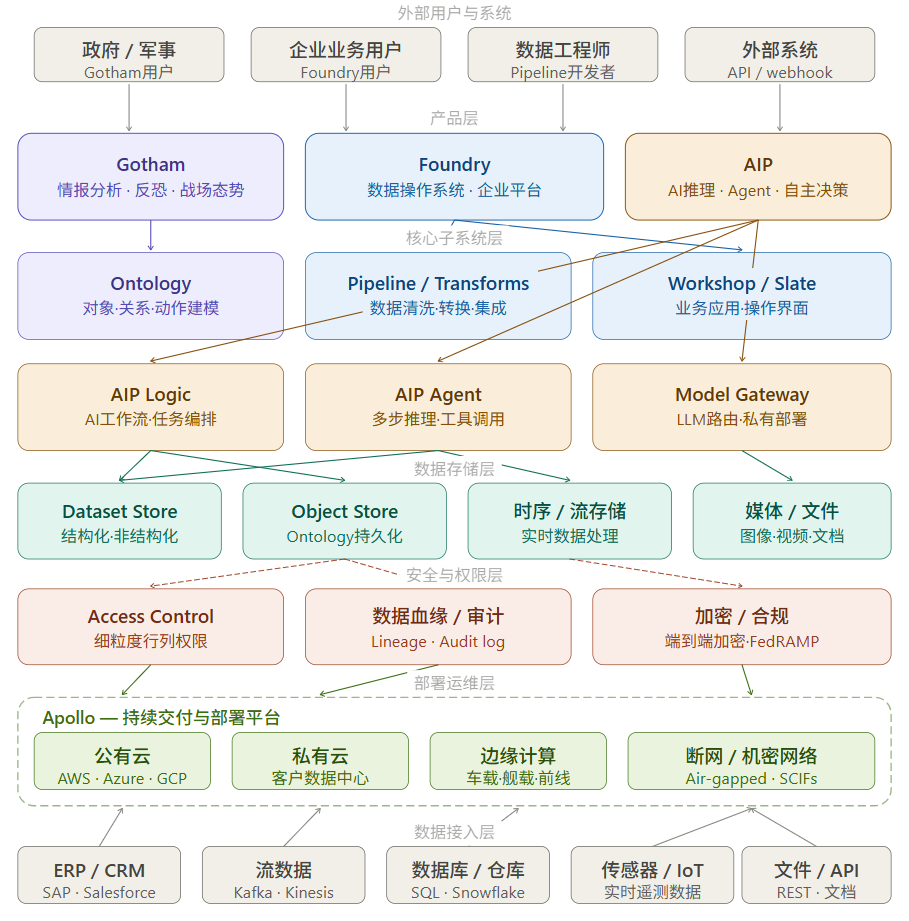
从上到下分别是:外部用户与系统层、产品层(Gotham / Foundry / AIP)、核心子系统层(Ontology / Pipeline / Workshop / AIP Logic / Agent / Model Gateway)、数据存储层(Dataset Store / Object Store / 时序存储 / 媒体文件)、安全合规层(Access Control / 数据血缘 / 加密合规),以及贯穿所有层次的 Apollo 部署运维层。
这六层的分工清晰:产品层面向最终用户,子系统层提供核心能力,存储层保证数据持久化,安全层横切每一层做权限管控,Apollo 对所有层提供透明的跨环境部署保障。
横向集成关系
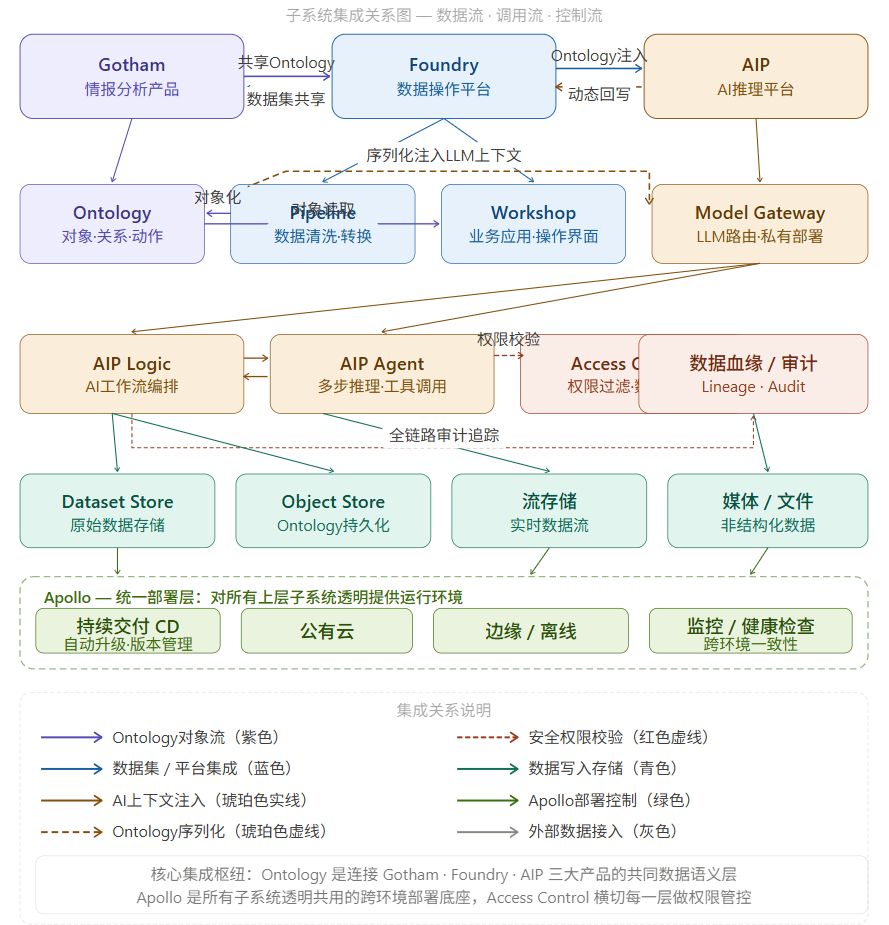
横向来看,有三条核心的集成路径:
Ontology 是连接三大产品的语义枢纽。 Gotham 和 Foundry 共享同一套 Ontology 层,军事情报对象和企业业务对象使用相同的建模范式。AIP 通过 Ontology 序列化获取 LLM 推理所需的上下文,推理结果再通过动态回写返回 Ontology,形成闭环。
Access Control 是横切所有层的安全管控面。 无论是业务用户访问 Workshop、LLM 查询 Ontology 对象,还是 Agent 触发 Action,都需要经过细粒度的行列级权限校验。AIP 的重要设计之一是:LLM 只能看到当前用户权限范围内的 Ontology 对象,权限边界不因引入 AI 而放宽。
Apollo 是所有子系统共用的部署底座。 Gotham、Foundry、AIP 的每一个子系统,都通过 Apollo 进行版本管理和跨环境部署。Apollo 让同一套代码可以在 AWS 云端、客户私有数据中心、前线作战车辆和断网机密网络中统一运行,这是 Palantir 能够服务高安全场景的根本保障。
八、核心技术护城河:为什么难以复制
理解了架构之后,Palantir 真正的护城河是什么?并不是某一项具体的技术,而是三层能力的叠加:
Ontology 作为 AI 的接地层,这是 Palantir 与其他 AI 平台最本质的架构差异。Ontology 不只是一个数据模型,它是连接现实世界业务语义和 AI 推理能力的桥梁。竞争对手可以集成同样的 LLM,但无法在短时间内复制客户在 Ontology 上积累多年的业务建模资产。
安全部署能力是第二道护城河。政府和军事客户的数据不能进入公共云,商业客户的核心数据也不愿意离开私有环境。Apollo 提供的跨环境一致性部署能力,加上端到端的加密和细粒度权限控制,让 Palantir 能够进入其他 AI 平台无法触达的高安全场景。
业务语义积累是第三道护城河。Palantir 在每个客户处的实施,都是在构建该客户领域的 Ontology 对象模型——哪些实体是重要的,它们之间有哪些关系,有哪些关键动作。这些领域知识的积累,随着时间推移形成越来越高的迁移成本。
九、一句话总结 Palantir 的演进逻辑
如果用一句话总结 Palantir 从 Foundry 到 AIP 的演进:
Foundry 让企业的数据变得可用;AIP 让企业的数据变得会思考、会行动。
Foundry 解决的是数据的"存、通、看";AIP 解决的是数据的"懂、判、做"。Ontology 是连接两者的语义地基,Apollo 是保证两者在任何环境下都能运行的部署底座,三者合一,才是 Palantir 所说的"AI 操作系统"的完整含义——不是操作电脑的 OS,而是操作企业乃至军队整体运转的 OS。
本文基于对话整理,供参考。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号