本体模型+AI 大模型驱动的 AI 原生应用技术架构设计

本体模型+AI 大模型驱动的 AI 原生应用技术架构设计

人月聊IT
发布于 2026-04-13 12:51:37
发布于 2026-04-13 12:51:37
大家好,我是人月聊IT。
在上一篇文章中给出了完整的UI建模规范标准。但是我们在正式让AI通过静默编程方式输出完整系统还缺少一个关键的技术架构设计。这个技术架构设计需要定义整个技术框架,技术组件,编程语言和前后端框架,核心算法,安全,AI对话交互实现机制等关键内容。
我在前面多次强调,本体模型不仅仅是支撑AI自动生成系统,更加重要的是AI在充分理解本体模型后,能够在后续和AI通过自然语言进行交互。这个自然语义交互也不是简单的类似ChatBI的功能。而是具备应用系统的推理和分析能力,这个才是我们真正需要的核心功能。
在有了完整的技术架构规范Markdown格式文件定义后,我们基本就准备完成了所有的前期工作。
架构定位与核心理念
1.1 系统本质
本架构描述的系统不是一个"加了 AI 功能的传统 CRUD 应用",而是一套以本体模型为核心驱动力、以 AI 大模型为生成引擎和运行时智能引擎的 AI 原生应用架构。它的核心特征体现在三个层面:
其一,以本体模型作为业务语义核心的模型驱动系统。所有的数据结构、接口定义、页面布局、AI 工具能力,都从同一套本体模型派生,而不是由开发者手工逐一编写。本体模型是整个系统的唯一真相源(Single Source of Truth)。
其二,以 AI 大模型作为双引擎的 AI 原生系统。在建造期,AI 大模型基于本体 YAML 自动生成应用骨架代码;在运行期,AI 大模型作为智能交互引擎,理解用户意图,调用后端能力,动态渲染结果。两个阶段共用同一套语义知识底座。
其三,采用 Hybrid UI 模式的企业级轻量应用。高频确定性操作通过固定业务界面完成,低频探索式需求通过 AI 对话动态完成,两者共享统一的后端能力层和设计系统,对用户呈现一致的视觉体验。
1.2 本体模型的三重角色
理解本架构的关键,在于理解本体模型在系统中承担的三重角色——这三重角色构成了整个系统从建造到运行的完整闭环:
角色一:业务建模载体。 本体模型通过 M1(对象)、M2(行为)、M3(规则)、M4(场景)、M5(主体)、M6(补偿)、M7(质量)、ME(事件)、M9(UI 模型)九个维度,完整表达了业务域的语义结构。每个维度都是一个独立的 YAML 元文件,可独立演进,互相引用。
角色二:程序生成基础。 AI 大模型在建造期读取这些 YAML,自动生成数据库表结构、后端 API 骨架、前端页面组件、AI 工具 Schema 定义等全部程序产物。代码是本体语义的物理实现,不是凭空编写的。
角色三:AI 推理知识底座。 在运行期,本体模型的语义内容被加载进运行时注册表,作为 AI 大模型构建 Prompt 上下文的结构化知识来源。AI 在理解"帮我查张三负责的未收款合同"这类意图时,注册表提供了实体定义、字段语义、查询边界等精确的业务语义,大幅提升了 AI 的执行精度和可控性。
(注:实际在UI规范yaml上,AI又单独输出一个含内容的UI模型文件,导致后续真实编码时的UI界面输出没有达到我的期望)
1.3 架构设计原则
全架构遵循以下六条设计原则:本体优先(本体模型是一切的起点,不存在游离于本体之外的业务逻辑)、能力复用(固定页面和 AI 对话共用同一后端能力层,不维护两套实现)、安全分级(AI 对话只读动态 SQL 严格受白名单控制,写操作必须通过固定页面)、渐进增强(MVP 阶段聚焦核心链路,权限、多租户、事件总线等能力预留扩展位)、生成友好(架构设计充分考虑 AI 代码生成的可操作性,模块边界清晰,职责单一)、视觉一致(固定页面与 AI 动态渲染遵循统一设计系统)。
总体分层架构
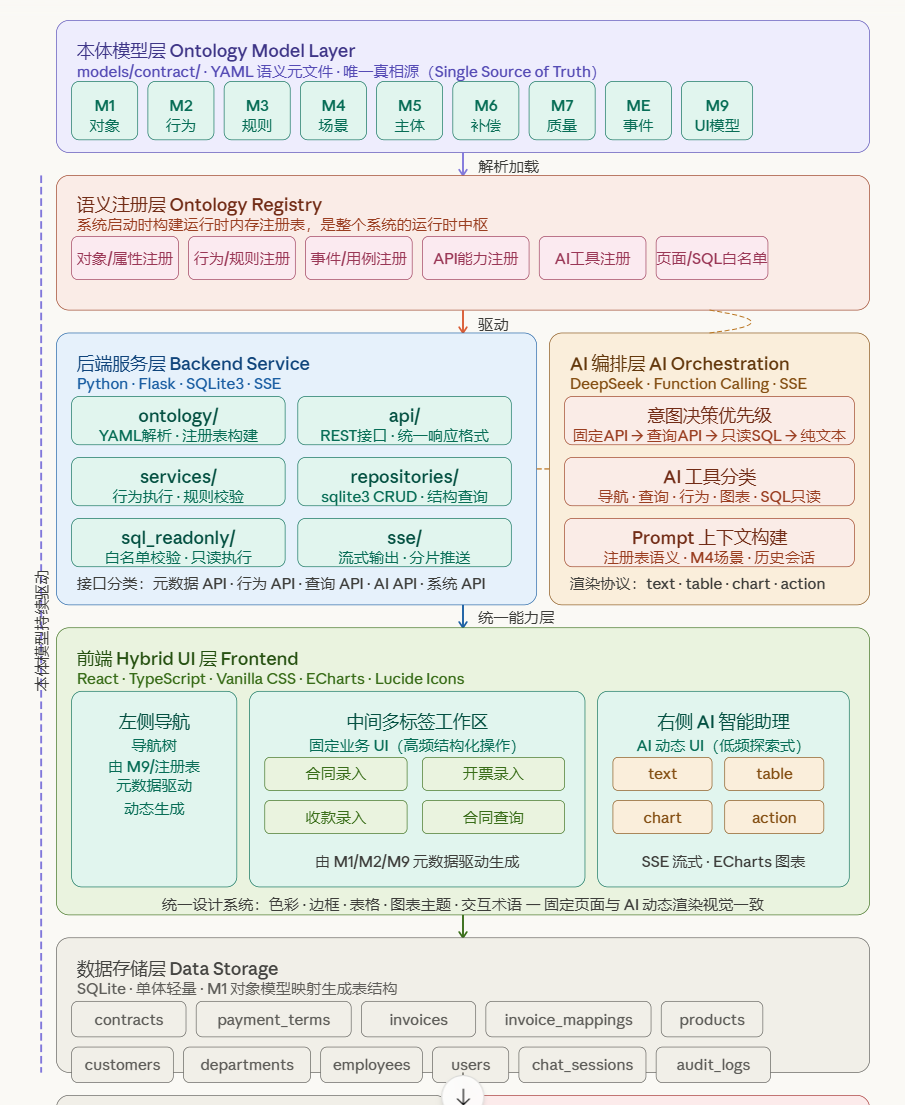
整个系统采用单体应用、分层解耦的方式实现,共六个层次,自上而下依次为:本体模型层、语义注册层、后端服务层、AI 编排层、前端 Hybrid UI 层、数据存储层。
本体模型层是整张图的顶端起点,M1–M9 九个 YAML 元文件并排展示,强调它们是整个系统的"唯一真相源"。左侧的紫色竖虚线贯穿所有层,标注"本体模型持续驱动",视觉上强调了本体模型不只是建模工具,而是运行时的持续驱动力。
语义注册层紧接其下,六类注册内容(对象属性、行为规则、事件用例、API 能力、AI 工具、页面/SQL 白名单)并列排布,体现了注册表作为"运行时中枢"统一供给所有下层模块的核心地位。
后端服务层与 AI 编排层并排放置,两者之间有虚线连接,体现"固定 UI 和 AI 对话共用同一后端能力层"的核心原则。AI 编排层内部的意图决策优先级(固定 API → 查询 API → 只读 SQL → 纯文本)直观呈现了你文档第 9.5 节的决策顺序。
前端 Hybrid UI 层用三栏结构(左导航 + 中工作区 + 右 AI 助理)准确还原了你的三栏工作台形态,固定业务 UI 的四个页面和 AI 动态 UI 的四种渲染类型(text/table/chart/action)分别用不同颜色区分,底部强调统一设计系统。
数据存储层列出了全部 12 张建议表,并标注"由 M1 对象模型映射生成"。底部的动态 SQL 安全控制模块用红色单独标注,突出其安全边界的重要性。
各层职责边界清晰,相邻层之间通过明确定义的接口交互,非相邻层不直接访问。本体模型层作为源头,通过语义注册层向下游三个执行层(后端、AI 编排、前端)持续提供语义驱动力。
各层详细设计
3.1 本体模型层
本体模型层是整个架构的起点,由位于 models/contract/ 目录下的九个 YAML 元文件构成。该层只表达业务语义,不承载任何运行逻辑。
各模型文件的驱动范围如下:
m1-object-model.yaml 驱动 SQLite 表结构生成、DTO 数据传输对象、表单字段定义、查询条件字段及实体引用关系。这是系统数据骨架的根本来源,所有的数据表都从 M1 的实体定义映射生成,不存在手工维护的数据库 Schema。
m2-behavior-model.yaml 驱动业务执行 API 的端点定义、AI 工具函数的 Schema 注册、前端页面的提交逻辑和按钮行为绑定。M2 中定义的每一个 COMMAND 行为对应一个写接口,每一个 QUERY 行为对应一个读接口。
m3-rule-model.yaml 驱动后端参数校验逻辑、前端输入提示规则、以及 AI 工具调用前的前置验证。规则在服务层以策略对象的方式注入行为执行流程,保持规则逻辑与行为逻辑的解耦。
m4-scenario-model.yaml 驱动页面与业务用例的绑定关系、AI 对话中的复杂操作执行路径说明。M4 场景描述也作为 Prompt 上下文的重要组成部分,帮助 AI 理解多步骤操作的完整业务流程。
me-event-model.yaml 定义行为执行后的领域事件,驱动行为完成后的状态回写链路和 AI 可解释的执行路径,同时为未来扩展事件总线预留了语义定义。
m9-contract-ui-model.yaml 驱动前端导航树生成、多标签页定义、表单布局、表格列配置及 AI 对话动作映射。UI 模型使前端页面不再是手工硬编码的静态组件,而是可以从语义定义中装配的动态结构。
3.2 语义注册层(Ontology Registry)
语义注册层是整个系统运行时的中枢,系统启动时首先解析全部本体 YAML,在内存中构建统一的注册表。注册表的数据结构组织如下:
registry = {
"aggregates": {}, # 聚合根边界定义
"entities": {}, # 实体属性定义(来自 M1)
"behaviors": {}, # 行为定义(来自 M2)
"rules": {}, # 规则定义(来自 M3)
"events": {}, # 事件定义(来自 ME)
"use_cases": {}, # 用例场景定义(来自 M4)
"quality_annotations": {}, # 质量约束(来自 M7)
"pages": {}, # 页面元数据(来自 M9)
"navigation": {}, # 导航树结构(来自 M9)
"api_capabilities": {}, # API 能力清单(从 M2 派生)
"ai_tools": {}, # AI 工具 Schema(从 M2 派生)
"db_whitelist": {} # 动态 SQL 白名单(从 M1 派生)
}
注册表的核心价值体现在四个方面。首先是 API 能力注册——把 M2 中所有可执行行为注册为标准化接口能力,后端路由层基于注册表动态暴露接口,新增业务行为无需手工添加路由。其次是 AI 工具注册——把可安全复用的行为、查询、规则能力注册为 Function Calling 的工具 Schema,AI 只能调用注册表中已明确定义的工具,不能超出语义边界自行构造调用。第三是页面元数据注册——把 M9 UI 模型注册为页面元数据,前端通过元数据接口获取导航结构、表单定义、表格列配置,实现页面的语义驱动生成。第四是数据库白名单注册——根据 M1 对象模型和已登记的查询行为,自动生成动态 SQL 可访问的表名、字段名白名单,为只读 SQL 安全控制提供权威数据源。
注册表在系统启动时一次性构建,驻留内存,供所有模块同步读取。这使得本体模型的语义变更(修改 YAML 后重启)能够自动同步到全部下游模块,无需逐一修改代码。
3.3 后端服务层
后端采用 Python + Flask + sqlite3 的轻量化技术栈,不引入 ORM 框架,以保持与 AI 代码生成的最大兼容性和最低复杂度。后端模块按职责划分为八个目录:
ontology/ 是注册表构建模块,负责 YAML 加载、模型校验和注册表初始化。系统启动时这是第一个执行的模块,其产出的注册表对象作为应用上下文全局共享。
api/ 是路由层,负责 REST 接口暴露、请求参数接收和统一响应封装。所有接口遵循统一响应格式:{ success, message, data, errorCode, traceId },异常统一由全局错误处理器捕获并格式化。
services/ 是业务逻辑层,负责行为执行、规则校验、查询执行和事件后处理。服务层是 M2 行为和 M3 规则的实现载体,每个 M2 行为对应一个服务方法,规则以策略对象的方式在行为执行前注入校验。
repositories/ 是数据访问层,直接使用 sqlite3 执行 SQL,负责所有的增删改查操作。不使用 ORM 的原因是 AI 生成的 SQL 更易读、更易调试,且与本体模型的字段映射关系更透明。
ai/ 是 AI 编排模块,负责 DeepSeek 接口对接、Prompt 构建、工具 Schema 注册和 Function Calling 调用结果处理。Prompt 构建时从注册表提取相关实体定义、行为描述和场景语义,作为系统 Prompt 的结构化业务上下文。
sql_readonly/ 是动态只读 SQL 模块,负责对 AI 生成的 SQL 进行白名单校验、危险关键字过滤、LIMIT 追加和审计日志记录。这是整个架构中安全边界最为严格的模块。
sse/ 是流式输出模块,基于 Server-Sent Events 协议实现 AI 对话的流式推送,定义了六种消息类型:message_start、delta(增量文本)、tool_call(工具调用状态)、tool_result(工具执行结果)、render_payload(结构化渲染内容)、message_end。
utils/ 是通用工具模块,包含日志、配置加载和公共校验函数。
后端接口按功能分为五类:元数据接口(/api/meta/*,返回导航树、页面定义和字段元数据)、行为接口(/api/behaviors/{behavior_id}/execute,对应 M2 写行为)、查询接口(/api/queries/{query_id}/execute,对应 M2 查询行为)、AI 接口(/api/ai/chat、/api/ai/chat/stream、/api/ai/tools)、系统接口(/api/auth/login、/api/health)。
3.4 AI 编排层
AI 编排层是本架构区别于传统应用的核心差异点,负责将用户的自然语言意图路由到正确的执行能力。运行时大模型固定采用 DeepSeek,通过配置文件管理 API Key、Base URL 和模型名,不硬编码。
意图决策算法是 AI 编排层最核心的设计,采用严格的优先级顺序:
第一优先级:固定工具或已注册的 API 能力。AI 首先检查注册表中的 ai_tools 和 api_capabilities,判断当前意图是否有对应的工具函数可以直接调用。这是最安全、最精确的执行路径。
第二优先级:注册表已有的查询能力。如果意图是数据查询类,且注册表中有对应的查询行为,调用已有查询接口返回结构化结果。
第三优先级:只读动态 SQL。当前两个优先级都无法覆盖时,且用户请求明确是只读查询,AI 可以生成 SQL 交给 sql_readonly 模块执行。这个路径受到严格的白名单控制,是最后一道能力补位手段。
第四优先级:纯文本解释。如果用户请求涉及写操作但没有通过固定页面提交,或者问题超出当前系统能力范围,AI 必须明确说明限制,不得尝试绕过安全边界。
AI 工具按功能分为五类:页面导航工具(打开指定业务页面)、查询工具(执行合同模糊查询、获取合同详情等)、行为工具(执行合同录入、开票录入、收款确认等写操作)、图表生成工具(将查询结果转换为 ECharts 图表配置)、只读 SQL 工具(动态生成并执行严格受控的 SELECT 查询)。
Prompt 上下文构建时,从注册表动态注入三类语义信息:相关实体的字段定义(让 AI 知道哪些字段存在、字段含义是什么)、相关行为的参数定义(让 AI 知道工具调用需要哪些参数)、相关场景的流程说明(让 AI 理解多步骤操作的上下文)。这种基于注册表的动态 Prompt 构建,使 AI 的业务理解精度显著高于使用通用 Prompt 的方案。
3.5 前端 Hybrid UI 层
前端采用 React + TypeScript + Vanilla CSS 技术栈,图表使用 ECharts,图标使用 Lucide Icons。不引入重量级 UI 组件库,以保持样式的完全可控性和与 AI 生成代码的兼容性。
前端整体采用三栏工作台形态:左侧导航树(由 M9 UI 模型和注册表元数据接口驱动生成)、中间多标签工作区(承载固定业务 UI)、右侧 AI 智能助理(承载 AI 动态 UI)。
固定业务 UI 承载高频、确定性、结构化的业务操作,第一阶段包括合同录入页、开票录入页、收款录入页、合同查询页四个页面。这些页面不完全手工编写,而是基于后端元数据接口(/api/meta/pages)返回的页面定义,结合 M1 字段定义和 M9 布局定义,动态装配组件。表单字段的类型、必填规则、枚举值列表都来自本体模型的语义定义,不在前端代码中硬编码。
AI 动态 UI 承载低频、探索式、分析式的交互需求,支持四种渲染类型。text 类型用于业务说明、状态反馈和执行结果描述,以流式文字形式逐字呈现。table 类型用于列表展示和结构化查询结果,表格样式与固定页面中的查询表格保持一致。chart 类型用于趋势图、分布图和统计图,固定使用 ECharts 渲染,图表主题与整体设计系统统一。action 类型用于引导用户打开某个固定页面或执行某个行为,以可点击卡片形式呈现。
前端分层结构包含六个模块:Layout 层(三栏框架结构)、Meta-driven 页面层(基于元数据动态生成页面骨架)、Functional 业务组件层(表单、表格等具体业务组件)、AI Chat 层(对话界面和渲染协议处理)、API Client 层(统一的后端接口调用封装)、SSE Client 层(流式响应的接收和拆解)。
视觉一致性是 Hybrid UI 模式的核心要求:固定页面与 AI 动态渲染必须共享统一的色彩系统、边框与背景体系、表格风格、图表主题、文字和状态标签规范。AI 对话框里渲染的表格与主工作台中的查询表格,应被视为同一设计系统下的不同容器,而非风格迥异的两套界面。
3.6 数据存储层
数据库固定使用 SQLite,选型理由是部署零依赖、原型开发快、适合 AI 生成代码的快速落地验证。数据库表结构完全由 M1 对象模型映射生成,不存在手工维护的 Schema。
表结构的映射策略遵循以下规则:M1 中的聚合根实体映射为独立主表(contracts、invoices);聚合内的明细实体映射为带外键的明细表(contract_payment_terms、invoice_term_mappings);支撑域引用实体映射为主数据表(products、customers、departments、employees);系统运行所需的非业务表包括 users(登录用户)、chat_sessions(对话会话)、chat_messages(对话历史)和 audit_logs(审计日志)。
所有业务表自动注入四个审计字段:created_at、updated_at、created_by、updated_by,由 ontology 模块在建表语句生成时统一追加,不在 M1 模型中显式定义。
四、动态 SQL 只读机制
动态 SQL 只读机制是本架构中安全设计最为精密的部分,也是 AI 能力从"有限工具调用"向"无限查询能力"扩展的关键桥梁。
4.1 适用场景与安全边界
当 AI 对话遇到当前注册表中没有对应查询 API 的数据读取需求时(如"最近 30 天哪个客户合同金额最高"、"按产品类型统计已开票金额"),才启用动态 SQL 路径。这是最后一道能力补位手段,不是第一选择。
动态 SQL 模块执行严格的只读约束。在语句级别,仅允许 SELECT 语句,明确禁止 INSERT、UPDATE、DELETE、DROP、ALTER、TRUNCATE、CREATE、ATTACH 和任何 PRAGMA 写操作。在结构级别,只允许访问白名单表和白名单字段,强制追加 LIMIT 防止大结果集,禁止多语句执行,设置 SQL 执行超时。在记录级别,所有动态 SQL 的执行都写入审计日志,包含生成的 SQL 语句、执行时间、结果行数和调用会话 ID。
4.2 白名单生成算法
SQL 白名单不手工维护,而是从注册表自动派生。派生算法如下:遍历注册表中 entities 的所有实体定义,提取每个实体对应的数据库表名和全部字段名,构建 {table: [fields]} 格式的白名单字典;遍历注册表中 behaviors 的所有 QUERY 类行为,提取其 queryable_fields 定义,追加到对应表的字段白名单;遍历注册表中 db_whitelist 的预定义视图和统计口径,补充复合查询的允许范围。每次系统启动时重建白名单,确保与当前本体模型保持同步。
4.3 动态 SQL 执行链路
完整执行链路分为七步:用户发起自然语言问题 → AI 判断当前无可复用 API,请求调用 readonly_sql_query 工具 → 后端接收工具调用请求,提取 AI 生成的 SQL → sql_readonly 模块对 SQL 进行关键字扫描、表名校验、字段校验 → 校验通过后执行 SQL,强制追加 LIMIT 500 → 结果转换为 text / table / chart 渲染协议 → 通过 SSE 流式返回前端渲染。任何校验环节失败都会中断执行并返回明确的拒绝原因,而不是静默失败。
五、SSE 流式输出架构
AI 对话必须支持流式输出,这是 AI 原生应用用户体验的基本要求。后端通过 SSE(Server-Sent Events)协议推送六种消息类型:message_start(标识本次响应开始)、delta(AI 输出的增量文本片段)、tool_call(AI 正在调用某个工具,携带工具名和参数)、tool_result(工具执行完成,携带结果数据)、render_payload(最终结构化渲染内容,包含渲染类型和渲染数据)、message_end(标识本次响应结束,携带完整的 token 消耗统计)。
前端 SSE Client 层按消息类型进行分流处理:收到 delta 时,增量拼接文本并逐字呈现;收到 tool_call 时,在对话区显示"正在查询合同数据…"等状态提示;收到 tool_result 时,更新工具执行状态;收到 render_payload 时,根据渲染类型(text / table / chart / action)切换最终呈现组件;收到 message_end 时,清理临时状态,完成渲染。这种分层的流式消息协议,使得 AI 对话体验流畅自然,用户在等待过程中始终能感知到系统的执行状态。
六、技术选型说明
6.1 技术选型汇总
技术域 | 选型 | 选型理由 |
|---|---|---|
后端框架 | Python + Flask | 轻量、AI 代码生成兼容性最佳、无魔法约定、易于阅读和修改 |
数据访问 | sqlite3(原生) | 不引入 ORM,SQL 透明,与 M1 映射关系清晰,AI 生成代码易于验证 |
数据库 | SQLite | 零依赖部署,原型开发快,MVP 阶段完全满足需求 |
AI 大模型 | DeepSeek | 支持 Function Calling,成本较低,中文业务语义理解能力强 |
流式协议 | SSE | 单向推送场景下比 WebSocket 更轻量,HTTP 原生支持,无需额外连接管理 |
前端框架 | React + TypeScript | 组件模型与元数据驱动页面生成契合,类型系统提升 AI 生成代码的可靠性 |
图表库 | ECharts | 配置式 API 适合 AI 动态生成图表配置,图表类型丰富,中文支持好 |
图标库 | Lucide Icons | 轻量,Tree-shakeable,风格简洁,与 Vanilla CSS 搭配无冲突 |
样式方案 | Vanilla CSS | 不依赖 CSS 框架,样式完全可控,AI 生成的 CSS 无框架约定干扰 |
配置管理 | YAML + 环境变量 | 与本体模型格式统一,配置语义清晰,敏感信息通过环境变量注入 |
6.2 关键技术决策说明
不使用 SQLAlchemy 的理由:ORM 会在数据访问层引入额外的映射层,使 M1 实体到数据库表的对应关系变得不透明。直接使用 sqlite3 执行 SQL,每一行 SQL 都能追溯到 M1 中的实体定义,调试和验证更直接。在 AI 生成代码的场景下,透明性比便利性更重要。
不使用重量级 UI 框架(如 Ant Design、MUI)的理由:组件库会引入大量预设样式和交互约定,AI 生成代码时很难保证组件用法的正确性,且样式覆盖成本高。Vanilla CSS 加上设计令牌(Design Tokens)方式定义的统一样式变量,能给 AI 代码生成提供更清晰的样式约束,同时保证固定页面和 AI 动态渲染的视觉一致性。
不使用 WebSocket 的理由:AI 对话是典型的单向服务端推送场景(用户发一次请求,服务端持续推送响应片段),SSE 在这个场景下比 WebSocket 更轻量,无需维护双向连接状态,且基于 HTTP 协议天然穿透代理和防火墙。
(注:注意该技术选型全部采用轻量化数据库和轻量组件,仅仅是为我个人验证完整模型驱动跑通使用。实际生产应用技术选型会更加复杂)
七、第一阶段落地范围
MVP 阶段严格控制实现范围,优先走通核心业务闭环:登录认证(简化版,默认管理员账号)、本体模型解析与注册表构建、合同录入与查询详情、开票录入、收款录入、AI 对话与 Function Calling、只读动态 SQL 查询、ECharts 图表渲染。
明确不在第一阶段实现的能力:完整 RBAC 权限体系(M5 保留语义占位)、多租户隔离、附件上传与管理、外部系统集成、分布式事件总线(ME 保留语义定义)、复杂工作流审批流程。
这些能力均在本体模型层面预留了语义定义,后续扩展时可以基于已有的语义基础快速落地,不需要重新建模。
八、关键结论
本架构的核心不是某个技术框架,而是"本体模型 + 运行时语义注册表 + 可复用 API + AI 工具调用"形成的统一闭环。这个闭环使得系统具备三个关键特性:
可生成性:架构设计的每一个组件边界都经过了"AI 能否从本体 YAML 生成这个组件"的验证,模块职责单一,接口清晰,AI 代码生成的成功率和质量显著高于面向传统复杂框架的生成。
可演进性:业务变更时,只需修改对应的本体 YAML 文件,注册表在下次启动时自动更新,API 能力、AI 工具、页面元数据和 SQL 白名单随之同步。大多数业务变更不需要修改一行代码。
可信赖性:AI 的执行能力边界被注册表严格约束,动态 SQL 受白名单严格管控,写操作只能通过固定页面的结构化 API 执行。AI 在这套架构中是一个受控的能力调度引擎,而不是一个自由发挥的黑盒。
这套架构既适合当前的合同管理场景,也适合作为后续更多业务域扩展的通用 AI 原生应用底座。当一个新的业务域需要接入时,只需提供对应的本体 YAML,整个技术栈可以直接复用。
注:个人基于该技术架构初步研发发现两个关键问题是。AI大模型在自动化生产UI功能界面的时候出现较大偏差,界面布局美观性和和UIDemo原型有很大出入。其次是AI大模型对话的时候感觉AI没有充分理解我本体模型的业务语义,导致很大自然语义对话存在幻觉。
AI 对话与本体 Copilot 迭代优化记录
本项目最初的目标,不只是生成一个“能跑起来的合同管理系统”,而是构建一个“本体模型驱动 + AI 大模型驱动”的 AI 原生应用。也就是说,models/contract 下的多个本体 YAML 文件,既要支撑系统生成,也要成为后续 AI 对话理解业务语义、解释流程规则、回答查询问题的语义基础。围绕这个目标,系统经历了多轮逐步优化,核心过程如下。
第一阶段,先完成基础应用落地。系统最初实现了前后端完整应用骨架,后端采用 Flask + sqlite3,前端采用 React + TypeScript + Vanilla CSS,并把合同录入、开票录入、收款录入、合同查询四个核心功能全部跑通。同时,系统支持 DeepSeek 大模型接入、SSE 流式输出、Hybrid UI,以及只读 SQL 兜底能力。这一阶段解决的是“从本体模型到可运行系统”的问题,但 AI 对话能力仍偏基础,更多是“能用”而不是“懂业务”。
第二阶段,开始补“语义查询引擎”。早期版本的 AI 对话更像普通聊天加若干关键词判断,很多业务查询虽然能返回结果,但语义并不稳定。例如“按部门统计合同总金额并输出三列信息”,最初只能返回两列;“某个合同的总金额和销售部门是什么”,也会错误地输出成表格,而不是自然语言。因此后续引入了结构化 semantic_query 能力,把自然语言拆解为 subject / intent / groupBy / metrics / fields / filters / responsePreference 等语义计划,再据此调用后端查询或生成图表。这样,统计、详情、单字段问答、图表输出才真正开始稳定。
第三阶段,修正了“只靠本地规则理解”的偏差。用户明确要求 AI 对话必须先调用大模型理解问题,再结合本体模型和后端能力完成回答,而不是完全靠本地 parser 先拍板。针对这一点,编排器被改成“DeepSeek 优先、函数调用驱动、本地逻辑仅兜底”的模式。大模型先结合本体上下文判断用户意图,再选择 semantic_query、readonly_sql_query 或页面跳转等工具。这一轮修正的核心原因,是此前虽然可用,但不符合“AI 真正理解本体语义”的设计原则。
第四阶段,补上“本体知识问答”能力。早期 AI 更擅长查合同、查收款、查统计,但一旦用户问“当前系统里的合同创建流程是如何的”“合同创建有哪些规则”,系统就会误判成写操作请求,返回“当前 AI 对话仅支持只读查询和页面导航”。问题根源有两个:一是缺少专门的本体知识检索通道;二是“创建”这类词被简单地判定成了新增操作。后续为此增加了运行时知识注册表,把 M1/M2/M3/M4/ME 模型、原始需求文档、技术架构文档统一整理成知识条目;同时新增 ontology_knowledge_query 工具,让 AI 可以围绕流程、规则、事件、页面职责进行解释型回答。之后又进一步优化 CUD 误判逻辑,把“流程、规则、如何、怎么、是什么”等解释性问题从写操作识别中剔除。
第五阶段,进入“领域 Copilot”深化阶段。这一轮不是简单做知识检索,而是要让 AI 能像顾问一样解释“为什么”。例如“为什么 HT2026040005 既没有开票,也没有收款”“为什么 HT2026040001 是部分收款”。这里暴露出一个关键问题:仅有本体知识还不够,AI 还必须结合真实业务数据和状态推导规则回答。因此新增了 domain_explanation_query 能力,把本体里的行为、规则、事件链与数据库中的合同、发票、收款实际状态结合起来,输出更接近业务顾问风格的解释文本。比如它不仅回答“未收款”,还会进一步说明“合同总金额是多少、累计收款是多少、当前有几张已收款/未收款发票,因此根据 Contract_UpdateReceiptSummary 的规则呈现为部分收款或未收款”。
第六阶段,修正了语义查询中的组合错误。一个典型问题是:“当前哪些合同既没有开票,也没有收款”。最初系统返回空结果,而实际 HT2026040005 应该命中。排查后发现,合同级语义里把“未开票”解释成“合同下没有发票”,又把“未收款”解释成“合同下存在未收款发票”,两者组合后 SQL 自相矛盾。后续增加了专门的组合状态 not_invoiced_unreceived,用于表示“合同下没有任何发票记录,因此自然也没有收款”,从而使这类查询回归正确。这一轮优化说明,本体语义不能只靠关键词拼装,必须考虑业务对象层级和组合语义。
第七阶段,继续向“多轮上下文 Copilot”演进。用户的真实使用方式并不是每句都带全编号,而是经常先问“查看合同 HT2026040002 详情”,然后再追问“它的销售部门和合同总金额是什么”“为什么它还是未收款”。为此,系统增加了会话级上下文能力:一方面把最近几轮会话历史送入大模型,另一方面在本地兜底层做“这个合同、它、上一条、第一张”这类代词消解,把问题自动改写为带具体编号的语义查询或解释请求。经过这轮改进,多轮连续追问已经可以稳定工作。
总体来看,这一系列优化的核心路径非常明确:从“系统可运行”逐步进化到“AI 能查数”,再进化到“AI 能理解本体模型和业务语义”,最后走向“AI 能在多轮上下文中像领域 Copilot 一样解释、追问和分析”。当前版本已经不再只是一个集成了大模型的 CRUD 系统,而是在朝着“本体语义驱动的业务智能助手”方向持续逼近。
本文档版本 1.0 |
基于合同管理 AI 原生应用技术架构设计文档 |
2026 年 4 月
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号