本体模型+AI 大模型驱动的 AI 原生应用构建-真实可运行的系统

本体模型+AI 大模型驱动的 AI 原生应用构建-真实可运行的系统

人月聊IT
发布于 2026-04-13 12:52:23
发布于 2026-04-13 12:52:23
大家好,我是人月聊IT。
今天继续分享对应本体+AI大模型驱动的AI原生应用构建。实际在前面两者我已经分享过一次V1.0版本的迭代。基于我一个老版本的Markdown格式的本体模型文件,构建了可运行的合同管理系统。
由于原来核心是基于我已有的本体模型文件,包括前期已经输出的Skills技能包内容,动态去构建上层混合UI界面交互。而AI大模型在里面起到一个核心的作用就是充分理解我业务语义,去实现基于问题需求的,对底层Skills包技能的动态组装和编排过程。
对于 UI 这一部分,它是一个混合 UI 既有自然语言对话的 UI 又有结构化的 UI 界面,那么对于结构化的 UI 界面,它其实就是提前生成出来的 UI 界面。
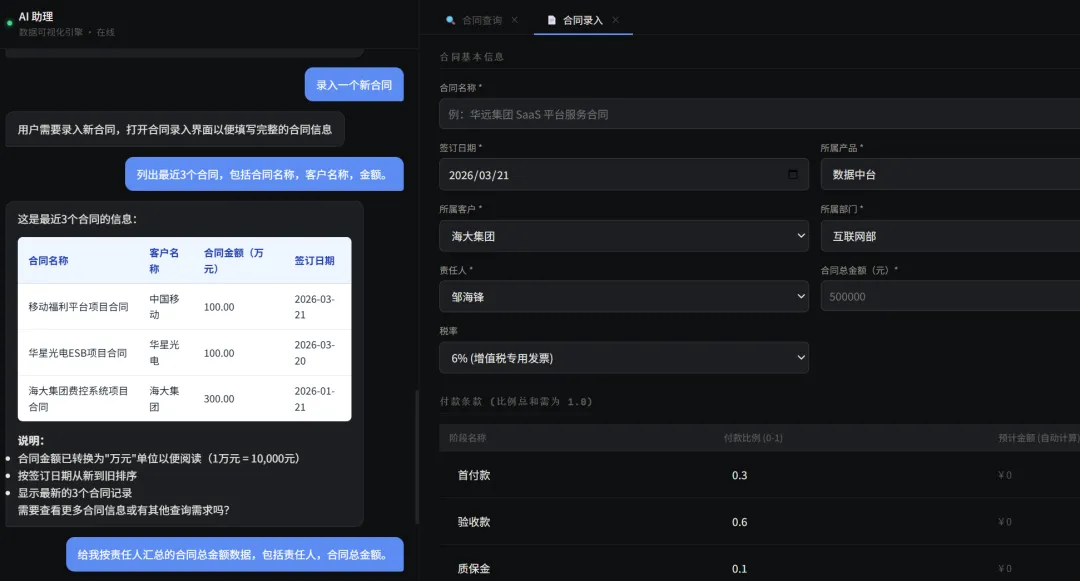
图片
在假期这两天我没有再用原来的本体模型markdown文档。而是用最新的本体模型建模规范M1-M7+ME事件的详细建模文档。采用AI静默编程的方式花了差不多1.5个小时,一次全部成功的跑出整个完整可运行系统。
今天这篇文章重点不是分享这个可运行系统。而是再讲讲我讲整个本体建模+AI大模型驱动,构建AI原生应用实现POC完整闭环的过程。
构建精确化的本体模型
在这里首先还是需要尽量构建拥有精确化语义的本体模型。所以这里首先还是做了一个关键步骤,即首先细化用户原始需求。也就是将用户需求提供给AI后,让AI提出有歧义,不准确,需补充说明的10个关键问题,然后我逐一作答。在迭代2轮我基本得到比较准确的需求文档。
接着就是基于需求文档+本体模型建模规范V2.0版本,让AI大模型输出完整的从M1到M7的本体模型Yaml文件,包括我新补充的ME事件模型。
注意在本体模型输出后,这里有一个关键的步骤。就是继续让AI大模型对需求文档和本体模型进行一致性检查和语义对齐。如果存在不一致的地方自动修正,如果存在分歧的地方反馈给我进一步补充需求说明。
经过第二次对齐后,我们基本就拿到一个比较完整的本体模型文件。
构建UI模型规范文件和合同管理UI模型
大家注意,基于我前面的思路。实际我不希望单独再构建一个合同管理的UI模型。而是仅仅提供UI模型规范文件。
首先我是通过大模型帮我构建了一套UI界面交互原型。这套原型顶部是标题栏位,固定。中部分为左,中,右三个部分。左边菜单栏和右边栏位都可以隐藏。左边默认200px左右,右边默认400px,中间功能区自动扩充占满,中间功能区支持多Tab标签展示。左边修改为一个树状的目录结构,仍然白色底色,节点需要有ico美化。可以逐层展开,即一个树功能菜单,叶子节点菜单可以打开功能。比如点供应商维护,进入供应商维护功能中间是功能区,支持多Tab,功能区里面的功能界面参考demo。 右边是一个完整的AI对话区。类似当前主流AI编程工具的AI对话区,可以进行AI对话,系统自动返回文字,表格,图表等各种信息。当然AI对话也可以打开功能区功能。
基于上面提示AI帮我输出了完整的可交互的界面原型。然后继续用AI逆向的思路,结合需求+Demo原型,让AI逆向输出一个UI建模标准规范的Yaml文件。
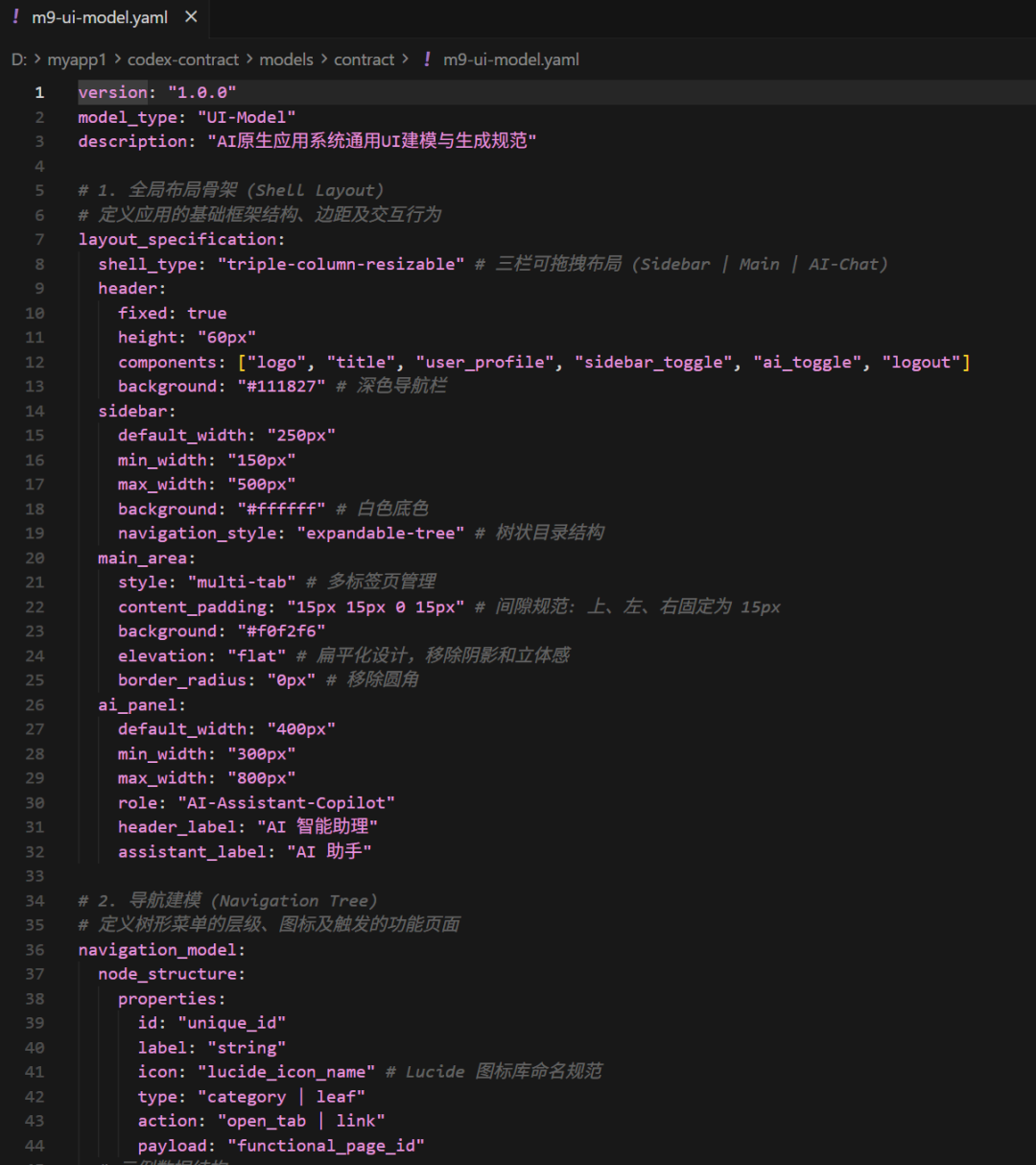
也就是说在这里我已经详细定义了AI大模型后续在生成应用的时候基于什么样的UI框架,界面样式风格。
构建技术架构规范
在给出了完整的UI建模规范标准。但是我们在正式让AI通过静默编程方式输出完整系统还缺少一个关键的技术架构设计。这个技术架构设计需要定义整个技术框架,技术组件,编程语言和前后端框架,核心算法,安全,AI对话交互实现机制等关键内容。
技术架构规划要给出具体的编程语言,数据库,前后端开发框架,技术组件使用,接口设计标准,安全,易用性,整体UI层和底层AI大模型的交互机制,核心算法等,这些都需要明确给出。
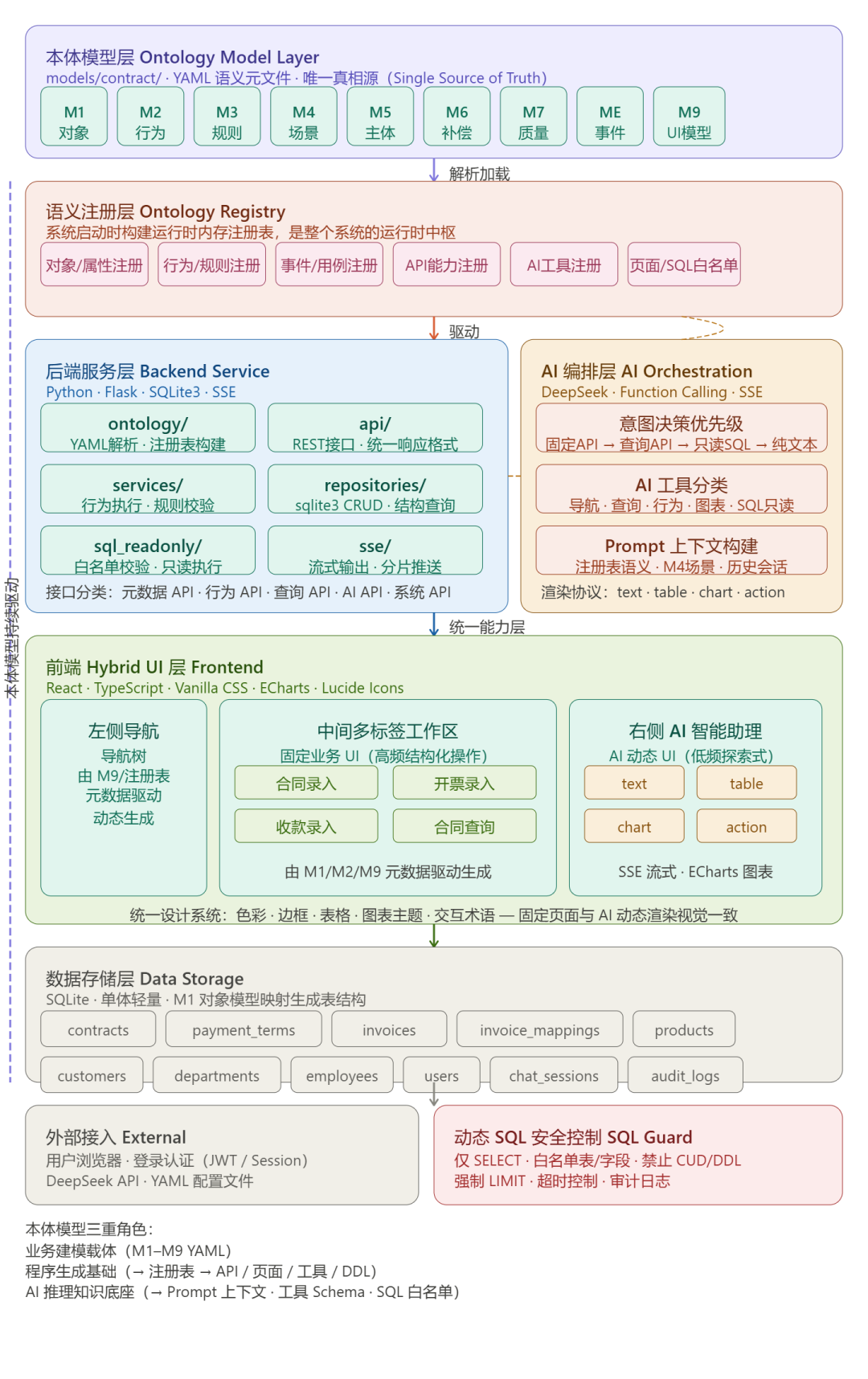
整个系统采用单体应用、分层解耦的方式实现,共六个层次,自上而下依次为:本体模型层、语义注册层、后端服务层、AI 编排层、前端 Hybrid UI 层、数据存储层。
本体模型层是整张图的顶端起点,M1–M9 九个 YAML 元文件并排展示,强调它们是整个系统的"唯一真相源"。左侧的紫色竖虚线贯穿所有层,标注"本体模型持续驱动",视觉上强调了本体模型不只是建模工具,而是运行时的持续驱动力。
语义注册层紧接其下,六类注册内容(对象属性、行为规则、事件用例、API 能力、AI 工具、页面/SQL 白名单)并列排布,体现了注册表作为"运行时中枢"统一供给所有下层模块的核心地位。
后端服务层与 AI 编排层并排放置,两者之间有虚线连接,体现"固定 UI 和 AI 对话共用同一后端能力层"的核心原则。AI 编排层内部的意图决策优先级(固定 API → 查询 API → 只读 SQL → 纯文本)直观呈现了你文档第 9.5 节的决策顺序。
前端 Hybrid UI 层用三栏结构(左导航 + 中工作区 + 右 AI 助理)准确还原了你的三栏工作台形态,固定业务 UI 的四个页面和 AI 动态 UI 的四种渲染类型(text/table/chart/action)分别用不同颜色区分,底部强调统一设计系统。
数据存储层列出了全部 12 张建议表,并标注"由 M1 对象模型映射生成"。底部的动态 SQL 安全控制模块用红色单独标注,突出其安全边界的重要性。
各层职责边界清晰,相邻层之间通过明确定义的接口交互,非相邻层不直接访问。本体模型层作为源头,通过语义注册层向下游三个执行层(后端、AI 编排、前端)持续提供语义驱动力。
AI静默编程输出整个系统
大家注意,按照标准的SDD规约确定的开发。实际我还需要输出详细的功能架构设计文档,接口设计文档,并在人工确认后。让AI输出独立的开发计划,然后一个个任务计划去执行。
在新的本体建模思路下,我前面就已经讲到了本体模型既承担了需求文档的作用,也承担了设计文档的作用。再去输出其它设计类文档,开发任务计划完全是多余。只要AI大模型的上下文管理和上下文记忆压缩能力足够强,AI完全可以朝长时间执行任务。实际前面这个本体模型输出完整可运行程序,AI花了差不多2个小时时间,中间我没有做任何干预全部输出。而且一次性成功率相当高。
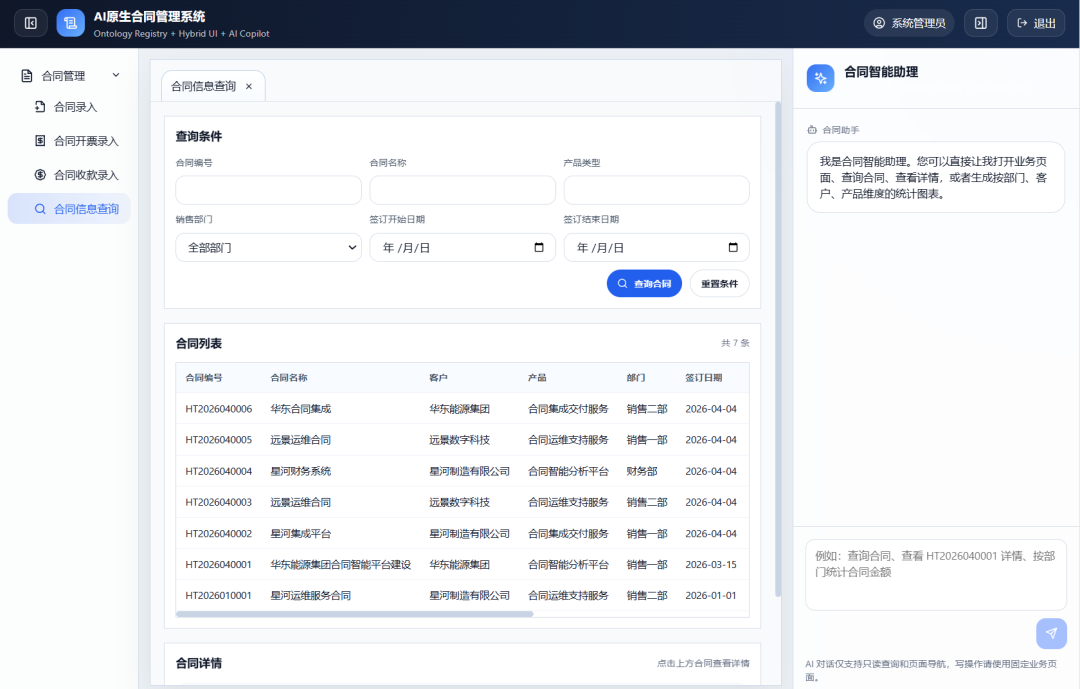
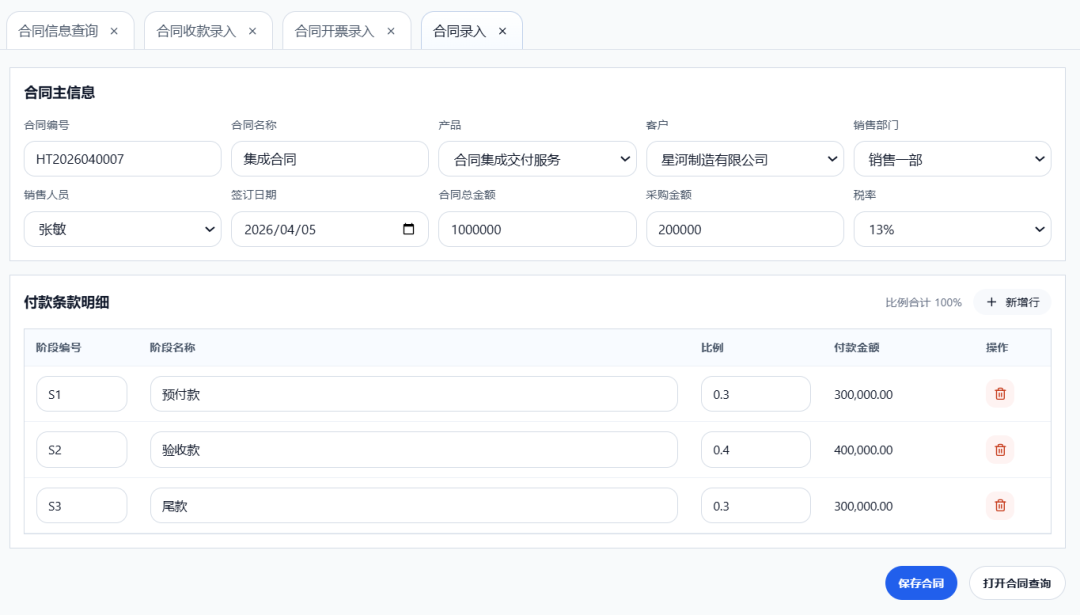
完整的合同信息录入界面:
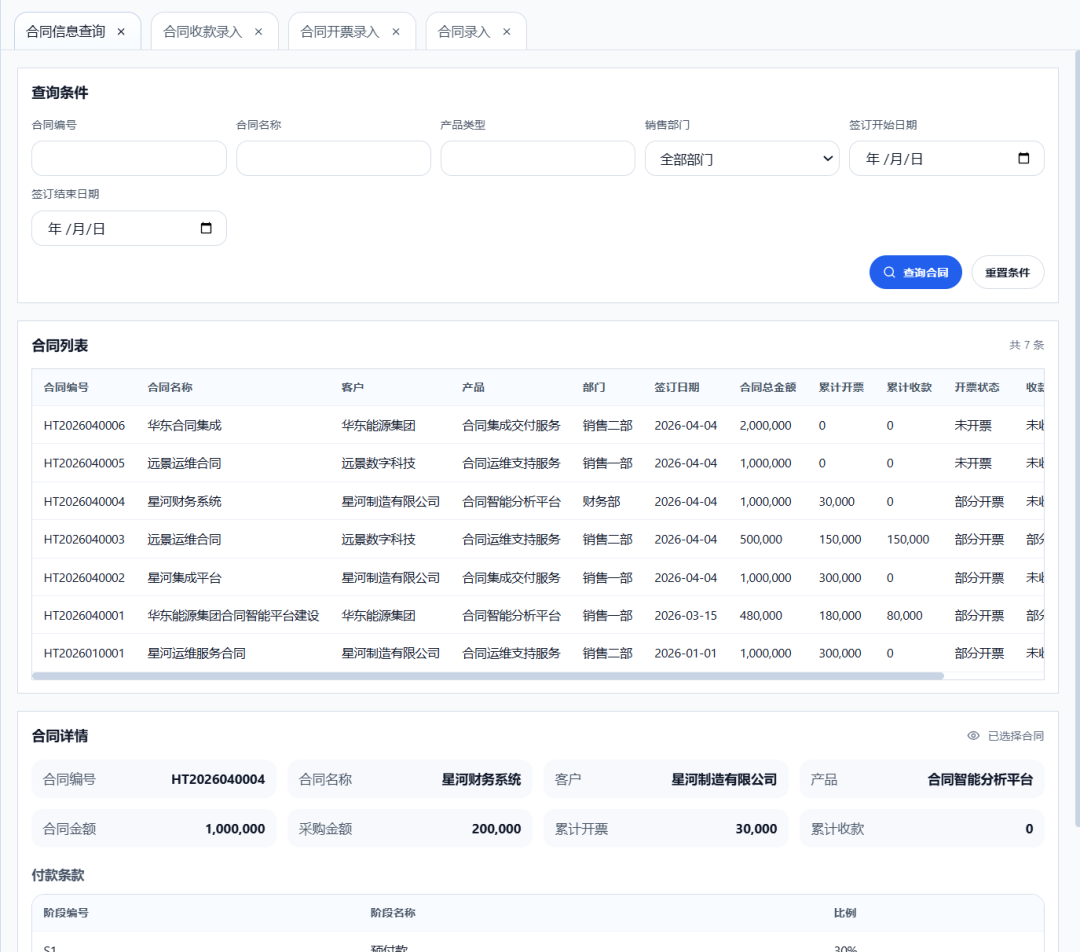
合同信息模糊查询界面:
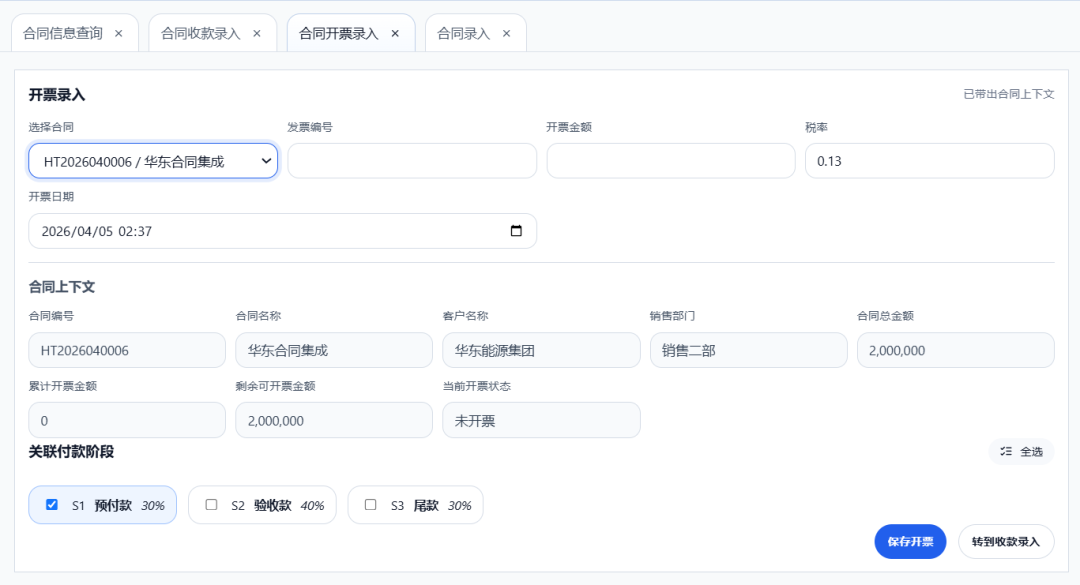
合同开票信息界面
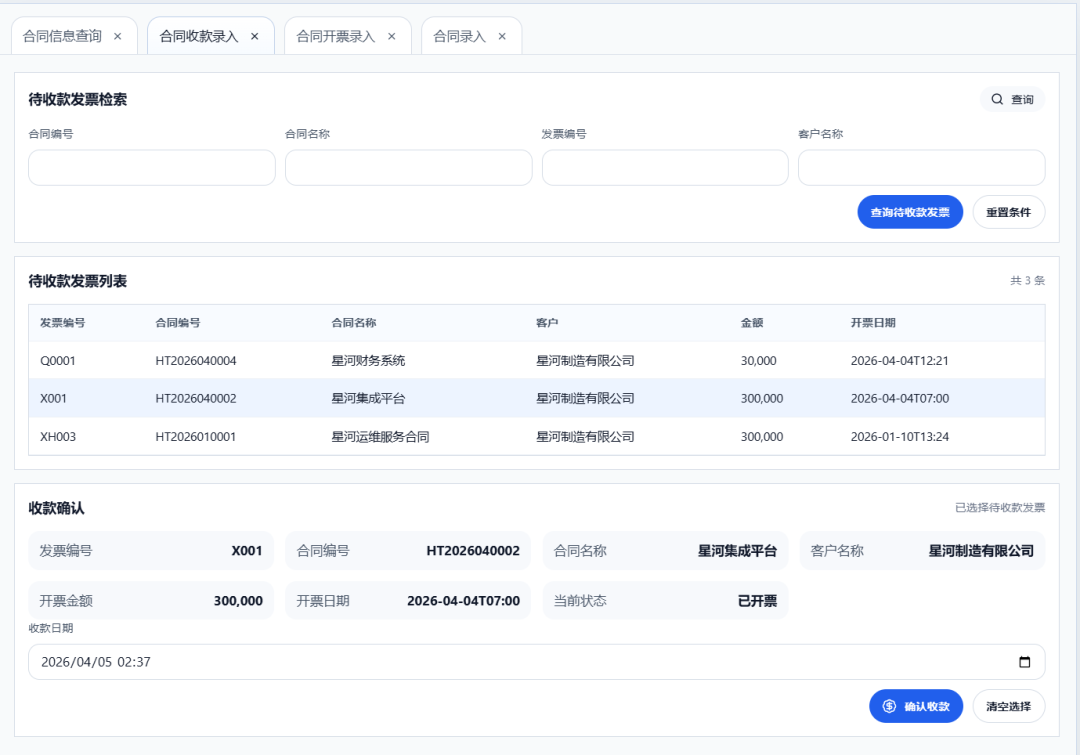
合同收款信息录入界面
AI对话框的自然语义对话
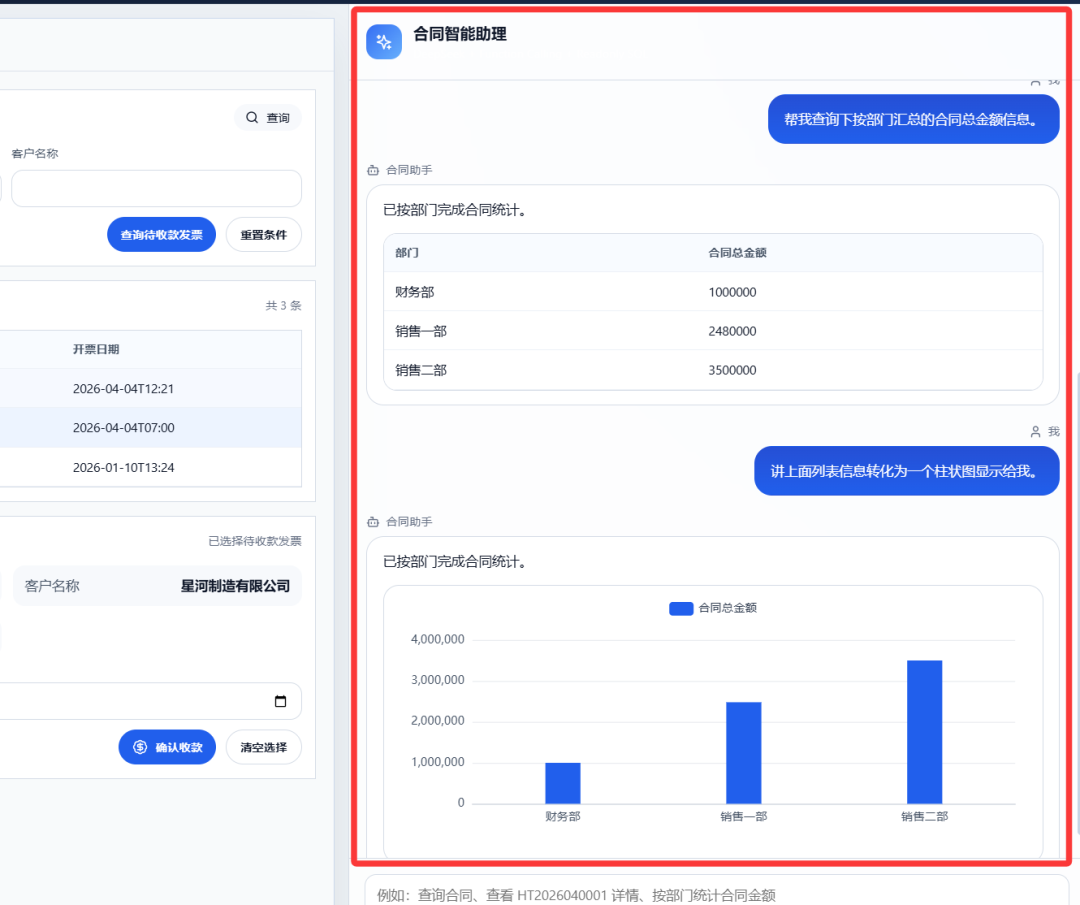
可运行系统我做了哪些优化调整
前面已经谈到AI大模型基于本体模型+UI规范+技术架构已经完整的可以输出整个完整的合同管理应用。但是实际我做了如下优化。
其一就是AI输出的界面布局风格,实际和我给出的Demo有比较大的差距。类似主从表录入采用了左右布局,而我Demo里面是上下布局。再次检查了UI规定的Yaml文件,发现在Yaml文件里面没有对录入界面详细布局,查询界面详细布局给出详细定义。也就是AI输出界面更多参考的是我Yaml规范文件,而不是我目录下的Demo原型。那么接着要做的就是对UI建模规范文件进行精细化处理。这个本身仅仅是优化问题,不影响我整个AI应用生成的功能本质。
其二就是AI大模型对话语义理解上面。实际上对于一些自然语义对话AI没有真正理解。类似我让AI帮我输出合同创建流程,发票录入规则等,实际AI无法给我返回我本体模型里面清晰定义的业务语义,而是告诉我没有系统操作功能。包括我自然语义查数的时候,类似一些开票未收款等复合语义AI理解出现偏差。(当前这里不排除是大模型本身能力有欠缺)。这个问题本身也是经过我多次优化和迭代最终基本解决。
所以实际上我后续在调整AI智能对话和语义层能力上做了大量的迭代。我们来看下整个AI大模型处理我输入对话的完整逻辑:
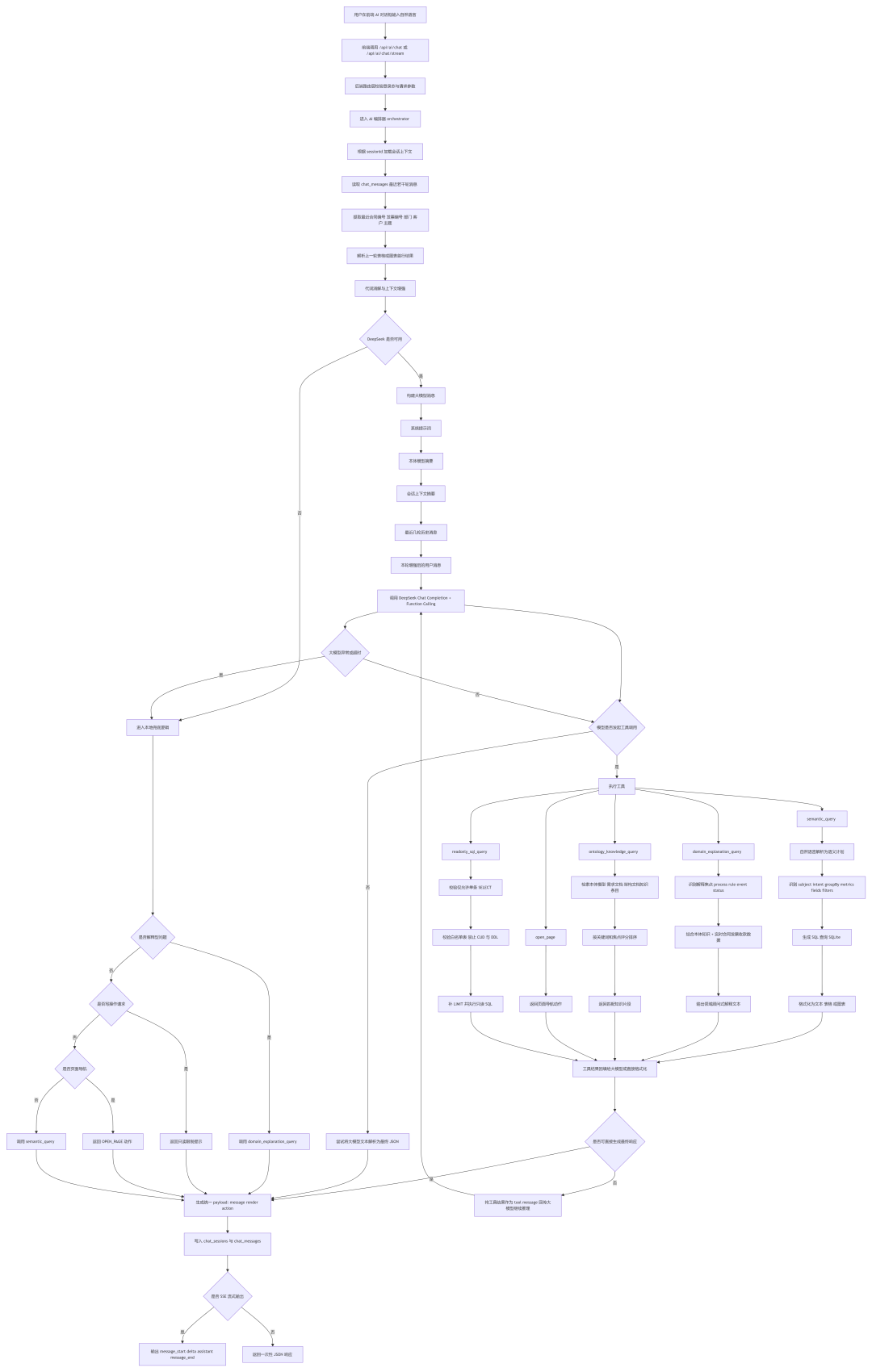
当前系统中的 AI 对话,不是一个孤立的聊天能力,而是建立在“前端会话入口 + 后端编排器 + 本体运行时注册表 + 领域工具能力 + 多轮上下文记忆”之上的完整处理链。用户在界面中输入自然语言后,请求首先从前端聊天组件发起,调用后端 `/api/ai/chat` 或 `/api/ai/chat/stream` 接口。请求中除了消息正文,还会携带 `sessionId`,用于标识是否属于同一轮连续对话。后端接口先做登录态校验,确认当前用户已登录,再进入统一的 AI 编排入口。
进入编排入口后,系统不会立即把用户原话直接发送给大模型,而是先加载当前会话上下文。上下文服务会从 `chat_messages` 表中读取最近若干轮历史消息,提取最近关注的合同编号、发票编号、部门、客户、最近主题对象以及最近问题类型。同时,它还会解析上一轮助手输出的表格或图表结果,识别首行中是否已经出现合同编号、发票编号等关键实体。如果用户本轮使用了“它”“这个合同”“上一条”“第一张”之类代词或承接性表述,本地上下文服务会先把这些表述改写为包含显式业务对象的增强请求。这一步的作用,是保证多轮会话里代词和省略信息能够被稳定续接。
接下来,系统进入“大模型优先”的主编排流程。如果 DeepSeek API 已配置可用,后端会构建一组完整消息发送给大模型,其中包括:系统级提示词、从本体模型抽取出的领域摘要、当前会话上下文摘要、最近几轮对话历史,以及本轮经过上下文增强后的用户请求。系统提示词里已经明确写入了合同管理领域的关键语义,例如合同、发票、收款之间的关系,已开票未收款、未开票等业务含义,以及 AI 必须优先调用哪些工具来完成不同类型的问题。
在大模型真正处理问题时,并不是自由回答,而是采用 function calling 模式。后端会向大模型暴露一组可调用工具:`semantic_query` 用于处理合同、发票、收款的结构化语义查询;`domain_explanation_query` 用于处理流程、规则、事件链路、状态原因等领域 Copilot 解释问题;`ontology_knowledge_query` 用于从本体模型、需求文档、架构文档中检索原始知识片段;`open_page` 用于页面导航;`readonly_sql_query` 作为最终兜底,仅允许只读 SQL 查询。大模型会根据用户问题的类型,决定调用哪一个工具。
如果问题属于典型业务查询,例如“按部门统计合同总金额”“查询已开票未收款合同”“查看某合同详情”,通常会调用 `semantic_query`。该工具内部会把自然语言进一步解析为结构化语义计划,识别对象主体是合同、发票还是收款,识别用户意图是列表、统计、详情还是数量,并提取分组维度、指标、字段、过滤条件以及最终结果应以文本、表格还是图表呈现。之后系统据此生成 SQL 查询 SQLite 数据库,并将结果组织成统一结构,再根据用户请求决定返回自然语言、表格或 ECharts 图表。
如果问题属于解释型问答,例如“合同创建流程是什么”“合同创建有哪些规则”“为什么这个合同还是未收款”,通常会调用 `domain_explanation_query`。这一工具既会利用本体模型中的行为、规则、用例、事件,也会结合真实数据库中的合同、发票、收款状态进行解释。也就是说,它不是单纯地把本体文档片段返回给用户,而是会先判断当前问题更像是在问流程、规则、事件链,还是在问某个合同或发票的当前状态原因,然后用更像领域顾问的方式组织回答。
如果大模型不可用,或者大模型调用中途异常,系统会回退到本地兜底处理模式。兜底模式同样会先利用多轮上下文增强用户请求,然后再做本地分流:流程、规则、状态原因类问题优先走 `domain_explanation_query`;页面跳转类问题走 `open_page`;普通查询类问题走 `semantic_query`;写操作请求则直接拒绝,并明确提示当前 AI 对话只支持只读查询和页面导航。只有当现成语义能力确实不能覆盖问题时,系统才允许调用严格受限的 `readonly_sql_query`。该工具会强制校验 SQL 必须是单条 `SELECT`,禁止任何 `INSERT/UPDATE/DELETE/DDL`,并校验访问表是否在白名单内,必要时自动补 `LIMIT`,最终再执行只读查询。
当某个工具返回结果后,编排器会对结果做统一归一化处理。如果是字段较少的单对象结果,优先转成自然语言句子;如果是多行多列统计,则转成表格;如果用户明确要求图表,或者语义计划里已经标记 `responsePreference=chart`,则转为 ECharts 渲染数据。之后系统将最终 `message / render / action` 三段式结构返回给前端。前端只负责渲染最终结果,不展示内部工具名、SQL、语义计划或参数细节。
最后,系统会把本轮用户消息和 AI 回复一并写入聊天会话表,为后续多轮上下文承接提供基础。也正因为有这一步,用户才能先问一个查询问题,再接着用“它”“上面的内容”“刚才那个结果”继续追问,系统仍然能够理解上下文并给出连续、自然的回答。
以上就本体模型+AI 大模型驱动的 AI 原生应用构建-真实可运行的系统的第二轮完整迭代全部完成。后续将开始第三轮新的迭代和思考,所以如果大家看我本体论的文章,包括本体模型驱动的AI原生应用设计文章,最好是按时间先后顺序阅读,方便理解我整个思考的过程。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号