开源模型新标杆:谷歌 Gemma 4 核心技术架构与多场景能力分析

开源模型新标杆:谷歌 Gemma 4 核心技术架构与多场景能力分析

Henry Zhang
发布于 2026-04-13 16:45:48
发布于 2026-04-13 16:45:48

题图摄于北京元大都公园海棠花溪
上周,Google DeepMind 发布新一代开源模型系列 Gemma 4。如同将一座超级计算机的核心技术浓缩进一枚芯片,Gemma 4 基于 Gemini 3 的研究成果构建,却以完全开源的形式交付给全球开发者。与闭源的 Gemini 系列不同,Gemma 4 采用 Apache 2.0 许可证,赋予开发者自由的商业使用权利和数字主权。
另一个重要的看点在于,这个强大的模型虽然体积非常小,能顺利部署在低端设备上,从而极大地丰富这些设备上的 AI 应用,真正打开想象空间,前景不可限量。
Gemma 4发布的官方视频(中文字幕由龙虾翻译生成)
本文对 Gemma 4 进行多方面的技术分析,涵盖其架构创新、核心能力、应用方法及行业对比。
基础信息与技术架构
发布背景与版本定位
Gemma 4 的发布极具战略意义。Gemini 是谷歌的闭源商业模型,通过订阅制 API 提供服务;而 Gemma 则是完全开源、支持本地部署的“技术公器”。这种双轨策略使谷歌既能通过 Gemini 获取商业价值,又能通过 Gemma 扩大技术影响力并构建开发者生态。
可以说,Gemma 是谷歌将其最先进的 Gemini 模型技术,以开源、轻量、可商用的形式重新打包,送给全球开发者的“礼物”。
模型变体与技术规格
Gemma 4 包含四个模型变体,覆盖从边缘设备到数据中心的全场景需求:
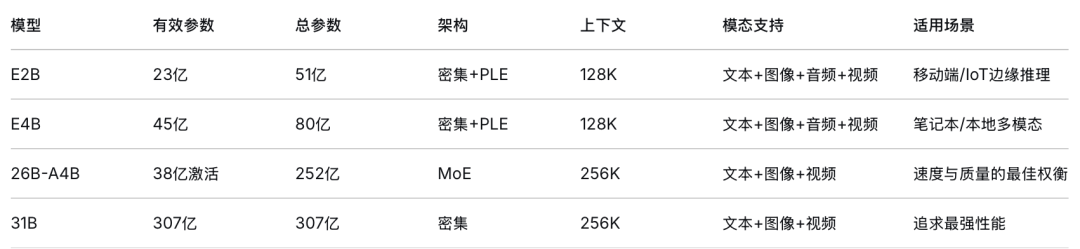
在 AI Arena 排行榜上,Gemma 4 31B 在所有开源模型中排名第 3,性能可与10 倍规模的模型相媲美。
核心技术能力分析
代码生成能力
代码生成是 Gemma 4 进步最大的方向。LiveCodeBench v6得分从29.1%跃升至80.0%,Codeforces ELO评分从110提升至2150,增长近20倍。HumanEval得分82.3,为开源模型最高。Gemma 4支持 Python、Java、C++ 等多种语言,并具备语言间翻译能力。更重要的是,它支持高质量的离线代码生成,用户数据无需上传云端,所有推理在本地完成。
工具使用能力
Gemma 4原生支持智能体工作流和函数调用。它可以自主生成结构化的工具调用请求,支持系统提示角色和原生 JSON 输出。开发者可以构建能够处理复杂任务的智能体,这些智能体能够根据环境反馈调整策略,如同一个能够自己决定何时使用计算器、何时查阅资料的研究助理。
多模态处理能力
全系模型支持文本、图像和视频(最长60秒,1fps),E2B 和 E4B 额外支持音频输入(最长30秒)。Gemma 4具备目标检测、边界框输出、GUI 元素检测、文档/PDF解析、图表理解、屏幕/UI界面理解等能力。在 OmniDocBench 测试中,31B 模型的编辑距离仅为 0.131,展现了卓越的 OCR 和图表理解能力。
手机和本地执行能力
Gemma 4 在移动端实现了重大突破。计算速度比前代快 4 倍,功耗降低60%。主流安卓旗舰可流畅运行 E4B,连续对话 25 次耗电小于 1%。E2B 模型在树莓派5上,2-bit 量化后内存占用小于 1.5GB,预填充速度 133 tokens/秒,解码速度 7.6 tokens /秒。这为边缘 AI 应用开辟了全新可能性。
资源消耗与硬件要求
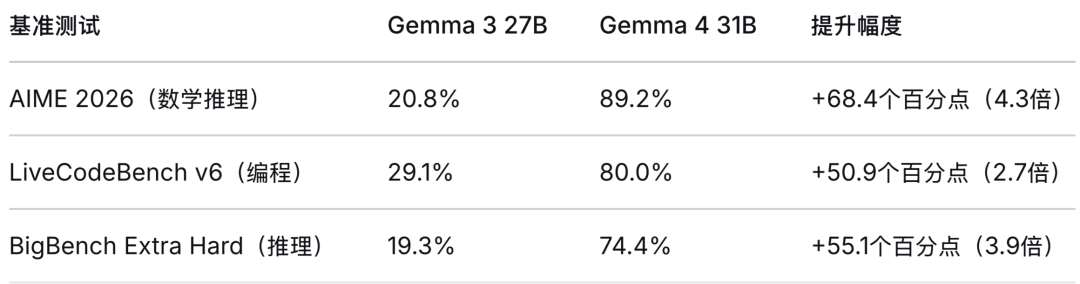
Gemma 4 的核心竞争优势可概括为:性能效率比领先(31B 模型接近 10 倍参数规模的性能)、开源策略优势( Apache 2.0 许可证,无使用限制)、技术特性优势(最长上下文窗口、原生多模态、原生工具调用)、生态系统优势(与Android、Google Workspace 等深度集成)。
使用方法与实践指南
本地部署指南
根据模型变体准备硬件资源后,可选择以下部署工具:
- Ollama:一条命令完成下载和运行,适合快速体验。
- vLLM:高吞吐生产环境部署,支持PagedAttention和连续批处理。
- Llama.cpp:CPU推理优化,支持ARM架构和移动端。

MacOS M4 芯片上用 Ollama 一键运行 Gemma 4
性能优化建议:使用量化版本减少内存占用;根据硬件选择合适的模型变体;启用GPU加速;调整批大小和序列长度。
移动端集成方案
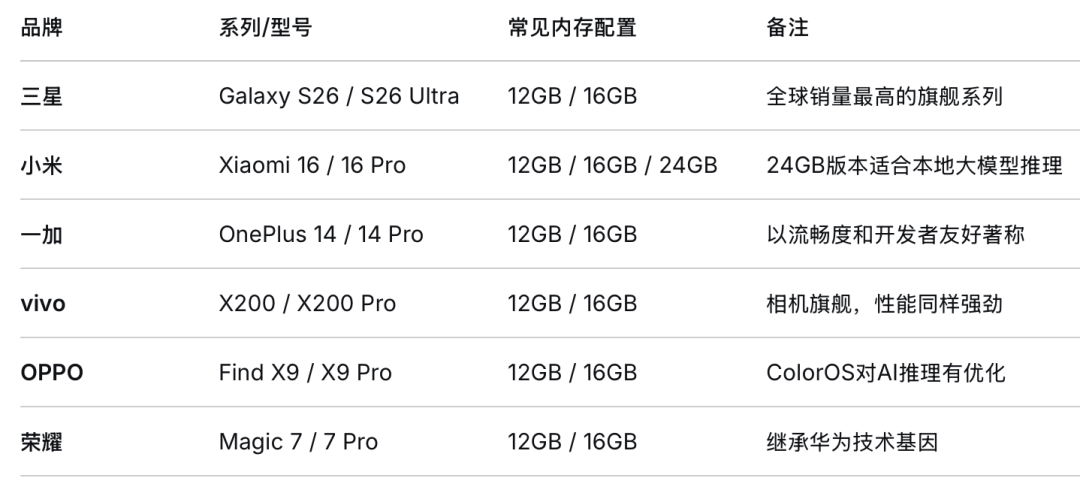
Android集成:通过ML Kit GenAI 提示API或直接集成 TensorFlow Lite,利用 Android NNAPI 进行硬件加速。中档或者旗舰级别的安卓手机基本可以跑起 E4B 模型( 8GB 以上内存),部分顶配版甚至可尝试 26B-A4B 模型:
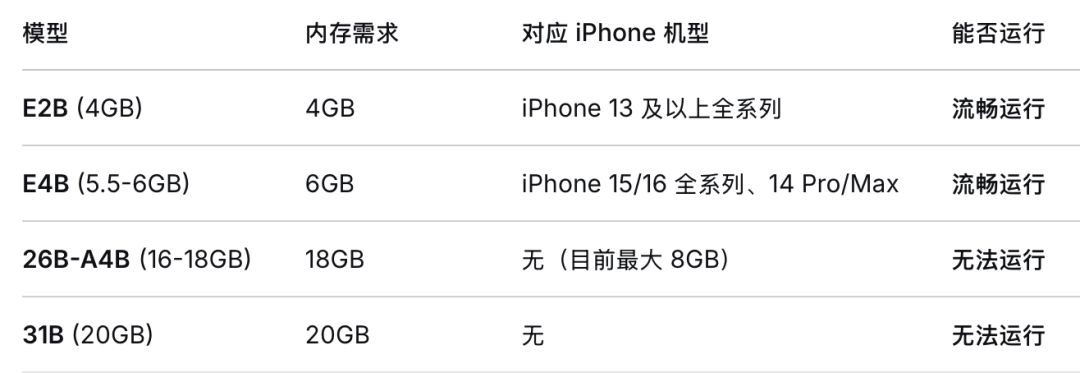
iOS集成:使用Core ML进行模型转换和部署,利用 Metal Performance Shaders 进行 GPU 加速,支持 Vision 框架进行视觉处理。部分 iPhone 机型只需要 4GB 即可跑 Gemma 4。iPad 使用的是 M 芯片,较新的机型可以跑通 E4B 甚至 26B-A4B。
开发最佳实践
模型选择上,根据任务需求选择合适的变体,优先使用量化版本,考虑使用MoE 变体以获得最佳效率。性能优化方面,使用GPU加速推理,优化批大小和序列长度,启用缓存机制。安全方面,注意模型的输出可能包含有害内容,实施适当的内容过滤,保护敏感数据。
总结与展望
核心发现
Gemma 4 代表了开源 AI 模型的重大技术突破。六项核心架构创新共同推动了性能的飞跃式提升,特别是在数学推理(4.3倍)、编程能力(2.7倍)和复杂推理(3.9倍)方面。Apache 2.0 许可证为开发者提供了前所未有的自由度。与谷歌产品生态系统的深度集成,为开发者提供了完整的技术栈。
应用前景
Gemma 4在软件开发与代码生成、智能体与自动化、多模态内容理解、边缘计算与物联网、移动应用开发等领域展现出广阔前景。其本地部署能力特别适合企业级开发场景,确保代码隐私和数据安全。
发展趋势
Gemma 4的发布将推动AI应用成本大幅降低,使更多中小企业享受AI红利;开放的模型和代码将促进技术创新;围绕 Gemma 4 的生态系统将日益繁荣;本地部署能力将推动AI应用更加注重隐私保护;开源模型的发展将推动AI技术的民主化。

Gemma 4 的发布标志着开源AI进入了一个新时代。它不仅是强大的技术工具,更是推动AI技术普及和创新的重要力量。对于研究、开发及应用领域的专业人士而言,深入理解和掌握 Gemma 4,将成为在 AI 时代保持竞争力的关键。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区留言讨论交流。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-05,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号