谷歌刚开源的 Gemma 4 大模型,不用联网、不要钱,手机就能跑!再无 Token 焦虑

谷歌刚开源的 Gemma 4 大模型,不用联网、不要钱,手机就能跑!再无 Token 焦虑

Henry Zhang
发布于 2026-04-13 16:47:35
发布于 2026-04-13 16:47:35

题图摄于北京国家体育中心
谷歌 DeepMind 于 4 月正式开源了 Gemma 4 系列模型。它不需要云端,不需要订阅,从此再无 token 焦虑 —— 只需要你的电脑或者手机,以及这篇一手测试文章。
为什么要在本地运行大模型?
在讨论"怎么做"之前,先花一分钟想清楚"为什么要做"。
用云端 AI 就像点外卖:你把数据交给服务商,等模型处理完再送回来。方便,但你的隐私有没有被窥探、被转卖,你无从知晓。本地运行大模型,则像家里雇了一位私厨——只为你一人服务,你的对话、文件、想法,从不离开这扇门。
这不仅意味着安全,更意味着你可以毫无顾虑地让 AI 帮你分析私人日记中的情绪状态,或是处理包含敏感数字的个人财务报表,而不用担心数据被上传至云端进行模型训练 。
这便是本地模型的核心价值:数据主权。当然,除此之外还有另一个非常实际的好处:永久免费,无论你问了多少个问题,调用了多少次,账单始终是零,再也没有 token 焦虑。
过去,许多用户出于隐私保护的考虑,希望私有化部署大模型服务,但高昂的硬件成本令人望而却步。这正是 Gemma 4 值得关注的原因:它既能保护数据隐私、无需 token 费用,而且硬件门槛不高。
我分别在 MacBook Air M4 16GB、iOS 和安卓手机上进行了测试,本文将分享这些设备上的实际表现。
Gemma 4 是什么?先认识这个家族
之前文章已经介绍过 Gemma 4,这里说些要点。
Gemma 4 是 Google DeepMind 在4 月 2 日发布的开源模型系列,基于与 Gemini 3 相同的底层技术,采用 Apache 2.0 许可证,允许商业使用和自由部署。
这个大模型家族共有四位成员,从轻到重分别是:
- E2B(有效参数 2B):家族中的轻骑兵。支持文本、图像与音频,128K 超长上下文,量化后仅需约 3.2GB 内存。手机、入门级电脑皆可胜任。
- E4B(有效参数 4B):综合能力最均衡的选择。量化后约需 5GB 内存,是大多数用户的首选。同样支持文本、图像与音频三模态输入。
- 26B MoE(混合专家架构):这是一个"外表庞大、内在灵活"的模型。总参数 26B,但推理时只激活约 3.8B,256K 超长上下文,速度与质量兼顾。
- 31B Dense(全密集架构):家族中的重装步兵,31B 参数全部参与推理,目前在主流开源模型排行榜位居前列。但它对硬件要求极高,16GB 内存无缘运行。但对于 32G 或 64G 的设备,这个版本是挑战 Llama 3 级别的存在。
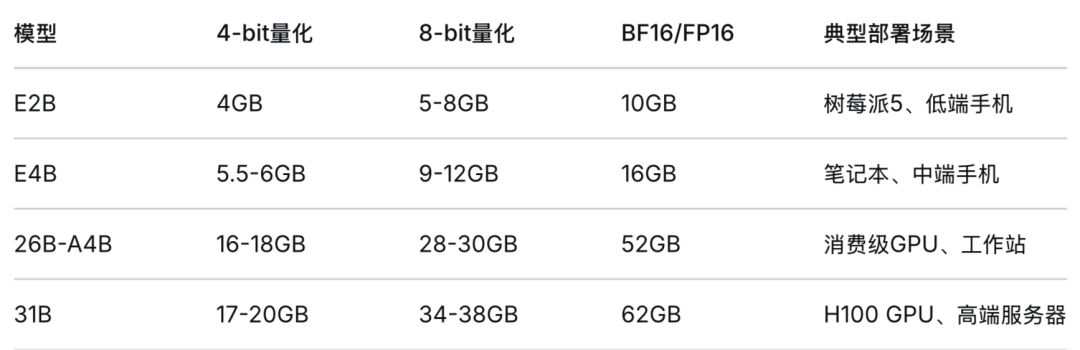
选型原则:16GB 内存的设备,运行 E2B 或 E4B 绰绰有余;26B 版本勉强能跑但会有内存压力;31B 版本不要尝试。
量化:让大象住进小房间的艺术
大模型的原始权重文件动辄数十 GB,这显然不是普通电脑能够承载的。解决这个问题的技术叫做量化(Quantization)——它本质是一种有损压缩。
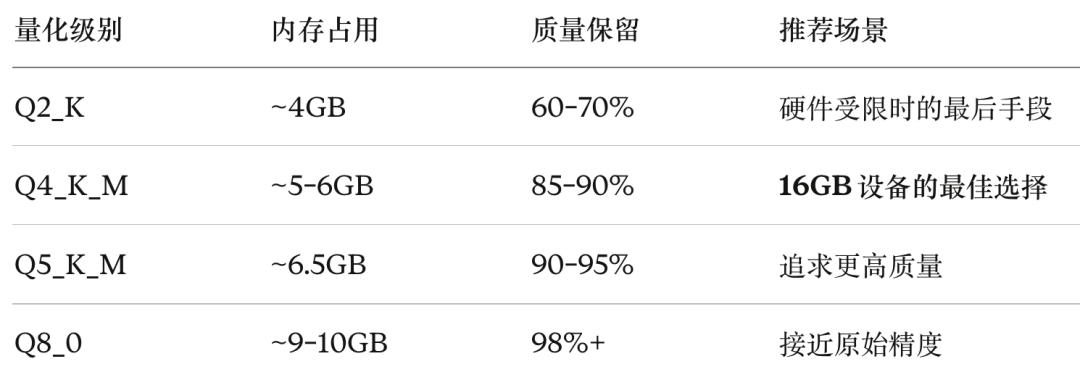
类比来理解:如果原始模型是一幅 8K 分辨率的油画,量化就是把它缩小成不同尺寸的印刷品。Q8_0 相当于 4K 打印,肉眼几乎看不出区别;Q4_K_M 相当于 1080P,细节略有损失但整体观感良好;Q2_K 相当于 480P,凑合能看,但已经开始模糊。
对于 16GB 内存的设备,Gemma 4 各量化级别的资源占用大致如下:
为什么 Mac 天生适合跑本地模型?
传统的 PC 架构中,CPU 和 GPU 使用独立的内存空间。模型在推理时,数据需要在两块内存之间来回复制,这个过程消耗时间,也浪费带宽。
M4 芯片采用统一内存架构(Unified Memory),CPU、GPU、神经网络引擎和矩阵加速器共享同一块物理内存。这就好比一支乐队,所有人共用同一份乐谱,而不是各自拿着一份副本对比再演奏——沟通成本几乎为零。
具体来说:M4 芯片集成 16 核神经网络引擎,每秒可执行 38 万亿次操作,内存带宽达 120GB/s。这些数字意味着,同样的模型在 M4 上的推理速度,会显著优于同等内存配置的传统笔记本。
用 Ollama 运行 Gemma 4
Ollama 是目前最简洁的本地模型管理工具,你不需要了解任何深度学习框架,不需要配置 Python 环境,不需要手动下载模型文件。熟悉容器的朋友,会发现Ollama管理模型和Docker管理容器镜像的机制很相近。上手几乎没有什么困难。
第一步:安装 Ollama
打开 Mac 的终端(Terminal),粘贴以下命令并回车:
brew install --cask ollama-app如果你没有安装 Homebrew,也可以使用官方脚本:
curl -fsSL https://ollama.com/install.sh | sh安装完成后,启动 Ollama 服务(相当于Docker Daemon):
ollama serve这一步相当于打开了你家的私厨厨房,接下来可以开始点餐了。
第二步:下载并运行 Gemma 4
只需一条命令:
ollama run gemma4:e4bOllama 会自动下载 E4B 版本的 Q4_K_M 量化模型(约 3GB),下载完成后直接进入对话界面。支持断点续传,网络中断后重新执行同一命令即可继续。
如果你的设备内存较小,或者只想体验轻量版:
ollama run gemma4:e2b第三步:验证运行状态
在另一个终端窗口输入:
ollama ps将看到类似这样的输出:

其中 “14%/86% CPU/GPU” 表示模型正在 CPU 与 GPU 之间协同计算:这是 M4 统一内存架构的优势直接体现。
至此,你已经拥有了一个完全本地运行的 Gemma 4 实例。所有对话均在你的设备上完成,零数据外传。
Gemma 4 在 Mac M4 16GB上的表现
首先测试了 E4B 模型,消耗约 10GB 内存,推理速度不算快,系统有一定卡顿感。换成 E2B 模型后,内存占用降至 7GB 左右,速度明显提升。虽然没有严格比较两者的回答质量,但对于简单问题,两者的表现应该相差不大。


Gemma 4 E4B在 Mac M4 上运行情况(CPU,GPU,内存)
由于 Gemma 4 采用自回归架构,推理速度会随着回复内容的增长而逐渐变慢(计算量随 token 数量呈平方级增长)。这一点在实际使用中也能明显感受到,如果需要用来撰写长文章,可能会比较吃力。
总体而言,16GB 的 Mac 能够运行 E2B 和 E4B 模型,但若追求更顺畅的体验,可以采用下一代 M5 芯片及更大的内存配置。对于企业用户而言,以相对较低的成本(几万到十几万元)即可搭建内部使用的模型服务器,这是一个相当有吸引力的方案,也将大大激发用户基于 Gemma 4 部署私有化模型的需求。
用 AI Edge Gallery 在手机上独立运行 Gemma 4
Gemma 4 除了可以在电脑上运行,还有一个重要应用场景——在手机等移动设备上直接部署。为此,谷歌提供了一个官方 App:AI Edge Gallery。
这是一款谷歌推出的实验性应用,支持在 Android 和 iOS 设备上直接运行开源 AI 模型。所有推理过程完全在手机本地完成,无需联网,也无需依赖任何服务器。
安装方式
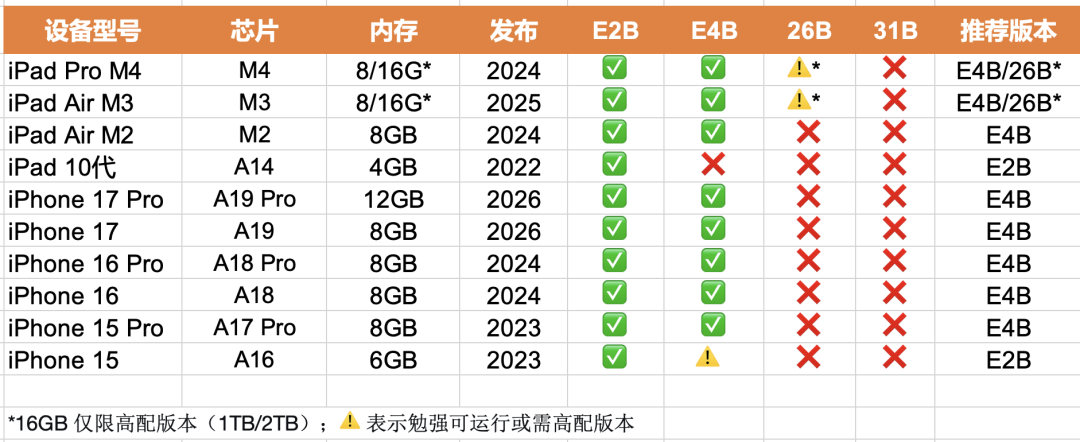
iOS 设备:直接在 App Store 搜索“Google AI Edge Gallery”下载安装即可。需要注意,设备需具备 8GB 或以上的 RAM。具体哪些 iPhone 或 iPad 型号可以运行,可参考本号之前的文章(谷歌 Gemma 4 核心技术架构与多场景能力分析)。
此外,如果你使用的是搭载 M 芯片的 Mac 电脑,由于它和 iPhone 一样采用 ARM 指令集,可以通过兼容模式运行 Google AI Edge Gallery。直接在 App Store 安装即可使用,性能也比手机端更优。
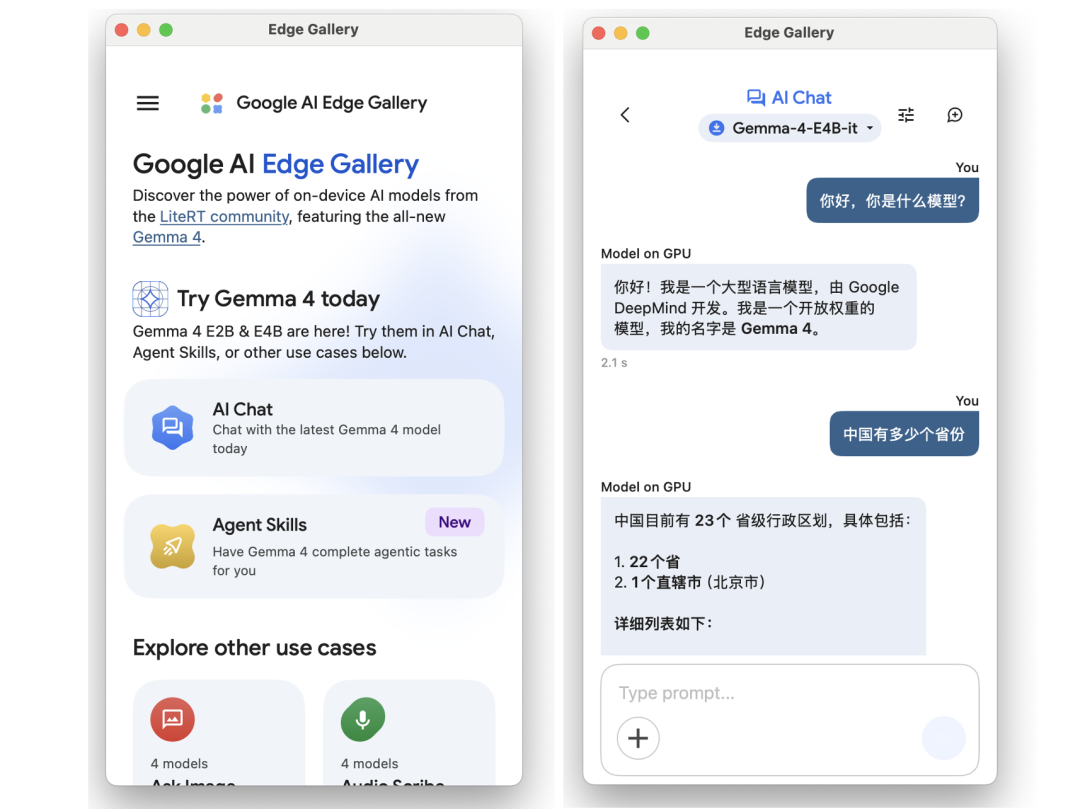
Mac M4 16GB 运行 AI Edge Gallery, Gemma 4 E4B 模型
Android 设备:需要采用 8GB 以上内存的中高端手机(具体型号可参考本号之前文章:谷歌 Gemma 4 核心技术架构与多场景能力分析),在 Google Play 商店搜索同名应用进行下载。国内用户也可通过 APK Mirror 下载,或直接访问 GitHub 的下载链接安装 APK 文件:
https://github.com/google-ai-edge/gallery/releases/download/1.0.11/ai-edge-gallery.apk
下载模型
打开应用后,根据自己设备的性能选择合适的模型版本,即可开始对话或使用各项功能:
- gemma-4-e2b-it:约 4GB,适合中低端手机
- gemma-4-e4b-it:约 6-7GB,适合旗舰机型,生成质量更优
下载完成后,模型即刻可用。此后所有对话均在手机本地完成,即使在飞行模式下也能照常运行。
这意味着在信号极差的地铁通勤路上,或是跨国航班的机舱里,你依然可以利用碎片时间进行深度写作或灵感头脑风暴,完全不受网络环境限制 。
核心功能一览
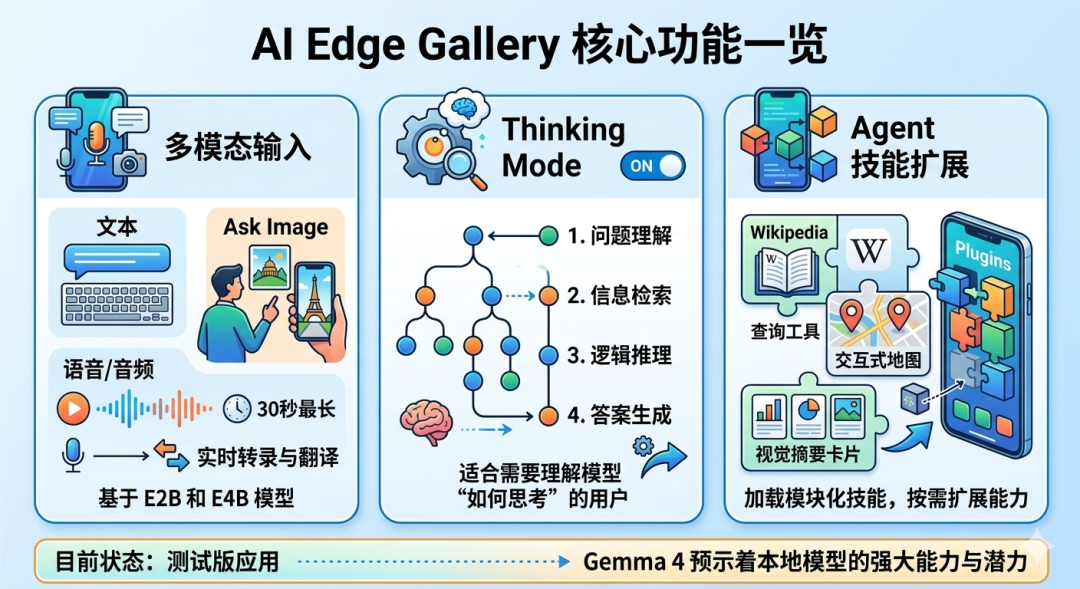
AI Edge Gallery 并不只是一个简单的聊天框,它提供了几项值得关注的能力:
- 多模态输入:除文字外,可上传图片提问("Ask Image"),也可录制语音或上传音频(最长 30 秒),进行实时转录与翻译。这得益于 E2B 与 E4B 模型原生支持图像与音频输入。
- Thinking Mode:开启后可以看到模型的完整推理过程,适合需要理解模型"如何思考"的用户。
- Agent 技能扩展:这是 AI Edge Gallery 最有特色的功能。除基础对话外,可以加载 Wikipedia 查询工具、交互式地图、视觉摘要卡片等模块化技能,相当于给手机上的 AI 安装"插件",按需扩展能力边界。
需要客观指出的是,AI Edge Gallery 目前更像是简单的测试版应用,真正稳定可用的正式版本可能还需要等待一段时间。但无论如何,Gemma 4 的发布已经让我们清晰看到本地模型的强大能力,以及其潜在广阔的用途。
结语
本地运行大模型,曾经是少数研究者的专属领地。今天,随着 Gemma 4 的开源和 Ollama 等工具的普及,以及硬件技术的发展,本地大模型将会激发更多的应用创新场景。
这不仅是技术的进步,更是一种权力的回归——把思考的工具握在自己手里,而非托付给远方的服务器。
AI 的本地时代,正在悄然开始。
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区留言讨论交流你对本地大模型的看法和希望做的应用。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号