谷歌Gemma 4遇上国产顶流:开源模型哪家强?

谷歌Gemma 4遇上国产顶流:开源模型哪家强?

Henry Zhang
发布于 2026-04-13 16:50:26
发布于 2026-04-13 16:50:26

题图摄于北京黄花水长城
谷歌上周发布 Gemma 4 系列开源模型,首次采用 Apache 2.0 协议,从手机到服务器全场景覆盖,从“替代品” 战略转向“争夺基础设施层”。与此同时,国内 Kimi K2.5、MiniMax M2.5、Qwen 3.5、GLM-5 等高性能模型集体爆发,中外开源力量,在此刻“相遇”了。
对于企业和开发者而言,问题不再是“要不要用AI”,而是“该选哪个AI”。选开源模型如同选队友:能力要强、成本要低、好管理、无法律风险。
接下来,我们从开源协议、硬件成本、代码能力、多模态表现、部署难度五个维度入手,把谷歌 Gemma 4 和国产顶流模型放在一起比一比。谁更划算?谁更好养?谁才是你的最佳队友?读完这篇,答案就心中有数了。
劳动合同比一比:谁家条款最良心?
模型的开源许可协议,就是你和“AI员工”签的劳动合同。条款宽松还是苛刻,直接决定了你的商业应用会不会踩坑。
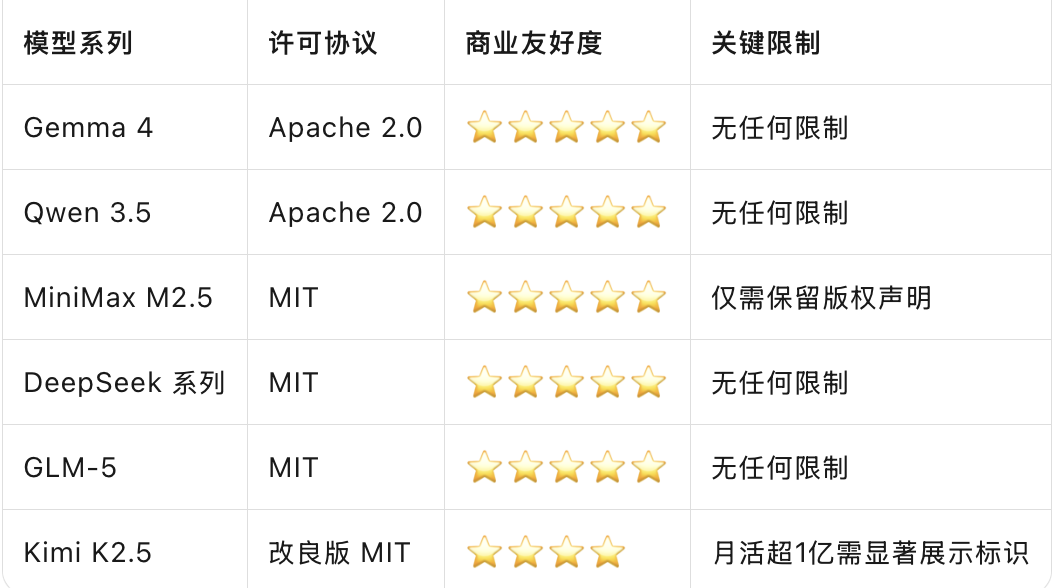
深度解读:
谷歌 Gemma 4 最大亮点之一,是全面采用 Apache 2.0 协议,取代了此前令人头疼的自定义许可证。这意味着可免费商用、自由修改分发、与 Hugging Face 等开源生态完全兼容。该协议没有“禁止危害用途”等灰色地带,是业界最宽松成熟的协议之一。
国内阵营同样给力。通义千问 Qwen 3.5 系列同样采用 Apache 2.0,真正实现个人企业免费使用、二次开发、私有化部署,无任何商用附加限制。智谱GLM-5 系列采用MIT协议,允许商业用途、二次开发、闭源发布衍生产品——这是千亿级参数模型首次采用如此宽松的协议,打破了“高性能模型必闭源”的行业惯例。
MiniMax M2.5 和 DeepSeek 系列也采用极其宽松的 MIT 协议,只需保留原始版权声明即可自由使用。DeepSeek 官方明确表示:“为了推动开源社区及行业生态发展,统一使用MIT协议。”
唯一的“小例外”是 Kimi K2.5。其改良版 MIT 协议基本允许商业使用,但设置了一个门槛:月活超1亿或月收入超 2000 万美元时,需显著展示 “Kimi K2.5” 标识。对 99% 的企业而言,这并非大问题——能做到这个体量的公司,加个 logo 也不难。
一句话总结: Gemma 4 和国内三巨头(通义、MiniMax、DeepSeek)都给出了“无附加条件”的宽松合同,想怎么用就怎么用,完全不用担心法律风险。
招聘成本:谁要的工资最低?
部署成本就像“AI员工”的工资:硬件投入是底薪,运营消耗是绩效奖金,维护人力是五险一金。
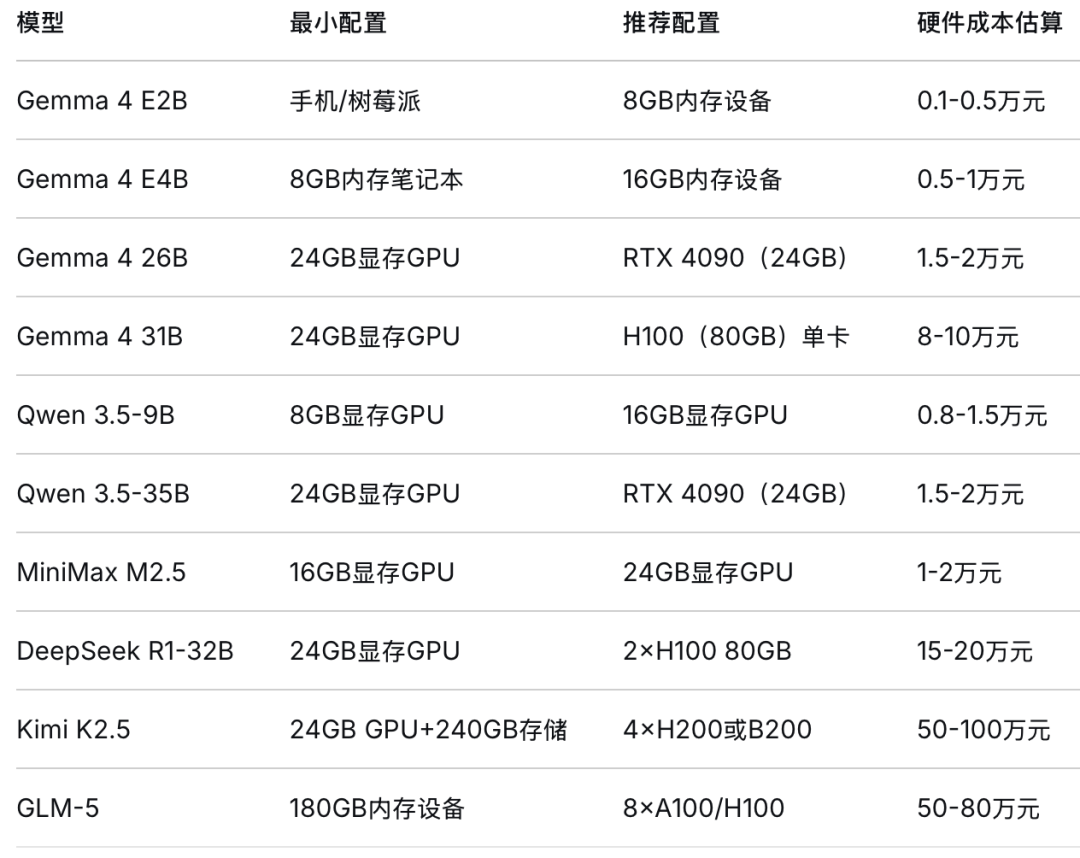
硬件成本对比一览
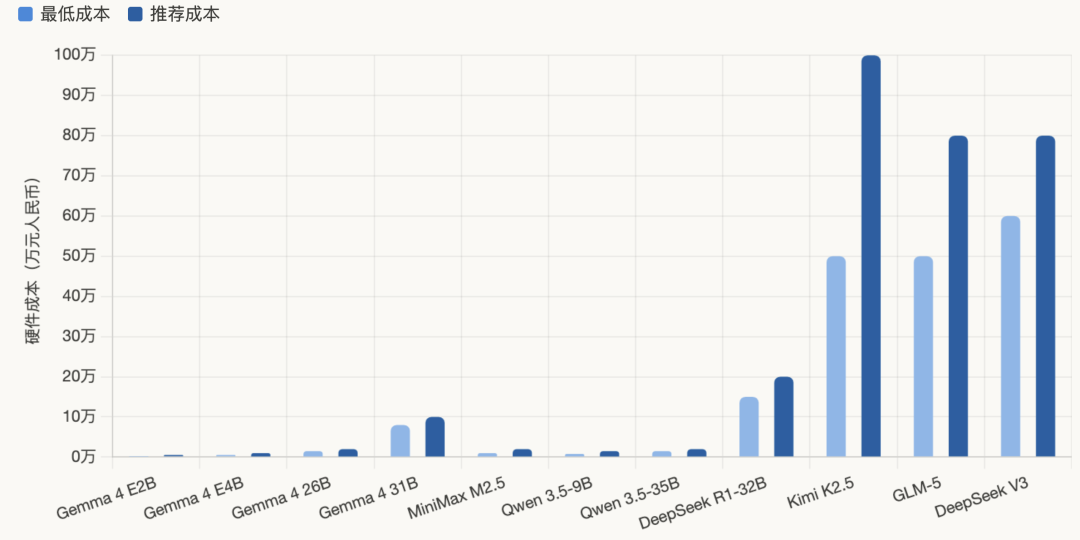
部署成本对比
运营成本对比

打个比方:
• MiniMax M2.5 和 Qwen 3.5-9B 就像刚毕业的985高材生——能力强、工资低(1-2万硬件搞定)、干活快(100 tokens/秒)。MiniMax通过INT4量化,显存从24GB降至8GB,一张RTX 3060就能跑。API成本更是惊人:输入约0.3美元/百万Token,输出约2.4美元,比顶级闭源模型便宜约100倍。
• Gemma 4系列像一个“变形金刚”——从树莓派到H100服务器,什么配置都能跑。E2B版本甚至可在手机上离线运行,适合边缘设备。26B版本总参数252亿,但推理时只激活38亿(MoE架构的魔力),量化后一张RTX 4090就能轻松驾驭。
• Kimi K2.5 和 GLM-5 则像院士级别的大牛——本事通天,但请得起的企业凤毛麟角。Kimi K2.5完整版630GB,至少需要4张H200 GPU,硬件投入50-100万起步。GLM-5完整版需1.5TB显存,INT4量化后仍需约420GB,得组16张RTX 3090集群才能勉强跑起来。
在高端消费级(2万元预算)市场,Qwen 3.5-35B堪称性价比之王,它以接近GPT-4早期的性能,做到了极低的硬件门槛。
但如果放眼所有预算范围,从几百元的树莓派到十万元的服务器,谷歌 Gemma 4 系列才是当之无愧的全能性价比之王。它通过 E2B、E4B、26B、31B 四个版本,在每个价位段都提供了‘越级’的性能表现,真正实现了‘丰俭由人,总有一款适合你’。”
业务能力:谁是真“卷王”?
代码能力(程序员最关心的)
代码生成能力是衡量大模型实用性的核心指标之一。毕竟,一个能帮你写代码的AI,才是真正能“回本”的AI。
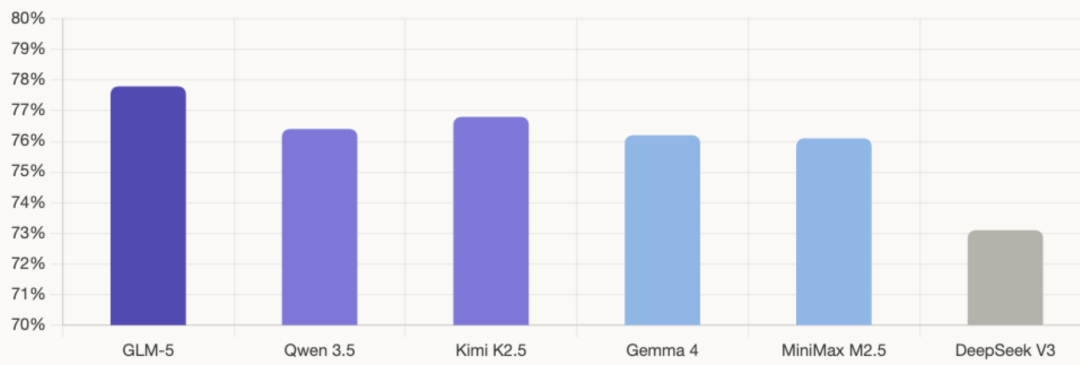
生成代码能力对比
深度解读:
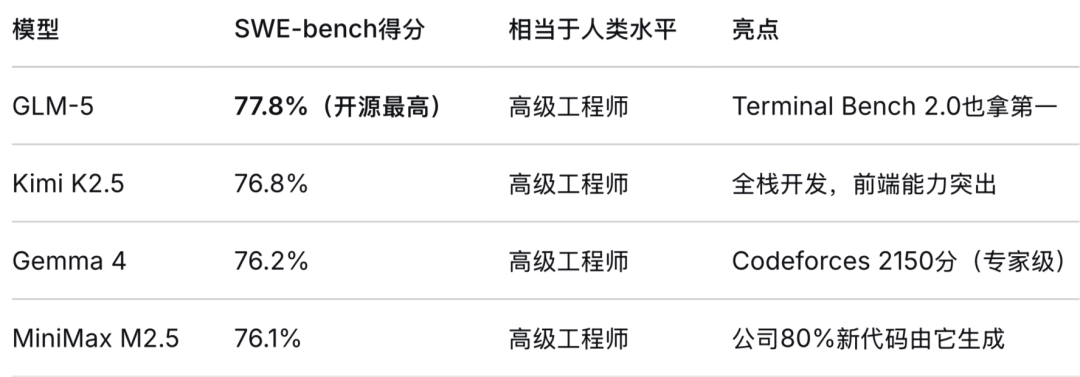
GLM-5 代码能力对齐 Claude Opus 4.5 ,在 SWE-bench-Verified 和Terminal Bench 2.0 中均拿下开源最高分,能可靠处理 Python、Java、Go 等多种语言及复杂命令行工作流。
Gemma 4 堪称“飞跃”—— LiveCodeBench 从 29.1% 飙至 80.0%,Codeforces 获 2150分(专家级),大幅领先 Qwen 3.5 的 1980 分。处理算法题和 CRUD 逻辑时稳健、注释详尽,甚至会主动做输入校验。
Kimi K2.5 被誉为“国内领先的 Coding 模型”,最强项是前端能力——从自然语言直接生成视觉精美的交互界面,精准处理动态布局、滚动动画等复杂效果。单提示即可处理整个代码库,堪称大型项目重构神器。
MiniMax M2.5 更令人惊叹:公司 80% 的新代码由它生成——AI 自己写代码养自己,这才是真闭环!在多语言任务 Multi-SWE-Bench 上达到行业最好水平。
综合来看,GLM-5 在标准化测试中登顶开源模型,综合实力最强。Kimi K2.5以前端开发和全库理解见长,适合界面生成与项目重构。MiniMax M2.5用“80%代码自产”证明了实战价值,多语言能力突出。Gemma 4 进步最猛,算法题稳健,是个人开发者的优质选择。选代码模型,看你要标杆、要实战、还是要性价比。
多模态能力(看图、看视频、听声音)
如果说代码能力是“智商”,那么多模态能力就是“感官”——能不能看懂图片、听懂语音、理解视频。
多模态综合能力

形象比喻:
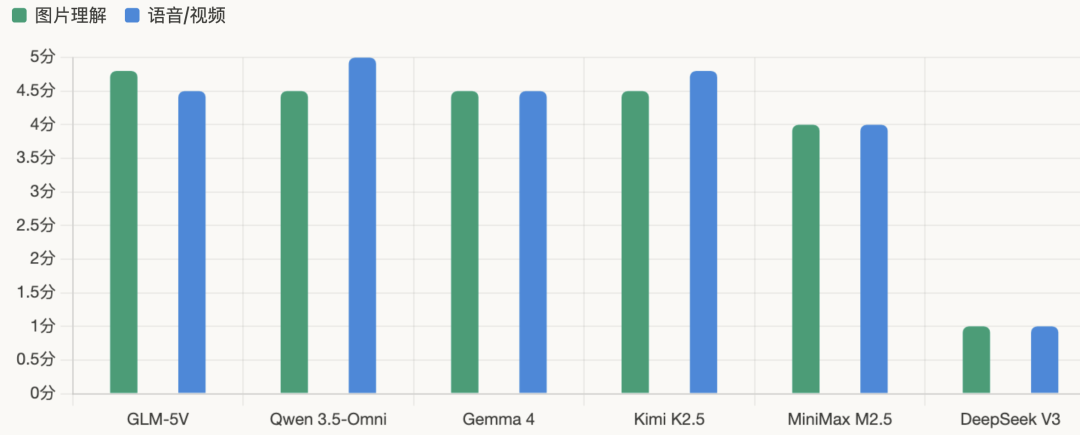
• GLM-5V-Turbo 是“全能艺术家”——会看画、会读图、能理解视频、还能自己画。它引入了 VQ-VAE 技术,将图像和视频帧离散化为 Visual Tokens,实现了统一的模态表示。在多模态 Coding、Tool Use、GUI Agent 等核心基准上都取得了领先表现。
• Gemma 4 是“语言天才”——支持 140+ 种语言,音频输入直接处理,无需中间的语音转文字步骤。它的视觉编码器支持可变分辨率,不再强制裁切图片,还能灵活配置图像 token 预算(五档可选)。
• Kimi K2.5 是“长视频专家”——能连续理解最长 10 小时的视频,通过时序感知模态融合层解决了帧间时序信息丢失的核心问题。它还有个“视频即代码”的绝活——能通过推理视频内容来重建网站。
• Qwen 3.5-Omni 是“方言通”——支持 113 种语言方言识别和 36 种语言合成,能处理超过 10 小时音频或 400 秒 720P 视频。它在 215 项第三方性能测试任务中拿下 SOTA 成绩。
• DeepSeek 则是“文科状元”——文本推理无人能敌,但对图片视频“视而不见”。V3 版本明确表示暂不支持多模态输入输出,只能处理纯文本任务。
多模态赛道上,GLM-5V-Turbo 凭借“理解+生成”的双向能力拔得头筹,是真正的全能选手。Gemma 4 和 Qwen 3.5-Omni 在各自擅长领域表现顶尖,前者语言覆盖广,后者方言识别强。Kimi K2.5 的长视频理解独树一帜。而DeepSeek 虽在多模态缺席,却是纯文本推理的最佳选择——选谁,取决于你是否需要让AI“看懂”世界。
好养活程度:谁最省心?
模型的运维复杂度,决定了你需要花多少人力去伺候它。
生活化类比:
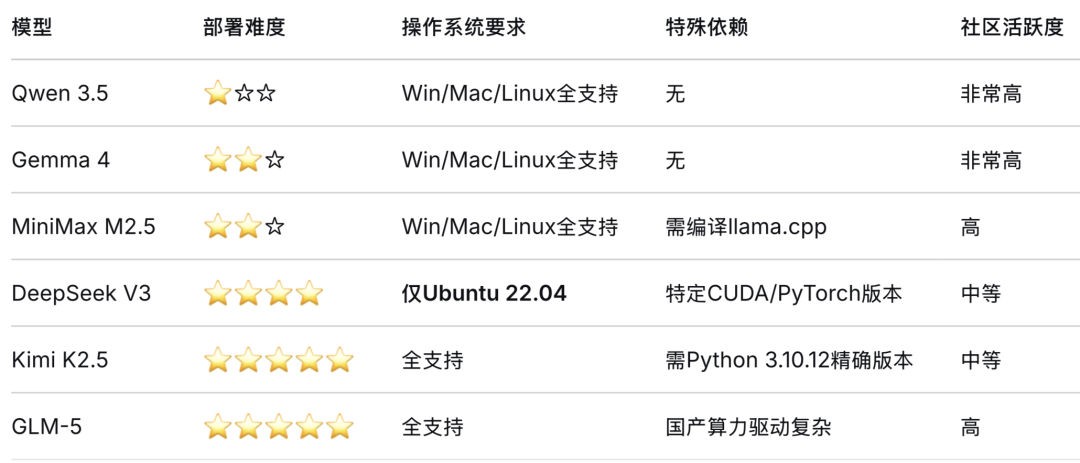
•Qwen 3.5 像养一只猫——给口吃的就能活。最低配置:CPU 支持 AVX2 指令集、内存 8GB 以上、SSD 剩余空间 20GB 以上,集成显卡都能跑 CPU 推理。推荐配置也只要 16GB 内存加一块 4GB 显存的显卡。
•Gemma 4 像养一条狗——需要一点训练但听话。与 Hugging Face、Ollama等主流生态完全兼容,通过 NVIDIA NeMo 框架可直接用 LoRA/SFT 技术进行领域适配,无需模型格式转换。
•DeepSeek V3 像养一匹马——需要专门的马厩和饲料。仅支持 Ubuntu 22.04 操作系统,必须用 Python 3.10、CUDA 11.8/12.2、PyTorch 2.0.1 这些精确版本,还需要 ≥ 3GB/s 的 NVMe SSD。
•Kimi K2.5 和 GLM-5 像养大象——没动物园根本养不起。超大规模模型的存储和加载管理复杂,需要复杂的量化配置和严格的资源监控调度。
从“好养活”到“难伺候”:Qwen 3.5 如猫,门槛极低;Gemma 4 如狗,生态友好;DeepSeek V3 如马,环境苛刻;Kimi 与 GLM-5 如大象,非大厂莫属。选模型前,先掂量自己的“饲养”能力。
终极选择指南:谁是你的“天选打工人”?
结语
2026年的开源模型生态,就像一个热闹非凡的人才市场,各路“AI打工人”摆摊亮相:
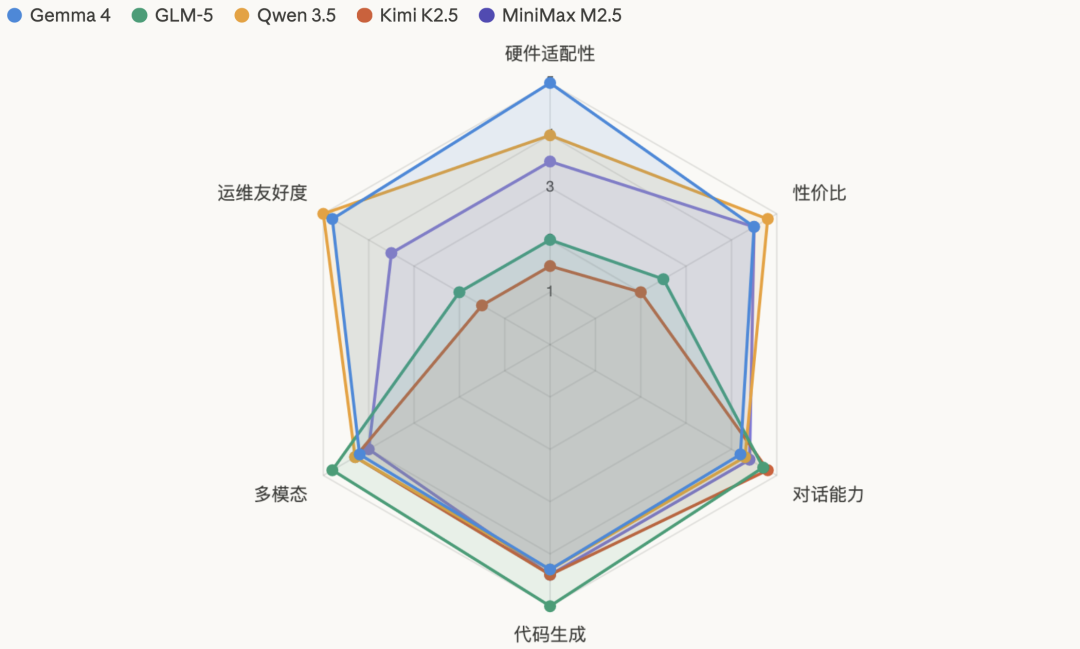
综合能力雷达图
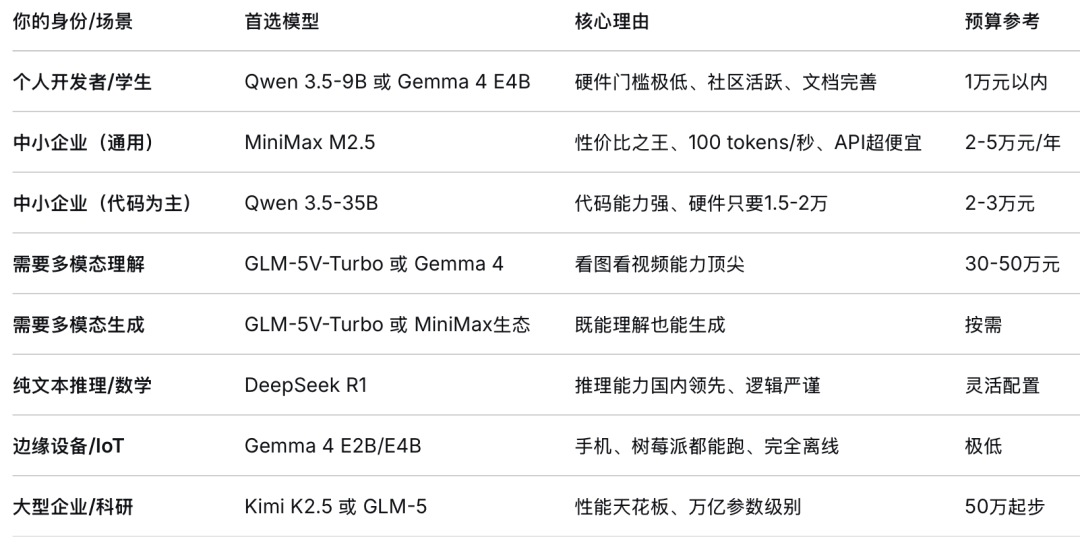
• 谷歌Gemma 4 像海归精英——背景光鲜(谷歌出品)、能力全面(多模态+Agent)、适应各种岗位(从树莓派到服务器)。它的Apache 2.0协议和原生Agent支持是最大卖点。
• Qwen 3.5 像国企骨干——稳定可靠、性价比高、没有明显短板。通义系的生态整合和极低的硬件门槛,让它成为个人开发者的首选。
• MiniMax M2.5 像互联网新贵——年轻、快(100 TPS)、便宜(API价格仅为闭源模型的1/100)。80%代码自产自用的故事,证明了它的实战价值。
• Kimi K2.5 像行业大佬——本事通天(1万亿参数、10小时视频理解、Agent Swarm百智能体并行),但请得起的企业凤毛麟角。
• GLM-5 像学术大牛——理论扎实(AIME 2026数学92.7%)、多才多艺(代码第一、多模态第一)、还接地气(全面适配国产算力)。
• DeepSeek 像推理专家——文科无敌(逻辑推理国内领先),但别让它看图。R1版本的深度思考模式虽然慢,但代码注释最详细、边界条件覆盖最完整。
最后送你一句真心话:没有最好的模型,只有最适合你钱包和需求的“AI打工人”。
选模型前先问自己三点:预算是多少?核心场景是什么?团队技术够不够强?
想清楚这三点,就能在今年开源模型“百团大战”中找到属于自己的“猛将”。选错浪费的不只是钱,更是时间和机会成本。希望这份对比能帮你做出明智选择。
(本文数据来源:各模型官方技术报告、第三方评测平台及社区实测数据,截至2026年4月。)
欢迎关注 亨利笔记, 👍 点赞 | ⭐ 收藏 | ↗️ 转发。欢迎评论区留言讨论交流。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-09,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号