零基础OceanBase数据库入门(8):SQL优化入门(定位+执行计划+实战)

零基础OceanBase数据库入门(8):SQL优化入门(定位+执行计划+实战)

俊才
发布于 2026-04-13 17:14:03
发布于 2026-04-13 17:14:03
上一篇我们完成了集群性能诊断,能快速定位CPU、内存、磁盘高负载问题。而在实际生产中,慢SQL才是数据库性能的头号杀手。
本篇完全基于OceanBase官方demo,带你走通标准SQL优化流程:定位TOP SQL→分析执行计划→实战优化,零基础也能照着做,快速搞定慢查询。
一、前置准备:登录租户
优化SQL可在业务租户操作,定位全局TOP SQL建议登录sys租户:
# 登录sys租户(密码替换为你的)
obclient -h127.0.0.1 -P2881 -uroot@sys -p -Doceanbase -A
二、第一步:定位TOP SQL(3条万能SQL)
优化的前提是找到耗资源的SQL,官方提供3种高频查询方式,直接复制可用。
2.1 查询指定时间段TOP SQL
按租户、节点、时间范围,筛选执行最慢的10条SQL:
SELECT
/*+READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000), PARALLEL(4)*/
sql_id,
COUNT(1),
AVG(elapsed_time),
AVG(execute_time),
AVG(total_wait_time_micro),
AVG(return_rows),
AVG(affected_rows),
query_sql,
ret_code
FROM v$OB_SQL_AUDIT
WHERE
tenant_id = 1002 -- 替换为目标租户ID
AND svr_ip IN ('127.0.0.1')
AND (CAST(USEC_TO_TIME(request_time) AS datetime)
BETWEEN '2025-09-07 14:00:46' AND '2025-09-08 14:01:46')
GROUP BY sql_id
ORDER BY AVG(elapsed_time) DESC
LIMIT 10\G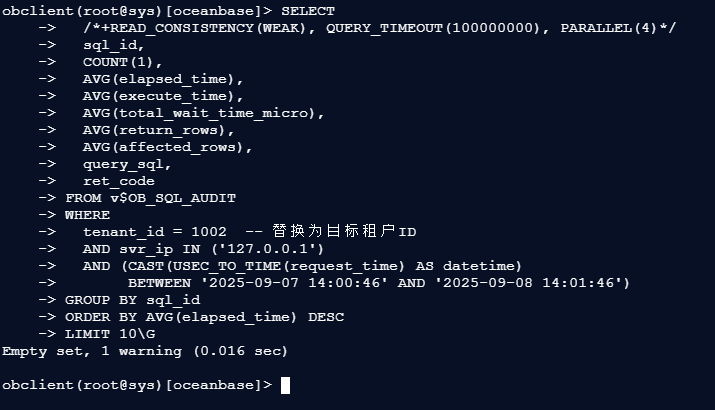
2.2 查询最近1分钟TOP SQL
快速排查实时慢查询:
SELECT
/*+ READ_CONSISTENCY(WEAK), QUERY_TIMEOUT(100000000), PARALLEL(4)*/
sql_id,
AVG(elapsed_time),
AVG(execute_time),
AVG(total_wait_time_micro),
AVG(return_rows),
AVG(affected_rows),
substr(query_sql, 1, 50) query_sql,
ret_code
FROM v$OB_SQL_AUDIT
WHERE TIME_TO_USEC(NOW(6)) - request_time < 60000000
GROUP BY sql_id, query_sql, ret_code
ORDER BY 3 DESC
LIMIT 10;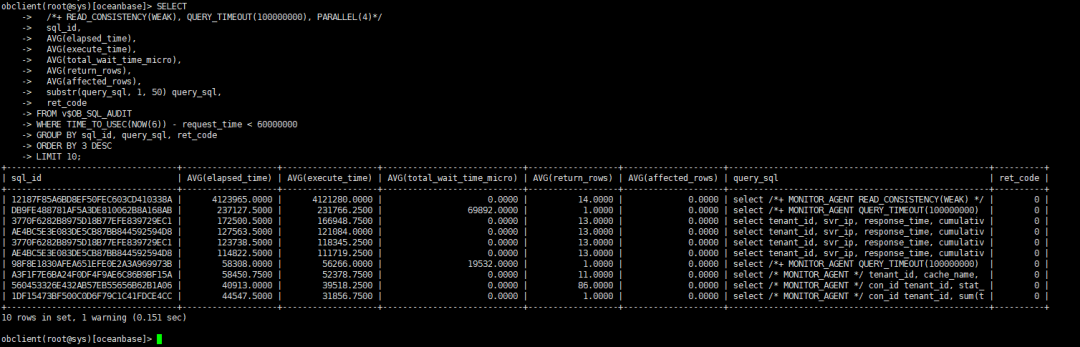
2.3 查询综合消耗TOP SQL
按总执行耗时排序,定位最影响集群的SQL:
SELECT
SQL_ID,
AVG(ELAPSED_TIME),
AVG(QUEUE_TIME),
AVG(ROW_CACHE_HIT + BLOOM_FILTER_CACHE_HIT + BLOCK_CACHE_HIT + DISK_READS) avg_logical_read,
AVG(execute_time) avg_exec_time,
COUNT(*) cnt,
AVG(execute_time - TOTAL_WAIT_TIME_MICRO) avg_cpu_time,
AVG(TOTAL_WAIT_TIME_MICRO) avg_wait_time,
WAIT_CLASS,
AVG(retry_cnt)
FROM v$OB_SQL_AUDIT
GROUP BY 1
ORDER BY avg_exec_time * cnt DESC LIMIT 10;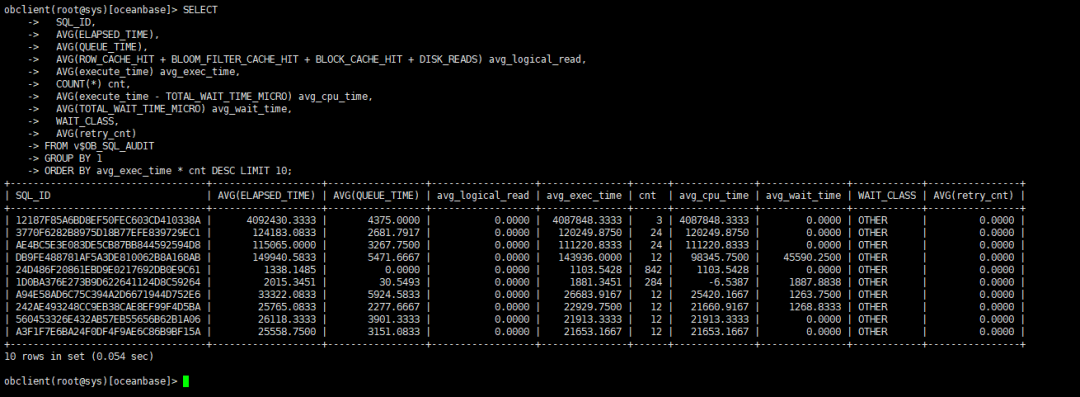
三、 查看SQL执行计划
找到慢SQL后,用执行计划分析扫描方式、关联算法、是否走索引,这是优化的核心。
3.1 创建测试表及数据
USE test;
CREATE TABLE t1 (c1 BIGINT, c2 VARCHAR(50));
CREATE TABLE t2 (c1 BIGINT, c2 VARCHAR(20));
INSERT /*+ append enable_parallel_dml parallel(8) monitor */ INTO t1 select random(), randstr(10, random()) FROM table(generator(1000000));
INSERT /*+ append enable_parallel_dml parallel(8) monitor */ INTO t2 select random(), randstr(10, random()) FROM table(generator(1000000));
3.2 用EXPLAIN查看执行计划
# 切换到测试库
USE test;
# 查看SQL执行计划
EXPLAIN SELECT * FROM t1,t2 WHERE t1.c1=t2.c1;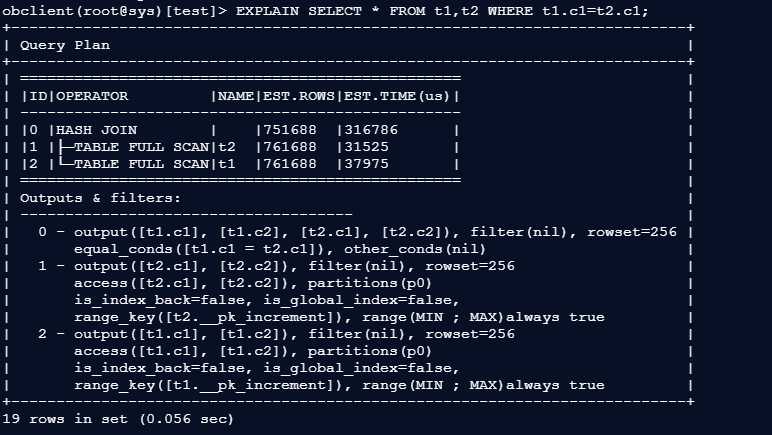
关键看如下内容:
- TABLE FULL SCAN:全表扫描(性能差)
- HASH JOIN/NESTED-LOOP JOIN:关联算法
- EST.TIME(us):预估执行耗时
3.3 用TRACE_ID查看执行计划监控
先获取SQL的trace_id:
obclient(root@sys)[test]> SELECT trace_id FROM oceanbase.GV$OB_SQL_AUDIT WHERE query_sql like '%table(generator(1000000))%' ORDER BY REQUEST_TIME DESC LIMIT 1;
+-----------------------------------+
| trace_id |
+-----------------------------------+
| YB427F000001-00064EEEB7B17A29-0-0 |
+-----------------------------------+
1 row in set (0.178 sec)
根据trace_id查计划详情:
obclient(root@sys)[test]> SELECT
-> PROCESS_NAME,
-> PLAN_LINE_ID,
-> PLAN_OPERATION,
-> COUNT(*) PARALLEL,
-> AVG(LAST_REFRESH_TIME - FIRST_REFRESH_TIME) AVG_REFRESH_TIME,
-> MAX(LAST_REFRESH_TIME - FIRST_REFRESH_TIME) MAX_REFRESH_TIME,
-> MIN(LAST_REFRESH_TIME - FIRST_REFRESH_TIME) MIN_REFRESH_TIME,
-> AVG(LAST_CHANGE_TIME - FIRST_CHANGE_TIME) AVG_CHANGE_TIME,
-> MAX(LAST_CHANGE_TIME - FIRST_CHANGE_TIME) MAX_CHANGE_TIME,
-> MIN(LAST_CHANGE_TIME - FIRST_CHANGE_TIME) MIN_CHANGE_TIME,
-> SUM(OUTPUT_ROWS) TOTAL_OUTPUT_ROWS,
-> SUM(STARTS) TOTAL_RESCAN_TIMES
-> FROM
-> oceanbase.GV$SQL_PLAN_MONITOR
-> WHERE
-> trace_id = 'YB427F000001-00064EEEB7B17A29-0-0'
-> GROUP BY
-> PLAN_LINE_ID
-> ORDER BY
-> PLAN_LINE_ID ASC;
+--------------+--------------+--------------------------+----------+------------------+------------------+------------------+-----------------+-----------------+-----------------+-------------------+--------------------+
| PROCESS_NAME | PLAN_LINE_ID | PLAN_OPERATION | PARALLEL | AVG_REFRESH_TIME | MAX_REFRESH_TIME | MIN_REFRESH_TIME | AVG_CHANGE_TIME | MAX_CHANGE_TIME | MIN_CHANGE_TIME | TOTAL_OUTPUT_ROWS | TOTAL_RESCAN_TIMES |
+--------------+--------------+--------------------------+----------+------------------+------------------+------------------+-----------------+-----------------+-----------------+-------------------+--------------------+
| 1939 | 0 | PHY_PX_FIFO_COORD | 1 | 4.8757960000 | 4.875796 | 4.875796 | NULL | NULL | NULL | 0 | 0 |
| 6395 | 1 | PHY_PX_REDUCE_TRANSMIT | 8 | 2.7876961250 | 2.856417 | 2.605654 | NULL | NULL | NULL | 0 | 0 |
| 6395 | 2 | PHY_PX_MULTI_PART_INSERT | 8 | 2.7876961250 | 2.856417 | 2.605654 | NULL | NULL | NULL | 0 | 0 |
| 6395 | 3 | PHY_PX_FIFO_RECEIVE | 8 | 2.7593627500 | 2.824415 | 2.505104 | 2.7130008750 | 2.804410 | 2.485099 | 1000000 | 0 |
| 6392 | 4 | PHY_PX_DIST_TRANSMIT | 1 | 2.8254700000 | 2.825470 | 2.825470 | 2.7067820000 | 2.706782 | 2.706782 | 1000000 | 0 |
| 6392 | 5 | PHY_SUBPLAN_SCAN | 1 | 2.7067820000 | 2.706782 | 2.706782 | 2.4132430000 | 2.413243 | 2.413243 | 1000000 | 0 |
| 6392 | 6 | PHY_FUNCTION_TABLE | 1 | 2.7067820000 | 2.706782 | 2.706782 | 2.4132430000 | 2.413243 | 2.413243 | 1000000 | 0 |
+--------------+--------------+--------------------------+----------+------------------+------------------+------------------+-----------------+-----------------+-----------------+-------------------+--------------------+
7 rows in set (0.014 sec)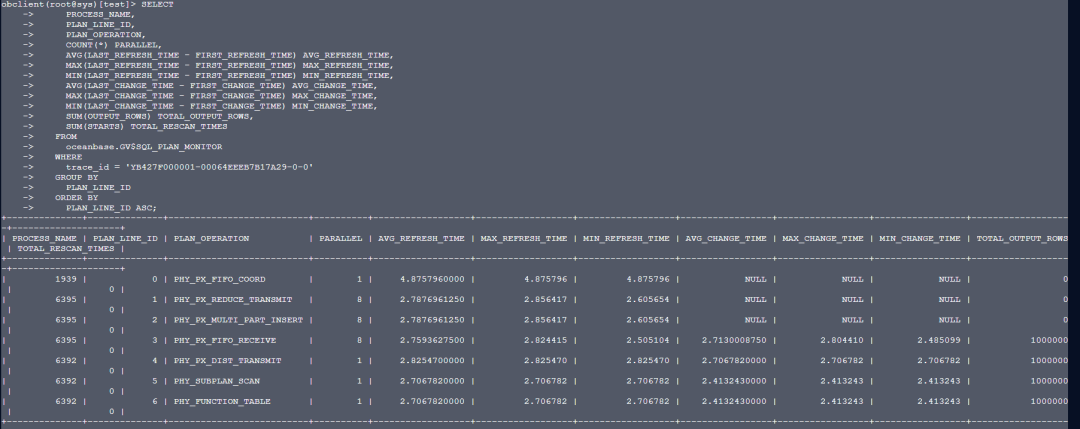
注:视图GV$SQL_PLAN_MONITOR一般仅记录执行时间大于5s的SQL,为了确保能获取到执行计划,建议在待执行的SQL语句中增加一个HINT/*+monitor*/。
四、第三步:实战优化(官方完整案例)
我们复现官方慢SQL案例,从0.7s优化到0.01s,直观感受优化效果。
4.1 构建测试环境
创建3张测试表:
CREATE TABLE tbl1 (c1 INT, c2 VARCHAR(50));
CREATE TABLE tbl2 (c1 CHAR, c2 VARCHAR(20));
CREATE TABLE tbl3 (c1 VARCHAR(20), c2 VARCHAR(20));
创建存储过程插入数据:
DELIMITER $
CREATE PROCEDURE insert_tbl1(IN args INT)
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i<=args DO
INSERT INTO tbl1(c1,c2) VALUE (i,CONCAT("jerry",i));
SET i=i+1;
END WHILE;
COMMIT;
END $
DELIMITER ;
# 调用插入100万数据
CALL insert_tbl1(1000000);
同样的处理tbl2及tbl3表
DELIMITER $
CREATE PROCEDURE insert_tbl2(IN args INT)
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i<=args DO
INSERT INTO tbl2(c1,c2) VALUE ('i',CONCAT("jerry",i));
SET i=i+1;
END WHILE;
COMMIT;
END
$
DELIMITER ;
DELIMITER $
CREATE PROCEDURE insert_tbl3(IN args INT)
BEGIN
DECLARE i INT DEFAULT 1;
START TRANSACTION;
WHILE i<=args DO
INSERT INTO tbl3(c1,c2) VALUE ('i',CONCAT("jerry",i));
SET i=i+1;
END WHILE;
COMMIT;
END
$
DELIMITER ;
call insert_tbl2(1000);
call insert_tbl3(100);
多次执行慢SQL(耗时约0.7s):
select tbl1.c2,tbl2.c2,tbl3.c2
from tbl1,tbl2,tbl3 where tbl1.c1=tbl2.c1 and tbl1.c1=tbl3.c1 and tbl2.c1='3';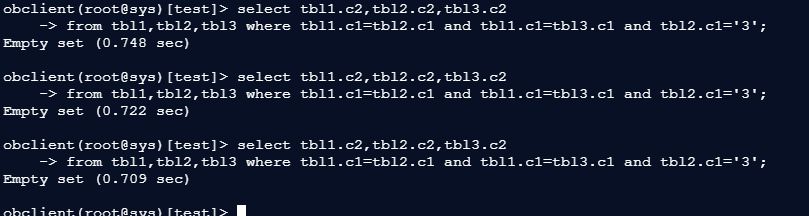
4.2 分析问题根源
执行EXPLAIN查看计划:全表扫描+隐式类型转换+关联顺序错误
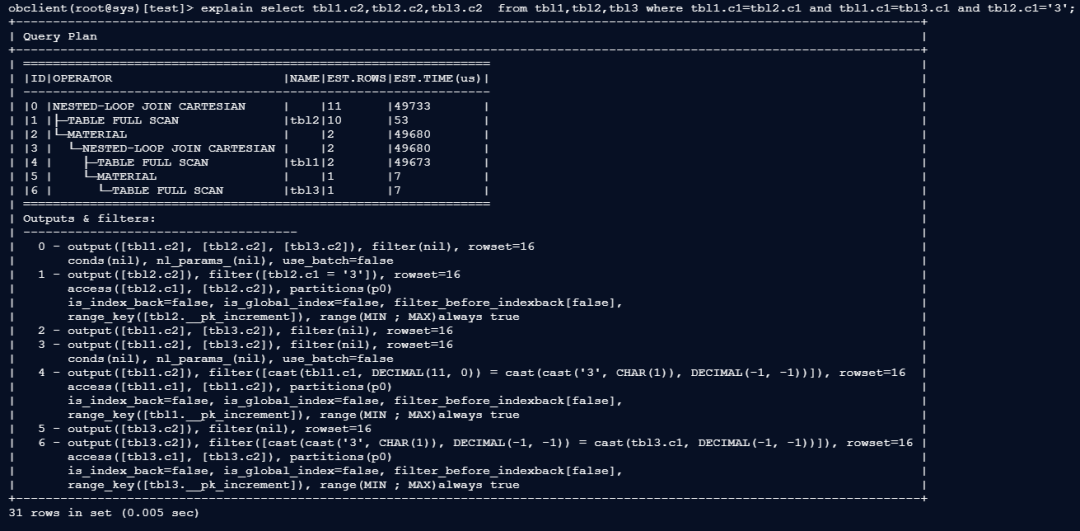
表结构问题:关联列c1数据类型不一致(int/char/varchar)
无索引,且未遵循小表驱动大表
4.3 三步优化
统一关联字段类型:
ALTER TABLE tbl1 MODIFY c1 VARCHAR(20);
ALTER TABLE tbl2 MODIFY c1 VARCHAR(20);
添加索引:
ALTER TABLE tbl1 ADD INDEX tbl1_c1 (c1);
ALTER TABLE tbl2 ADD INDEX tbl2_c1 (c1);
ALTER TABLE tbl3 ADD INDEX tbl3_c1 (c1);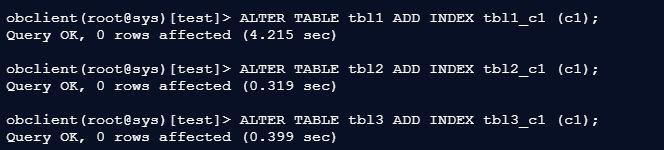
调整关联顺序(小表驱动大表):
select /*+ leading(tbl2 tbl1 tbl3)*/ tbl1.c2,tbl2.c2,tbl3.c2
from tbl1,tbl2,tbl3 where tbl1.c1=tbl2.c1 and tbl1.c1=tbl3.c1 and tbl2.c1='3';
Empty set (0.011 sec)
4.4 优化效果
- 执行时间:0.7s→0.011s,提升60倍
- 执行计划:全表扫描→索引范围扫描,预估耗时大幅下降
五、SQL优化核心思路(官方总结)
- 定位:用V$OB_SQL_AUDIT找到TOP SQL
- 分析:用EXPLAIN看是否全表扫描、类型转换、关联算法
优化:
- 加索引,避免全表扫描
- 统一关联字段类型,消除隐式转换
- 小表驱动大表,调整关联顺序
- 合理使用Hint指定执行计划
六、小结
本篇我们掌握了OceanBase SQL优化标准流程:
- 用3条SQL快速定位TOP慢查询
- 用EXPLAIN+trace_id分析执行计划
- 通过统一字段类型+加索引+调整关联顺序完成实战优化
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号