突袭!DeepSeek上线专家模式

突袭!DeepSeek上线专家模式

TechMiel
发布于 2026-04-13 17:36:45
发布于 2026-04-13 17:36:45
就在今天,DeepSeek悄咪咪搞了个大动作——没有预热、没有官宣,直接全量上线了“专家模式”,还把原来的核心交互模式升级成了“快速模式”,堪称平地一声雷。
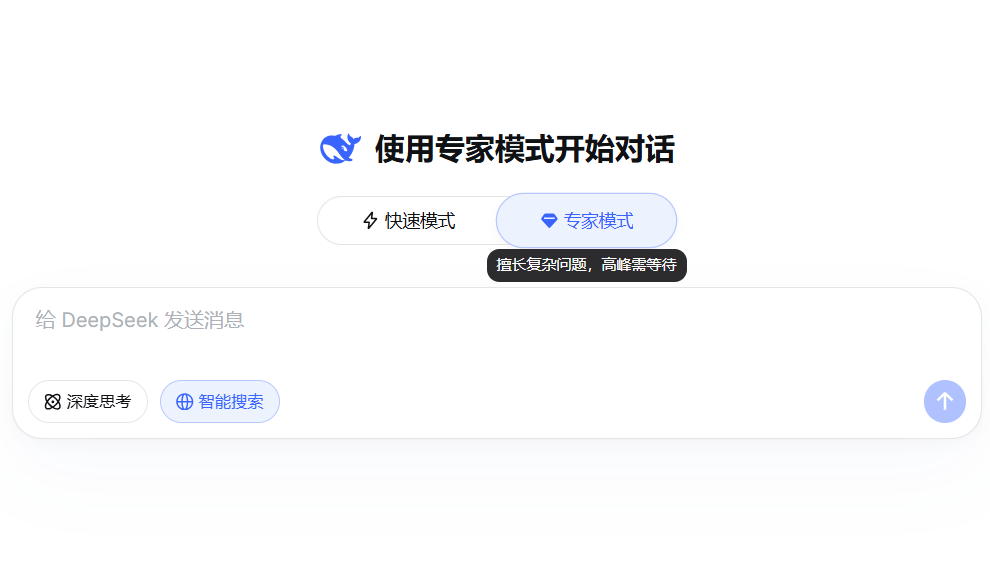
上线后我第一时间就去实测了一把。说实话,这种不声不响的更新,反而比大张旗鼓的预热更让人在意。看似只是简单的模式分层,背后其实藏着DeepSeek的两个小心思:一是解决此前服务崩溃、算力不足的问题,二是为即将发布的V4模型铺路,毕竟业界等这款适配国产算力的新模型,已经等了快两个月了。
一、专家模式实测:不是V4,但足够解决打工人的刚需
很多人看到专家模式上线,第一反应就是“这是不是V4模型?”,我实测下来可以明确说:大概率不是。不管是问复杂代码调试,还是之前让全网AI翻车的“50米洗车题”,专家模式的表现虽然比快速模式强太多,但对比网传V4的参数(万亿参数、多模态),差距还是很明显,更像是R1模型的优化版。这里要说明下,快速模式不是全新的,是DeepSeek把原来大家常用的基础交互模式,重新命名并优化而来,核心还是V3.2模型,只是更贴合“快速响应”的定位。

但说实话,专家模式是真的戳中了打工人和从业者的痛点。它跟快速模式的区别很直观:快速模式(就是原来的基础模式,只是换了个名字、做了小优化)主打快,适合闲聊、查个简单信息,黑盒输出,看完就完;专家模式会把整个思考过程都展示出来,像极了我们自己做题时打草稿,拆解问题、一步步推演,哪怕算错了,也能跟着它的思路找到漏洞。比如我测的9.9和9.11谁大,它不仅给答案,还会拆解比较逻辑,对做复杂题、写代码的人来说,确实能省不少事。不过有个小槽点,专家模式高峰要等,还不能传附件、用语音,实用性打了点折扣。
二、模式分层的真相:算力焦虑下的妥协,也是V4的铺垫
很多人觉得DeepSeek搞模式分层,只是为了差异化竞争,其实不然。我记得3月底的时候,DeepSeek曾崩了10多个小时,当时大家还猜是算力扛不住了,现在看来,大概率就是在为这次更新做准备。分层设计的核心,说白了就是“分流”——日常简单对话用轻量的V3.2(也就是现在的快速模式,延续了原来的基础能力),省算力;复杂任务才用专家模式的重模型,避免资源浪费,这也是应对算力不足最务实的办法。

更重要的是,这波更新也是在为V4铺路。业界早就传V4要适配华为昇腾950PR,阿里、字节、腾讯都提前订了几十万颗芯片,甚至带动芯片涨价20%,可见大家对V4的期待有多高。DeepSeek现在优化产品体验、解决算力分配问题,就是在为V4上线后的大规模使用做准备,毕竟V4的算力需求只会更高。
最后来谈谈我自己的一些看法:DeepSeek的创始人梁文锋一直太专注技术,不太看重商业化,这也是它步伐比其他AI慢的原因。现在虽然开始重视产品化,甚至招了Agent方向的产品经理,但面对内外竞争,能不能借着V4和专家模式的东风站稳脚跟,还不好说。但不管怎么说,这种不搞噱头、扎实做产品的态度,在当下的AI圈,确实难得。对此,你怎么看呢,欢迎评论区留言哦~
▲ 欢迎关注“TechMiel” 一起探索AI前沿与科技宇宙~
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号