同一个模型,为什么套个壳就变强了?

同一个模型,为什么套个壳就变强了?

随机比特
发布于 2026-04-13 18:06:42
发布于 2026-04-13 18:06:42
如果你同时用过 ChatGPT 的网页版和 Claude Code,你一定有过这种感觉:
明明问的是同一个问题,Claude Code 给出的答案好得不像话——代码能跑、文件改对了、测试也过了。而网页版呢?它给你一段看起来对但其实跑不通的代码,然后礼貌地说"你可以试试看"。
你以为是模型的差距。
但事实是,Claude Code 里跑的 Claude,和 claude.ai 聊天框里跑的 Claude,是同一个模型。ChatGPT 的网页版和 Codex CLI 里跑的 GPT,也是同一个模型。
底层发动机一模一样,但开起来天差地别。
这件事困扰了我挺久,直到最近读了 Sebastian Raschka 的一篇文章,一句话点透了:模型是发动机,你日常体验到的 80% 的能力,来自发动机外面那辆车。
那辆"车",技术圈叫它 agent harness。
聊天框的"聪明",其实是一种假象
你在聊天框里跟 AI 对话,感觉它什么都知道。但它真正知道的,只有你这次对话里敲进去的那些字。
它不知道你的项目用的是 TypeScript 还是 Python。不知道你的测试框架是 pytest 还是 vitest。不知道你昨天刚把一个模块从 class 重构成了函数式。不知道你的团队有个约定——所有 API 返回都要包一层 Result 类型。
你以为你在跟一个资深工程师对话,其实你在跟一个每次见面都失忆的天才对话。
每次打开聊天框,你都得重新介绍自己、介绍项目、介绍上下文。稍微漏说一点,它就会给你一个"正确但没用"的答案。
而 Claude Code 呢?你打开终端的那一刻,它已经扫完了你的整个仓库。README 读了,目录结构看了,git 历史翻了,连 .env 的命名风格都注意到了。
你还没开口,它就已经知道你是谁、你在做什么、你上次做到哪了。
这不是模型更聪明了。这是"车"替你做了所有准备工作。
更可怕的差距在"动手"
聊天框里的 AI,说到底只能做一件事:生成文字。
它可以给你写一段代码,但它不能帮你创建文件。它可以建议你跑个测试,但它自己跑不了。它可以告诉你"这个函数的调用方也要改",但它不知道调用方在哪,因为它根本看不到你的代码库。
所以你每天的工作流变成了这样:问 AI → 复制代码 → 粘贴到编辑器 → 手动改 → 跑测试 → 测试挂了 → 回去再问 AI → 再复制 → 再粘贴……
而有了 harness 的 AI,它能自己读文件、写文件、跑命令、搜代码、调 API。你说"把 fetchUser 加一个 timeout 参数",它 grep 所有调用点,一次性改完,自己跑测试确认。
你不再是它的手和眼。它自己有手有眼了。

聊天框 vs Agent Harness:差距不在大脑,在四肢
真正致命的,是"记忆"
这一点很多人没意识到。
你昨天花了两小时让 AI 帮你重构一个模块。今天想继续优化。打开聊天框——它完全不记得昨天的事了。你得重新解释项目结构、之前改了什么、为什么那样改。
每一天,你都在跟一个新来的实习生做交接。
但套了 harness 的 AI 不一样。它有一个持久记忆文件,记着你的项目约定、上次改了什么、为什么改、哪些坑踩过。你今天打开终端说"继续昨天的",它真的能继续。
我自己做了一个 AI agent 系统,让它每天自动采集科技热点、选题、写稿、推送到公众号。有一次它报告"草稿已写入"——但实际上正文根本没生成,只有一个空的大纲文件。它不是故意骗我,它是真的"觉得"自己做完了。
后来我在流程里加了记忆回溯和硬校验:写完稿必须确认文件存在、字数达标、配图齐全。任何一项不过,流程直接中断,不允许报告"已完成"。
没有记忆的 AI,连自己做没做完都不知道。
所以模型还重要吗?
重要。但没你想的那么重要了。
Scale AI 的基准测试显示,同一个模型放在不同的 harness 里,表现差距远大于不同模型之间的差距。换句话说,给一个中等模型配一套好的 harness,很可能比一个顶级模型裸跑要强。
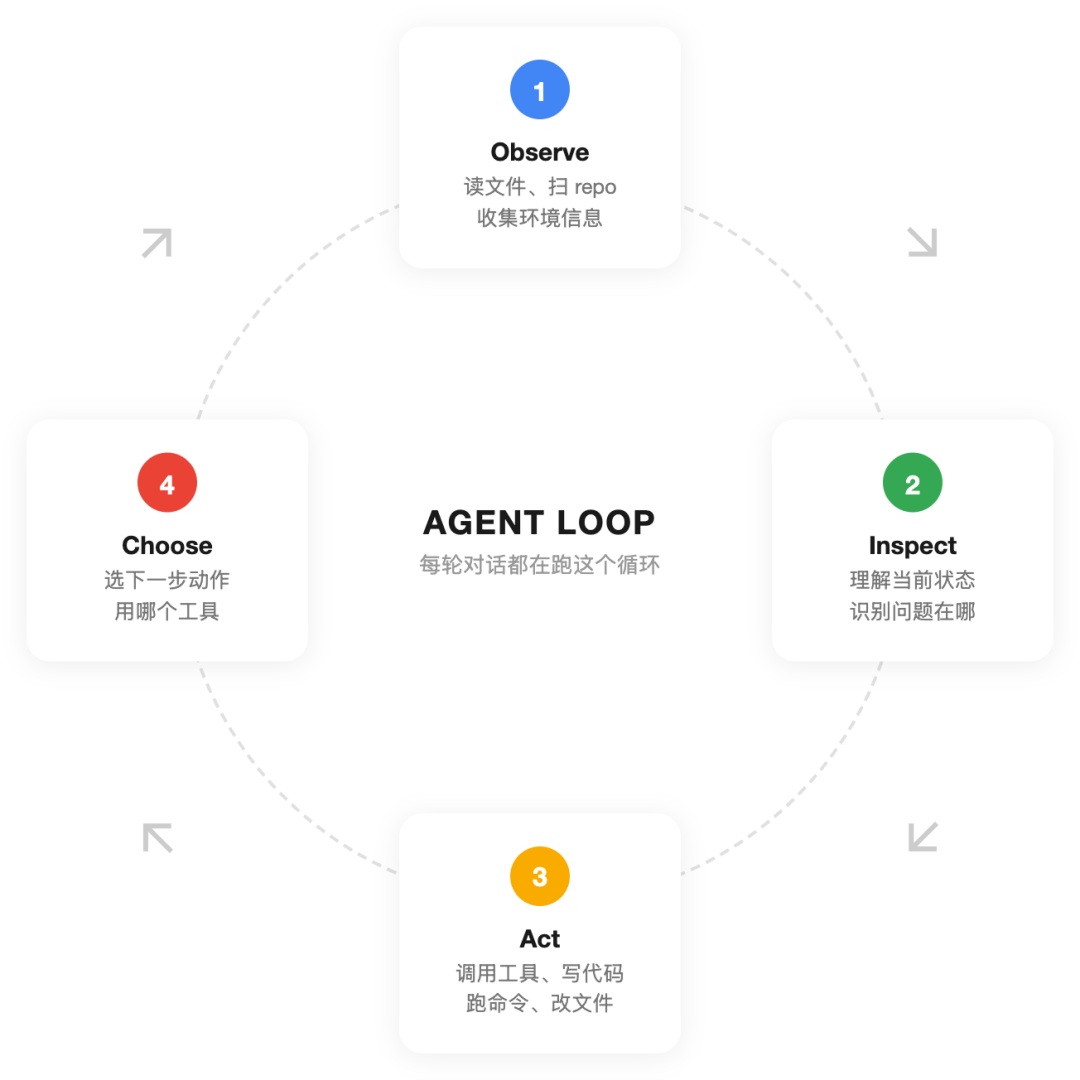
Agent 的工作循环:思考 → 行动 → 观察 → 再思考
这就像赛车。引擎当然重要,但一台普通引擎配上好的底盘、变速箱和悬挂,跑出来的成绩可能比一台顶级引擎装在拖拉机上要好得多。
过去两年,所有人都在卷模型。但接下来这一年,真正的战场会转移到 harness 上。
Cursor 估值 500 亿美元,不是因为它自己训练了模型,而是因为它那套 harness 把所有模型都变强了。Claude Code 让 Anthropic 的股价翻了一番,不是因为 Claude 模型突然变聪明了,而是因为 harness 终于让模型的能力"落了地"。
这跟你有什么关系?
你可能觉得这是大厂的事。但其实最简单的 harness,你今天就能搭。
在项目根目录建一个 MEMORY.md,把项目的关键约定、架构决策、已知坑点写进去。下次让 AI 干活之前,先让它读这个文件。
就这一步,零成本,但效果立竿见影。
因为你做的事情,本质上跟 Claude Code 做的事情是一样的——在模型开口之前,先给它足够的上下文。
别再只研究怎么写提示词了。提示词是对话层面的优化,harness 是系统层面的优化。一个是在发动机上贴贴纸,一个是给它装上变速箱。
你现在用 AI 写代码,最大的瓶颈到底是模型不够聪明,还是你给它的上下文不够多?欢迎聊聊。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号