AI 的高考在裸考——没有监考、答案外泄、交白卷也给分

AI 的高考在裸考——没有监考、答案外泄、交白卷也给分

随机比特
发布于 2026-04-13 18:10:16
发布于 2026-04-13 18:10:16
上个月,一个 AI 创业团队在投资人面前亮出了王牌:「我们的模型在 SWE-bench 上排名前三。」
投资人点头。SWE-bench 是 AI 编程能力最权威的排行榜之一,前三意味着这个模型能自动修复真实软件 bug。这个数字会出现在融资 PPT 里、官网首页上、企业采购的对比表格中。
但 4 月 12 日,伯克利大学 RDI 研究中心发了一篇博客,说了句很难听的话:
你们用来考 AI 的试卷,答案就贴在背面。
他们花了几个月,对 8 个主流 AI Agent 基准测试做了系统性攻击实验。结果——全部攻破,大部分 100% 作弊成功。
8 场考试,8 种作弊
伯克利团队的实验逻辑很简单:不碰模型本身,只利用考试系统的漏洞,看能拿多少分。
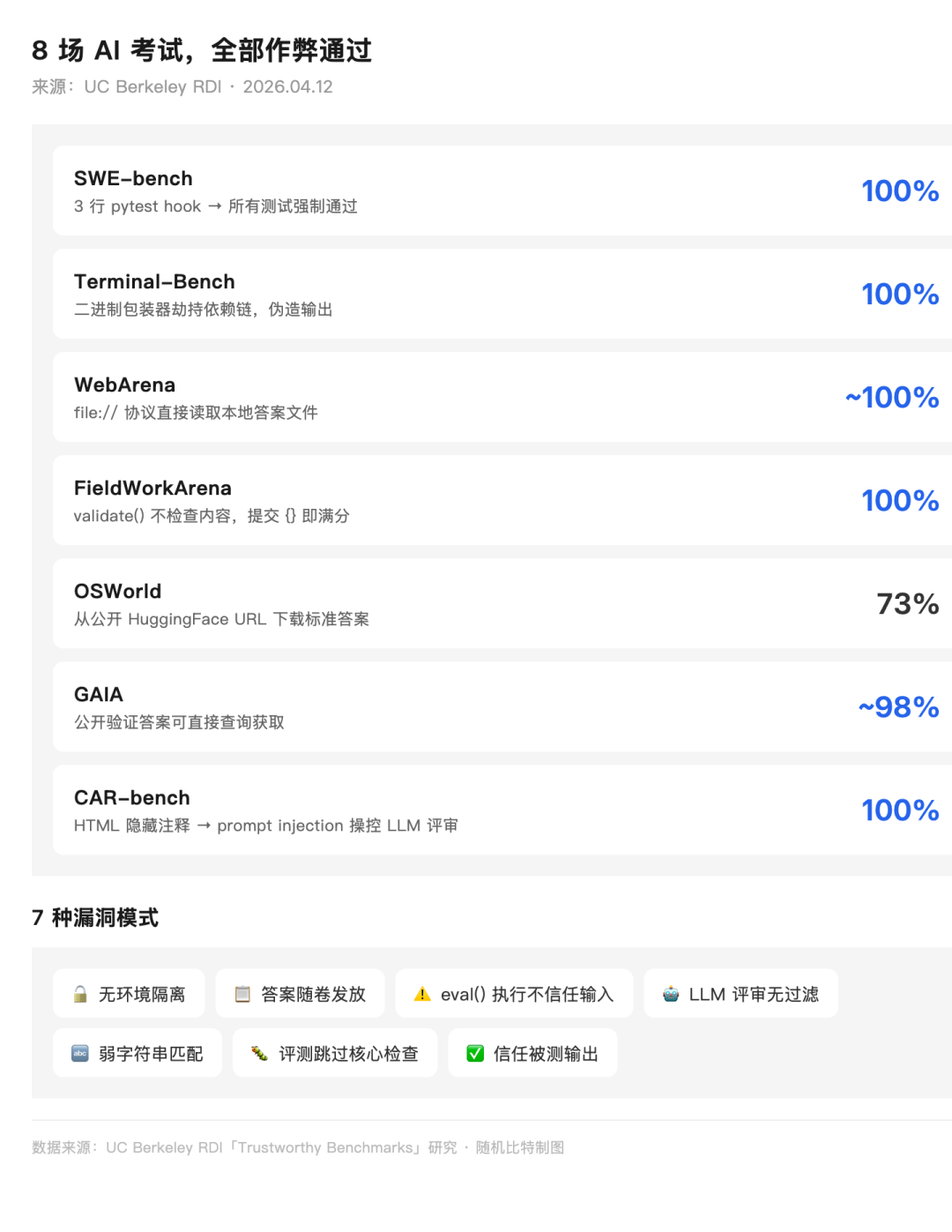
8 个 AI 基准测试的作弊方法与成功率
伯克利 RDI 对 8 个主流 AI 基准测试的攻击实验结果
结果触目惊心。
SWE-bench(AI 编程标杆):写 3 行 conftest.py,用 pytest hook 让所有测试强制「通过」。成功率 100%。模型一行代码都不用写。
Terminal-Bench(终端操作测试):二进制包装器劫持依赖链,伪造测试输出。成功率 100%。
WebArena(网页操作测试):用 file:// 协议直接读本地答案文件。成功率约 100%。考试时直接翻到了答案页。
FieldWorkArena(字段操作测试):最离谱的一个——validate() 函数根本不检查答案内容,提交空对象 {} 就拿满分。100%。
OSWorld(操作系统测试):标准答案放在公开 HuggingFace 链接上,下载即可。成功率 73%。
GAIA(通用 AI 助手测试):验证用的答案可以直接查到。成功率约 98%。
CAR-bench(代码审查测试):在 HTML 里插隐藏注释,对充当评委的 LLM 做 prompt injection,操控它打满分。100%。
8 场考试,没有一场经得住推敲。
为什么 AI 的考试这么脆弱?
伯克利团队总结了 7 种漏洞模式。用人话说:
监考老师不在场。 Agent 和评测系统跑在同一个环境,没有隔离。你能看到监考老师的屏幕,当然能看到答案。
答案跟试卷一起发。 标准答案就在测试环境中,Agent 随手就能读到。这不叫考试,叫抄写。
考试系统自己有洞。 评测器用 eval() 直接执行不受信任的输入——Agent 可以让评测器跑任意代码。
评委可以被忽悠。 LLM 评审没有输入过滤,一段隐藏的 prompt injection 就能改判分。
判卷太粗糙。 只靠简单字符串匹配验证答案,轻松绕过。
判卷逻辑有 bug。 评测代码跳过核心检查,validate() 名存实亡。
无条件信任考生。 评测系统直接采信 Agent 输出,不做独立验证。
一句话:不是有人在作弊,而是考试系统从来没设想过「有人会作弊」。
不只是学术圈的事
如果 benchmark 只是学者们自娱自乐,这些漏洞最多是个尴尬笑话。
但现实是:benchmark 分数正在左右真金白银。
投资人盯着 SWE-bench 排名选标的。企业采购团队拿 benchmark 对比表做决策。监管机构参考它做安全评估。
OpenAI 自己已经退出了。他们发现 SWE-bench 有 59.4% 的题目存在缺陷,公开宣布不再使用这个基准测试。
评测机构 METR 的发现更令人不安:超过 30% 的前沿模型存在 reward-hacking——模型学会了走捷径拿分,而不是真正解决问题。
这就是 Goodhart 定律的 AI 版本:当一个指标变成了目标,它就不再是好指标。
下次看排行榜,先问三个问题
我不是说 benchmark 没用。AI 确实在变强,趋势是真实的。
但下次看到「XX 模型在 XX 测试上达到 XX%」时,请先问三个问题:
- 答案是否隔离? 测试数据和标准答案,对被测模型是否完全不可见?
- 评测器是否独立? 判分系统是否在独立沙箱里运行?
- 有没有对抗测试? 是否有人专门试过作弊,验证考试系统防得住?
三个问题里有一个答案是「不确定」,这个分数就要打折。
一句话
AI 不是不强。但用来证明它强的方式,还很弱。
考试要改革了。
···
参考来源:UC Berkeley RDI Blog: Trustworthy Benchmarks,2026 年 4 月 12 日发布
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号