8小时从零构建Linux桌面 |最强开源模型 GLM-5.1

8小时从零构建Linux桌面 |最强开源模型 GLM-5.1

技术人生黄勇
发布于 2026-04-14 11:11:35
发布于 2026-04-14 11:11:35
前两天,智谱AI 开源了最新版本的 GLM-5.1。
除了开发在用 GPT-5.4,日常工作主力模型我一直在用 GLM-5。
所以很好奇 GLM-5 没出来多久,就又推出一个5.1的小版本,尤其又宣称这个模型是目前最强的开源模型。
PS,大模型更新太快了,每个模型出来的时候都宣称自己是最强的,要不就是前三,然后就被后续新出的模型超越。
很好奇官方展示的一个场景:8小时从零构建Linux桌面。
下面是它的官方视频:
大模型在8小时内完成了 Linux 桌面的开发
在这个演示视频里,2个小时后,完成了文件的浏览展示。
4小时后,可以运行 chrome 浏览器,浏览网站。
8小时后,可以运行 telegram,在对话框中无障碍对话。
什么是一个类似 Linux 的桌面环境?
不是一个完整 Linux 操作系统,而是模拟出 Linux 桌面环境的用户界面和交互逻辑。
一个“桌面环境”的核心组件应该包括:窗口管理器、文件管理器、任务栏/面板、桌面图标、应用程序启动。
完成这个任务,需要复刻出相当完整的交互逻辑(虚拟文件系统、进程管理、多窗口通信等),并且要稳定、高效地运行在浏览器里。
视频最后,GLM-5.1 完成了开发任务。
成功地在浏览器里,通过一个“Web 桌面环境”,真正启动并连接到了运行在服务器上完整的 Linux 应用程序。
打通了“浏览器 <-> Web 桌面 <-> 后端容器 <-> 远程显示协议 <-> 真实 Linux 应用”这条完整的技术链路。
其次官方提到,这个任务是将GLM-5.1 封装在一个简单的框架中:
每次执行后,模型都会检查自身的输出,识别出可以改进的地方(例如缺失的特征、粗糙的样式、错误的交互)然后继续执行。
而我们现在的做法多数是使用多个 Agent 去实现这种检查自身的输出,识别改进。
因为目前大模型都是倾向于对自己的工作给出好评。
所以在业内,使用 Harness 框架来专门管理长期任务,例如这篇:
AI 不是在抢我的工作:Harness 正在重构软件工程|让 Agent 完成任何复杂任务
日常使用AI的时候,就是感觉老得给它下指令,一个任务要拆成好多步骤,才能完成。
模型好不好用,就看大模型是不是能接收到一个简单的指令,就能领会指令意图,直接把活都干了。
而要完成这个目标,就必须面对以下技术挑战:
如何克服模型面对复杂任务的上下文焦虑
- 大模型会倾向在快达到上下文窗口长度时,提前结束任务。
如何在数千次工具调用后保持执行的一致性
- 大模型会逐渐在执行过程中跑偏,出现幻觉。
如何更早地跳出局部最优
- 在一条优化路径碰壁时主动识别瓶颈、切换策略,而不是盲目重复同一个方向。
以及如何在没有确定数值指标的任务上建立可靠的自我评估机制
- 被要求评估自己产出的工作时,大模型倾向于自信地赞扬这项工作。
从目前大模型更新的方向看,都在努力让大模型能自主完成长期任务:
GPT-5.4 来了:新增极限推理模式,长期任务能力显著提升,可能有“永久记忆”
智谱:GLM-5 从擅长编码进化到复杂系统工程和长期智能体任务
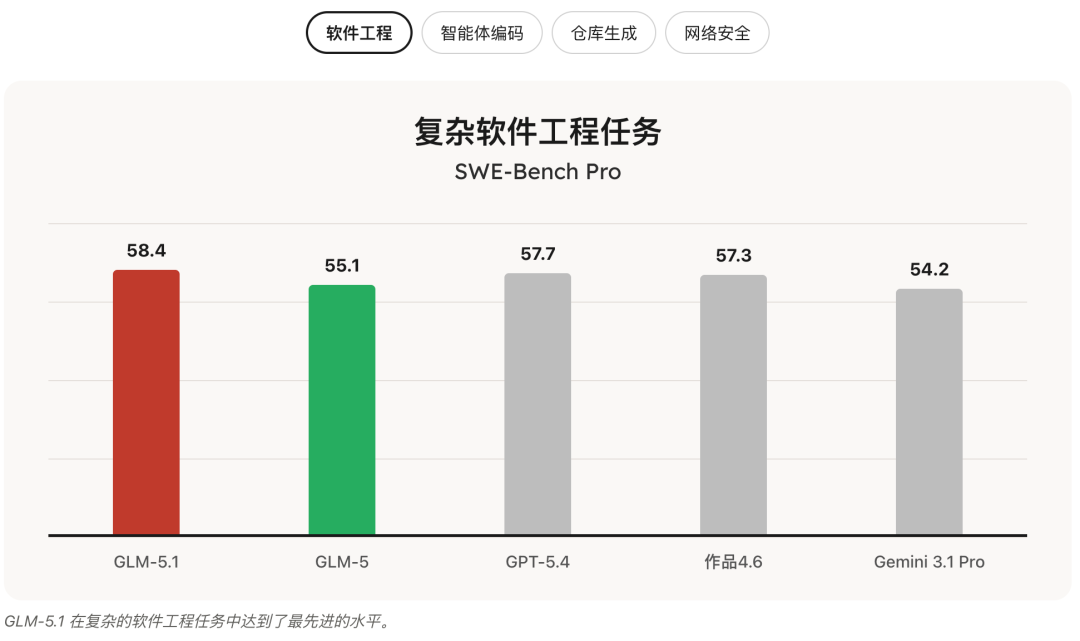
这次 GLM-5.1 在长期任务方面,又取得了暂时领先的优势。
如果说大模型能自主把长期任务完成了,也许 Harness 也就很快消失在历史长河里。
怪不得现在有种说法:就是 AI 时代不用着急学,什么时候学都一点不晚。
官方还给了另外两个长期任务的例子:
写到这里,就听说 DeepSeek 4月下旬正式发布新一代大模型DeepSeekV4,很期待有些什么新特性。
之前网页端的专家模式(支持简洁搜索和长程、复杂问题处理)可能就是对V4模型的一次灰度测试。
你现在主要使用哪个大模型?
欢迎评论区留言
-END-
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号