OceanBase vs TiDB:分布式数据库双雄争霸,谁才是你的菜?还需要分库分表吗?

OceanBase vs TiDB:分布式数据库双雄争霸,谁才是你的菜?还需要分库分表吗?

果酱带你啃java
发布于 2026-04-14 13:07:37
发布于 2026-04-14 13:07:37
在分布式数据库的赛道上,OceanBase 和 TiDB 无疑是两颗最耀眼的明星。它们都宣称能解决传统数据库在海量数据场景下的瓶颈,都支持 SQL、兼容主流数据库协议,甚至在架构设计上也有几分相似。但当你真正面临技术选型时,可能会陷入困惑:这两者到底有什么本质区别?各自适合什么样的业务场景?有了这些 “开箱即用” 的分布式数据库,我们还需要手动做分库分表吗?
作为一名深耕数据库领域多年的技术人,我将从底层架构、核心特性、性能表现、适用场景等多个维度,为你深度剖析这两款国产分布式数据库的异同,并结合实际案例告诉你,在什么情况下该选择它们,什么情况下还需要分库分表的辅助。
一、底层架构大比拼:同源异流的分布式之路
要理解 OceanBase 和 TiDB 的区别,首先得从它们的底层架构说起。虽然两者都是分布式关系型数据库,但在设计理念和实现方式上却有着显著差异。
1.1 OceanBase 的架构:基于 Shared-Nothing 的集群化设计
OceanBase 采用了彻底的 Shared-Nothing 架构,整个集群由多个节点组成,每个节点独立运行,拥有自己的 CPU、内存和存储,节点间通过网络进行通信。其核心架构可以分为三层:
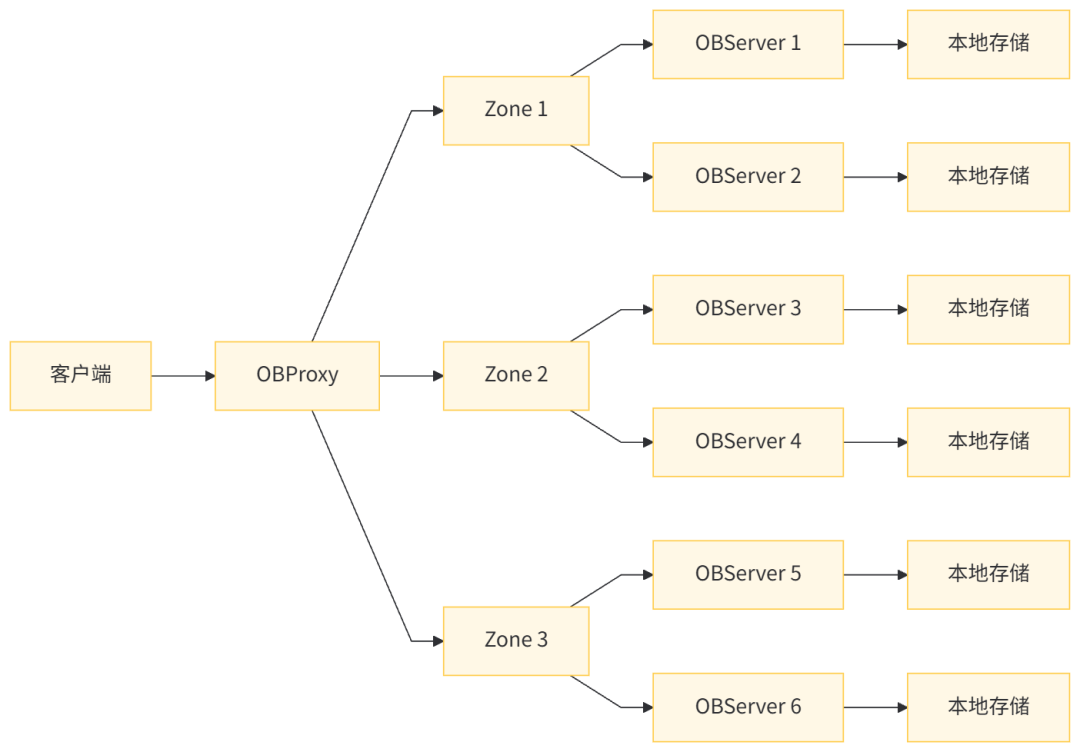
- OBProxy:负责客户端请求的路由和负载均衡,透明地将请求转发到合适的 OBServer 节点。
- Zone:由一组 OBServer 节点组成的逻辑单元,通常对应一个数据中心或机房,用于实现高可用和容灾。
- OBServer:集群的核心节点,每个 OBServer 同时承担计算和存储的角色,运行着 SQL 引擎、事务引擎和存储引擎。
- 本地存储:每个 OBServer 使用本地磁盘存储数据,通过分布式文件系统(如 OBStore)管理数据的持久化。
OceanBase 将数据按表进行水平分片(Partition),每个分片可以有多个副本,分布在不同的 Zone 中。副本之间通过 Paxos 协议实现一致性,确保数据的高可用和强一致性。
1.2 TiDB 的架构:计算与存储分离的新范式
TiDB 则采用了计算与存储分离的架构,将整个系统分为三个主要组件:

- TiDB Server:负责 SQL 解析、优化和执行,不存储数据,相当于计算节点。多个 TiDB Server 节点可以并行工作,实现负载均衡。
- TiKV Cluster:分布式 KV 存储引擎,负责数据的持久化存储。数据被分割成多个 Region(默认 64MB),每个 Region 有多个副本(默认 3 个),通过 Raft 协议保证一致性。
- PD Cluster:Placement Driver,集群的大脑,负责管理元数据、调度 Region、负载均衡等。
TiDB 的架构借鉴了 Google 的 Spanner 和 F1,通过计算与存储的分离,实现了更好的扩展性和资源利用率。
1.3 架构对比:各有千秋的设计哲学
从架构上看,OceanBase 和 TiDB 的主要区别在于:
- 计算与存储是否分离:
- OceanBase:每个节点同时承担计算和存储任务,耦合度较高。
- TiDB:计算(TiDB Server)和存储(TiKV)完全分离,可以独立扩缩容。
- 一致性协议:
- OceanBase:使用 Paxos 协议保证副本一致性。
- TiDB:使用 Raft 协议保证 Region 副本的一致性。
- 分片策略:
- OceanBase:以表为单位进行水平分片,分片粒度较大。
- TiDB:将表数据分割成多个 Region,粒度较小(默认 64MB),更灵活。
这些架构上的差异,直接影响了两者在性能、扩展性、易用性等方面的表现。
二、核心特性深度对比:细节决定成败
除了架构上的差异,OceanBase 和 TiDB 在核心特性上也各有侧重。让我们逐一对比:
2.1 兼容性:对传统数据库的友好度
在企业级应用中,数据库的兼容性至关重要,它直接关系到迁移成本。
- OceanBase:
- 高度兼容 MySQL 和 Oracle 语法,尤其是在金融场景中,对 Oracle 的兼容性做得非常出色。
- 支持 PL/SQL 存储过程、触发器、自定义函数等 Oracle 特有功能。
- 案例:某大型国有银行将核心系统从 Oracle 迁移到 OceanBase,几乎无需修改应用代码。
- TiDB:
- 主要兼容 MySQL 语法,支持大部分 MySQL 5.7/8.0 的功能。
- 对 Oracle 的兼容性较弱,不支持 PL/SQL 等高级特性。
- 案例:某电商平台从 MySQL 分库分表迁移到 TiDB,应用层只需修改连接字符串。
示例:PL/SQL 兼容性对比
在 Oracle 中,我们可以创建这样的存储过程:
CREATE OR REPLACE PROCEDURE get_user_count(
p_dept_id IN NUMBER,
p_count OUT NUMBER
) AS
BEGIN
SELECT COUNT(*) INTO p_count FROM users WHERE dept_id = p_dept_id;
DBMS_OUTPUT.PUT_LINE('User count: ' || p_count);
END;
/
这段代码可以直接在 OceanBase 中运行,因为它支持 PL/SQL 语法。但在 TiDB 中,需要改写成 MySQL 风格的存储过程:
DELIMITER //
CREATE PROCEDURE get_user_count(
IN p_dept_id INT,
OUT p_count INT
)
BEGIN
SELECT COUNT(*) INTO p_count FROM users WHERE dept_id = p_dept_id;
SELECT CONCAT('User count: ', p_count) AS message;
END //
DELIMITER ;
2.2 事务支持:ACID 特性的实现
事务是关系型数据库的核心特性,尤其是在金融等关键业务中,事务的一致性和隔离性至关重要。
- OceanBase:
- 支持完整的 ACID 特性,默认隔离级别为读已提交(Read Committed),也支持可串行化(Serializable)。
- 采用多版本并发控制(MVCC)和乐观锁机制,提高并发性能。
- 支持分布式事务,通过两阶段提交(2PC)和 Paxos 协议保证一致性。
- TiDB:
- 同样支持完整的 ACID 特性,默认隔离级别为可重复读(Repeatable Read)。
- 采用 MVCC 和乐观锁,在高并发写入场景下表现优异。
- 分布式事务基于 Percolator 模型实现,通过 Timestamp Oracle(TSO)生成全局唯一的时间戳,避免了 2PC 的性能瓶颈。
示例:分布式事务对比
假设我们有两个表:orders和order_items,分别存储订单和订单项信息。在一个分布式事务中,我们需要同时插入订单和订单项:
在 OceanBase 中,分布式事务的写法与单机事务无异:
BEGIN;
INSERT INTO orders (order_id, user_id, total_amount) VALUES (1001, 1, 99.99);
INSERT INTO order_items (item_id, order_id, product_id, quantity, price) VALUES (2001, 1001, 3001, 2, 49.99);
COMMIT;
OceanBase 会自动识别这是一个分布式事务(如果两个表分布在不同节点),并通过 2PC 和 Paxos 协议保证一致性。
在 TiDB 中,写法完全相同:
BEGIN;
INSERT INTO orders (order_id, user_id, total_amount) VALUES (1001, 1, 99.99);
INSERT INTO order_items (item_id, order_id, product_id, quantity, price) VALUES (2001, 1001, 3001, 2, 49.99);
COMMIT;
TiDB 会通过 Percolator 模型实现分布式事务,无需显式指定,对应用透明。
2.3 扩展性:应对业务增长的能力
分布式数据库的核心优势之一就是扩展性,让我们看看两者的表现:
- OceanBase:
- 支持在线扩容,新增节点后,数据会自动均衡到新节点。
- 最大可支持数千节点的集群,单集群容量可达 PB 级。
- 案例:支付宝的 OceanBase 集群支撑了数亿用户的交易,峰值 TPS 达到数百万。
- TiDB:
- 计算层(TiDB Server)和存储层(TiKV)可以独立扩容,更加灵活。
- 同样支持 PB 级数据量,适合快速增长的业务。
- 案例:某互联网公司的 TiDB 集群在半年内从 10 节点扩展到 50 节点,期间业务无感知。
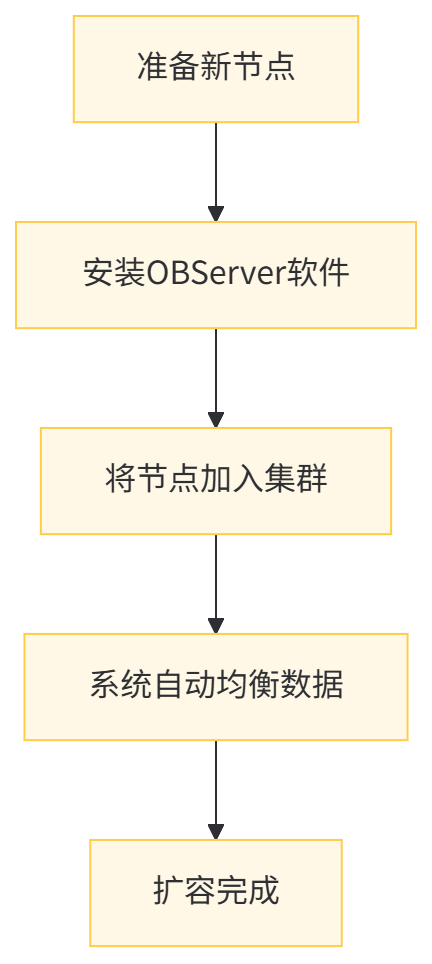
扩展流程对比:
OceanBase 的扩容流程:
TiDB 的扩容流程:
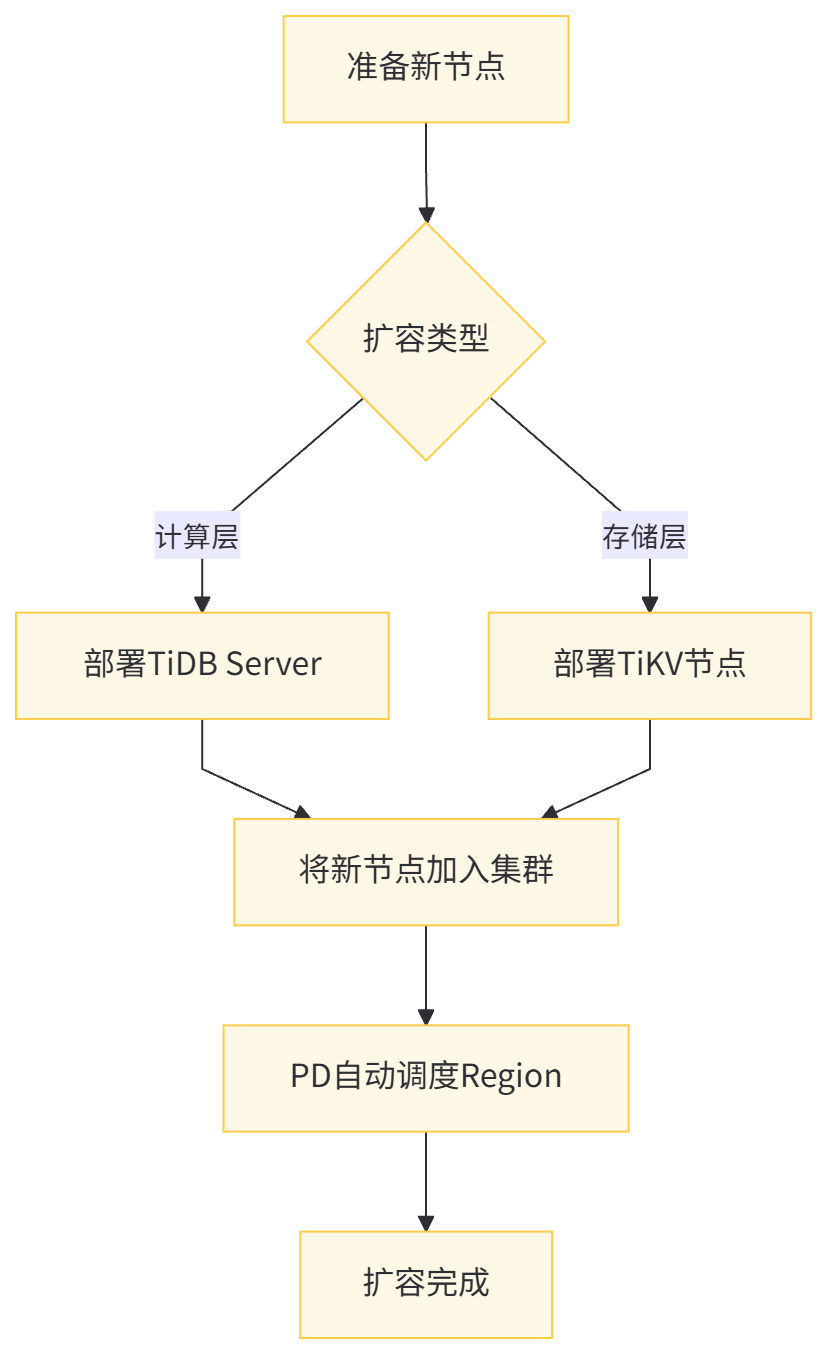
TiDB 的计算与存储分离架构,使得扩容更加灵活,可以根据业务负载单独扩容计算或存储资源。
2.4 高可用与容灾:数据安全的保障
在关键业务中,数据库的高可用和容灾能力至关重要。
- OceanBase:
- 采用多副本机制,默认 3 副本,支持跨机房部署。
- 通过 Paxos 协议保证副本一致性,单副本故障不影响服务。
- 支持秒级故障自动切换,RPO(恢复点目标)为 0,RTO(恢复时间目标)秒级。
- TiDB:
- 每个 Region 默认 3 副本,分布在不同节点。
- 通过 Raft 协议保证一致性,Leader 节点故障后,Follower 会自动选举为新 Leader。
- 支持跨区域部署,提供更强的容灾能力,RPO=0,RTO 分钟级。
容灾方案对比:
OceanBase 的多机房部署:

三个 Zone 分别部署在三个不同的机房,通过 Paxos 协议实时同步数据,任何一个机房故障,另外两个机房仍能提供服务。
TiDB 的跨区域部署:

TiDB 可以跨多个数据中心部署,PD 集群协调全局,保证数据一致性。当一个数据中心故障时,另一个数据中心可以接管服务。
2.5 性能表现:谁更快?
性能是数据库选型的重要指标,我们从读、写、复杂查询等方面对比:
- OLTP 场景:
- OceanBase:在高并发写入场景下表现优异,尤其在金融级交易场景中经过了严格考验。
- TiDB:读性能出色,尤其是在分布式 JOIN 等操作上优化较好。
- OLAP 场景:
- OceanBase:通过集成 OLAP 引擎(如 OB Analytics),支持一定的分析能力,但主要优势仍在 OLTP。
- TiDB:通过 TiFlash(列式存储引擎),提供强大的实时分析能力,支持 HTAP(混合事务 / 分析处理)。
性能测试对比(基于标准 TPC-C 测试):
指标 | OceanBase | TiDB |
|---|---|---|
TPS | 数百万 | 数十万 |
响应时间 | 毫秒级 | 毫秒级 |
扩展性 | 线性扩展 | 接近线性扩展 |
需要注意的是,实际性能会受到硬件配置、数据模型、查询类型等多种因素影响,以上数据仅供参考。
三、适用场景分析:没有最好,只有最合适
了解了 OceanBase 和 TiDB 的特性后,我们来看看它们各自适合什么样的业务场景。
3.1 OceanBase 的最佳实践场景
- 金融核心系统:
- 特点:高并发、高可用、强一致性、数据量大。
- 案例:支付宝、网商银行等金融机构的核心交易系统。
- 优势:Oracle 兼容性好,事务一致性强,经过了双 11 等极端场景的考验。
- 大型企业级应用:
- 特点:复杂业务逻辑、大量存储过程、高稳定性要求。
- 案例:中国移动、国家电网等大型企业的业务系统。
- 优势:兼容传统数据库生态,迁移成本低,运维成熟。
- 需要替代 Oracle 的场景:
- 特点:依赖 PL/SQL、复杂索引、高级数据类型。
- 案例:某省级社保系统从 Oracle 迁移到 OceanBase。
- 优势:对 Oracle 的语法和功能支持最全面,迁移成本最低。
3.2 TiDB 的最佳实践场景
- 互联网业务:
- 特点:快速迭代、数据量爆炸式增长、读写分离。
- 案例:知乎、美团、字节跳动等互联网公司的业务。
- 优势:MySQL 兼容性好,扩展灵活,适合敏捷开发。
- 实时数据分析场景:
- 特点:需要实时处理和分析大量数据,支持复杂查询。
- 案例:某电商平台的实时销售分析系统。
- 优势:通过 TiFlash 实现 HTAP,无需数据同步即可进行实时分析。
- 需要替代 MySQL 分库分表的场景:
- 特点:数据量大,已使用分库分表,运维复杂。
- 案例:某物流平台从 ShardingSphere 迁移到 TiDB。
- 优势:透明的分布式能力,无需应用层处理分库分表逻辑。
3.3 场景选择决策树
为了帮助你快速做出选择,我整理了一个决策树:
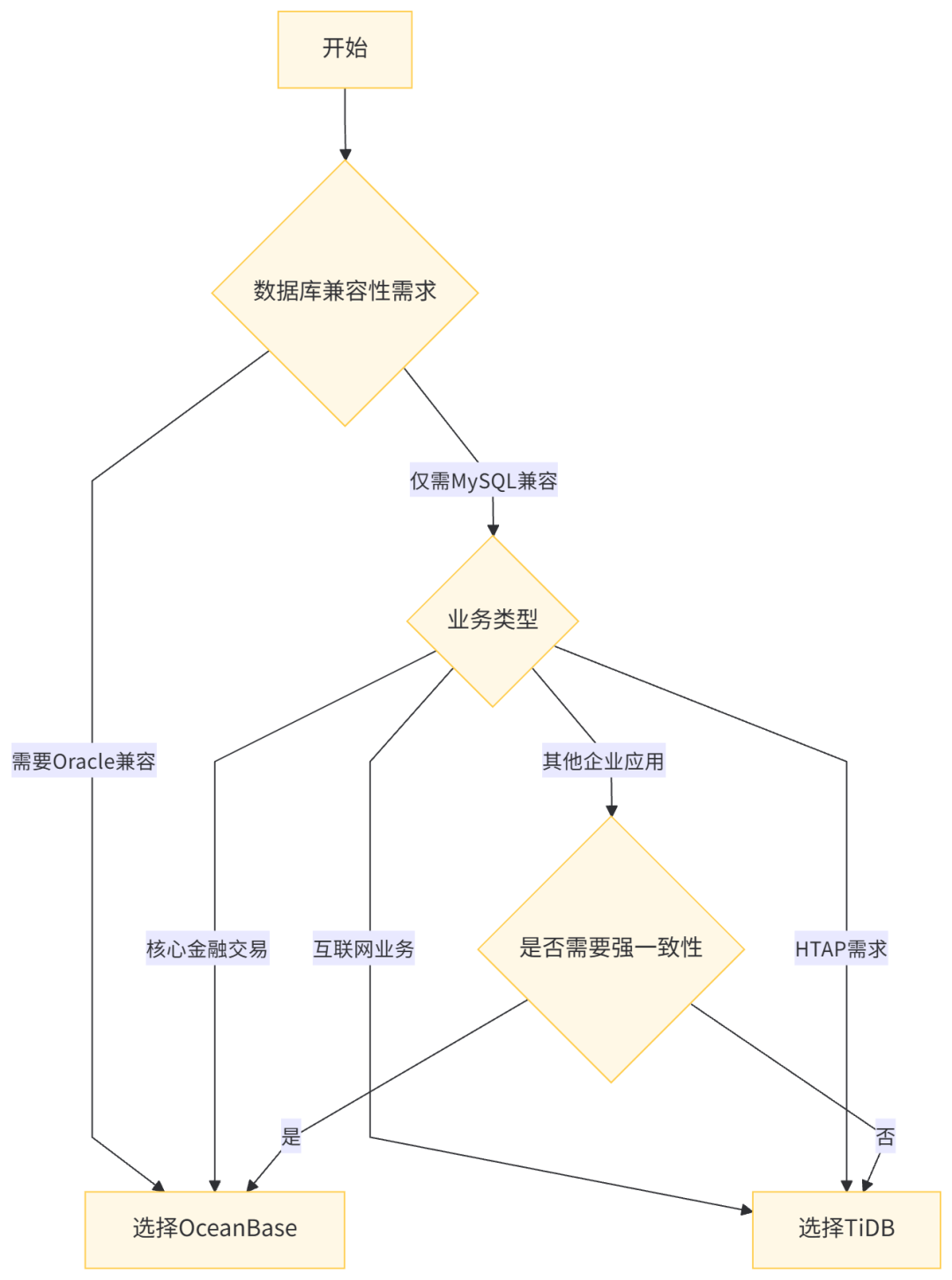
当然,这只是一个简化的决策模型,实际选型时还需要考虑团队技术栈、运维能力、成本等因素。
四、分库分表的那些事:还需要吗?
很多人会问:有了 OceanBase 和 TiDB 这样的分布式数据库,我们还需要手动做分库分表吗?这个问题不能一概而论,需要具体分析。
4.1 分库分表的本质与痛点
分库分表是传统单机数据库应对海量数据的无奈之举,通过将数据分散到多个数据库和表中,解决单机性能瓶颈。常见的分库分表中间件有 ShardingSphere、MyCat 等。
分库分表的痛点:
- 应用层需要处理复杂的分片逻辑,增加开发难度。
- 分布式事务难以保证,一致性问题突出。
- 运维复杂,扩容、迁移成本高。
- 跨分片查询性能差,尤其是 JOIN 操作。
4.2 OceanBase/TiDB 与分库分表的关系
OceanBase 和 TiDB 作为原生分布式数据库,内部已经实现了自动分片、分布式事务、透明扩容等功能,从理论上讲,可以替代分库分表方案。
但在实际应用中,是否需要分库分表,取决于以下因素:
- 数据量和访问模式:
- 如果数据量在 TB 级别以下,且访问模式简单,可能不需要分库分表。
- 如果数据量达到 PB 级别,或者有特殊的访问模式(如热点数据),可能需要结合分库分表的思想,进行表设计优化。
- 迁移成本:
- 如果现有系统已经大量使用分库分表,迁移到分布式数据库可能需要重构,成本较高。
- 新建系统建议直接使用分布式数据库,避免引入分库分表的复杂性。
- 性能需求:
- 对于超高并发的场景(如秒杀),即使使用分布式数据库,可能仍需要结合分库分表的思想,进行特殊优化。
4.3 最佳实践:何时用分布式数据库,何时用分库分表?
- 优先选择分布式数据库的场景:
- 新建系统,数据量预期会增长到 TB 级以上。
- 对事务一致性要求高,有复杂的跨表查询。
- 希望降低运维成本,提高开发效率。
- 可以考虑分库分表的场景:
- 现有系统基于 MySQL/PostgreSQL,数据量增长但未达到 PB 级。
- 团队对分库分表技术栈熟悉,迁移成本高。
- 有特殊的性能优化需求,如热点数据隔离。
- 混合方案:
- 在某些场景下,可以将分布式数据库和分库分表结合使用。例如,用 TiDB 存储核心业务数据,用分库分表存储日志、监控等非核心数据。
4.4 示例:从分库分表迁移到 TiDB 的实践
假设我们有一个电商订单系统,原来使用 MySQL 分库分表,按订单 ID 哈希分为 8 个库,每个库又按时间分为 12 个表(每月一个表)。应用层使用 ShardingSphere 处理分片逻辑。
迁移到 TiDB 的步骤:
表结构设计:原来的分库分表表结构:
-- 分库:db_order_0 到 db_order_7
-- 每个库中分表:t_order_202301 到 t_order_202312
CREATE TABLE t_order_${month} (
order_id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
order_time DATETIME NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
PRIMARY KEY (order_id)
);
迁移到 TiDB 后,无需分表,直接使用一张表:
CREATE TABLE t_order (
order_id BIGINT NOT NULL,
user_id BIGINT NOT NULL,
order_time DATETIME NOT NULL,
total_amount DECIMAL(10,2) NOT NULL,
PRIMARY KEY (order_id)
) PARTITION BY RANGE (TO_YEAR(order_time) * 100 + TO_MONTH(order_time)) (
PARTITION p202301 VALUES LESS THAN (202302),
PARTITION p202302 VALUES LESS THAN (202303),
...
PARTITION p202312 VALUES LESS THAN (202401)
);
TiDB 支持分区表,内部会自动管理分区的分布,对应用透明。
应用代码改造:原来使用 ShardingSphere 的代码:
// 使用ShardingSphere的DataSource
@Autowired
private DataSource shardingDataSource;
public Order getOrder(Long orderId) {
try (Connection conn = shardingDataSource.getConnection();
PreparedStatement ps = conn.prepareStatement("SELECT * FROM t_order WHERE order_id = ?")) {
ps.setLong(1, orderId);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
// 映射结果集到Order对象
return mapOrder(rs);
}
}
} catch (SQLException e) {
log.error("查询订单失败", e);
throw new RuntimeException("查询订单失败", e);
}
return null;
}
迁移到 TiDB 后,代码简化:
// 使用普通的MySQL DataSource
@Autowired
private DataSource tidbDataSource;
public Order getOrder(Long orderId) {
try (Connection conn = tidbDataSource.getConnection();
PreparedStatement ps = conn.prepareStatement("SELECT * FROM t_order WHERE order_id = ?")) {
ps.setLong(1, orderId);
try (ResultSet rs = ps.executeQuery()) {
if (rs.next()) {
// 映射结果集到Order对象
return mapOrder(rs);
}
}
} catch (SQLException e) {
log.error("查询订单失败", e);
throw new RuntimeException("查询订单失败", e);
}
return null;
}
可以看到,迁移到 TiDB 后,应用层无需关心分片逻辑,代码更加简洁。
数据迁移:使用 TiDB 提供的 TiDB Data Migration (DM) 工具,将分库分表的数据迁移到 TiDB 的单表中。
性能优化:根据业务访问模式,在 TiDB 中创建合适的索引,如:
-- 针对用户查询订单的场景创建索引
CREATE INDEX idx_user_time ON t_order (user_id, order_time);
通过这个例子可以看出,使用 TiDB 后,我们可以告别复杂的分库分表逻辑,大大简化应用开发和运维成本。
五、选型建议与未来展望
5.1 选型时的关键考量因素
在选择 OceanBase、TiDB 或分库分表方案时,建议从以下几个方面考虑:
- 业务需求:明确你的业务是 OLTP、OLAP 还是 HTAP?数据量有多大?增长速度如何?
- 技术兼容性:现有应用使用的数据库类型?是否有大量存储过程、特殊函数?
- 团队能力:团队对哪种技术栈更熟悉?是否有分布式数据库的运维经验?
- 成本预算:包括硬件成本、软件许可成本、人力成本等。
- 长期规划:未来 3-5 年的业务发展规划,是否需要国际化部署、多活架构等?
5.2 分布式数据库的未来趋势
- HTAP 融合:事务处理和分析处理的界限将越来越模糊,一个数据库同时支持两种 workload。
- 云原生:更好地适应云环境,支持弹性伸缩、按需付费。
- 智能化:自动调优、故障自愈、智能索引推荐等 AI 能力将成为标配。
- 多模数据支持:除了关系型数据,还将支持 JSON、时序、地理空间等多种数据类型。
5.3 总结
OceanBase 和 TiDB 都是优秀的国产分布式数据库,它们各有侧重:
- OceanBase 在金融级稳定性、Oracle 兼容性方面更具优势,适合核心交易系统。
- TiDB 在 MySQL 兼容性、HTAP 能力、互联网场景适应性方面表现更好。
至于是否还需要分库分表,答案是:在大多数情况下,使用 OceanBase 或 TiDB 可以替代分库分表方案,降低系统复杂度。但在某些特殊场景下(如现有系统迁移成本过高、有特殊的性能优化需求),分库分表仍有其存在的价值。
技术选型没有绝对的对错,关键是要结合自身业务特点,选择最适合的方案。随着分布式数据库技术的不断成熟,未来我们将有更多更好的选择,让数据管理变得更加简单、高效。
希望这篇文章能帮助你更好地理解 OceanBase、TiDB 和分库分表技术,在实际项目中做出明智的选择。如果你有任何疑问或不同见解,欢迎在评论区交流讨论。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号